







- 聚合函数
单值类型的聚合函数:
格式:
reduce(fn): 根据传入的函数对数据进行聚合计算
fold(defaultAgg,fn): 根据传入的函数对数据进行聚合计算, 同时支持给agg设置初始值
aggregate(defaultAgg,fn1,fn2): 根据传入的函数对数据进行聚合计算, 参数1 设置agg的初始值, fn1 对RDD的各个分区内的数据进行聚合操作, fn2 负责将各个分区的聚合结果进行汇总处理
案例:
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看各个分区的结果:
rdd.glom().collect()
结果:
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9, 10]
]
需求: 求和计算, 求所有数据之和
rdd.reduce(lambda agg,curr: agg + curr)
结果:
55
rdd.fold(0,lambda agg,curr: agg + curr)
结果:
55
rdd.fold(10,lambda agg,curr: agg + curr)
结果:
95
# 在分区内执行聚合的方案
def fn1(agg,curr):
return agg + curr
# 将各个分区的结果进行汇总的方案
def fn2(agg,curr):
return agg + curr
rdd.aggregate(10,fn1,fn2)
# 结果:
95
思考: 最终聚合的结果是多少呢?
# 在分区内执行聚合的方案
def fn1(agg,curr):
return agg + curr
# 将各个分区的结果进行汇总的方案
def fn2(agg,curr):
return agg - curr
rdd.aggregate(10,fn1,fn2)
# 结果:
-75
KV类型的聚合函数:
格式:
reduceByKey(fn)
foldByKey(defaultAgg, fn)
aggregate(defaultAgg,fn1,fn2)
以上三个与单值类型是一样的, 只是在单值的基础上加了分组的操作而已, 针对的每个分组内的数据进行聚合计算
额外还有一个: groupByKey() 仅分组 不聚合计算
思考点:groupByKey() + 聚合操作 和 reduceByKey() 都是可以完成分组聚合统计, 谁的效率更高一些呢? 为什么?
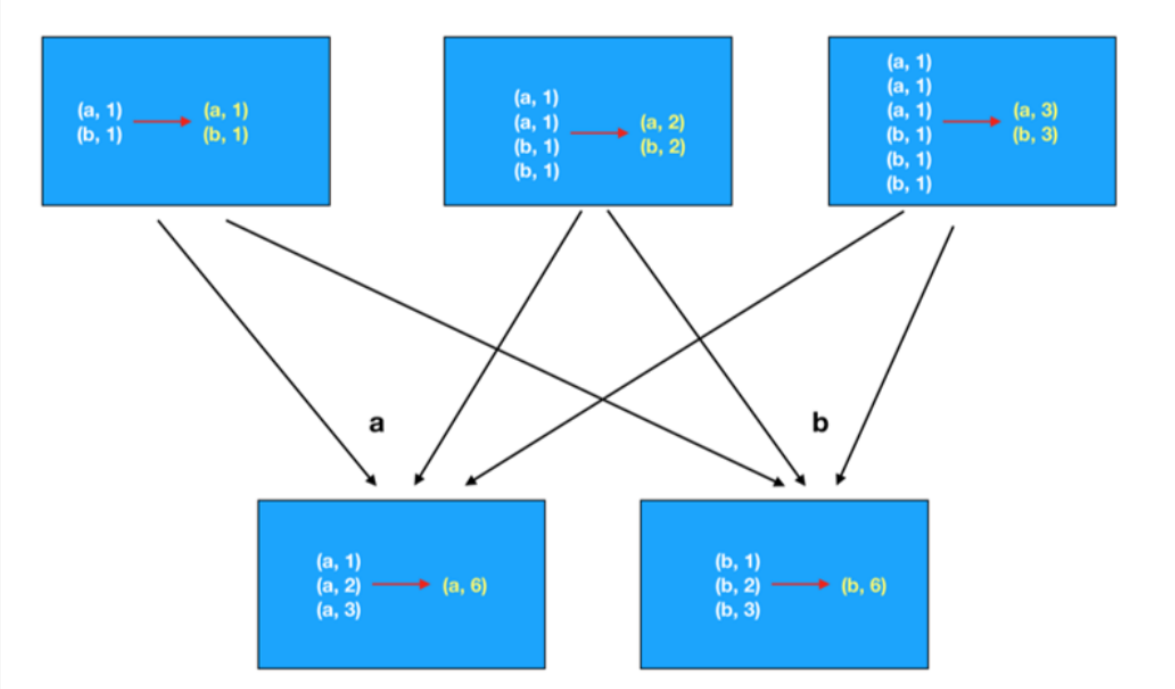
reduceByKey
reduceByKey执行逻辑:
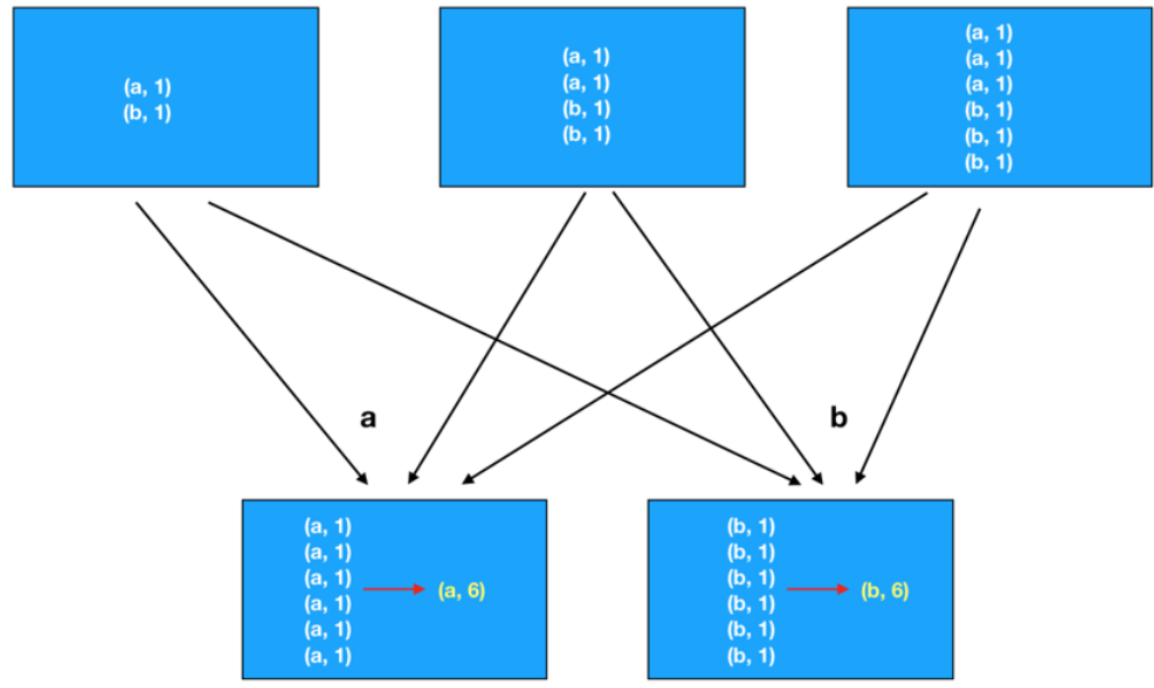
groupByKey+聚合:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











