







 本文介绍了Hadoop的MapReduce计算框架,包括其map和reduce阶段的工作原理,执行流程中的磁盘IO瓶颈,以及一个简单的WordCount应用示例,展示了如何编写和运行MapReduce任务。
本文介绍了Hadoop的MapReduce计算框架,包括其map和reduce阶段的工作原理,执行流程中的磁盘IO瓶颈,以及一个简单的WordCount应用示例,展示了如何编写和运行MapReduce任务。
一、MapReduce的介绍
MapReduce是Hadoop的分布式计算框架,由两个阶段组成,分别是map和reduce阶段,对于程序员而言,使用过程非常简单,只要覆盖map阶段中的map方法和reduce节点的reduce方法即可
map和reduce阶段的形参的键值对的形式
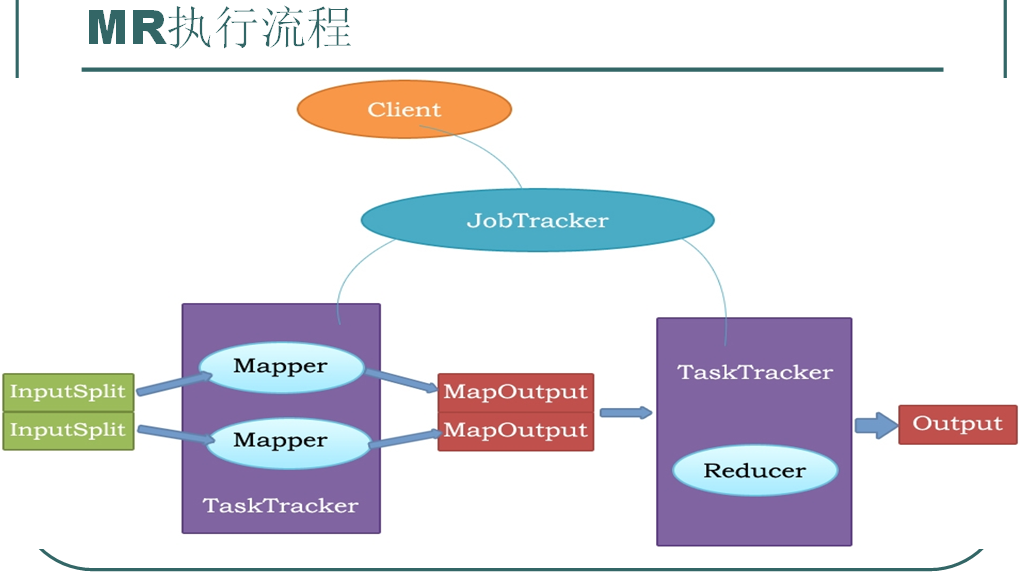
mapreduce的执行流程
瓶颈:磁盘IO
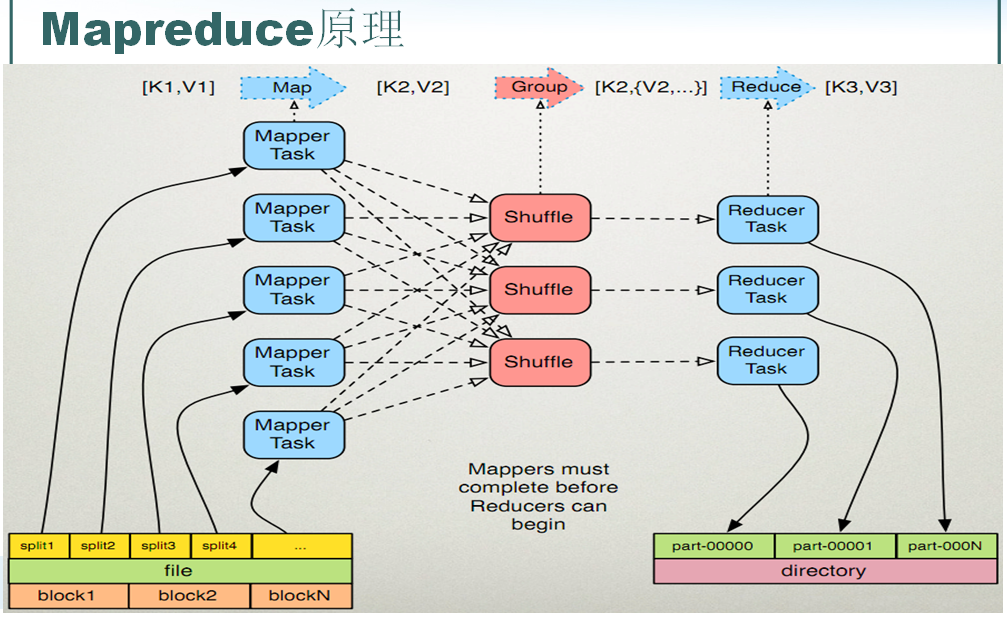
mapreduce执行原理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进行分区。
1.4 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
1.5 (可选)分组后的数据进行归约。(Combine)
2.0 reduce任务处理
2.1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。
例子:实现WordCountApp
# 第一个统计单词的java程序(hadoop自带的例子源码)
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
@SuppressWarnings("all")
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
下面运行命令跟输出结果
[hadoop@master hadoop-1.1.2]$ hadoop jar hadoop-yting-wordcounter.jar org.apache.hadoop.examples.WordCount /user/hadoop/20140303/test.txt /user/hadoop/20140303/output001
[hadoop@master hadoop-1.1.2]$ hadoop fs -ls /user/hadoop/20140303/output001
Found 3 items
-rw-r--r-- 1 hadoop supergroup 0 2014-03-03 10:44 /user/hadoop/20140303/output001/_SUCCESS
drwxr-xr-x - hadoop supergroup 0 2014-03-03 10:43 /user/hadoop/20140303/output001/_logs
-rw-r--r-- 1 hadoop supergroup 188 2014-03-03 10:44 /user/hadoop/20140303/output001/part-r-00000
[hadoop@master hadoop-1.1.2]$ hadoop fs -text /user/hadoop/20140303/output001/part-t-00000
text: File does not exist: /user/hadoop/20140303/output001/part-t-00000
[hadoop@master hadoop-1.1.2]$ hadoop fs -text /user/hadoop/20140303/output001/part-r-00000
a 1
again 1
and 1
changce 1
easy 1
forever 1
give 1
hand 1
heart 2
hold 1
最小的MapReduce(默认设置)
Configuration configuration = new Configuration();
Job job = new Job(configuration, "HelloWorld");
job.setInputFormat(TextInputFormat.class);
job.setMapperClass(IdentityMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setReducerClass(IdentityReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormat(TextOutputFormat.class);
job.waitForCompletion(true);
序列化
Writable
数据流单向的
LongWritable不能进行加减等操作(没必要,java的基本类型都已经弄了这些功能了)
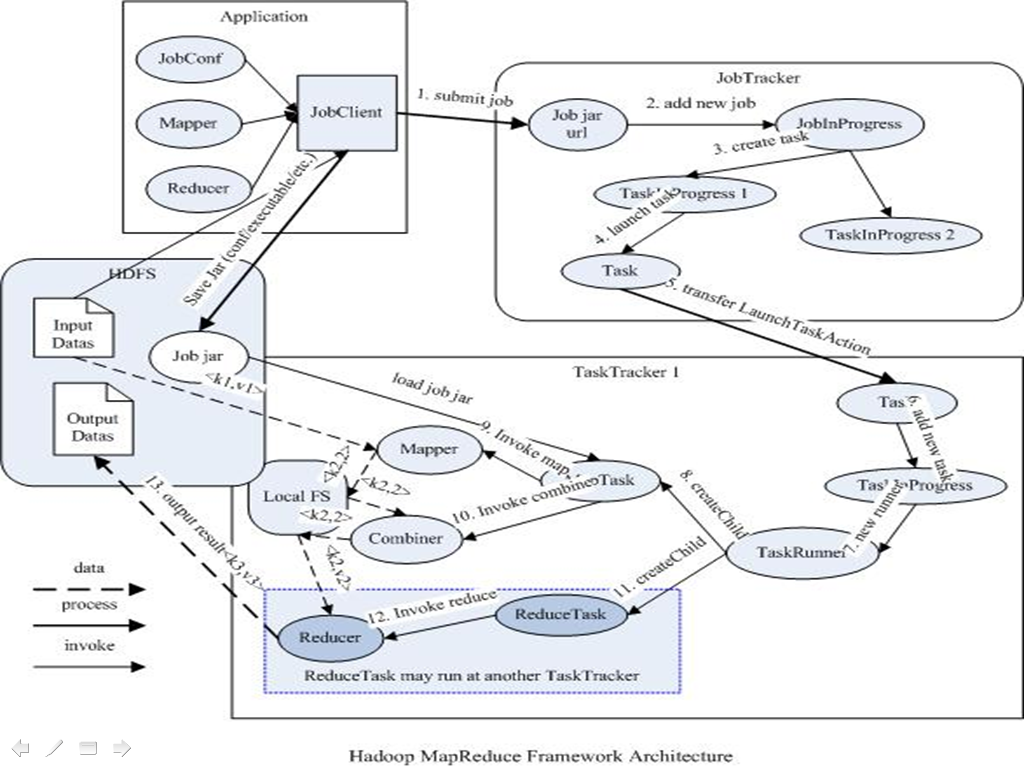
JobTracker,TaskTracker
JobTracker
负责接收用户提交的作业,负责启动、跟踪任务执行。
JobSubmissionProtocol是JobClient与JobTracker通信的接口。
InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
TaskTracker
负责执行任务
JobClient
是用户作业与JobTracker交互的主要接口。
负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。
执行过程
















 6282
6282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









