







快速入门PyTorch
文章目录
什么是PyTorch
- 一个基于Python的机器学习框架
- 两个主要特点:
- 在GPUs上进行N维张量计算(如NumPy)
- 用于训练深度神经网络的自动微分
前置知识—tensors的基本使用
tensor是pytorch的基本数据结构,他是一个高维矩阵,类似数组(arrays)。

查看Tensors的维度
x.shape()

⚠️ PyTorch的dim(维度)等价于 NumPy中的axis(轴)
创建Tensors
直接从数据中获取(比如:list 或者 numpy.ndarray)
x = torch.tensor([[1, -1], [-1, 1]])
x = torch.from_numpy(np.array([[1, -1], [-1, 1]]))

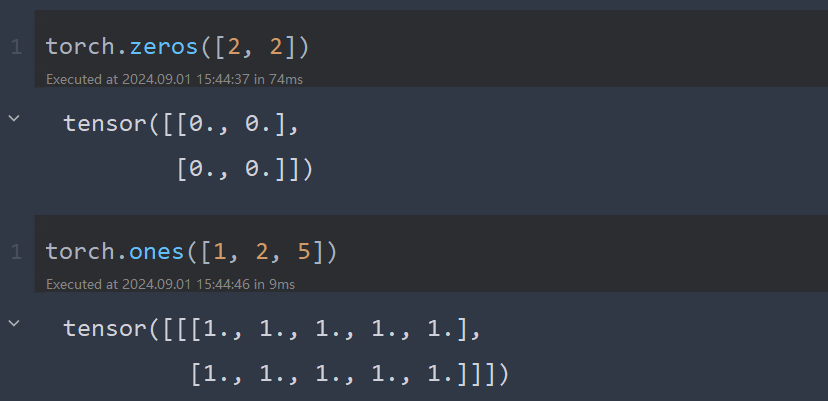
创建全是0或全是1的常数张量
x = torch.zeros([2, 2]) # [2, 2]指shape 第0维2列,第1维2列
x = torch.ones([1, 2, 5]) # [1, 2, 5]指shape 第0维1列,第1维2列,第2维5列
常用操作
支持常用的算术函数:
- 加法:
z = x + y - 减法:
z = x - y - 幂运算:
y = x.pow(2) - 求和:
y = x.sum() - 平均:
y = x.mean()
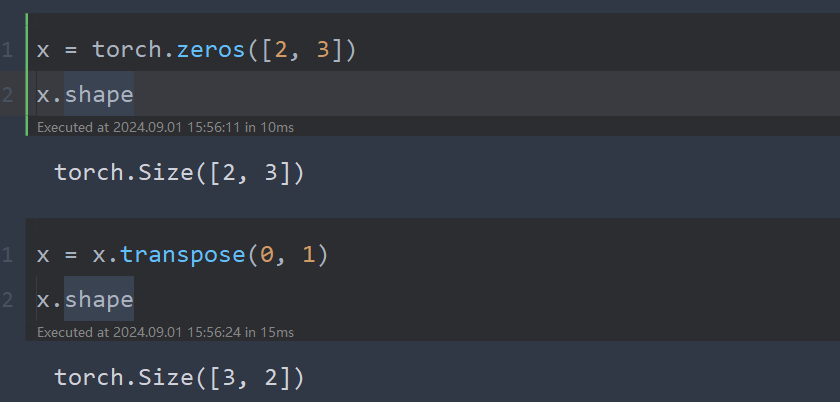
Transpose:将指定的两个维度转置:
x = torch.zeros([2, 3])
x.shape
x = x.transpose(0, 1)
x.shape

Squeeze:删除length = 1的指定维度
x = torch.zeros([1, 2, 3])
x.shape
x = x.squeeze(0) # dim = 0
x.shape


x = torch.zeros([2, 1, 3])
x.shape
x = x.squeeze(1) # dim = 1
x.shape

Unsqueeze:扩展一个维度
x = torch.zeros([2, 3])
x.shape
x = x.unsqueeze(1) # dim = 1
x.shape


x = torch.zeros([3, 2])
x.shape
x = x.unsqueeze(2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











