







1.基础—朴素算法
在学习KMP算法之前,一定要先学会朴素算法,KMP算法就是对此算法的改进
上代码:
定义一个该串的结构体:
- 串从data[1]开始,data[0]不用,该数组的下标就是字符的位置
- length代表该串的长度
朴素算法
思路:
拿子串跟主串从头一个一个的开始比 ,
- 如果当前相同,则主串下一个位置跟子串下一个位置比较
- 如果当前位置不相同,则子串从头开始(j==1)跟主串的下一个位置比较
该算法有个缺点:
如果当前位置不相同,则子串从头开始(j==1)跟主串的下一个位置比较
重复步骤太多
举个例子:
主串:abab??????????
子串:ababb
当子串比到五个位置发现不符合,按照朴素算法主串要回到第二个位置,而子串要回到第一个位置比较。
但实际上:
我们可以直接将主串的第五个位置与子串的第三个位置比较,这样相对朴素算法,节省了很多步骤,这就是KMP算法做的事
KMP算法:
接着上面的讨论,KMP的核心就是
求出next[]
- 作用:当j=next[j],可以让主串在子串的第j个位置失配后,移动子串到最近的位置重新比较,如果不成功,重复j=next[j],直到匹配成功或者全部不匹配
- 即一直重复j=next[j] 直到 ch[i]==ch[j] 或 j==0(全部不相等,主串子串自动到下一个比较);
- 好处:避免了失配后,子串需要一律回到第一个位置,减少了许多的重复操作
在此之前,我们先要有如下概念:
前缀,后缀,共同前后缀
举个例子:字符串:a b a b a
- 前缀(a,ab,aba,abab,ababa)
- 后缀(a,ba,aba,abab,ababa)
- 共同前后缀:aba
有什么用呢?
主串: a b a b a ?????? (后缀)
子串: a b a b a x x x (前缀)
(PS:某个位置失配,我们是能确定主串某个位置之前的元素)
(PS:x代表未知元素,方便举例子,不必太过关系)
当第六个位置不匹配的时候,子串向右滑动,子串与主串重合的部分就是该已知的串它们前缀后缀共同的字符串,aba对不对?
然后重点:我们就可以将前缀aba 后面的b与第五个位置比较
这样可以表示为: next[6]=4
意思是:主串与子串比到第六个位置不匹配,子串移动到第四个位置重新比较
得出一个重要的结论:相同的前后缀,决定子串移动到哪个位置,
用i表示主串与子串匹配到的位置,j表示子串的位置
则next[i] = j;
当我们移动合适的位置,如果我们要进行进行下一个位置的判断,它们的共同前后缀会发生改变,例如这样
主串: a b a b a b????? (后缀)
子串: a b a b a b x (前缀)
我们刚才得出了第六个位置不匹配子串移动的情况,现在我们要判断第七个位置不匹配的情况,
那么我们就可以确定第六个元素,主串蓝色部分的元素为b,子串蓝色部分也为b,
那么它们的前后缀由原来的(a,b,a)变成了现在的(a,b,a,b),它的共同前后缀长度加一,
即 7=next[5] (主串与子串第七个位置失配,将子串移动到第五个位置)
这个过程用代码表示就是:
if(ch[i]==ch[j]){
i++;j++;next[i]=j
}
刚才是蓝色部分相同的情况,那假如蓝色不相同呢,它的共同前后缀会发生什么变化,我们该如何操作呢?
如下:当主串蓝色部分为a,子串蓝色部分为b
主串: a b a b a a ???? (后缀)
子串: a b a b a a (前缀)
那么它们的共同前后缀将不在按顺序增加,所以我们就要另外讨论,我们不难看出它们的共同前后缀为(a),那么第主串第七个位置,应该与第二个位置比较,即a[7]=2,
但是计算机可不会一眼就看出来,它只能一步一步的计算,
所以我们该采取怎样的操作,这一步操作也正是KMP算法中最难理解的一步。
其实类似与比较未知位置子串失配的问题,只不过这次是比较已知的蓝色部分位置,
我们做的就是让前缀的元素与蓝色部分相等,或者全部不相等为止
即一直重复j=next[j] 直到 ch[i]==ch[j] 或 j=0(全部不相等,主串子串自动到下一个比较);
我们采取的方法是将先单独考虑这个部分;
后缀: a b a a
前缀: a b a b
这是第四个位置前缀与后缀元素不相等(j==4),我们再采取 j = next[j] 的策略 ,找出它们的共同前后缀,然后比较蓝色部分,直到蓝色部分相等或者确定该位置与子串任何元素都不相同
第一次移动如下
后缀: a b a a
前缀: a b a b
如果相同,则执行
if(ch[i]==ch[j]){
i++;j++;next[i]=j
}操作
如不同,显然这里是不同的,我们就要再继续上面的操作,再比较,直到蓝色部分相等或者确定该位置与子串任何元素都不相同
后缀: a a
前缀: a b
这是第二个位置失配(j==2),我们再进行 j=next[j]操作,而这里next[2]=1,所以子串从第一个位置与蓝色部分比较
ps:next[1]=0,next[2]=1,为固定值,任何字符串都适用,具体的大家可以自己推倒一下。
新的结果如下
后缀: a a
前缀: a b
终于,前缀与后缀相同,圆满完成此任务
执行
if(ch[i]==ch[j]){
i++;j++;next[i]=j
}操作
以上便是KMP算法的核心操作
求next[]实现代码如下:
KMP实现代码:
在朴素算法的基础上增加了一些变动
KMP算法还不是算太完美的,还可以稍微改进
举个例子
主串: a b a b ??????
子串: a b a b a x x x
当我们匹配都第五个位置,子串a与主串匹配失败时,我们执行 j= next[j] 的操作,我们会发现
主串: a b a b ??????
子串: a b a b a x x x
依旧是 a 与主串比较,显然结果也是一样,步骤略显多余,我们还要再求一次j=next[j]那么我们是否可以省去类似这样的步骤,
我们的解决办法如下,定义nextval[]数组
先进行这样的判断
if(ch[j]==ch[next[j]])
如果相同
nextVal[j] = nextVal[next[j]];(直接跳到相等元素位置失配的情况下)
否则
nextVal[j]=next[j];不做改变
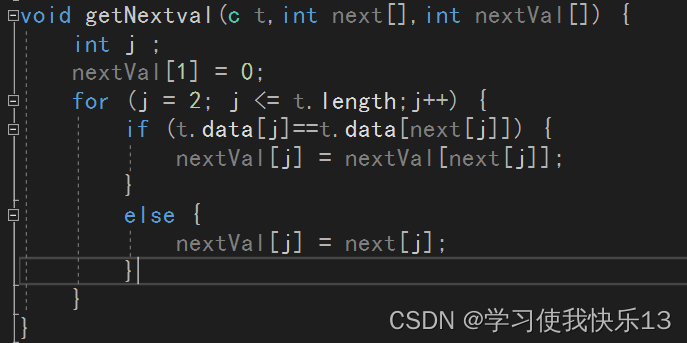
求nextVal[]代码如下:
改进的KMP算法:
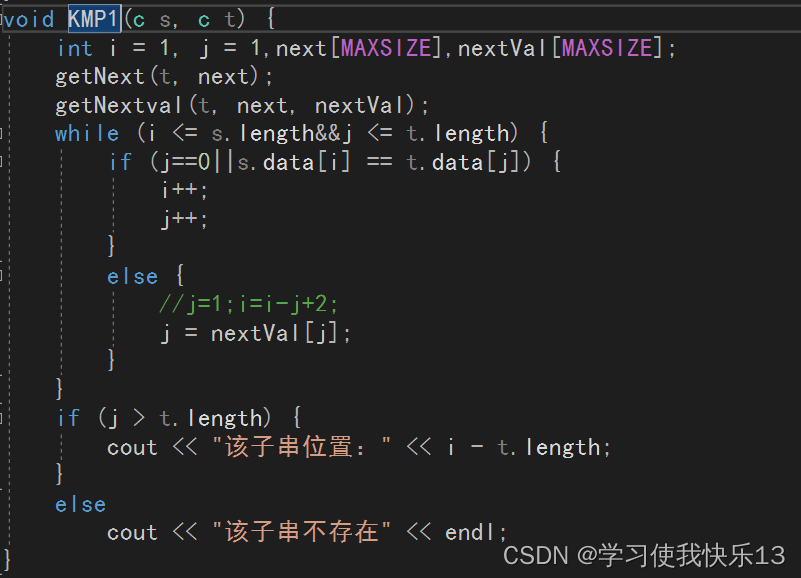
全部代码如下
#include<iostream>
#include<string>
using namespace std;
#define MAXSIZE 100
typedef char ElemType;
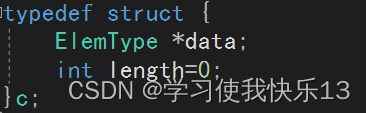
typedef struct {
ElemType *data;
int length=0;
}c;
void input(c &t) {
ElemType x;
int i=1;
cout << "请输入一组字符以‘回车’结束" <<endl;
t.data = new ElemType[MAXSIZE];
while( (x=cin.get())!= '\n'){
t.data[i++] = x;;
t.length++;
}
}
void print(c t) {
int i=1;
while (i <= t.length) {
cout << t.data[i++];
}
}
void length(c t) {
cout << "该字符串的长度为:" << t.length << endl;
}
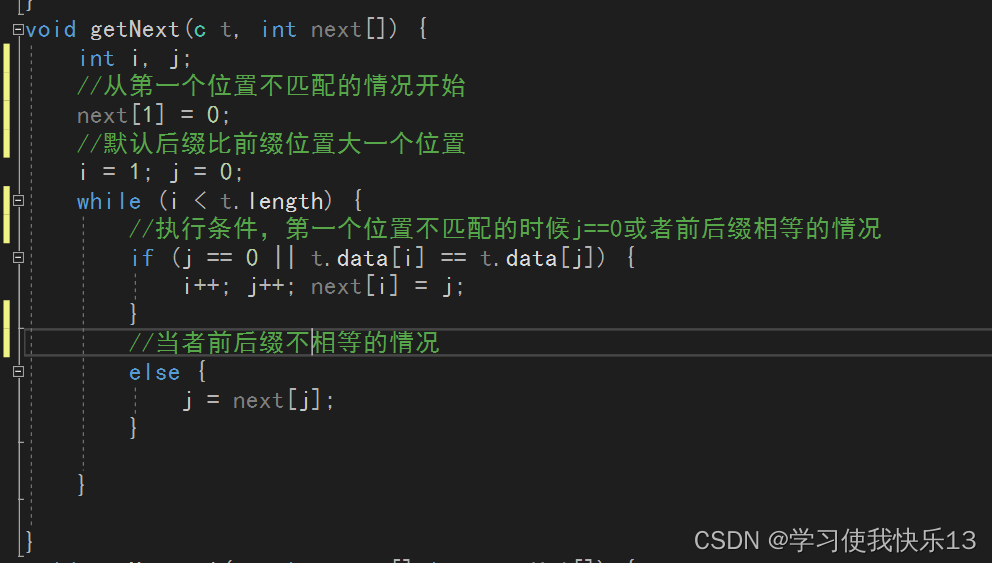
void getNext(c t, int next[]) {
int i, j;
//从第一个位置不匹配的情况开始
next[1] = 0;
//默认后缀比前缀位置大一个位置
i = 1; j = 0;
while (i < t.length) {
//执行条件,第一个位置不匹配的时候j==0或者前后缀相等的情况
if (j == 0 || t.data[i] == t.data[j]) {
i++; j++; next[i] = j;
}
//当者前后缀不相等的情况
else {
j = next[j];
}
}
}
void getNextval(c t,int next[],int nextVal[]) {
int j ;
nextVal[1] = 0;
for (j = 2; j <= t.length;j++) {
if (t.data[j]==t.data[next[j]]) {
nextVal[j] = nextVal[next[j]];
}
else {
nextVal[j] = next[j];
}
}
}
void KMP1(c s, c t) {
int i = 1, j = 1,next[MAXSIZE],nextVal[MAXSIZE];
getNext(t, next);
getNextval(t, next, nextVal);
while (i <= s.length&&j <= t.length) {
if (j==0||s.data[i] == t.data[j]) {
i++;
j++;
}
else {
//j=1;i=i-j+2;
j = nextVal[j];
}
}
if (j > t.length) {
cout << "该子串位置:" << i - t.length;
}
else
cout << "该子串不存在" << endl;
}
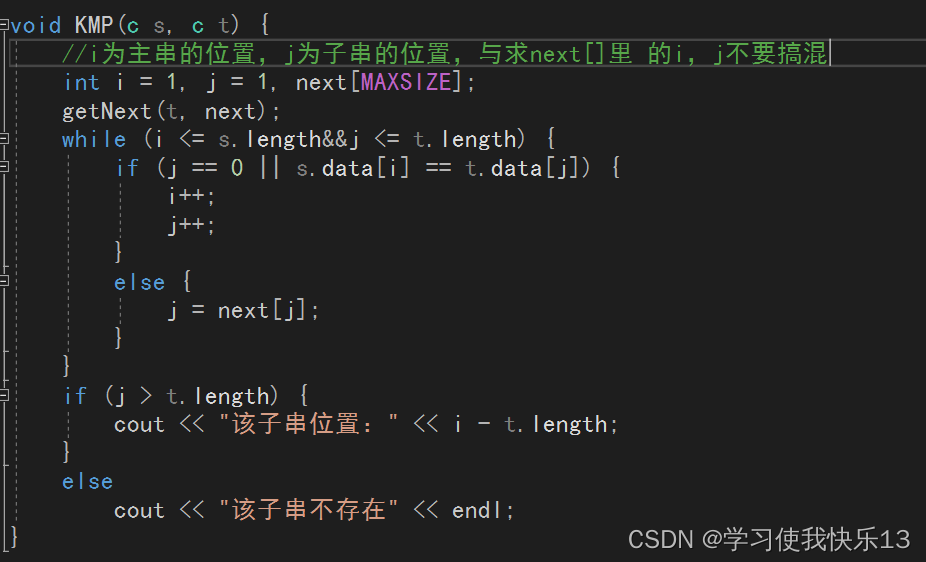
void KMP(c s, c t) {
int i = 1, j = 1, next[MAXSIZE];
getNext(t, next);
while (i <= s.length&&j <= t.length) {
if (j == 0 || s.data[i] == t.data[j]) {
i++;
j++;
}
else {
j = next[j];
}
}
if (j > t.length) {
cout << "该子串位置:" << i - t.length;
}
else
cout << "该子串不存在" << endl;
}
//定义两个串,s为主串,t为子串
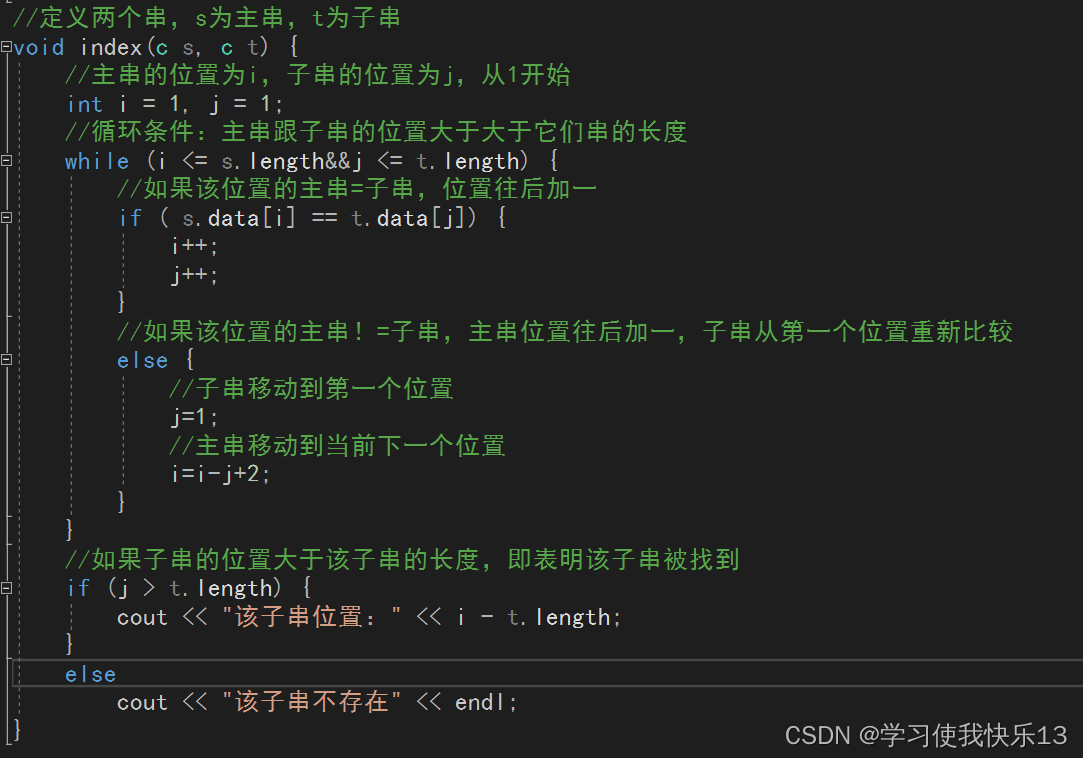
void index(c s, c t) {
//主串的位置为i,子串的位置为j,从1开始
int i = 1, j = 1;
//循环条件:主串跟子串的位置大于大于它们串的长度
while (i <= s.length&&j <= t.length) {
//如果该位置的主串=子串,位置往后加一
if ( s.data[i] == t.data[j]) {
i++;
j++;
}
//如果该位置的主串!=子串,主串位置往后加一,子串从第一个位置重新比较
else {
//子串移动到第一个位置
j=1;
//主串移动到当前下一个位置
i=i-j+2;
}
}
//如果子串的位置大于该子串的长度,即表明该子串被找到
if (j > t.length) {
cout << "该子串位置:" << i - t.length;
}
else
cout << "该子串不存在" << endl;
}
int main() {
c t,s;
input(s);
input(t);
KMP1(s,t);
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









