







数组和广义表
5.1多维数组
5.1.1数组的逻辑结构
数组是我们熟悉的一种数据结构,可以看作线性表的推广。
数组作为一种数据结构其特点是结构中的元素本身可以是具有某种结构的数据,但属于同一类型。比如:一维数组可以看作一个线性表,二维数组可以看作“数据元素是一维数组”的一维数组,三维数组可以看作“数据元素是二维数组”的一维数组,以此类推。

数组是一个具有固定格式和数量的数据有序集,每一个数据元素有唯一的一组下标来标识,因此,在数组上不能做插入、删除数据元素的操作。 通常在各种高级语言中数组一旦被定义,每一维的大小及上下界都不能改变。在数组中通常做下面两种操作:
(1) 取值操作:给定一组下标,读其对应的数据元素。
(2) 赋值操作:给定一组下标,存储或修改与其相对应的数据元素。
我们着重研究二维和三维数组,因为它们的应用是广泛的,尤其是二维数组。
5.1.2数组的内存映像
通常,数组在内存被映象为向量,即用向量作为数组的一种存储结构,这是因为内存的地址空间是一维的,数组的行列固定后,通过一个映象函数,则可根据数组元素的下标得到它的存储地址。
对于一维数组按下标顺序分配即可。
对多维数组分配时,要把它的元素映象存储在一维存储器中,一般有两种存储方式:
①以行为主序(或先行后列)的顺序存放,即一行分配完了接着分配下一行。如C、BASICPASCAL等程序设计语言;
②以列为主序(先列后行)的顺序存放,即一列一列地分配。如FORTRAN等语言。
以行为主序的分配规律:最右边的下标先变化。即最右下标从小到大,循环一遍后,右边第二个下标再变,…,从右向左,最后是左下标。
以列为主序的分配规律:最左边的下标先变化。恰好与行序为主相反,即最左下标从小到大,循环一遍后,左边第二个下标再变,…,从左向右,最后是右下标。
例如,一个2×3二维数组,逻辑结构可以用下图表示。
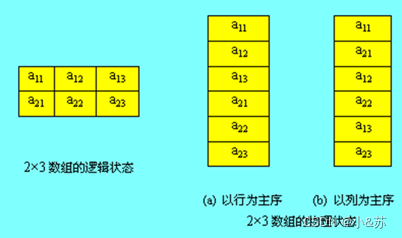
(a)图以行为主序,内存分配顺序为:a11 ,a12 ,a13 ,a21 ,a22 ,a23 ;
(b)图以列为主序,内存分配顺序为:a11 ,a21 ,a12 ,a22 ,a13 ,a23 ;
设有m×n二维数组Amn,下面按元素的下标求其地址的计算。
以“行为主序”的分配为例:设数组的基址为LOC(a11),每个数组元素占据l个地址单元,那么aij 的物理地址可用一线性寻址函数计算:
LOC(aij) = LOC(a11) + ( (i-1)*n + j-1 ) * l
在C语言中,数组中每一维的下界定义为0,则:
LOC(aij) = LOC(a00) + ( i*n + j ) * l
推广到一般的二维数组:A[c1…d1] [c2…d2],则aij的物理地址计算函数为:
LOC(aij)=LOC(a c1 c2)+( (i- c1) * ( d2 - c2 + 1)+ (j- c2) )*l
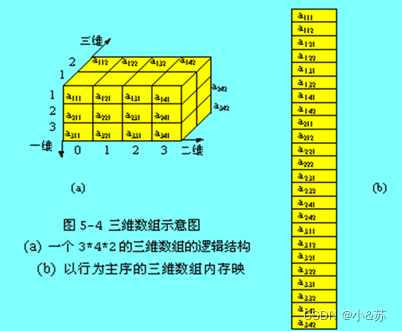
同理对于三维数组Amnp,即m×n×p数组,对于数组元素aijk其物理地址为:
LOC(aijk)=LOC(a111)+( ( i-1) np+ (j-1)*p +k-1)*l
推广到一般的三维数组:A[c1…d1] [c2…d2] [c3…d3],则aijk的物理地址为:
LOC(i,j)=LOC(a c1 c2 c3)+( (i- c1) * ( d2 - c2 + 1)* (d3- c3 + 1)+ (j- c2) * ( d3- c3 + 1)+(k- c3))*l
三维数组的逻辑结构和以行为主序的分配示意图如图所示。
例5.1 若矩阵Am×n 中存在某个元素aij满足:aij是第i行中最小值且是第j列中的最大值,则称该元素为矩阵A的一个鞍点。试编写一个算法,找出A中的所有鞍点。
基本思想:在矩阵A中求出每一行的最小值元素,然后判断该元素它是否是它所在列中的最大值,是则打印出,接着处理下一行。矩阵A用一个二维数组表示。
void saddle(int A[][],int m,int n){
//m,n是矩阵A的行和列
int i,j,k,p,min;
for(i=0;i<m;i++)//按行处理
{
min=A[i][0];
for(j=1;j<n;j++){
if(A[i][j]<min) min=A[i][j];//找第i行最小值
for(j=0;j<n;j++)//检测该行中的每一个最小值是否是鞍点
if(A[i][j]==min)
{
k=j;
p=0;
while(p<m&&A[p][j]<=min)
p++;
if(p>=m) cout<<i<<k<<min;
}
}
}
}
算法的时间性能为O(m* (n+m* n))。
5.2特殊矩阵的压缩存储
5.2.1对称矩阵
对称矩阵的特点是:在一个n阶方阵中,有aij=aji ,其中1≤i , j≤n,如图所示是一个5阶对称矩阵。
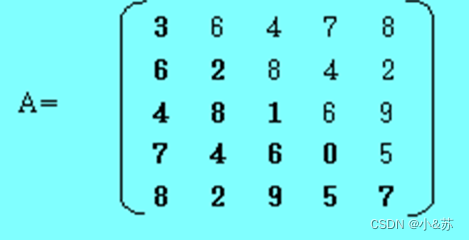
对称矩阵关于主对角线对称,因此只需存储上三角或下三角部分即可。这样,原来需要nn个存储单元,现在只需要n(n+1)/2个存储单元了,节约了n(n-1)/2个存储单元,当n较大时,这是可观的一部分存储资源。


对下三角部分以行为主序顺序存储到一个向量S[n(n+1)/2]中去,如上图示意。
这样,原矩阵下三角中的某一个元素aij则具体对应一个S[k],下面的问题是要找到k与i、j之间的关系。
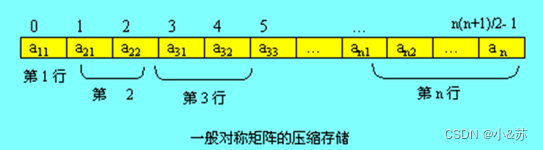
对于下三角中的元素aij,其特点是:i≥j且1≤i≤n,存储到向量S中后,根据存储原则,它前面有i-1行,共有1+2+…+i-1=i*(i-1)/2个元素,而aij又是它所在的行中的第j个,所以在上面的排列顺序中,aij是第i*(i-1)/2+j个元素,因此它在S中的下标k与i、j的关系为:
k=i* (i-1)/2+j-1 (0≤k<n* (n+1)/2 )
若i<j,则aij是上三角中的元素,因为aij=aji,这样,访问上三角中的元素aij时则去访问和它对应的下三角中的aji即可,因此将上式中的行列下标交换就是上三角中的元素在S中的对应关系:
k=j * (j-1)/2+i-1 (0≤k<n*(n+1)/2 )
综上所述,对于对称矩阵中的任意元素aij,若令I=max(i,j),J=min(i,j),则将上面两个式子综合起来得到:
k=I*(I-1)/2+J-1
5.2.2三角矩阵
-
下三角矩阵
与对称矩阵类似,不同之处在于存完下三角中的元素之后,紧接着存储对角线上方的同一个常量即可,这样一共存储n*(n+1)/2+1个元素。
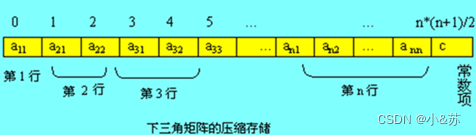
设存入向量S[n*(n+1)/2+1]中,S[k]与aji 的对应关系为:
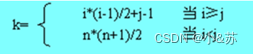
上三角矩阵
对于上三角矩阵,以行为主序顺序存储上三角部分,最后存储对角线下方的常量。对于第1行,存储n个元素,第2行存储n-1个元素,…,第i行存储(n-i+1)个元素,aij的前面有i-1行,共存储:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uGIzndfb-1668559589995)(C:\Users\WSM-\AppData\Roaming\Typora\typora-user-images\image-20221110132737729.png)]](https://img-blog.csdnimg.cn/769179fc0c5445158eef4ee208d822d8.png)
个元素。
S[k]与aji的对应关系为:
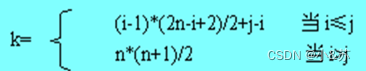
5.2.3带状矩阵
n阶矩阵A称为带状矩阵,如果存在最小正数m,满足当∣i-j∣≥m时,aij=0,这时称w=2m-1为矩阵A的带宽。
一种压缩方法是将A压缩到一个n行w列的二维数组B中,如下图所示,当某行非零元素的个数小于带宽w时,先存放非零元素后补零。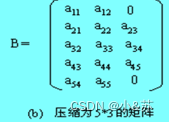
那么aij 映射为b i′j′,映射关系为:
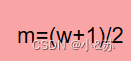 另一种压缩方法是将带状矩阵压缩到向量C中去,按以行为主序,顺序的存储其非零元素。如下图所示,按其压缩规律,找到相应的映象函数。
另一种压缩方法是将带状矩阵压缩到向量C中去,按以行为主序,顺序的存储其非零元素。如下图所示,按其压缩规律,找到相应的映象函数。
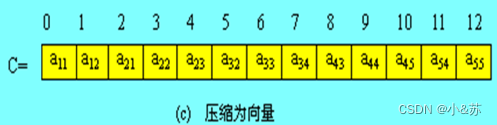
如当w=3时,映象函数为: k=2*i+j-3
5.3稀疏矩阵
5.3.1稀疏矩阵的三元组表存储
将三元组按行优先的顺序,同一行中列号从小到大的规律排列成一个线性表,称为三元组表,采用顺序存储方法存储该表。如图(a)稀疏矩阵对应的三元组表为图(b)。

三元组表存储定义:
#define SMAX 1024 /一个足够大的数/
typedef struct
{ int i,j; /非零元素的行、列/
datatype v; /非零元素值/
}SPNode; /三元组类型/
typedef struct
{ int mu,nu,tu; /矩阵的行、列及非零元素的个数/
SPNode data[SMAX]; /三元组表/
} SPMatrix; /三元组表的存储类型/
这样的存储方法确实节约了存储空间,但矩阵的运算从算法上可能变的复杂些。
1.稀疏矩阵的转置
设SPMatrix A; 表示一mn的稀疏矩阵,其转置B则是一个nm的稀疏矩阵,因此有 SPMatrix B; 。由A求B需:
⑴A的行、列转化成B的列、行;
⑵将A.data中每一三元组的行列交换后转到B.data中;

A的转置B如图(a)所示,图(b)是它对应的三元组存储。以上算法完成之后,并没有完成B。
算法思路:
①A的行、列转化成B的列、行;
②在A.data中依次找第一列的、第二列的、直到最后一列,并将找到的每个三元组的行、列交换后顺序存储到B.data中即可。
SPMatrix *TransM1(SPMatrix *A){
SPMatrix *B;
int p,q,col;
B=new SPMatrix;//申请存储空间
B->mu=A->nu;
B->nu=A->mu;
B->tu=A->tu;//稀疏矩阵的行、列、元素个数
if(B->tu>0)//有非零元素则转换
{
q=0;
for(col=1;col<=(A->nu);col++)//按A的列序转换
{
for(p=1;p<=(A->tu);p++)//扫描整个三元组
{
if(A->data[p].j==col)
{
B->data[q].i=A->data[p].j;
B->data[q].j=A->data[p].i;
B->data[q].v=A->data[p].v;
q++;
}
}
}
}
return B;//返回的是矩阵B的指针
}
分析该算法,其时间主要耗费在col和p的二重循环上,所以时间复杂性为O(n * t)。(设m、n是原矩阵的行、列,t是稀疏矩阵的非零元素个数),显然当非零元素的个数t和m* n同数量级时,算法的时间复杂度为O(m*n2),和通常存储方式下矩阵转置算法相比,可能节约了一定量的存储空间,但算法的时间性能更差一些。
上述算法效率低的原因是算法要从A的三元组表中寻找第一列、第二列、…,要反复搜索A表!
改进思想:若能直接确定A中每一三元组在B中的位置,则对A的三元组表扫描一次即可。
这是可以做到的! 因为A中第一列的第一个非零元素一定存储在B.data[1],如果还知道第一列的非零元素的个数,那么第二列的第一个非零元素在B.data中的位置便等于第一列的第一个非零元素在B.data中的位置加上第一列的非零元素的个数,如此类推,因为A中三元组的存放顺序是先行后列,对同一行来说,必定先遇到列号小的元素,这样只需扫描一遍A.data即可。
根据这个想法,需引入两个向量来实现 :
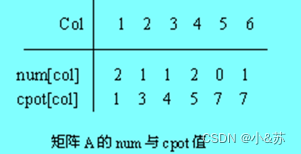
①num[n+1]和cpot[n+1],num[col]表示矩阵A中第col列的非零元素的个数(为了方便均从1单元用起)
②cpot[col]初始值表示矩阵A中的第col列的第一个非零元素在B.data中的位置。
于是cpot的初始值为:
cpot[1]=1;
cpot[col]=cpot[col-1]+num[col-1]; 2≤col≤n
例如 对于矩阵A的num 和cpot的值如下:
依次扫描A.data,当扫描到一个col列元素时,直接将其存放在B.data的cpot[col]位置上,cpot[col]加1.
cpot[col]中始终是下一个col列元素在B.data中的位置。
//改进的稀疏矩阵转置算法
SPMatrix *TransM2(SPMatrix *A){
SPMatrix *B;
int i,j,k;
int num[n+1],cpot[n+1];
B=new SPMatrix;//申请存储空间
B->mu=A->nu;
B->nu=A->mu;
B->tu=A->tu;//稀疏矩阵的行、列、元素个数
if(B->tu>0)//有非零元素则转换
{
for(i=1;i<=A->nu;i++) num[i]=0;
for(i=1;i<=A->tu;i++)
//求矩阵A中每一列非零元素的个数
{
j=A->data[i];
num[j]++;
}
cpot[1]=1;///求矩阵A中每一列第一个非零元素在B.data中的位置
for(i=2;i<A->nu;i++)
cpot[i]=cpoy[i-1]+num[i-1];
for(i=1;i<=A;i++)//扫描三元组元素
{
j=A->data[i].j//当前三元组的列号
k=cpot[j];//当前三元组在B.data中的位置
B->data[k].i=A->data[j];
B->data[k].j=A->data[i];
B->data[k].v=A->data[k].v;
cpoy[j]++;
}
}
return B;//返回的是转置矩阵的指针
}
时间复杂度分析:这个算法中有四个循环,分别执行n,t,n-1,t次,在每个循环中,每次迭代的时间是一常量,因此总的计算量是O(n+t)。当然它所需要的存储空间比前一个算法多了两个向量。
2.稀疏矩阵的乘积
已知稀疏矩阵A(m1× n1)和B(m2× n2),n1= m2,求乘积C(m1× n2)。稀疏矩阵A、B、C及它们对应的三元组表A.data、B.data、C.data如图所示。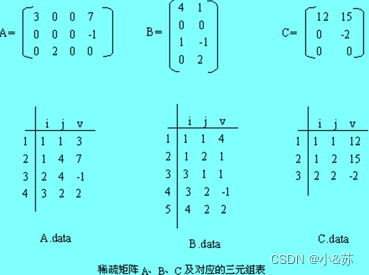
由矩阵乘法规则知:C(i,j)=A(i,1)×B(1,j)+A(i,2)×B(2,j)+…+A(i,n)×B(n,j)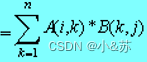
矩阵用二维数组表示时,传统的矩阵乘法是:A的第一行与B的第一列对应相乘累加后得到c11,A的第一行再与B的第二列对应相乘累加后得到c12,…。
然而,现在按三元组表存储,三元组表是按行为主序存储的,在B.data中,同一列的非零元素其三元组并未相邻存放,因此在B.data中反复搜索某一列的元素是很费时的,因此改变一下求值的顺序。
以求c11和c12为例,因为 :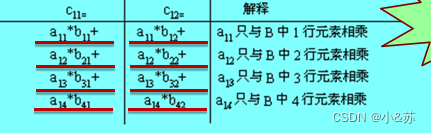
即a11只有可能和B中第1行的非零元素相乘,a12只有可能和B中第2行的非零元素相乘,…,而同一行的非零元是相邻存放的,所以求c11和c12同时进行。
求a11 * b11累加到c11,求a11 * b12累加到c12,再求a12 * b21累加到c11,再求a12*b22累加到c22.,…,当然只有aik和bkj(列号与行号相等)且均不为零(三元组存在)时才相乘,并且累加到cij当中去。
为了运算方便,设一个累加器:datatype temp[n+1];用来存放当前行中cij的值(n等于B的列数),当前行中所有元素全部算出之后,再存放到C.data中去。
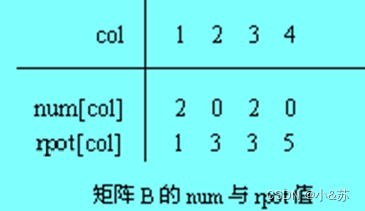
为了便于B.data中寻找B中的第k行第一个非零元素,在此需引入num和rpot两个向量。num[k]表示矩阵B中第k行的非零元素的个数;rpot[k]表示第k行的第一个非零元素在B.data中的位置。于是有:
rpot[1]=1
rpot[k]=rpot[k-1]+num[k-1] 2≤k≤n
例如,对于矩阵B的num和rpot如图所示。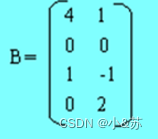
根据以上分析,稀疏矩阵的乘法运算的粗略步骤如下:
⑴初始化。清理一些单元,准备按行顺序存放乘积矩阵;
⑵求B的num,rpot;
⑶做矩阵乘法。将A.data中三元组的列值与B.data中三元组的行值相等的非零元素相乘,并将具有相同下标的乘积元素相加。
//稀疏矩阵的乘积算法
SPMatrix *MulSMatrix(SPMatrix *A,SPMatrix *B){
//稀疏矩阵A(m1*n1)和B(m2*n2) 用三元组表存储,求A*B
SPMatrix *C;//乘积矩阵的指针,通过函数返回值返回
int p,q,i,j,k,r;
DataType temp[n+1];
int num[B->nu+1],rpot[B->nu+1];//0号空间没用,符合表达习惯
if(A->nu!=B->mu) return NULL;
//A的列与B的行不相等,错误,返回空指针
C=new SPMatrix;//申请C矩阵的存储空间
C->mu=A->mu;
C->nu=B->nu;
if(A->tu*B->tu==0)
{
C->tu=0;
return c;//A、B均为零矩阵,C亦为零矩阵
}
for(i=1;i<=B->mu;i++) num[i]=0;//求矩阵B中每一行非零元素的个数
for(k=1;k<=B->tu;k++)
{
i=B->data[k].i;
num[i]++;
}
rpot[1]=1;//求矩阵B中每一行第一个非零元素在B.data中的位置
for(i=2;i<=B->mu;i++)
rpot[i]=rpot[i-1]+num[i-1];
r=0;//计数C中非零元素的个数
p=1;//指示A.data中当前非零元素的位置
for(i=1;i<=A->mu;i++)
{
for(j=1;j<=B->nu;j++) temp[j]=0;//cij的累加器的初始化
while(A->data[p].i==i)//求第i行的
{
k=A->data[p].j;//A中当前非零元素的列号
if(K<B->mu) t=rpot[k+1]-1;
else t=B->tu;//确定B.data中第k行最后一个非零元素的位置
for(q=rpot[k];q<=t;q++)//B中第k行的每一个非零元素
{
j=B->data[q].j;
temp[j]=temp[j]+A->data[p].v*B->data[q].v
}
p++;
}//while
for(j=1;j<=B->nu;j++)
if(temp[j])
{
r++;
C->data[r]={i,j,temp[j]};
}
}
C->tu=r;
return C;
}
分析上述算法的时间性能如下:
(1)求num的时间复杂度为O(B->nu+B->tu);
(2)求rpot 时间复杂度为O(B->mu);
(3)求temp时间复杂度为O(A->mu * B->nu);
(4)求C的所有非零元素的时间复杂度为O(A->tu*B->tu/B->mu);
(5)压缩存储时间复杂度为O(A->mu * B->nu);
所以,总的时间复杂度为O(A->mu * B->nu+(A->tu*B->tu)/B->nu)。
5.3.2稀疏矩阵的十字链表存储
三元组表可以看作稀疏矩阵顺序存储,但是在做一些操作(如加法、乘法)时,非零项数目及非零元素的位置会发生变化,这时这种表示就十分不便。
在这节中,我们介绍稀疏矩阵的一种链式存储结构——十字链表,它同样具备链式存储的特点,因此,在某些情况下,采用十字链表表示稀疏矩阵是很方便的。
下图是一个稀疏矩阵的十字链表。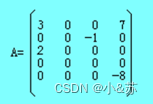
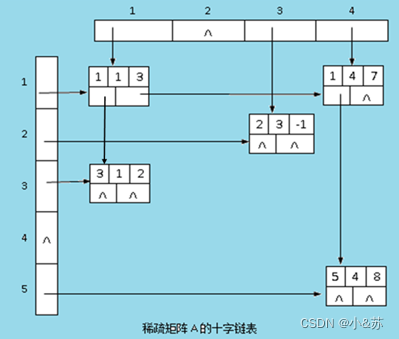
用十字链表表示稀疏矩阵的基本思想是:
对每个非零元素存储为一个结点,结点由5个域组成,其结构如图表示,其中:row域存储非零元素的行号,col域存储非零元素的列号,v域存储本元素的值,right,down是两个指针域。
结点的结构定义如下:
typedef struct node
{ int row, col;
datatype v;
struct node down , * right;
-
} MNode,*MLink;
5.4广义表
顾名思义,广义表是线性表的推广。也有人称其为列表(Lists,用复数形式以示与统称的表List的区别)。
5.4.1广义表的定义和基本运算
⒈广义表的定义和性质
线性表是由n个数据元素组成的有限序列。其中,每个组成元素被限定为单元素,有时这种限制需要拓宽。例如,中国举办的某体育项目国际邀请赛,参赛队清单可采用如下的表示形式:
(俄罗斯,巴西,(国家,河北,四川),古巴,美国,(),日本)
在这个拓宽了的线性表中,韩国队应排在美国队的后面,但由于某种原因未参加,成为空表。国家队、河北队、四川队均作为东道主的参赛队参加,构成一个小的线性表,成为原线性表的一个数据项。这种拓宽了的线性表就是广义表。
广义表(Generalized Lists)是n(n≥0)个数据元素a1,a2,…,ai,…,an的有序序列,一般记作:
ls=(a1,a2,…,ai,…,an)
其中:ls是广义表的名称,n是它的长度。每个ai(1≤i≤n)是ls的成员,它可以是单个元素,也可以是一个广义表,分别称为广义表ls的单元素和子表。当广义表ls非空时,称第一个元素a1为ls的表头(head),称其余元素组成的表(a2,…,ai,…,an)为ls的表尾(tail)。
显然,广义表的定义是递归的。
为书写清楚起见,通常用大写字母表示广义表,用小写字母表示单个数据元素,广义表用括号括起来,括号内的数据元素用逗号分隔开。
下面是一些广义表的例子:
A =()
B =(e)
C =(a,(b,c,d))
D =(A,B,C)
E =(a,E)
F =(())
广义表可以看成是线性表的推广,线性表是广义表的特例。
广义表的结构相当灵活,在某种前提下,它可以兼容线性表、数组、树和有向图等各种常用的数据结构。例如,当二维数组的每行(或每列)作为子表处理时,二维数组即为一个广义表。
另外,树和有向图也可以用广义表来表示。
由于广义表不仅集中了线性表、数组、树和有向图等常见数据结构的特点,而且可有效地利用存储空间,因此在计算机的许多应用领域都有成功使用广义表的实例。
⒉广义表的性质:
⑴广义表是一种多层次的数据结构。广义表的元素可以是单元素,也可以是子表,而子表的元素还可以是子表,…。
⑵广义表可以是递归的表。广义表的定义并没有限制元素的递归,即广义表也可以是其自身的子表。例如表E就是一个递归的表。
⑶广义表可以为其他表所共享。例如,表A、表B、表C是表D的共享子表。在D中可以不必列出子表的值,而用子表的名称来引用。
广义表的上述特性对于它的使用价值和应用效果起到了很大的作用。
⒊广义表基本运算
广义表有两个重要的基本操作,即取头操作(Head)和取尾操作(Tail)。
根据广义表的表头、表尾的定义可知,对于任意一个非空的列表,其表头可能是单元素也可能是列表,而表尾必为列表。例如:
Head(B)= e
Tail(B)=()
Head(C)= a
Tail(C)=((b,c,d))
Head(D)= A
Tail(D)=(B,C)
Head(E)= a
Tail(E)=(E)
Head(F)=()
Tail(F)=()
此外,在广义表上可以定义与线性表类似的一些操作,如建立、插入、删除、拆开、连接、复制、遍历等。
CreateLists(ls):根据广义表的书写形式创建一个广义表ls。
IsEmpty(ls):若广义表ls空,则返回True;否则返回False。
Length(ls):求广义表ls的长度。
Depth(ls):求广义表ls的深度。
Locate(ls,x):在广义表ls中查找数据元素x。
Merge(ls1,ls2):以ls1为头、ls2为尾建立广义表。
CopyGList(ls1,ls2):复制广义表,即按ls1建立广义表ls2。
Head(ls):返回广义表ls的头部。
Tail(ls):返回广义表的尾部。……
5.4.2广义表的存储
由于广义表中的数据元素可以具有不同的结构,因此难以用顺序的存储结构来表示。
而链式的存储结构分配较为灵活,易于解决广义表的共享与递归问题,所以通常都采用链式的存储结构来存储广义表。在这种表示方式下,每个数据元素可用一个结点表示。
按结点形式的不同,广义表的链式存储结构又可以分为不同的两种存储方式。一种称为头尾表示法,另一种称为孩子兄弟表示法。
⒈头尾表示法
若广义表不空,则可分解成表头和表尾;反之,一对确定的表头和表尾可惟一地确定一个广义表。头尾表示法就是根据这一性质设计而成的一种存储方法。
由于广义表中的数据元素既可能是列表也可能是单元素,相应地在头尾表示法中结点的结构形式有两种:一种是表结点,用以表示列表;另一种是元素结点,用以表示单元素。
在表结点中应该包括一个指向表头的指针和指向表尾的指针;而在元素结点中应该包括所表示单元素的元素值。为了区分这两类结点,在结点中还要设置一个标志域,如果标志为1,则表示该结点为表结点;如果标志为0,则表示该结点为元素结点。
其形式定义说明如下:
typedef enum {ATOM, LIST} Elemtag;
/ATOM=0:单元素;LIST=1:子表/
typedef struct GLNode {
Elemtag tag; /标志域,用于区分元素结点和表结点/
union { /元素结点和表结点的联合部分/
datatype data; /data是元素结点的值域/
struct {
struct GLNode *hp, *tp
}ptr; /ptr是表结点的指针域,ptr.hp和ptr.tp分别指向表头和表尾/
};
} * GList; /广义表类型/
头尾表示法的结点形式如图所示。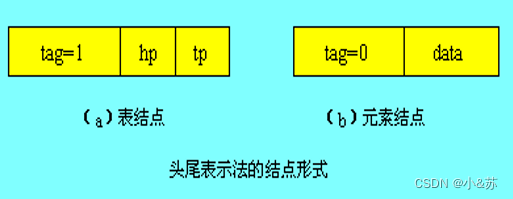
对于5.5.1所列举的广义表A、B、C、D、E、F,若采用头尾表示法的存储方式,其存储结构如下图所示。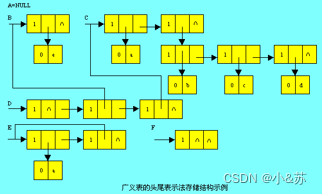

可以看出,采用头尾表示法容易分清列表中单元素或子表所在的层次。例如,在广义表D中,单元素a和e在同一层次上,而单元素b、c、d在同一层次上且比a和e低一层,子表B和C在同一层次上。另外,最高层的表结点的个数即为广义表的长度。例如,在广义表D的最高层有三个表结点,其广义表的长度为3。
⒉孩子兄弟表示法
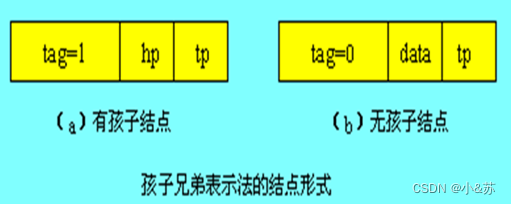
广义表的另一种表示法称为孩子兄弟表示法。在孩子兄弟表示法中,也有两种结点形式:一种是有孩子结点,用以表示列表;另一种是无孩子结点,用以表示单元素。
在有孩子结点中包括一个指向第一个孩子(长子)的指针和一个指向兄弟的指针;而在无孩子结点中包括该元素的元素值和一个指向兄弟的指针。
为了能区分这两类结点,在结点中还要设置一个标志域。如果标志为1,则表示该结点为有孩子结点;如果标志为0,则表示该结点为无孩子结点。
孩子兄弟表示法的结点形式如图所示。
其形式定义说明如下:
typedef enum {ATOM, LIST} Elemtag;
/ATOM=0:单元素;LIST=1:子表/
typedef struct GLENode {
Elemtag tag; /标志域,用于区分元素结点和表结点/
union { /元素结点和表结点的联合部分/
datatype data; /元素结点的值域/
struct GLENode * hp; /表结点的表头指针/
};
struct GLENode * tp; /指向下一个结点/
}* EGList; /广义表类型/
对于5.5.1节中所列举的广义表A、B、C、D、E、F,若采用孩子兄弟表示法的存储方式,其存储结构如图所示。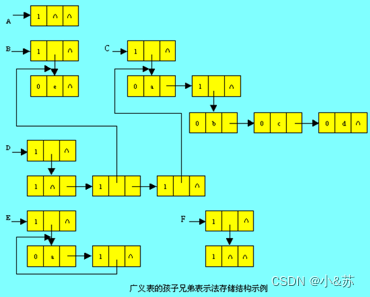
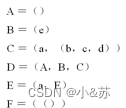

*5.5.3广义表基本操作的实现
我们以头尾表示法存储广义表,讨论广义表的有关操作的实现。由于广义表的定义是递归的,因此相应的算法一般也都是递归的。















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









