







基本原理:
物以类聚,人以群分
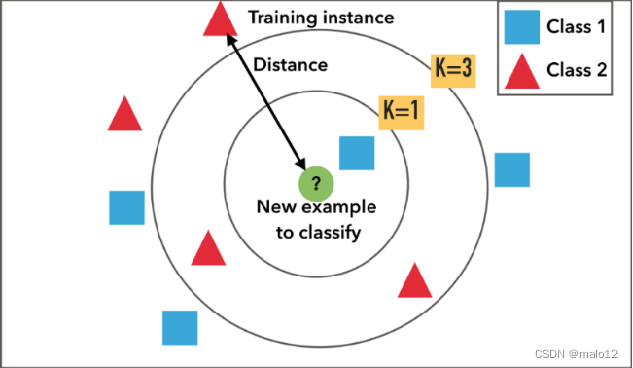
1、K近邻算法
K近邻(K-Nearest Neighbor, KNN)是一种常用的监督学习方法:
- 确定训练样本,以及某种距离度量
- 对于某个给定的测试样本,找到训练集中距离最近的k个样本
- 对于分类问题使用“投票法”获得预测结果
- 对于回归问题使用“平均法”获得预测结果
- 还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大
- 投票法:选择这k个样本中出现最多的类别标记作为预测结果。
- 平均法:将这k个样本的实值输出标记的平均值作为预测结果。
算法详细描述见ppt
2、K近邻模型
2.1 距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映
图形理解:
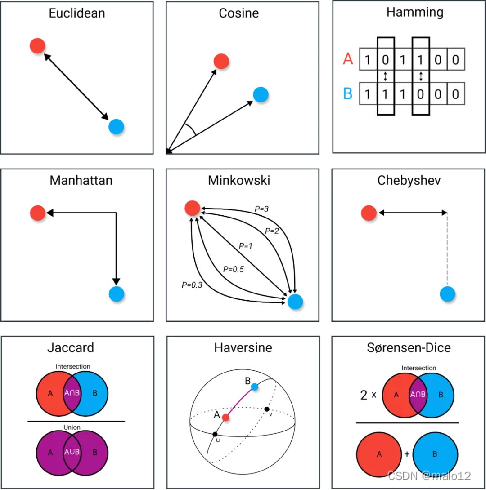
各种距离度量的详细介绍(与上图不是一一对应)

2.2 K值的选择
为了避免平票的出现,K应该选择奇数
- K值小:单个样本的影响越大
- 优点:近似误差(approximation error)减小
只有与输入实例较近的训练实例才会对预测结果起作用 - 缺点:估计误差(estimation error)增大
- 预测结果会对近邻的实例点非常敏感(易受噪声影响)
- K值大:单个样本的影响越小
- 优点:估计误差(estimation error)减小
- 缺点:近似误差(approximation error)增大
交叉验证
千万不能用测试数据来调参
数据量越少,可以适当增加折数
2.3 特征缩放
- 线性归一化(Min-max Normalization)
- 标准差标准化(Z-score Normalization)
3、K近邻的实现:KD树(课上说会考)
最简单实现
线性扫描(linear scan):
计算输入实例与每一个训练实例的距离,复杂度O(n)
缺点:当训练集很大时,计算非常耗时
KD树优化
可以使用KD树来提高K近邻搜索的效率
平均计算复杂度是O(logN)
预备知识:二叉搜索树
3.1 构造KD树
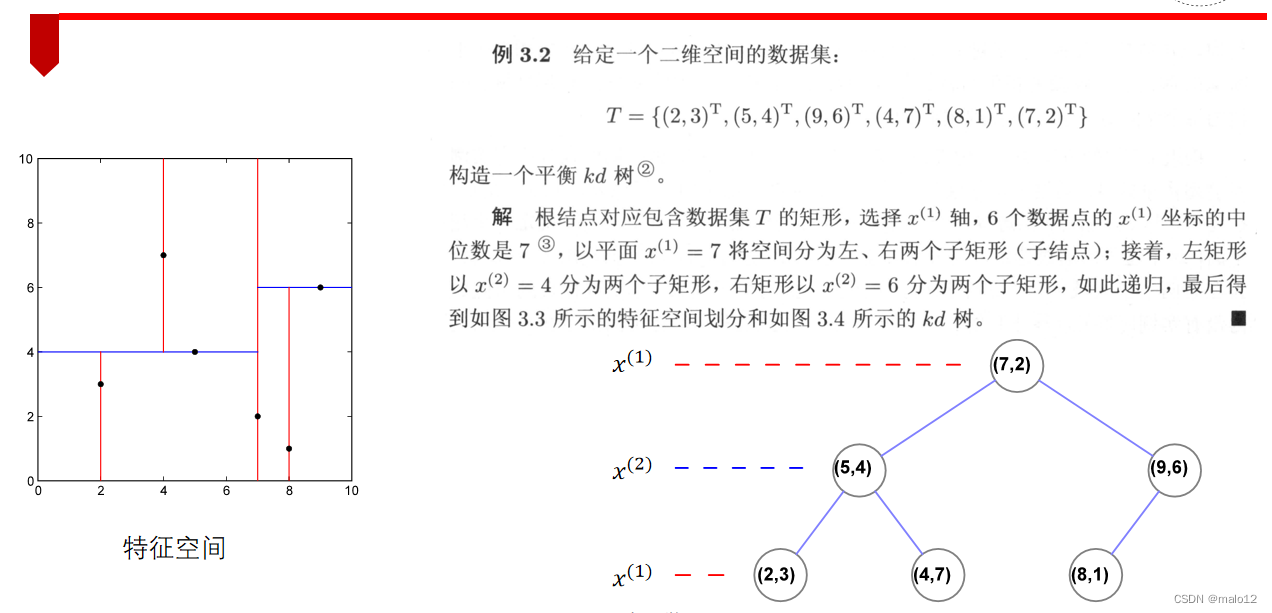
3.2 搜索KD树
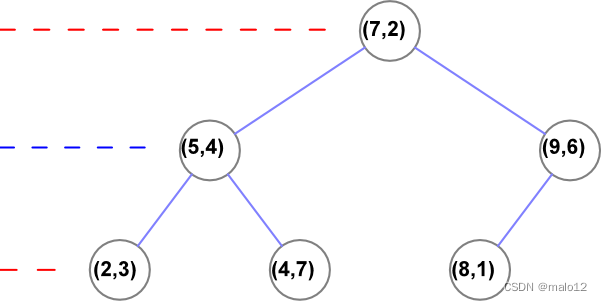
- 步骤一:找到初始当前最近点
先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径:(7,2)→(5,4)→(4,7),取(4,7)为当前最近邻点 - 步骤二:然后回溯到(5,4),将其作为第二个临近点
- 步骤三:进入(5,4)结点的另一个子空间进行查找 (2,3)
- 步骤四:接着根据规则回退到根结点(7,2),与x=7的超平面不相交,因此不用进入(7,2)的右子空间进行查找
4、scikit-learn库中的最近邻算法

详细内容请看官方文档
实战内容请看ppt
实战2-1:海伦约会
实战2-2:手写数字识别
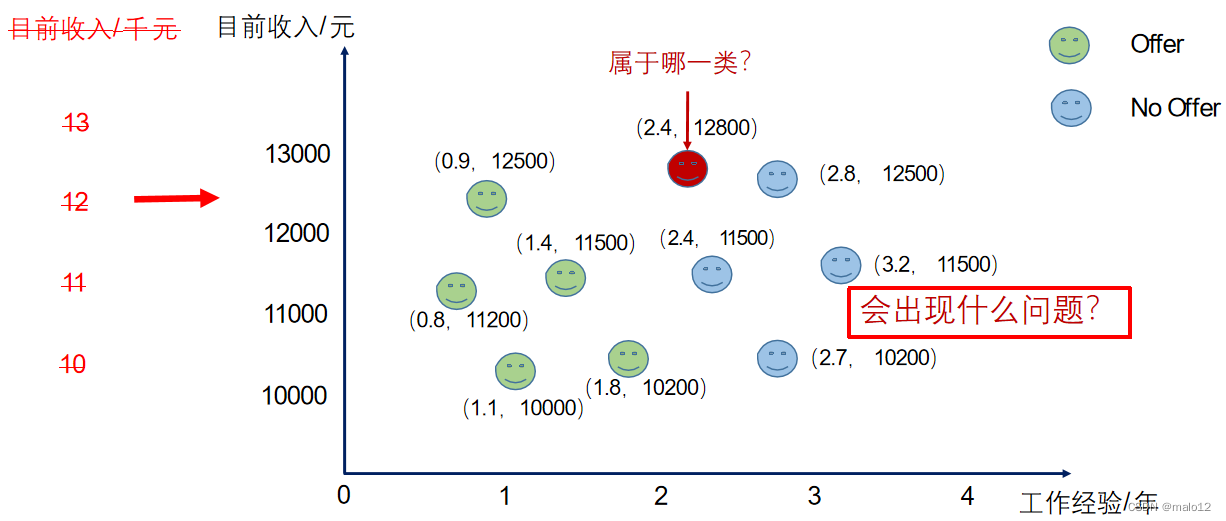
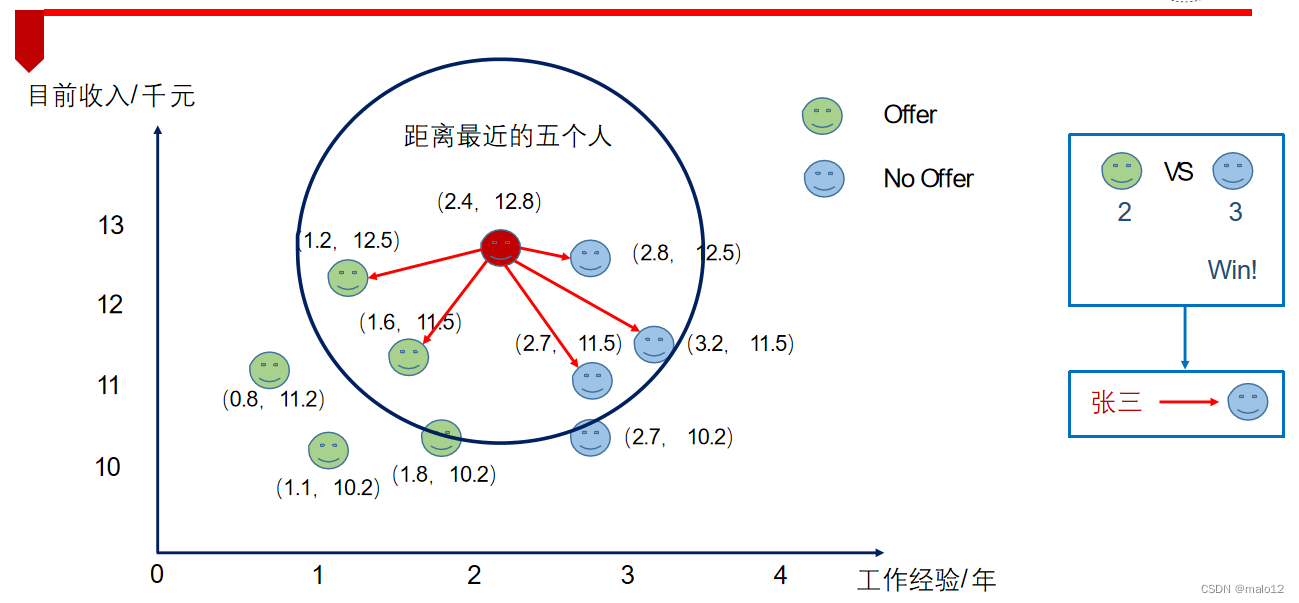
举例:offer预测
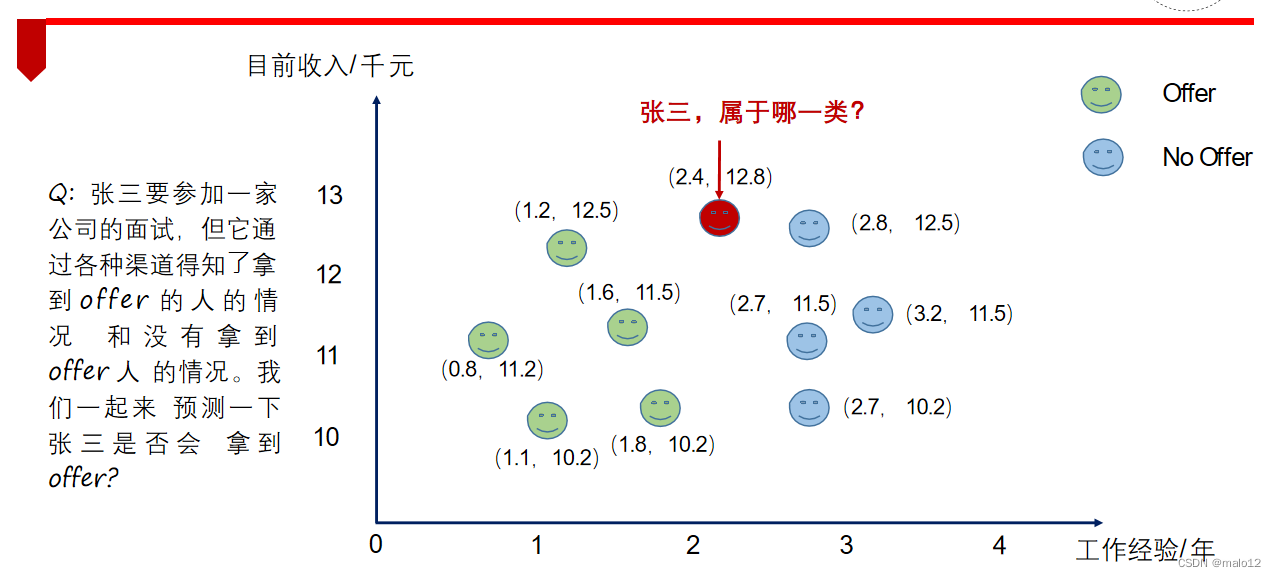
k=1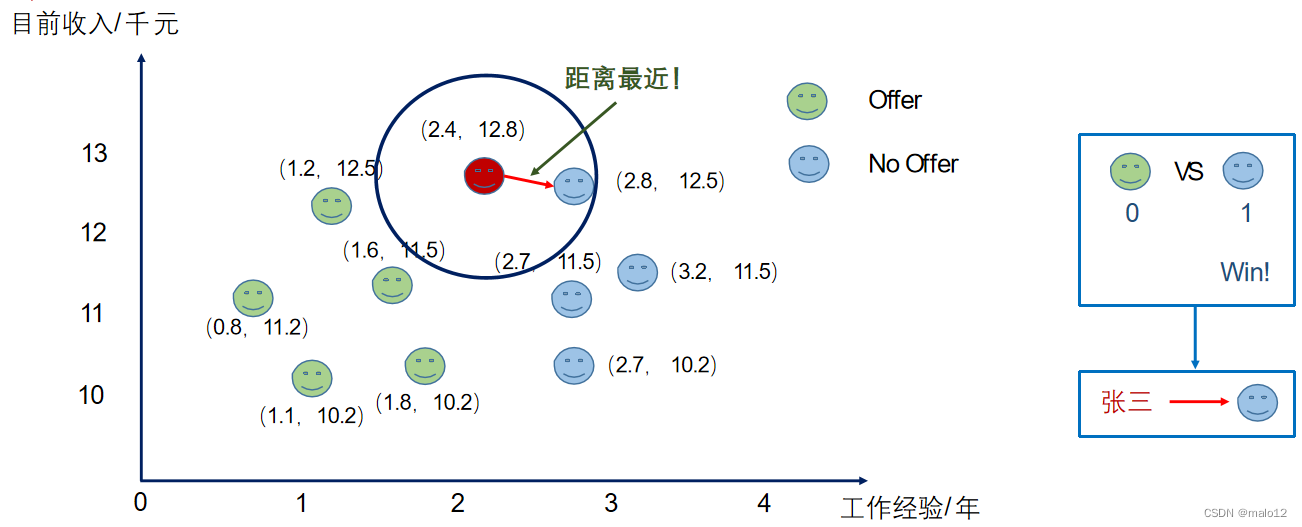
k=3
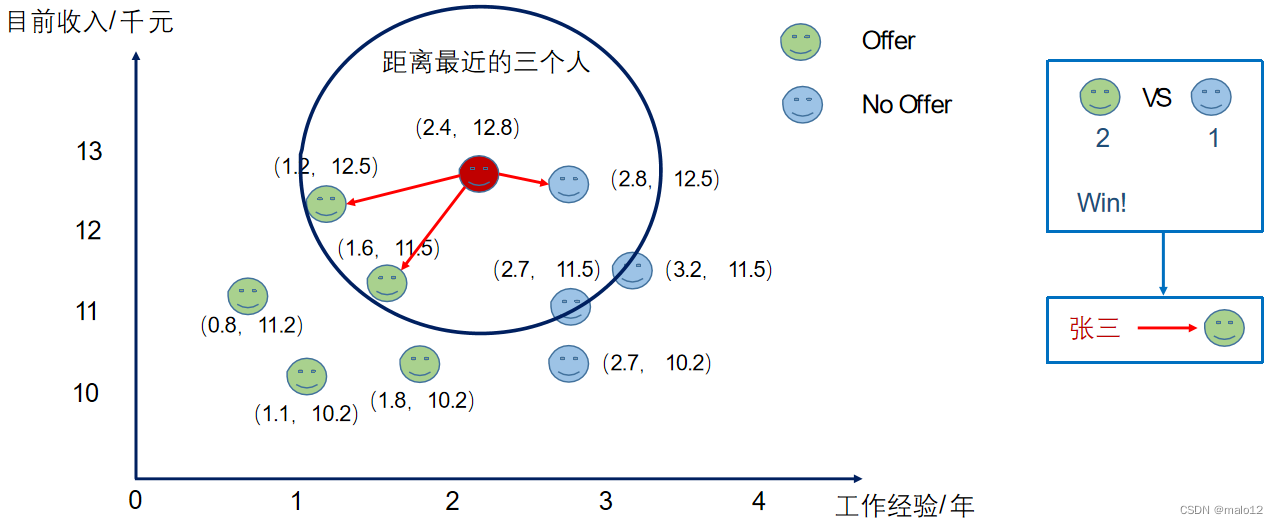
k=5















 4883
4883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









