







待完善,预习用
邻近算法 KNN,K-NearestNeighbor
属于数据挖掘-分类技术 分类算法
K最近邻
即:每个样本可以用它最接近的K个邻近值来代表
近邻算法就是将数据集合中的每一个记录进行分类的方法。
基本思想
要判断一个新数据的类别,就看它的邻居。根据新数据的特征得到在相应属性空间中的坐标,看附近的数据都是什么类别。
-
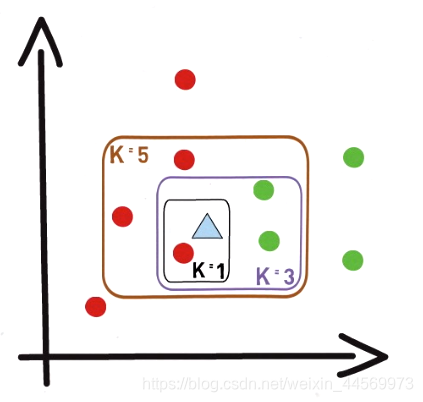
KNN中的K表示邻居的数量,K=3就是通过最近的3个样本来判断数据类别。
-
计算距离时,可以用两点间的直线距离(欧氏距离),也可以使用坐标轴距离绝对值的和(曼哈顿距离)。
算法中,K的取值很重要,K太小则容易受到个例影响,K太大容易受到距离较远的特殊数据影响。K的取值受问题自身和数据集大小决定,建议反复尝试。K的大小也影响做决策参考的数据量。
算法步骤
step1:定义空间、距离公式
step2:先计算新样本与所有样本间的距离
step3:按由近及远的距离排列 (选出距离最小的k个)
step4:按K的取值确定分类——看最近的K个里面哪个类别最多
因此:数据越多则KNN的计算量越大
特点:
只关注局部的样本分布,不需要loss函数
适用于样本容量比较大的类域的自动分类
缺点:
1.计算量较大:每个待分类的文本都需要计算它到全体已知样本的距离,才能求得它的K个最邻近点。
2.局部估算可能不符合全局的分部
3.不能计算概率
4.对K的取值非常敏感
举例

用户A,用户B的喜好确定,用户C和用户A的喜好相似,于是推荐用户A的喜好给用户C
即:把A和C归为相似用户

补充
曼哈顿距离
对应 L 1 L_1 L1范数, L 1 = ∑ i = 1 n ∣ x 1 i − x 2 i ∣ L_1=\sum_{i=1}^n|x_{1i}-x_{2i}| L1=i=1∑n∣x1i−x2i∣
欧氏距离
对应
L
2
L_2
L2范数.
欧氏距离:
d
12
=
∑
k
=
1
n
(
x
1
−
x
2
)
2
d_{12}=\sqrt {\sum_{k=1}^{n}(x_1-x_2)^2}
d12=k=1∑n(x1−x2)2
实践
数据集
IRIS数据集:[百度百科]
Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
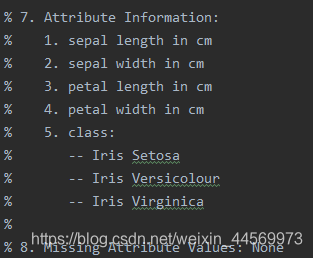
该数据集包含了4个属性:
& Sepal.Length(花萼长度),单位是cm;
& Sepal.Width(花萼宽度),单位是cm;
& Petal.Length(花瓣长度),单位是cm;
& Petal.Width(花瓣宽度),单位是cm;
种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及Iris Virginica(维吉尼亚鸢尾)。
X
=
{
x
1
,
x
2
,
…
,
x
n
}
,
x
i
=
(
x
i
1
,
x
i
2
,
x
i
3
,
x
i
4
)
,
\mathbf X=\{x_1,x_2,\dots,x_n\}, x_i=(x_{i1},x_{i2},x_{i3},x_{i4}),
X={x1,x2,…,xn},xi=(xi1,xi2,xi3,xi4),标签
Y
=
{
Iris Setosa
,
Iris Versicolour
,
Iris Virginica
}
\mathbf Y=\{\textrm{Iris Setosa},\textrm{Iris Versicolour},\textrm{Iris Virginica}\}
Y={Iris Setosa,Iris Versicolour,Iris Virginica}
代码:日撸 Java 三百行(51-60天,kNN 与 NB)
weka.jar的一些使用
/**
* The whole dataset.
*/
Instances dataset;
dataset.instance(paraCurrent).toString(4);
dataset.instance(int index); // 整条数据
dataset.instance(paraCurrent).value(int index); // index标签的值 index = 4:{0,1,2}
dataset.instance(paraCurrent).toString(4); // 第index的值toString {Iris-virginica,...}
dataset.numInstances(); // 数据集的数据数 int














 4333
4333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









