






集合类的讲解
知识点
:
集合类的为了提供统一的方法,Sum公司制定了一系列的集合类接口,其中有Collection,等等.在Collection的基础上又有其子接口Set,List他们的区别在于Set里的元素不允许重复,
List里的元素是按先后顺序进行存放的。(还有一中没有先后顺序也可以重复,这样的情况被称为Bags,JDK中并没有这样一个java类,但是需要可以自己实现。List中的元素允许重复. AbstractCollection实现了Collection 接口,AbstractSet又继承了AbstractCollection,而最后我们用到的TreeSet,HashSet等等都是继承了AbstractSet. 为什么Sum公司不直接用类TreeSet继承AbstractCollection中间又用AbstractSet呢?这是因为设计到一个设计模式————模版模式,所为模版模式就是为了提供一个流程而制定的一个步骤,在此虽然不能这样理解,但是这里用主要思想是这个类中有个removeAll()方法,由于所以的集合类的removeAll()方法都可以用同一个方法实现,所以为了提高重用性,所以Sum公司提供了这样一个中间类,也提高了可扩充性(这种设计思想在许多项目和JDK中已经见惯不惊了,也的到了业内人士的认可。举例:JDK中的DocumentBuilder类有有许多parse()方法,但是有一个abstract的抽象方法,而其他的parse()方法都是实现了的,为什么要留这样一个抽象的方法呢?原因也是设计到这样一个设计模式,因为其他的parse()方法的实现其实最后到是转换成哪个抽象的parse()方法,哪个抽象的parse()方法是我们最后要自己实现的,这样一来又提高了代码的复用性和减小了程序员的工作量。
至于List接口的扩展和Set很象,这里就不讲咯。
讲到具体的集合类
HashSet如果要遵循规范就必须在加入集合的对象中覆盖原来的hashCode()和equals()方法,为什么要覆盖这2个方法呢.首先我们想在集合中加入2个具有相同属性的类的时候只加入其中的一个。但是HashSet的底层进行存储顺序判断的时候的算法决定于hashcode值,如果2个对象不是同一个对象那么他们的hashcode值就不相同.所以如果要让set类底层知道这2个对象是相同的不进行加入,所以就必须把他们的hashcode值返回的值相同,并且equals返回true。这个的算法不同,常用的办法就是类属性的hashcode值的总和。
TreeSet它也是AbstractSet的一个子类,他与HashSet不同在于他的存储顺序与hashcode值无关系。而与他的比较器或加入的对象有关系。如果利用比较器比较只需要在TreeSet的构造函数中传入一个实现了
Comparator接口的类,这个接口有2个方法,但是起决定性的方法是compare(T o1, T o2)这个方法,equals()这个方法在TreeSet里无作用。另外如果TreeSet在创建的时候没有传入
参数,那么就必须要求加入的类实现
Comparable接口。其实在这里TreeSet的构造函数中传入一个比较器也涉及到一个设计模式————策略模式(如果在一个类里要处理一个算法,可以把这个算法抛给另外一个类处理,这样有很好的扩展性,很符合开闭原则<!--不对内部类进行修改就可以对类的功能进行扩充-->),在这里顺便提下在项目中尽量使用组合,避免使用继承。
Vector 它是继承了
AbstractList类,是线程安全的,在多线程中共用一个集合的时候因该考虑。而且他们可以加入同一个对象.
ArrayList 他是线程不安全的,所以在某些不用考虑线程的时候效率比Vecoter高,当然如果遇到线程问题的时候也可以做相应的安全处理(至于处理后和Vector哪个效率高不确定),而且他们可以加入同一个对象.
Map和Collection在某中程度上来看很象,它进行存储的时候都是键值对应,他的扩展类有
HashMap,HashTable,以及HashTree,LinkedHashMap,IndentityHashMap.WeakHashMap.
HashMap 他允许键值为空(最多只有一个空键值,这个自己思考),它是线程不安全的,
当遇到2个键值相同的时候他会把后面一个元素覆盖前面位置上的元素。他们常常用于加载配置文件的时候用。
HashTable 它不允许键值为空,但是他是线程安全的。
IndentityHashMap.WeakHashMap.在日常开发中用的很少,具体可以查阅JDK。
集合的工具类
Collections(集合) 和 Arrays类(数组
)
JDK1
。
5
新特性举例
标注@Override(覆盖)
例如有个类中有这样一个方法
特性1:@Override
public boolean equals(Object obj)
他就会去他父类找是否有这样一个方法,如果没有就报告错误,主要是为了避免写错代码而重新创建一个方法,这样强制了代码覆盖父类的方法。
特性2 减略了叠代.
for(Student s: xx)//xx是一个集合或数组,:相当于 in和javascript的便利很象
{
//注意Student只能放到里面,不能防到外面
}
特性3 范性(集合元素的统一性)
import java.util.*;
public class Test
{
public static void main(String agrs[])
{
HashMap<String,Integer> map = new HashMap<String,Integer>();
map.put("zhangsan",20);//这里可以不包装成Integer,jdk1.5会自动包装,注意1.5以下版本不能
map.put("lisi",23);
Set<Map.Entry<String,Integer>> set = map.entrySet();
for(Map.Entry entry : set)
{
System.out.println("Key = " + entry.getKey() + " Value = "+entry.getValue());
}
}
}
中文字符的编码问题
在properties配置文件中的特殊字符的转换问题,如果要输出=或.这些特殊字符的时候就要用/=/.这里的转义字符.但是这些都是对于英文字符,对于中文就必须对中文进行unicode编码(因为properties只能读unicode编码格式的字符),例如中文”好”进行unicode编码就是/u597d.我们这里知道中文字符的编码问题呢?这个可以借助很多工具如JDK中的native2ascii.exe这个命令,他的具体格式为
native2ascii
[options] [inputfile [outputfile]](可以翻阅Properties这个类的时候查阅其帮助)
集合类之间的关系图
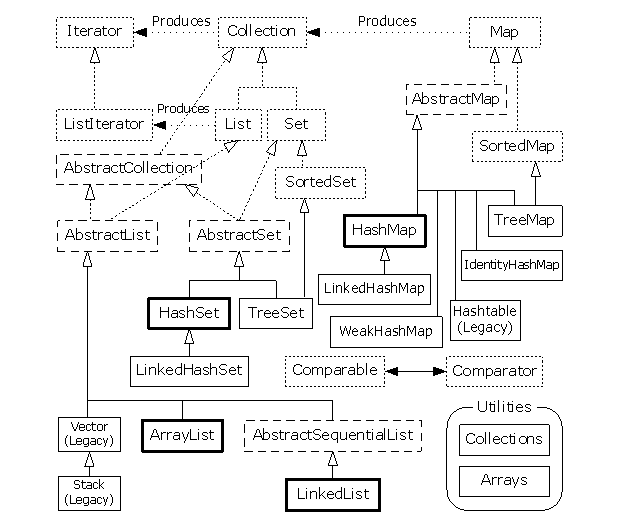
学习总结
:
通过今天的学习对集合类有了很深的了解,知道其底层实现的接口和他们之间的其别,例如Set,List的区别就在与Set里的元素不允许重复,而List是按存放的先后顺序进行存放.以及HashSet里的存储顺序的算法和TreeSet的算法.Vectorh和ArrayList的区别,HashMap和HashTable的区别,和其他一些不常用的集合类更学习了模式方法设计模式和策略模式设计模式.还学习到了properties的中文问题的解决方法和JDK1.5的一些新特性.而且通过下课的理解和对同学的讲解知识的掌握达到了95%以上.
学习中的问题:
今天暂时无问题,觉得力度不够大,希望自己能克服困难多练习,哇哈哈!















 28万+
28万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









