






深度学习分类模型训练代码模板
简介
参数模块
采用argparse模块进行配置,便于服务器上训练,以及超参数记录。在服务器上进行训练时,通常采用命令行启动,或时采用sh脚本批量训练,这时候就需要从命令行传入一些参数,用来调整模型超参。
采用了函数get_args_parser()实现,有了args,还可以将它记录到日志中,便于复现以及查看模型的超参数设置,便于跟踪。
def get_args_parser(add_help=True):
import argparse
parser = argparse.ArgumentParser(description="PyTorch Classification Training", add_help=add_help)
parser.add_argument("--data-path", default=r"E:\PyTorch-Tutorial-2nd\data\datasets\cifar10-office", type=str,
help="dataset path")
parser.add_argument("--model", default="resnet8", type=str, help="model name")
parser.add_argument("--device", default="cuda", type=str, help="device (Use cuda or cpu Default: cuda)")
parser.add_argument(
"-b", "--batch-size", default=128, type=int, help="images per gpu, the total batch size is $NGPU x batch_size"
)
parser.add_argument("--epochs", default=200, type=int, metavar="N", help="number of total epochs to run")
parser.add_argument(
"-j", "--workers", default=4, type=int, metavar="N", help="number of data loading workers (default: 16)"
)
parser.add_argument("--opt", default="sgd", type=str, help="optimizer")
parser.add_argument("--random-seed", default=42, type=int, help="random seed")
parser.add_argument("--lr", default=0.01, type=float, help="initial learning rate")
parser.add_argument("--momentum", default=0.9, type=float, metavar="M", help="momentum")
parser.add_argument(
"--wd",
"--weight-decay",
default=1e-4,
type=float,
metavar="W",
help="weight decay (default: 1e-4)",
dest="weight_decay",
)
parser.add_argument("--lr-step-size", default=80, type=int, help="decrease lr every step-size epochs")
parser.add_argument("--lr-gamma", default=0.1, type=float, help="decrease lr by a factor of lr-gamma")
parser.add_argument("--print-freq", default=80, type=int, help="print frequency")
parser.add_argument("--output-dir", default="./Result", type=str, help="path to save outputs")
parser.add_argument("--resume", default="", type=str, help="path of checkpoint")
parser.add_argument("--start-epoch", default=0, type=int, metavar="N", help="start epoch")
return parser
日志模块
logging模块记录文本信息.log文件。模型训练的日志很重要,它用于指导下一次实验的超参数如何调整。
采用借助logging模块构建一个logger,并且以时间戳(年月日-时分秒)的形式创建文件夹,便于日志管理。
在logger中使用logger.info函数代替print函数,可以实现在终端展示信息,还可以将其保存到日志文件夹下的log.log文件,便于溯源。
class Logger(object):
def __init__(self, path_log):
log_name = os.path.basename(path_log)
self.log_name = log_name if log_name else "root"
self.out_path = path_log
log_dir = os.path.dirname(self.out_path)
if not os.path.exists(log_dir):
os.makedirs(log_dir)
def init_logger(self):
logger = logging.getLogger(self.log_name)
logger.setLevel(level=logging.INFO)
# 配置文件Handler
file_handler = logging.FileHandler(self.out_path, 'w')
file_handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
# 配置屏幕Handler
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# console_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
# 添加handler
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
训练模块
训练模块封装为通用类——ModelTrainer。训练过程比较固定,因此会将其封装成 train_one_epoch和evaluate的两个函数,从这两个函数中需要返回我们关心的指标,如loss,accuracy,混淆矩阵等。
class ModelTrainer(object):
@staticmethod
def train_one_epoch(data_loader, model, loss_f, optimizer, scheduler, epoch_idx, device, args, logger, classes):
model.train()
end = time.time()
class_num = len(classes)
conf_mat = np.zeros((class_num, class_num))
loss_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
batch_time_m = AverageMeter()
last_idx = len(data_loader) - 1
for batch_idx, data in enumerate(data_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# forward & backward
outputs = model(inputs)
optimizer.zero_grad()
loss = loss_f(outputs.cpu(), labels.cpu())
loss.backward()
optimizer.step()
# 计算accuracy
acc1, acc5 = accuracy(outputs, labels, topk=(1, 5))
_, predicted = torch.max(outputs.data, 1)
for j in range(len(labels)):
cate_i = labels[j].cpu().numpy()
pre_i = predicted[j].cpu().numpy()
conf_mat[cate_i, pre_i] += 1.
# 记录指标
loss_m.update(loss.item(), inputs.size(0)) # 因update里: self.sum += val * n, 因此需要传入batch数量
top1_m.update(acc1.item(), outputs.size(0))
top5_m.update(acc5.item(), outputs.size(0))
# 打印训练信息
batch_time_m.update(time.time() - end)
end = time.time()
if batch_idx % args.print_freq == args.print_freq - 1:
logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
"train", batch_idx, last_idx, batch_time=batch_time_m,
loss=loss_m, top1=top1_m, top5=top5_m)) # val是当次传进去的值,avg是整体平均值。
return loss_m, top1_m, conf_mat
@staticmethod
def evaluate(data_loader, model, loss_f, device, classes):
model.eval()
class_num = len(classes)
conf_mat = np.zeros((class_num, class_num))
loss_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
for i, data in enumerate(data_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = loss_f(outputs.cpu(), labels.cpu())
# 计算accuracy
acc1, acc5 = accuracy(outputs, labels, topk=(1, 5))
_, predicted = torch.max(outputs.data, 1)
for j in range(len(labels)):
cate_i = labels[j].cpu().numpy()
pre_i = predicted[j].cpu().numpy()
conf_mat[cate_i, pre_i] += 1.
# 记录指标
loss_m.update(loss.item(), inputs.size(0)) # 因update里: self.sum += val * n, 因此需要传入batch数量
top1_m.update(acc1.item(), outputs.size(0))
top5_m.update(acc5.item(), outputs.size(0))
return loss_m, top1_m, conf_mat
指标统计模块
根据训练返回的指标进行loss、accuracy、混淆矩阵等指标的计算。通过tensorboard进行可视化展示。
class AverageMeter:
"""
Computes and stores the average and current value
Hacked from https://github.com/rwightman/pytorch-image-models/blob/master/timm/utils/metrics.py
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
完整代码
# -*- coding:utf-8 -*-
import os
import time
import datetime
import torchvision
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import torch
import torch.nn as nn
import my_utils as utils
def get_args_parser(add_help=True):
import argparse
parser = argparse.ArgumentParser(description="PyTorch Classification Training", add_help=add_help)
parser.add_argument("--data-path", default=r"E:\PyTorch-Tutorial-2nd\data\datasets\cifar10-office", type=str,
help="dataset path")
parser.add_argument("--model", default="resnet8", type=str, help="model name")
parser.add_argument("--device", default="cuda", type=str, help="device (Use cuda or cpu Default: cuda)")
parser.add_argument(
"-b", "--batch-size", default=128, type=int, help="images per gpu, the total batch size is $NGPU x batch_size"
)
parser.add_argument("--epochs", default=200, type=int, metavar="N", help="number of total epochs to run")
parser.add_argument(
"-j", "--workers", default=4, type=int, metavar="N", help="number of data loading workers (default: 16)"
)
parser.add_argument("--opt", default="sgd", type=str, help="optimizer")
parser.add_argument("--random-seed", default=42, type=int, help="random seed")
parser.add_argument("--lr", default=0.01, type=float, help="initial learning rate")
parser.add_argument("--momentum", default=0.9, type=float, metavar="M", help="momentum")
parser.add_argument(
"--wd",
"--weight-decay",
default=1e-4,
type=float,
metavar="W",
help="weight decay (default: 1e-4)",
dest="weight_decay",
)
parser.add_argument("--lr-step-size", default=80, type=int, help="decrease lr every step-size epochs")
parser.add_argument("--lr-gamma", default=0.1, type=float, help="decrease lr by a factor of lr-gamma")
parser.add_argument("--print-freq", default=80, type=int, help="print frequency")
parser.add_argument("--output-dir", default="./Result", type=str, help="path to save outputs")
parser.add_argument("--resume", default="", type=str, help="path of checkpoint")
parser.add_argument("--start-epoch", default=0, type=int, metavar="N", help="start epoch")
return parser
def main():
# 调用 get_args_parser() 函数获取 ArgumentParser 实例
# 然后调用 parse_args() 方法解析命令行参数
# 解析后的参数将作为命名空间对象返回,并将其存储在变量 args 中
# args 现在包含了所有通过命令行传递给程序的参数,可以通过属性访问,例如 args.parameter_name
args = get_args_parser().parse_args()
# 设置随机种子,确保模型可复现性
utils.setup_seed(args.random_seed)
args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = args.device
data_dir = args.data_path
result_dir = args.output_dir
# ------------------------------------ log ------------------------------------
logger, log_dir = utils.make_logger(result_dir)
writer = SummaryWriter(log_dir=log_dir)
# ------------------------------------ step1: dataset ------------------------------------
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
normTransform = transforms.Normalize(normMean, normStd)
train_transform = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
normTransform
])
valid_transform = transforms.Compose([
transforms.ToTensor(),
normTransform
])
# root变量下需要存放cifar-10-python.tar.gz 文件
# cifar-10-python.tar.gz可从 "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz" 下载
# 其他数据集可以自定义数据集处理方式
train_set = torchvision.datasets.CIFAR10(root=data_dir, train=True, transform=train_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root=data_dir, train=False, transform=valid_transform, download=True)
# 构建DataLoder
train_loader = DataLoader(dataset=train_set, batch_size=args.batch_size, shuffle=True, num_workers=args.workers)
valid_loader = DataLoader(dataset=test_set, batch_size=args.batch_size, num_workers=args.workers)
# ------------------------------------ tep2: model ------------------------------------
# 此处替换自己模型即可
model = utils.resnet8()
model.to(device)
# ------------------------------------ step3: optimizer, lr scheduler ------------------------------------
criterion = nn.CrossEntropyLoss() # 选择损失函数
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=args.lr_step_size,
gamma=args.lr_gamma) # 设置学习率下降策略
# ------------------------------------ step4: iteration ------------------------------------
best_acc, best_epoch = 0, 0
logger.info(f'args = {args}')
logger.info(f'train_loader = {train_loader}, valid_loader = {valid_loader}')
logger.info("Start training")
start_time = time.time()
epoch_time_m = utils.AverageMeter()
end = time.time()
for epoch in range(args.start_epoch, args.epochs):
# 训练
loss_m_train, acc_m_train, mat_train = \
utils.ModelTrainer.train_one_epoch(train_loader, model, criterion, optimizer, scheduler,
epoch, device, args, logger, classes)
# 验证
loss_m_valid, acc_m_valid, mat_valid = \
utils.ModelTrainer.evaluate(valid_loader, model, criterion, device, classes)
epoch_time_m.update(time.time() - end)
end = time.time()
logger.info(
'Epoch: [{:0>3}/{:0>3}] '
'Time: {epoch_time.val:.3f} ({epoch_time.avg:.3f}) '
'Train Loss avg: {loss_train.avg:>6.4f} '
'Valid Loss avg: {loss_valid.avg:>6.4f} '
'Train Acc@1 avg: {top1_train.avg:>7.4f} '
'Valid Acc@1 avg: {top1_valid.avg:>7.4f} '
'LR: {lr}'.format(
epoch, args.epochs, epoch_time=epoch_time_m, loss_train=loss_m_train, loss_valid=loss_m_valid,
top1_train=acc_m_train, top1_valid=acc_m_valid, lr=scheduler.get_last_lr()[0]))
# 学习率更新
scheduler.step()
# 记录
writer.add_scalars('Loss_group', {'train_loss': loss_m_train.avg,
'valid_loss': loss_m_valid.avg}, epoch)
writer.add_scalars('Accuracy_group', {'train_acc': acc_m_train.avg,
'valid_acc': acc_m_valid.avg}, epoch)
conf_mat_figure_train = utils.show_conf_mat(mat_train, classes, "train", log_dir, epoch=epoch,
verbose=epoch == args.epochs - 1, save=False)
conf_mat_figure_valid = utils.show_conf_mat(mat_valid, classes, "valid", log_dir, epoch=epoch,
verbose=epoch == args.epochs - 1, save=False)
writer.add_figure('confusion_matrix_train', conf_mat_figure_train, global_step=epoch)
writer.add_figure('confusion_matrix_valid', conf_mat_figure_valid, global_step=epoch)
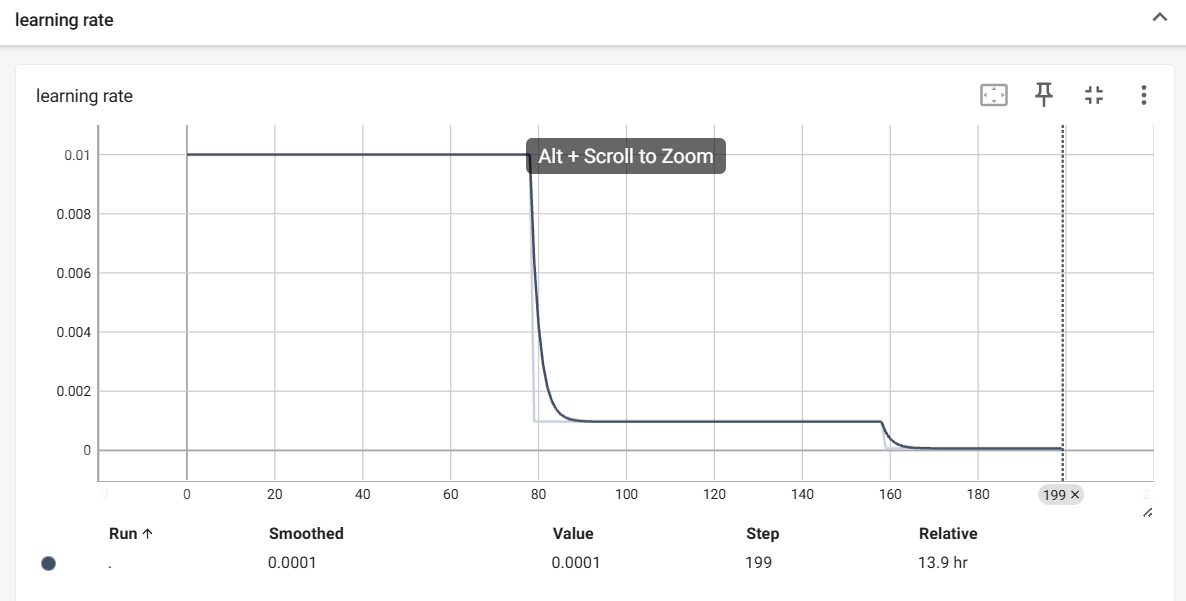
writer.add_scalar('learning rate', scheduler.get_last_lr()[0], epoch)
# ------------------------------------ 模型保存 ------------------------------------
if best_acc < acc_m_valid.avg or epoch == args.epochs - 1:
best_epoch = epoch if best_acc < acc_m_valid.avg else best_epoch
best_acc = acc_m_valid.avg if best_acc < acc_m_valid.avg else best_acc
checkpoint = {
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"lr_scheduler_state_dict": scheduler.state_dict(),
"epoch": epoch,
"args": args,
"best_acc": best_acc}
pkl_name = "checkpoint_{}.pth".format(epoch) if epoch == args.epochs - 1 else "checkpoint_best.pth"
path_checkpoint = os.path.join(log_dir, pkl_name)
torch.save(checkpoint, path_checkpoint)
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
logger.info("Training time {}".format(total_time_str))
# 切换自己数据集的分类
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
if __name__ == "__main__":
main()
my_utils.py
# -*- coding:utf-8 -*-
import random
import numpy as np
import os
import time
import torchmetrics
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as init
from datetime import datetime
import logging
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(400, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 400)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def _weights_init(m):
classname = m.__class__.__name__
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight)
class LambdaLayer(nn.Module):
def __init__(self, lambd):
super(LambdaLayer, self).__init__()
self.lambd = lambd
def forward(self, x):
return self.lambd(x)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1, option='A'):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
if option == 'A':
"""
For CIFAR10 ResNet paper uses option A.
"""
self.shortcut = LambdaLayer(lambda x:
F.pad(x[:, :, ::2, ::2], (0, 0, 0, 0, planes // 4, planes // 4), "constant",
0))
elif option == 'B':
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
"""
https://github.com/akamaster/pytorch_resnet_cifar10/blob/master/resnet.py
"""
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1) # 原版16
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2) # 原版32
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2) # 原版64
self.linear = nn.Linear(64, num_classes)
self.apply(_weights_init)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, out.size()[3])
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def resnet8(num_classes=10):
return ResNet(BasicBlock, [1, 1, 1], num_classes)
def resnet20():
"""
https://github.com/akamaster/pytorch_resnet_cifar10/blob/master/resnet.py
"""
return ResNet(BasicBlock, [3, 3, 3])
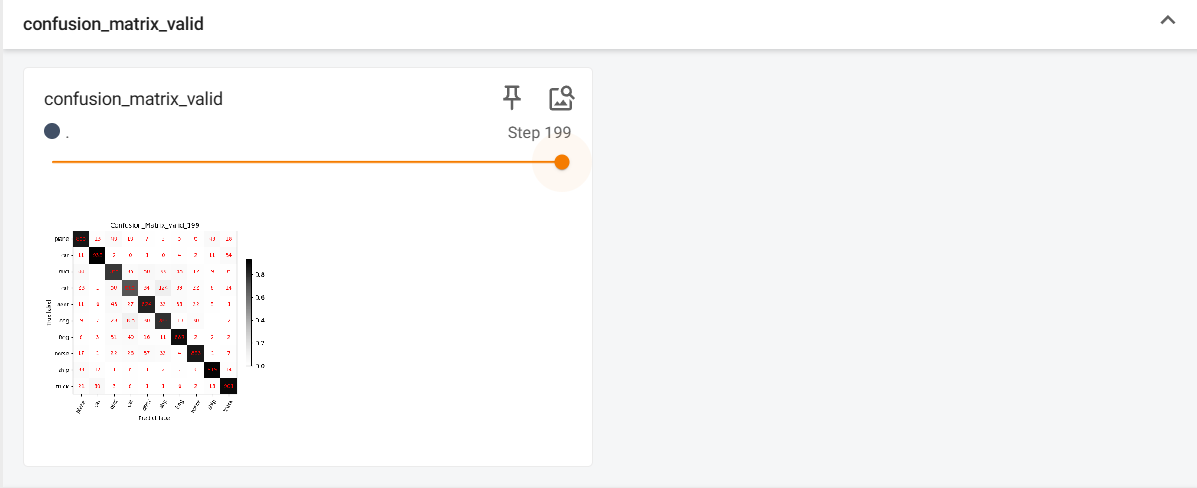
def show_conf_mat(confusion_mat, classes, set_name, out_dir, epoch=999, verbose=False, perc=False, save=True):
"""
混淆矩阵绘制并保存图片
:param confusion_mat: nd.array
:param classes: list or tuple, 类别名称
:param set_name: str, 数据集名称 train or valid or test?
:param out_dir: str, 图片要保存的文件夹
:param epoch: int, 第几个epoch
:param verbose: bool, 是否打印精度信息
:param perc: bool, 是否采用百分比,图像分割时用,因分类数目过大
:return:
"""
cls_num = len(classes)
# 归一化
confusion_mat_tmp = confusion_mat.copy()
for i in range(len(classes)):
confusion_mat_tmp[i, :] = confusion_mat[i, :] / confusion_mat[i, :].sum()
# 设置图像大小
if cls_num < 10:
figsize = 6
elif cls_num >= 100:
figsize = 30
else:
figsize = np.linspace(6, 30, 91)[cls_num - 10]
fig, ax = plt.subplots(figsize=(int(figsize), int(figsize * 1.3)))
# 获取颜色
cmap = plt.cm.get_cmap('Greys') # 更多颜色: http://matplotlib.org/examples/color/colormaps_reference.html
plt_object = ax.imshow(confusion_mat_tmp, cmap=cmap)
cbar = plt.colorbar(plt_object, ax=ax, fraction=0.03)
cbar.ax.tick_params(labelsize='12')
# 设置文字
xlocations = np.array(range(len(classes)))
ax.set_xticks(xlocations)
ax.set_xticklabels(list(classes), rotation=60) # , fontsize='small'
ax.set_yticks(xlocations)
ax.set_yticklabels(list(classes))
ax.set_xlabel('Predict label')
ax.set_ylabel('True label')
ax.set_title("Confusion_Matrix_{}_{}".format(set_name, epoch))
# 打印数字
if perc:
cls_per_nums = confusion_mat.sum(axis=0)
conf_mat_per = confusion_mat / cls_per_nums
for i in range(confusion_mat_tmp.shape[0]):
for j in range(confusion_mat_tmp.shape[1]):
ax.text(x=j, y=i, s="{:.0%}".format(conf_mat_per[i, j]), va='center', ha='center', color='red',
fontsize=10)
else:
for i in range(confusion_mat_tmp.shape[0]):
for j in range(confusion_mat_tmp.shape[1]):
ax.text(x=j, y=i, s=int(confusion_mat[i, j]), va='center', ha='center', color='red', fontsize=10)
# 保存
if save:
fig.savefig(os.path.join(out_dir, "Confusion_Matrix_{}.png".format(set_name)))
plt.close()
if verbose:
for i in range(cls_num):
print('class:{:<10}, total num:{:<6}, correct num:{:<5} Recall: {:.2%} Precision: {:.2%}'.format(
classes[i], np.sum(confusion_mat[i, :]), confusion_mat[i, i],
confusion_mat[i, i] / (1e-9 + np.sum(confusion_mat[i, :])),
confusion_mat[i, i] / (1e-9 + np.sum(confusion_mat[:, i]))))
return fig
class ModelTrainer(object):
@staticmethod
def train_one_epoch(data_loader, model, loss_f, optimizer, scheduler, epoch_idx, device, args, logger, classes):
model.train()
end = time.time()
class_num = len(classes)
conf_mat = np.zeros((class_num, class_num))
loss_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
batch_time_m = AverageMeter()
last_idx = len(data_loader) - 1
for batch_idx, data in enumerate(data_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# forward & backward
outputs = model(inputs)
optimizer.zero_grad()
loss = loss_f(outputs.cpu(), labels.cpu())
loss.backward()
optimizer.step()
# 计算accuracy
acc1, acc5 = accuracy(outputs, labels, topk=(1, 5))
_, predicted = torch.max(outputs.data, 1)
for j in range(len(labels)):
cate_i = labels[j].cpu().numpy()
pre_i = predicted[j].cpu().numpy()
conf_mat[cate_i, pre_i] += 1.
# 记录指标
loss_m.update(loss.item(), inputs.size(0)) # 因update里: self.sum += val * n, 因此需要传入batch数量
top1_m.update(acc1.item(), outputs.size(0))
top5_m.update(acc5.item(), outputs.size(0))
# 打印训练信息
batch_time_m.update(time.time() - end)
end = time.time()
if batch_idx % args.print_freq == args.print_freq - 1:
logger.info(
'{0}: [{1:>4d}/{2}] '
'Time: {batch_time.val:.3f} ({batch_time.avg:.3f}) '
'Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) '
'Acc@1: {top1.val:>7.4f} ({top1.avg:>7.4f}) '
'Acc@5: {top5.val:>7.4f} ({top5.avg:>7.4f})'.format(
"train", batch_idx, last_idx, batch_time=batch_time_m,
loss=loss_m, top1=top1_m, top5=top5_m)) # val是当次传进去的值,avg是整体平均值。
return loss_m, top1_m, conf_mat
@staticmethod
def evaluate(data_loader, model, loss_f, device, classes):
model.eval()
class_num = len(classes)
conf_mat = np.zeros((class_num, class_num))
loss_m = AverageMeter()
top1_m = AverageMeter()
top5_m = AverageMeter()
for i, data in enumerate(data_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = loss_f(outputs.cpu(), labels.cpu())
# 计算accuracy
acc1, acc5 = accuracy(outputs, labels, topk=(1, 5))
_, predicted = torch.max(outputs.data, 1)
for j in range(len(labels)):
cate_i = labels[j].cpu().numpy()
pre_i = predicted[j].cpu().numpy()
conf_mat[cate_i, pre_i] += 1.
# 记录指标
loss_m.update(loss.item(), inputs.size(0)) # 因update里: self.sum += val * n, 因此需要传入batch数量
top1_m.update(acc1.item(), outputs.size(0))
top5_m.update(acc5.item(), outputs.size(0))
return loss_m, top1_m, conf_mat
class ModelTrainerEnsemble(ModelTrainer):
@staticmethod
def average(outputs):
"""Compute the average over a list of tensors with the same size."""
return sum(outputs) / len(outputs)
@staticmethod
def evaluate(data_loader, models, loss_f, device, classes):
class_num = len(classes)
conf_mat = np.zeros((class_num, class_num))
loss_m = AverageMeter()
# task类型与任务一致
# num_classes与分类任务的类别数一致
top1_m = torchmetrics.Accuracy(task="multiclass", num_classes=class_num).to(device)
# top1 acc group
top1_group = []
for model_idx in range(len(models)):
# task类型与任务一致
# num_classes与分类任务的类别数一致
top1_group.append(torchmetrics.Accuracy(task="multiclass", num_classes=class_num).to(device))
for i, data in enumerate(data_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = []
for model_idx, model in enumerate(models):
output_single = F.softmax(model(inputs), dim=1)
outputs.append(output_single)
# 计算单个模型acc
top1_group[model_idx](output_single, labels)
# 计算单个模型loss
# 计算acc 组
output_avg = ModelTrainerEnsemble.average(outputs)
top1_m(output_avg, labels)
# loss 组
loss = loss_f(output_avg.cpu(), labels.cpu())
loss_m.update(loss.item(), inputs.size(0))
return loss_m, top1_m.compute(), top1_group, conf_mat
class Logger(object):
def __init__(self, path_log):
log_name = os.path.basename(path_log)
self.log_name = log_name if log_name else "root"
self.out_path = path_log
log_dir = os.path.dirname(self.out_path)
if not os.path.exists(log_dir):
os.makedirs(log_dir)
def init_logger(self):
logger = logging.getLogger(self.log_name)
logger.setLevel(level=logging.INFO)
# 配置文件Handler
file_handler = logging.FileHandler(self.out_path, 'w')
file_handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
# 配置屏幕Handler
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# console_handler.setFormatter(logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
# 添加handler
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
def make_logger(out_dir):
"""
在out_dir文件夹下以当前时间命名,创建日志文件夹,并创建logger用于记录信息
:param out_dir: str
:return:
"""
now_time = datetime.now()
time_str = datetime.strftime(now_time, '%Y-%m-%d_%H-%M-%S')
log_dir = os.path.join(out_dir, time_str) # 根据config中的创建时间作为文件夹名
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 创建logger
path_log = os.path.join(log_dir, "log.log")
logger = Logger(path_log)
logger = logger.init_logger()
return logger, log_dir
def setup_seed(seed=42):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed) # cpu
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True # 训练集变化不大时使训练加速,是固定cudnn最优配置,如卷积算法
class AverageMeter:
"""
Computes and stores the average and current value
Hacked from https://github.com/rwightman/pytorch-image-models/blob/master/timm/utils/metrics.py
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""
Computes the accuracy over the k top predictions for the specified values of k
Hacked from https://github.com/rwightman/pytorch-image-models/blob/master/timm/utils/metrics.py
"""
maxk = min(max(topk), output.size()[1])
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.reshape(1, -1).expand_as(pred))
return [correct[:min(k, maxk)].reshape(-1).float().sum(0) * 100. / batch_size for k in topk]
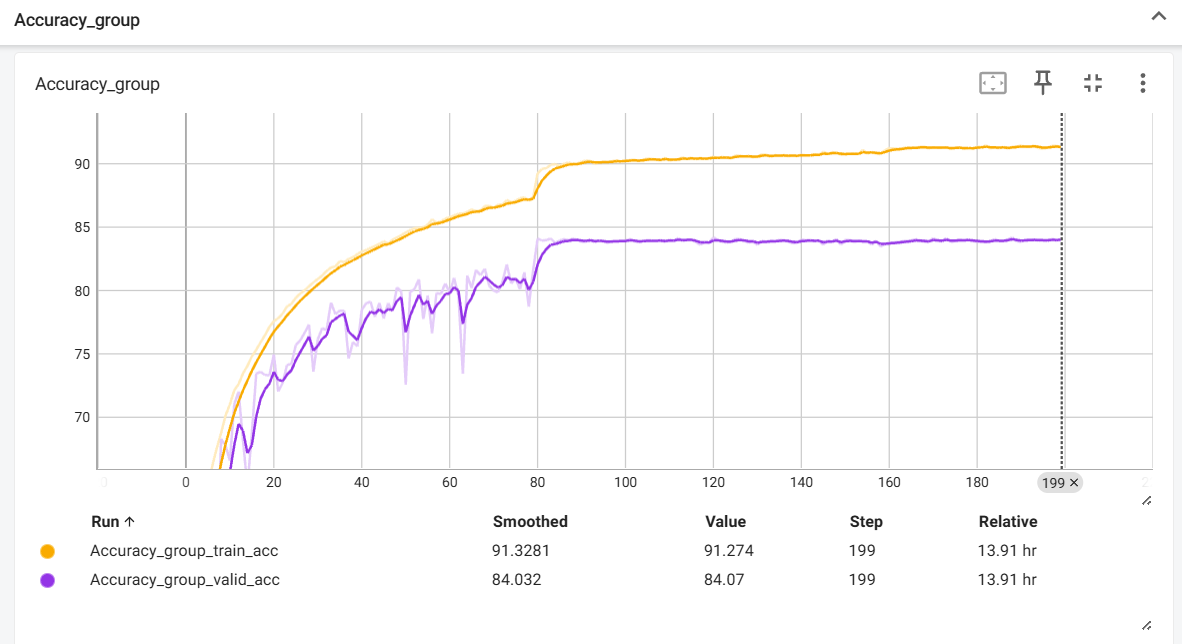
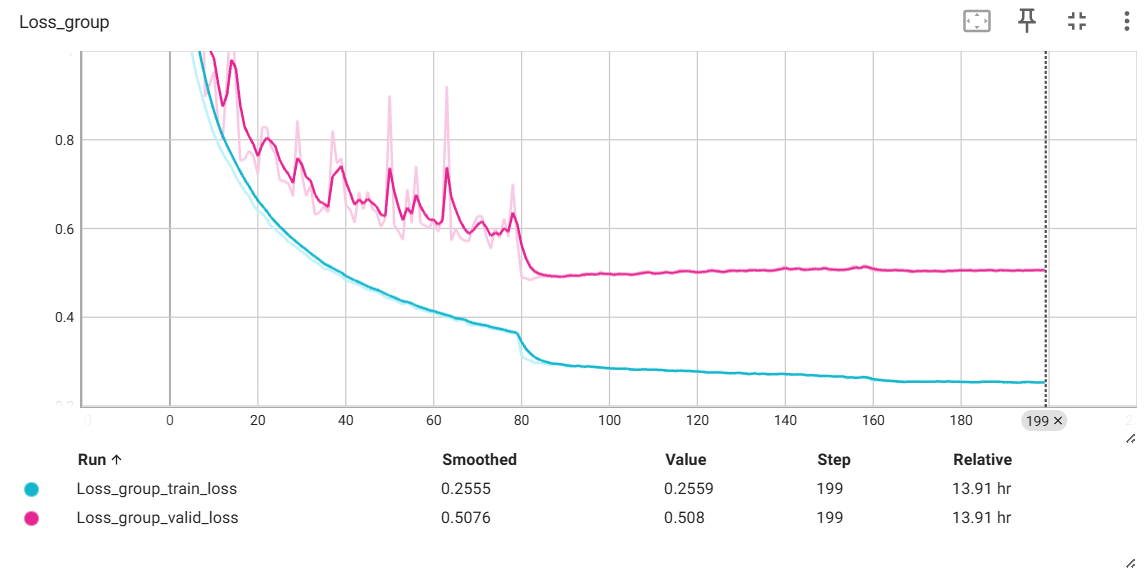
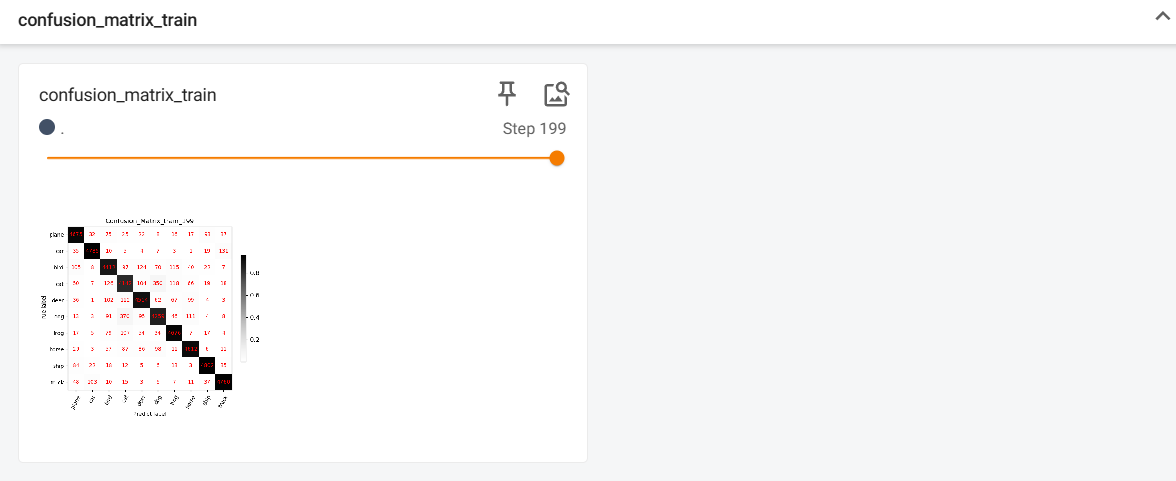
效果图


















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











