







目录
一、初识selenium
①selenium是基于浏览器自动化的一个模块,便捷的获取网站中动态加载的数据(之前文章中使用的ajax方法,很麻烦),便捷实现模拟登录(自动打开网页,进行一系列的点击操作)。
二、selenium使用前准备
①安装selenium
由于我使用的是anaconda,因此自带selenium。
②下载一个浏览器的驱动程序(谷歌浏览器)
下载路径:http://chromedriver.storage.googleapis.com/index.html
③关于版本选择的说明:
-
一般直接按照浏览器版本去找对应的driver就行了。
(如果不能一一对应,就找大版本号对应的或者比浏览器版本号稍大的都行) -
对于windows的用户来说,win64的操作系统用win32的即可。
-
所有Chromedriver均可在下面链接找到
④我的驱动版本
可以在谷歌浏览器中输入chrome://version/,查看浏览器版本

⑤将驱动器放置在代码文件中即可 ,稍后使用。
三、selenium的使用
1.实例化selenium对象
from selenium import webdriver
#实例化一个浏览器对象(传入浏览器的驱动成)
bro = webdriver.Chrome(executable_path='./chromedriver')2.编写基于浏览器自动化的操作代码
①发起请求
#让浏览器发起一个指定url对应请求
bro.get('http://scxk.nmpa.gov.cn:81/xk/')案例一完整代码:
需求:存储动态加载的信息
from selenium import webdriver
from lxml import etree
from time import sleep
#实例化一个浏览器对象(传入浏览器的驱动成)
bro = webdriver.Chrome(executable_path='./chromedriver')
#让浏览器发起一个指定url对应请求
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
#page_source获取浏览器当前页面的页面源码数据
page_text = bro.page_source
#解析企业名称
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@id="gzlist"]/li')
for li in li_list:
name = li.xpath('./dl/@title')[0]
print(name)
sleep(5)
bro.quit()
②标签定位
#标签定位,想在搜索框中输入关键词,需要定位到搜索框对应的标签
search_input = bro.find_element_by_id('q')③标签交互
可以点击、输入文本、控制滚轮等
#标签交互,在搜索框中输入内容
search_input.send_keys('Iphone')
#点击搜索按钮
btn = bro.find_element_by_css_selector('.btn-search')
btn.click()
#执行一组js程序,滚轮向下拖动
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')④执行js程序
#执行一组js程序,滚轮向下拖动
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')⑤前进,后退
#回退
bro.back()
#前进
bro.forward()⑥关闭浏览器
bro.quit()案例二完整代码:
需求:在淘宝搜索框中,输入“Iphone”,并点击搜索,然后使用滚轮向下滚动一屏的高度。(前提是登陆了淘宝,登录具体细节在其他文章中给出)
from selenium import webdriver
from lxml import etree
from time import sleep
#实例化一个浏览器对象(传入浏览器的驱动成)
bro = webdriver.Chrome(executable_path='./chromedriver')
#让浏览器发起一个指定url对应请求
bro.get('https://www.taobao.com/')
#标签定位
search_input = bro.find_element_by_id('q')
#标签交互
search_input.send_keys('Iphone')
#执行一组js程序
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
#点击搜索按钮
btn = bro.find_element_by_css_selector('.btn-search')
btn.click()
bro.get('https://www.baidu.com')
sleep(2)
#回退
bro.back()
sleep(2)
#前进
bro.forward()
sleep(5)
bro.quit()
四、动作链与iframe
iframe:在一个页面中,可以嵌套一个子页面,这样的操作可以使用iframe来实现。
案例需求:把下图方块拖动到指定位置

完整代码:
from selenium import webdriver
from time import sleep
#导入动作链对应的类
from selenium.webdriver import ActionChains
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
#如果定位的标签是存在于iframe标签之中的则必须通过如下操作在进行标签定位
bro.switch_to.frame('iframeResult')#切换浏览器标签定位的作用域
div = bro.find_element_by_id('draggable')
#动作链
action = ActionChains(bro)
#点击长按指定的标签
action.click_and_hold(div)
for i in range(5):
#perform()立即执行动作链操作
#move_by_offset(x,y):x水平方向 y竖直方向
action.move_by_offset(17,0).perform()
sleep(0.5)
#释放动作链
action.release()
# bro.quit()
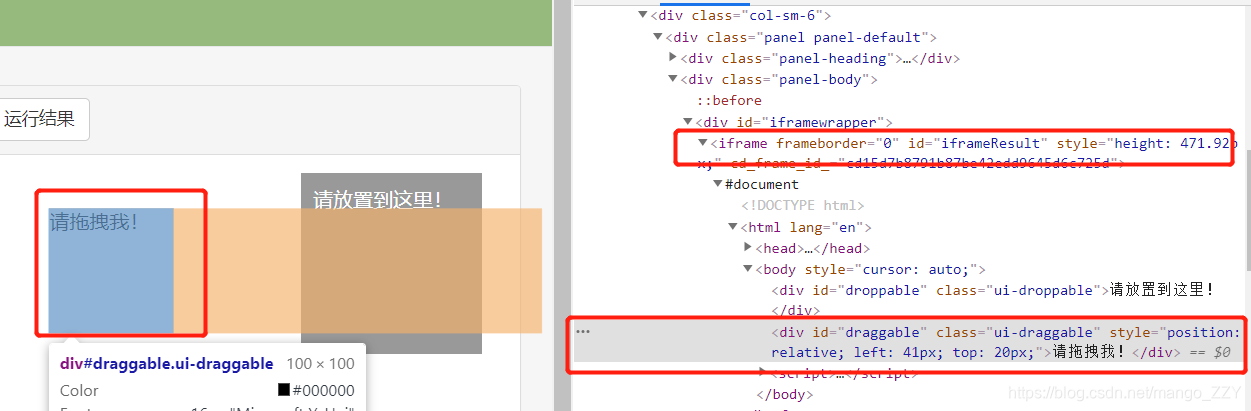
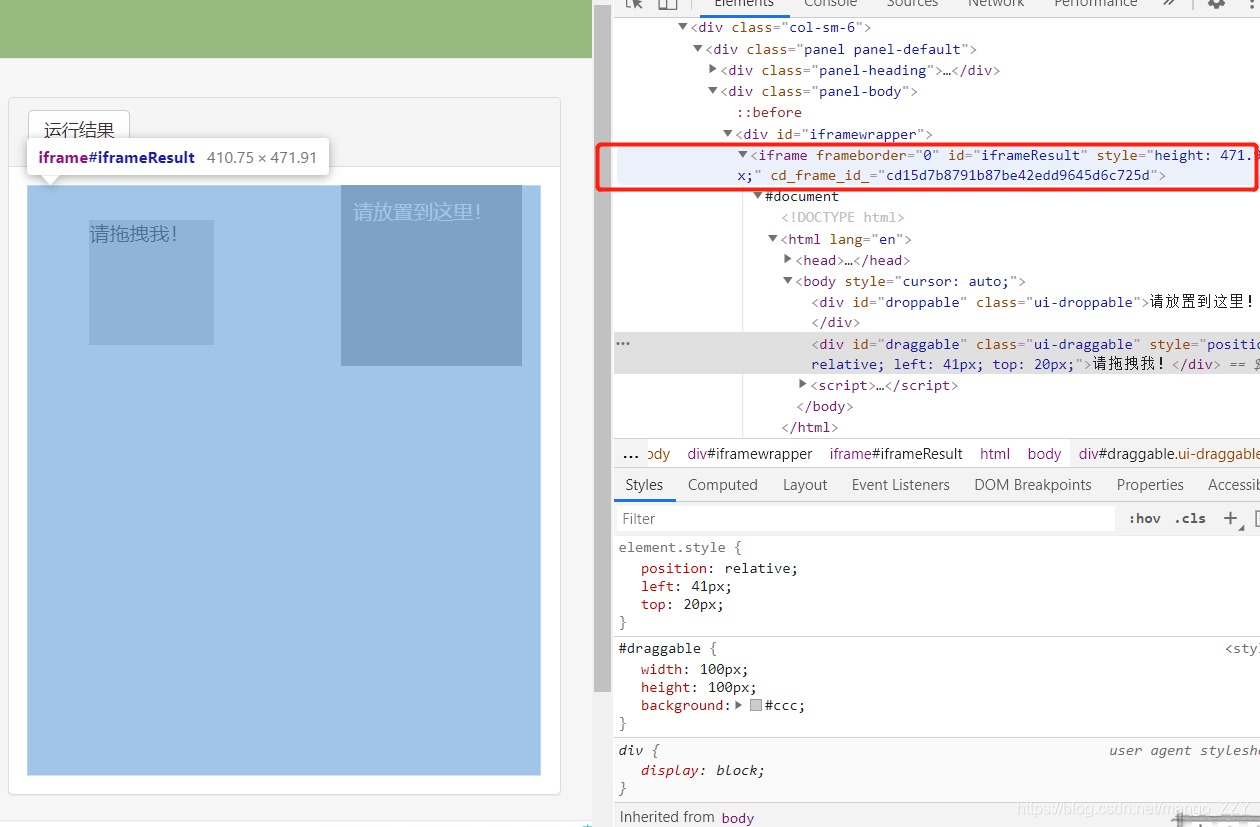
如上图所示,要挪动的方块被嵌套在当前网页的子页面中。如果定位的标签存在在iframe之中,必须用上述代码中的方法切换作用域,切换到指定的iframe中,否则会默认在全局作用域。
五、iframe总结
- 如果定位的标签存在于iframe标签之中,则必须使用switch_to.frame(id)
- 动作链(拖动):from selenium.webdriver import ActionChains
- 实例化一个动作链对象:action = ActionChains(bro)
- click_and_hold(div):长按且点击操作
- move_by_offset(x,y)
- perform()让动作链立即执行
- action.release()释放动作链对象
六、无头浏览和规避检测
1.无头浏览就是不弹出浏览器
2.如果selenium被检测到,会被拒绝爬取,这也是一种反爬手段。因此我们需要规避selenium检测。
以上两条不需要背下来,用的时候copy就行。
目前好像有了新的规避方法,等我用到我会更新,欢迎大家和我交流!
from selenium import webdriver
from time import sleep
# 实现无可视化界面
from selenium.webdriver.chrome.options import Options
# 实现规避检测
from selenium.webdriver import ChromeOptions
# 实现无可视化界面的操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 如何实现让selenium规避被检测到的风险
bro = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options,options=option)
# 无可视化界面(无头浏览器) phantomJs浏览器也可以,但是他已经停止更新维护了
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()














 3274
3274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









