






1 Repmgr概述
1.1 简介
官方网站:repmgr - Replication Manager for PostgreSQL clusters

repmgr是一个2ndQuadrant开发的一款复制的开源工具套件,用于管理PostgreSQL服务器集群中的复制和故障转移。最初,它主要是为了简化流副本的管理,后来发展成为一个完整的故障转移管理套件。它通过设置备用服务器,监视复制以及执行管理任务(如故障转移或手动切换操作)的工具,增强了PostgreSQL内置的热备份功能。
repmgr与声名远扬的ORACLE ADG逻辑复制工具非常类似。它的功能强大,安装和配置简单,有很强的可操控性
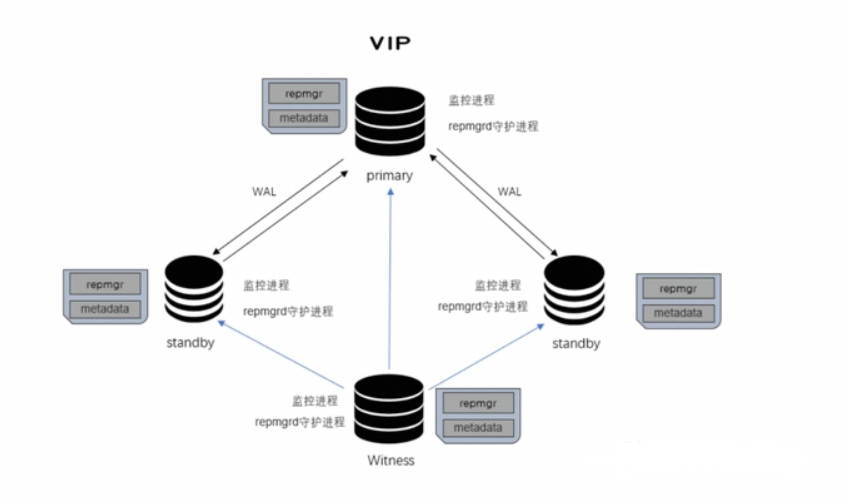
其中witness节点是防止出现脑裂的一种有效方法。
witness节点是一个普通的数据库实例,并不是流复制的一部分:它的作用是如果发生故障转移的情况,提供见证信息从而证明是主节点本身不可用,而不是不同的物理网络中断导致的脑裂。
在主节点的同一网络创建witness服务,如果主节点不可用,则备节点可以决定是否可以在不脑裂风险的情况下提升为主节点:如果备节点网络上只是和witness或主节点中的一个节点不通,则很可能存在网络中断,它不应该切换为主节点。如果备节点和witness节点相通,但和主节点不通,这证明不是网络中断,而是主节点本身不可用,因此它可以切换为主节点。
1.2 特点
repmgr的特点是非常轻量,单功能全面
- 故障检测和自动故障切换:repmgr 可以检测到主服务器故障并自动切换到备用服务器。
- 自动故障恢复:repmgr 可以检测到从服务器故障并自动将其重新加入到复制拓扑中。
- 多个备用服务器:repmgr 支持多个备用服务器,可以在主服务器故障时自动切换到最合适的备用服务器。
- 灵活的复制拓扑:repmgr 支持各种复制拓扑,包括单主服务器和多主服务器。
- 管理和监控:repmgr 提供了用于管理和监控PostgreSQL复制的各种工具和命令。
可以说 repmgr 是一个扩展模块,简化了 PostgreSQL 复制的管理和维护,提高系统的可靠性和可用性。它是一个非常有用的工具,特别是对于需要高可用性的生产环境。同时 repmgr 也是由 Postgresql 社区开发以及维护的。
主要提供了两个工具:
repmgr
#用于执行管理任务的命令行工具 设置备用服务器,将备用服务器提升为主服务器,切换主服务器和备用服务器,显示复制群集中服务器的状态
repmgrd
#主动监视复制群集中的服务器的守护程序 监视和记录复制性能,通过检测主数据库和提升最合适的备用服务器,向用户定义的群集中事件提供有关事件的通知 可以执行任务的脚本,例如通过电子邮件发送警报1.3 版本说明
官方链接:https://www.repmgr.org/docs/current/install-requirements.html#INSTALL-COMPATIBILITY-MATRIX
| repmgr version | Supported? | Latest release | Supported PostgreSQL versions | Notes |
| repmgr 5.4 | YES | 5.4.1 (2023-07-04) | 10, 11, 12, 13, 14, 15, 16 | |
| repmgr 5.3 | YES | 5.4.1 (2023-07-04) | 9.4, 9.5, 9.6, 10, 11, 12, 13, 14, 15 | PostgreSQL 15 supported from repmgr 5.3.3 |
| repmgr 5.2 | NO | 5.2.1 (2020-12-07) | 9.4, 9.5, 9.6, 10, 11, 12, 13 | |
| repmgr 5.1 | NO | 5.1.0 (2020-04-13) | 9.3, 9.4, 9.5, 9.6, 10, 11, 12 | |
| repmgr 5.0 | NO | 5.0 (2019-10-15) | 9.3, 9.4, 9.5, 9.6, 10, 11, 12 | |
| repmgr 4.x | NO | 4.4 (2019-06-27) | 9.3, 9.4, 9.5, 9.6, 10, 11 | |
| repmgr 3.x | NO | 3.3.2 (2017-05-30) | 9.3, 9.4, 9.5, 9.6 | |
| repmgr 2.x | NO | 2.0.3 (2015-04-16) | 9.0, 9.1, 9.2, 9.3, 9.4 |
2 Postgresql+repmgr高可用环境部署
2.1 环境说明
| 节点说明 | 节点配置 | 节点地址 | 节点部署 |
| master | CentOS7.9 4c/8G | 192.168.16.220 | Postgresql 、repmgr |
| slave1 | CentOS7.9 4c/8G | 192.168.16.221 | Postgresql 、repmgr |
| slave2 | CentOS7.9 4c/8G | 192.168.16.222 | Postgresql 、repmgr |
| witness | CentOS7.9 4c/8G | 192.168.16.223 | Postgresql 、repmgr |
2.2 PostgreSQL部署
2.2.1 环境准备
四个节点都执行
#安装依赖
yum -y install wget flex libselinux-devel readline-devel zlib zlib-devel openssl-devel pam-devel libxml2-devel libxslt-devel python python-devel tcl-devel systemd-devel pcre-devel gcc gcc-c++ make tree psmisc
yum -y groupinstall "Development Tools"
#创建用户
groupadd -g 5432 postgres
useradd -u 5432 -g postgres postgres
echo "2lp7VaR9um6g" | passwd --stdin postgres
#创建安装目录
mkdir -p /opt/pg/soft # 存放软件包
mkdir -p /opt/pg/pg12/12.15 # PG_HOME
mkdir /opt/pg/pgdata # PG_DATA
mkdir /opt/pg/pgwal # 存放wal文件
mkdir /opt/pg/pgarch # 存放wal归档文件
mkdir /opt/pg/pglog # 存放PostgreSQL的软件日志文件
chown -R postgres:postgres /opt/pg/
chmod 0700 /opt/pg/pgdata /opt/pg/pgwal /opt/pg/pgarch
# 创建目录软连接,方便日后数据库软件升级
ln -s /opt/pg/pg12 /opt/pg/pgsql
#创建主机映射
vi /etc/hosts
192.168.16.220 master
192.168.16.221 slave1
192.168.16.222 slave2
192.168.16.223 witness
#节点互信
ssh-keygen -t rsa
for i in 192.168.16.220 192.168.16.221 192.168.16.222 192.168.16.223;do ssh-copy-id -i $i;done
#切换到postgres进行节点互信,因为后面通过节点切换的时候,需要以postgres用户来ssh节点,否则故障切换会失败
su - postgres
ssh-keygen -t rsa
for i in 192.168.16.220 192.168.16.221 192.168.16.222 192.168.16.223;do ssh-copy-id -i $i;done2.2.2 数据库节点初始化
四个节点都执行
以下内核优化根据具体环境情况进行:内核优化
cat >> /etc/sysctl.conf << EOF
#for postgres db 12.15
kernel.shmall = 966327 # expr `free |grep Mem|awk '{print $2 *1024}'` / `getconf PAGE_SIZE`
kernel.shmmax = 3958075392 # free |grep Mem|awk '{print $2 *1024}'
kernel.shmmni = 4096
kernel.sem = 50100 64128000 50100 1280
fs.file-max = 76724200
net.ipv4.ip_local_port_range = 9000 65000
net.core.rmem_default = 1048576
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 4096
net.core.netdev_max_backlog = 10000
vm.overcommit_memory = 0
fs.aio-max-nr = 40960000
net.ipv4.tcp_timestamps = 0
vm.dirty_ratio=20
vm.dirty_background_ratio=3
vm.dirty_writeback_centisecs=100
vm.dirty_expire_centisecs=500
vm.swappiness=10
vm.min_free_kbytes=524288
EOF节点资源限制
cat >> /etc/security/limits.conf << EOF
#for postgres db 12.15
* soft nofile 1048576
* hard nofile 1048576
* soft nproc unlimited
* hard nproc unlimited
* soft core unlimited
* hard core unlimited
* soft memlock unlimited
* hard memlock unlimited
EOF
cat >> /etc/pam.d/login << EOF
#for postgres db 12.15
session required pam_limits.so
EOF环境变量配置
cat >> /etc/profile << EOF
#for postgres db 12.15
export LANG=en_US.utf8
export PGHOME=/opt/pg/pgsql/12.15/
export PGUSER=postgres
export PGPORT=5432
export PGDATA=/opt/pg/pgdata
export PATH=\$PGHOME/bin:\$PATH:\$HOME/bin
export LD_LIBRARY_PATH=\$PGHOME/lib:\$LD_LIBRARY_PATH
EOF
source /etc/profile # 使环境变量生效2.2.3 安装postgreSQL
官方下载链接:PostgreSQL: File Browser
安装包:postgresql-12.15.tar.gz
1)编译安装数据库(四个节点都执行)
#解压安装包
cd /opt/pg/soft/
tar -xzvf postgresql-12.15.tar.gz
# 编译安装
cd postgresql-12.15/
./configure --prefix=/opt/pg/pgsql/12.15/ --enable-debug --enable-cassert --enable-depend CFLAGS=-O0 # --with-pgport=6000
make -j 4 && make install
# 安装工具集
cd /opt/pg/soft/postgresql-12.15/contrib
make -j 4 && make install
# 查询版本,确认安装成功
postgres --version # postgres (PostgreSQL) 12.15
2)数据库初始化
主节点和witness节点执行
su - postgres
# 从pg11起,initdb设置WAL段的大小 --wal-segsize=32 单位MB
$ initdb --pgdata=/opt/pg/pgdata --waldir=/opt/pg/pgwal --encoding=UTF8 --allow-group-access --data-checksums --username=postgres --pwprompt --wal-segsize=32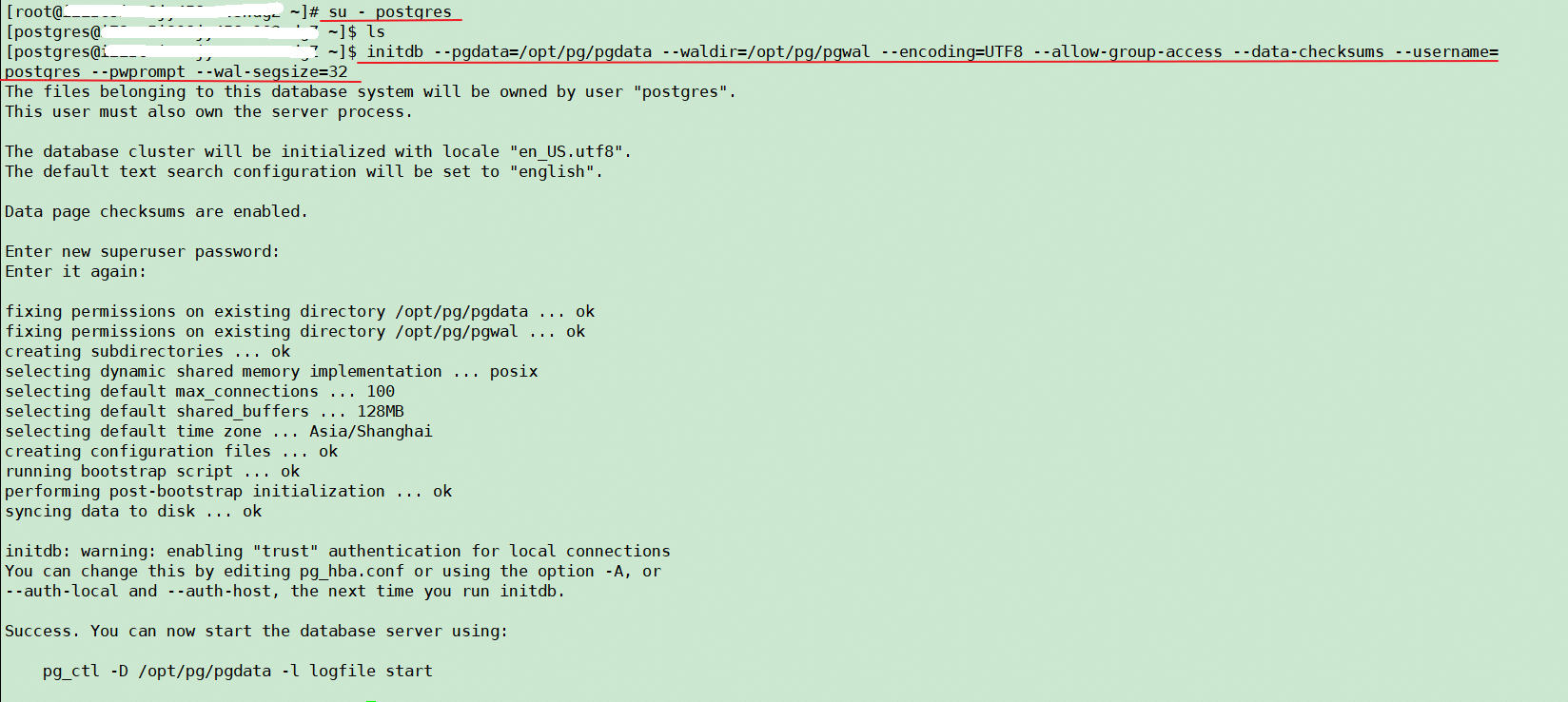
3)配置数据库参数
主节点和witness节点执行
vi $PGDATA/postgresql.conf
listen_addresses = '*'
max_wal_senders = 10
max_replication_slots = 10
wal_level = replica
hot_standby = on
wal_log_hints = on
full_page_writes=on
shared_preload_libraries = 'repmgr'
wal_keep_segments=100
archive_mode = on
archive_command = 'test ! -f /opt/pg/pgarch/%f && cp %p /opt/pg/pgarch/%f'4)配置访问策略
主节点和witness节点执行
vi $PGDATA/pg_hba.conf
#修改为如下:
host all all 192.168.16.0/24 md52.2.4 安装repmgr
2.2.4.1 repmgr安装
四个节点执行
#下载并解压
cd /opt/pg/soft/
wget -c https://repmgr.org/download/repmgr-5.3.3.tar.gz
tar -zxvf repmgr-5.3.3.tar.gz -C /opt/pg/soft/postgresql-12.15/contrib
#编译安装
cd /opt/pg/soft/postgresql-12.15/contrib
mv repmgr-5.3.3 repmgr
cd repmgr
yum install flex
./configure && make install2.2.4.2 配置修改
master节点
vi /etc/repmgr.conf
#repmgr基本配置信息
node_id=1
node_name='master'
conninfo='host=192.168.16.220 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/opt/pg/pgdata'
replication_user=repmgr
replication_type=physical
location=myrepmgr
#repmgr日志配置
log_level=INFO
log_facility=STDERR
log_file='/opt/pg/pglog/repmgr.log'
log_status_interval=10
# 启用witness时使用,否则witness即使注册在集群中,也不会影响故障切换
witness_sync_interval=15
primary_visibility_consensus=true
#可执行文件配置
pg_bindir='/opt/pg/pgsql/12.15/bin'
#集群faibver设置
failover='automatic'
promote_command='/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='/opt/pg/pgsql/12.15/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'slave1节点
vi /etc/repmgr.conf
#repmgr基本配置信息
node_id=2
node_name='slave1'
conninfo='host=192.168.16.221 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/opt/pg/pgdata'
replication_user=repmgr
replication_type=physical
location=myrepmgr
#repmgr日志配置
log_level=INFO
log_facility=STDERR
log_file='/opt/pg/pglog/repmgr.log'
log_status_interval=10
# 启用witness使用
witness_sync_interval=15
primary_visibility_consensus=true
#可执行文件配置
pg_bindir='/opt/pg/pgsql/12.15/bin'
#集群faibver设置
failover='automatic'
promote_command='/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='/opt/pg/pgsql/12.15/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'slave2节点
vi /etc/repmgr.conf
#repmgr基本配置信息
node_id=3
node_name='slave2'
conninfo='host=192.168.16.222 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/opt/pg/pgdata'
replication_user=repmgr
replication_type=physical
location=myrepmgr
#repmgr日志配置
log_level=INFO
log_facility=STDERR
log_file='/opt/pg/pglog/repmgr.log'
log_status_interval=10
# 启用witness使用
witness_sync_interval=15
primary_visibility_consensus=true
#可执行文件配置
pg_bindir='/opt/pg/pgsql/12.15/bin'
#集群faibver设置
failover='automatic'
promote_command='/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='/opt/pg/pgsql/12.15/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'witness节点
vi /etc/repmgr.conf
#repmgr基本配置信息
node_id=4
node_name='witness'
conninfo='host=192.168.16.223 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/opt/pg/pgdata'
replication_user=repmgr
replication_type=physical
location=myrepmgr
#repmgr日志配置
log_level=INFO
log_facility=STDERR
log_file='/opt/pg/pglog/repmgr.log'
log_status_interval=10
# 启用witness使用
witness_sync_interval=15
primary_visibility_consensus=true
#可执行文件配置
pg_bindir='/opt/pg/pgsql/12.15/bin'
#集群faibver设置
failover='automatic'
promote_command='/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='/opt/pg/pgsql/12.15/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'配置参考文档:
基于repmgr的PostgreSQL的高可用搭建 - UCloud云社区
PostgreSQL repmgr高可用集群+keepalived高可用_ITPUB博客
PostgreSQL repmgr高可用集群+keepalived高可用_ITPUB博客
2.2.5 启动主节点数据库
master和witness节点操作
su - postgres
#启动数据库
pg_ctl start -w -D $PGDATA -l /opt/pg/pglog/startup.log
#其他管理命令
#停止数据库
pg_ctl stop -m fast -w -D $PGDATA
#重启数据库
pg_ctl restart -m fast -w -D $PGDATA
#重载数据库配置
pg_ctl reload -D $PGDATA2.2.6 配置repmgr用户
master和witness节点操作
#创建数据库
create database repmgr;
#创建用户
create user repmgr with password 'repmgr' superuser login;
#授权用户管理数据库权限
alter database repmgr owner to repmgr;
2.2.7 修改pg_hba.conf
master和witness节点执行
vi $PGDATA/pg_hba.conf
# IPv4 local connections: 此配置下增加以下配置
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.16.0/24 trust
# replication privilege:此配置下增加以下配置
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.16.0/24 trust
注意:配置完成pg_hba.conf后,需要重启数据库
#重启数据库
pg_ctl restart -m fast -w -D $PGDATA配置密码认证文件
四个节点执行
su - postgres
#创建一个免密登录文件
vi .pgpass
192.168.16.220:5432:repmgr:repmgr:repmgr
192.168.16.220:5432:replication:repmgr:repmgr
192.168.16.221:5432:repmgr:repmgr:repmgr
192.168.16.221:5432:replication:repmgr:repmgr
192.168.16.222:5432:repmgr:repmgr:repmgr
192.168.16.222:5432:replication:repmgr:repmgr
192.168.16.223:5432:repmgr:repmgr:repmgr
192.168.16.223:5432:replication:repmgr:repmgr
#修改授权
chmod 600 .pgpass2.3 repmgr集群构建
2.3.1 master 节点加入集群
# 确保master数据库已开启
#将master数据库注册至集群,并查看状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf primary register"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
2.3.2 slave1 节点加入集群
#slave1节点,测试连通性并克隆master数据库数据
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -h 192.168.16.220 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone --dry-run"
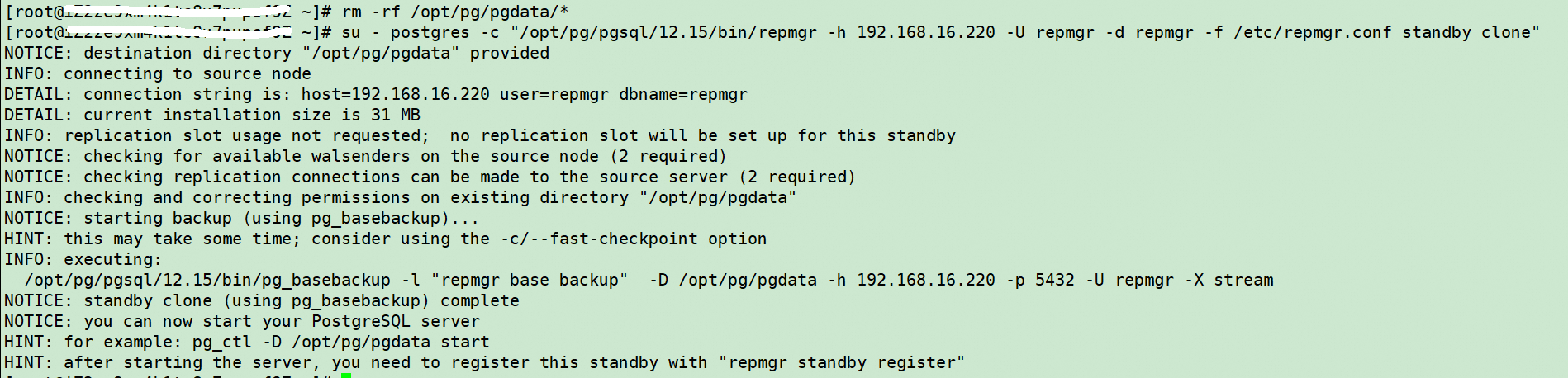
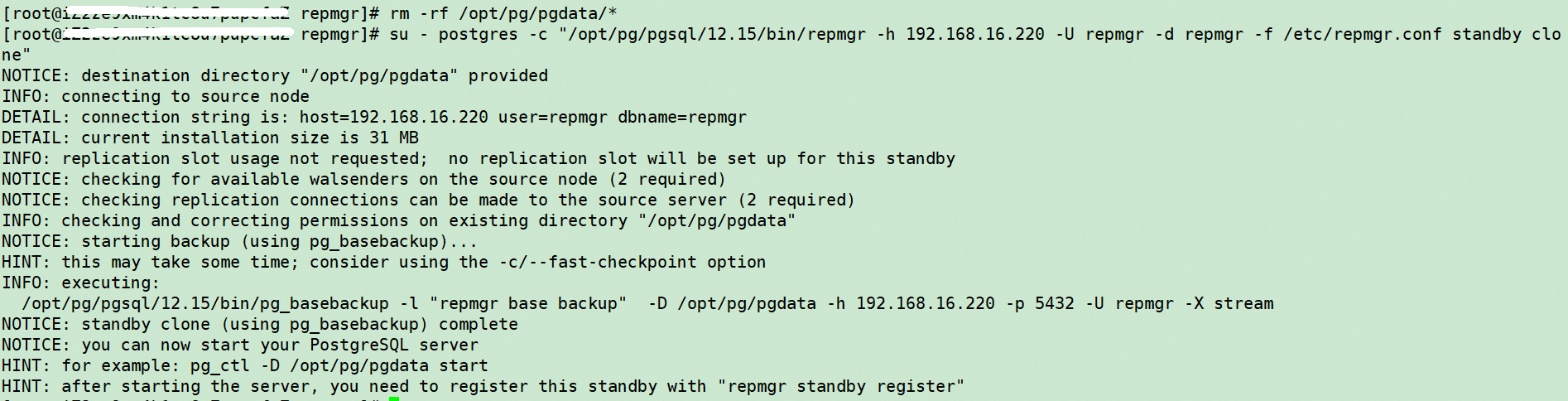
#删除pg的数据
rm -rf /opt/pg/pgdata/*
#执行同步主库的数据
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -h 192.168.16.220 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone"
#启动slave1节点数据库
su - postgres
pg_ctl start -w -D $PGDATA -l /opt/pg/pglog/startup.log
#slave1节点,将slave1数据库注册到集群,并查看状态
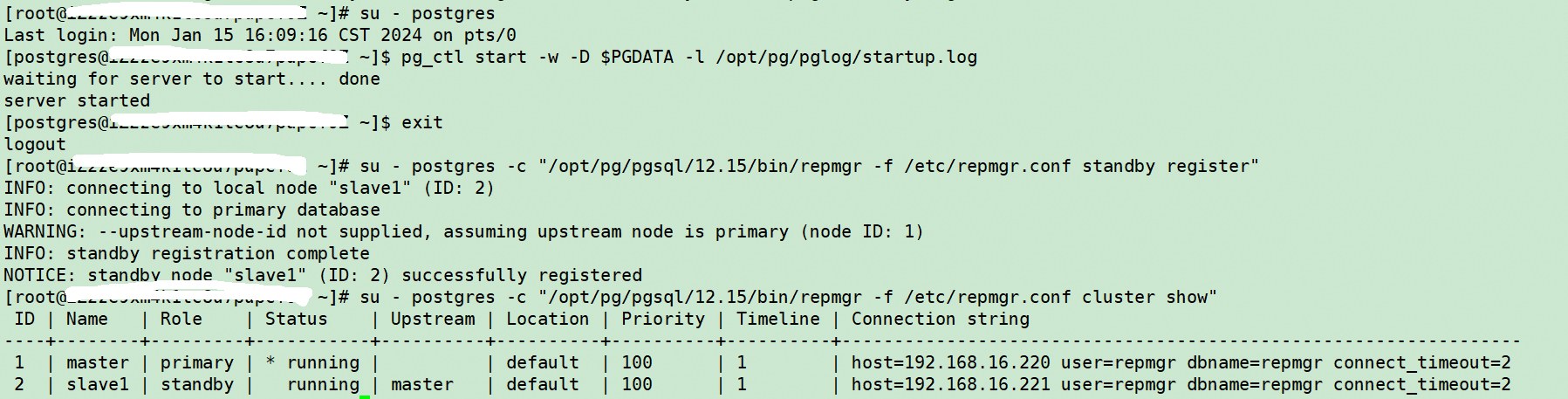
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby register"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"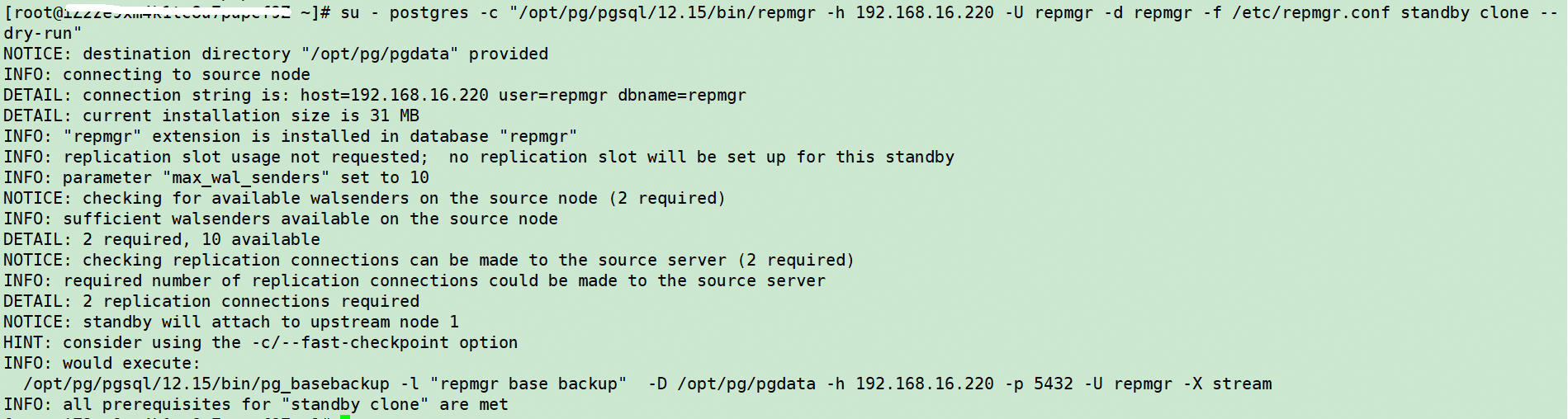
2.3.3 slave2 节点加入集群
#slave2节点,测试连通性并克隆master数据库数据
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -h 192.168.16.220 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone --dry-run"
#删除pg的数据
rm -rf /opt/pg/pgdata/*
#执行同步主库的数据
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -h 192.168.16.220 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone"
#启动slave2节点数据库
su - postgres
pg_ctl start -w -D $PGDATA -l /opt/pg/pglog/startup.log
#slave2节点,将slave2数据库注册到集群,并查看状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby register"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"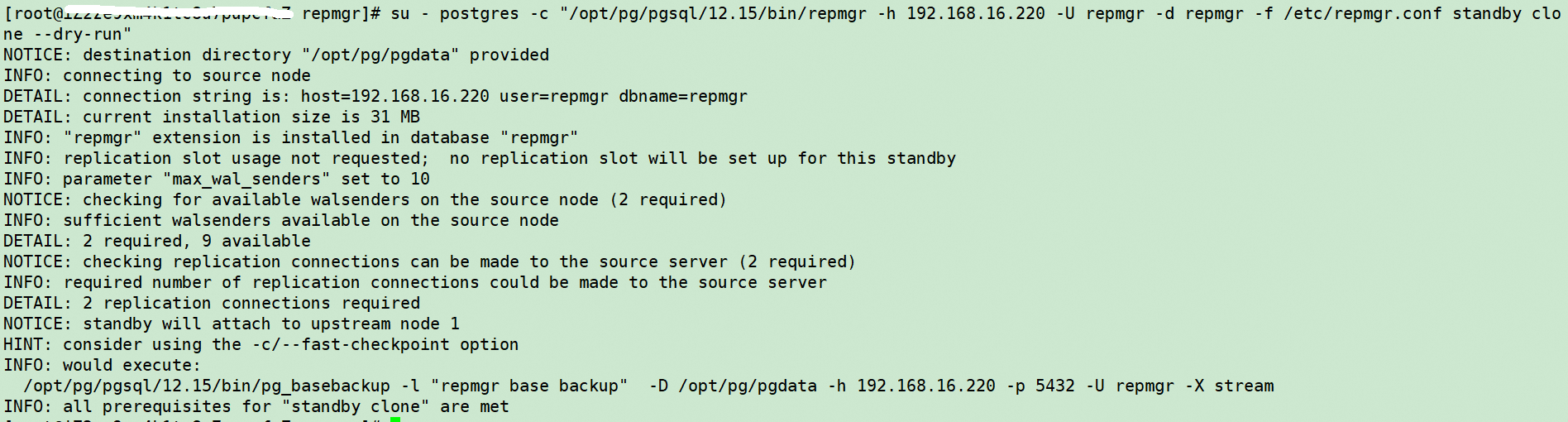


2.3.4 witness节点加入集群
#witness节点,将witness数据库注册到集群,并查看状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf -h 192.168.16.220 witness register"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"

2.3.5 开启守护进程
四个节点操作
#开启守护进程(故障自动转移)
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgrd -f /etc/repmgr.conf -d -p /tmp/repmgrd.pid"
#停止守护进程
REPMGRD_PID=`ps -ef | grep repmgrd|grep -v grep |awk '{print $2}'`
kill -9 $REPMGRD_PID2.4 数据库状态
master节点
pg_controldata |grep 'Database cluster state'
slave节点
pg_controldata |grep 'Database cluster state'
2.5 主从故障切换
2.5.1 主从库复制数据
#主库登录操作
psql (12.15)
Type "help" for help.
#创建表
postgres=# create table tb_1 (id int8,create_time timestamp(0) without time zone);
CREATE TABLE
#插入数据集
postgres=# insert into tb_1 values (1,now());
INSERT 0 1
#查看数据
postgres=# select * from tb_1;
id | create_time
----+---------------------
1 | 2024-01-15 16:26:03
(1 row)#从库登录操作
psql (12.15)
Type "help" for help.
postgres=# select * from tb_1;
id | create_time
----+---------------------
1 | 2024-01-15 16:26:03
(1 row)
从以上来看数据库主从复制已正常
2.5.2 故障切换验证
#master节点操作,停止数据库模拟主库宕机
su - postgres
pg_ctl stop -m fast -w -D $PGDATA
slave1查看集群切换过程
tail -fn100 /opt/pg/pglog/repmgr.log
[2024-01-16 12:23:05] [WARNING] unable to ping "host=192.168.16.220 user=repmgr dbname=repmgr connect_timeout=2"
[2024-01-16 12:23:05] [DETAIL] PQping() returned "PQPING_REJECT"
[2024-01-16 12:23:05] [WARNING] unable to connect to upstream node "master" (ID: 1)
[2024-01-16 12:23:05] [INFO] checking state of node "master" (ID: 1), 1 of 6 attempts
[2024-01-16 12:23:05] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 12:23:05] [DETAIL] PQping() returned "PQPING_REJECT"
[2024-01-16 12:23:05] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 12:23:15] [INFO] checking state of node "master" (ID: 1), 2 of 6 attempts
[2024-01-16 12:23:15] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 12:23:15] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 12:23:15] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 12:23:25] [INFO] checking state of node "master" (ID: 1), 3 of 6 attempts
[2024-01-16 12:23:25] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 12:23:25] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 12:23:25] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 12:23:35] [INFO] checking state of node "master" (ID: 1), 4 of 6 attempts
[2024-01-16 12:23:35] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 12:23:35] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 12:23:35] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 12:23:45] [INFO] checking state of node "master" (ID: 1), 5 of 6 attempts
[2024-01-16 12:23:45] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 12:23:45] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 12:23:45] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 12:23:55] [INFO] checking state of node "master" (ID: 1), 6 of 6 attempts
[2024-01-16 12:23:55] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 12:23:55] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 12:23:55] [WARNING] unable to reconnect to node "master" (ID: 1) after 6 attempts
[2024-01-16 12:23:55] [INFO] 2 active sibling nodes registered
[2024-01-16 12:23:55] [INFO] 4 total nodes registered
[2024-01-16 12:23:55] [INFO] primary node "master" (ID: 1) and this node have the same location ("myrepmgr")
[2024-01-16 12:23:55] [INFO] local node's last receive lsn: 0/2A0000A0
[2024-01-16 12:23:55] [INFO] checking state of sibling node "slave2" (ID: 3)
[2024-01-16 12:23:55] [INFO] node "slave2" (ID: 3) reports its upstream is node 1, last seen 51 second(s) ago
[2024-01-16 12:23:55] [INFO] standby node "slave2" (ID: 3) last saw primary node 51 second(s) ago
[2024-01-16 12:23:55] [INFO] last receive LSN for sibling node "slave2" (ID: 3) is: 0/2A0000A0
[2024-01-16 12:23:55] [INFO] node "slave2" (ID: 3) has same LSN as current candidate "slave1" (ID: 2)
[2024-01-16 12:23:55] [INFO] checking state of sibling node "witness" (ID: 4)
[2024-01-16 12:23:55] [INFO] node "witness" (ID: 4) reports its upstream is node 1, last seen 51 second(s) ago
[2024-01-16 12:23:55] [INFO] witness node "witness" (ID: 4) last saw primary node 51 second(s) ago
[2024-01-16 12:23:55] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds
[2024-01-16 12:23:55] [NOTICE] promotion candidate is "slave1" (ID: 2)
[2024-01-16 12:23:55] [NOTICE] this node is the winner, will now promote itself and inform other nodes
[2024-01-16 12:23:55] [INFO] promote_command is:
"/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file"
[2024-01-16 12:23:55] [NOTICE] redirecting logging output to "/opt/pg/pglog/repmgr.log"
[2024-01-16 12:23:55] [WARNING] 2 sibling nodes found, but option "--siblings-follow" not specified
[2024-01-16 12:23:55] [DETAIL] these nodes will remain attached to the current primary:
slave2 (node ID: 3)
witness (node ID: 4, witness server)
[2024-01-16 12:23:55] [NOTICE] promoting standby to primary
[2024-01-16 12:23:55] [DETAIL] promoting server "slave1" (ID: 2) using pg_promote()
[2024-01-16 12:23:55] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
[2024-01-16 12:23:56] [NOTICE] STANDBY PROMOTE successful
[2024-01-16 12:23:56] [DETAIL] server "slave1" (ID: 2) was successfully promoted to primary
[2024-01-16 12:23:56] [INFO] checking state of node 2, 1 of 6 attempts
[2024-01-16 12:23:56] [NOTICE] node 2 has recovered, reconnecting
[2024-01-16 12:23:56] [INFO] connection to node 2 succeeded
[2024-01-16 12:23:56] [INFO] original connection is still available
[2024-01-16 12:23:56] [INFO] 2 followers to notify
[2024-01-16 12:23:56] [NOTICE] notifying node "slave2" (ID: 3) to follow node 2
[2024-01-16 12:23:56] [ERROR] unable to execute repmgr.notify_follow_primary()
[2024-01-16 12:23:56] [DETAIL]
FATAL: terminating connection due to administrator command
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
[2024-01-16 12:23:56] [DETAIL] query text is:
SELECT repmgr.notify_follow_primary(2)
[2024-01-16 12:23:56] [NOTICE] notifying node "witness" (ID: 4) to follow node 2
INFO: node 4 received notification to follow node 2
[2024-01-16 12:23:56] [INFO] switching to primary monitoring mode
[2024-01-16 12:23:56] [NOTICE] monitoring cluster primary "slave1" (ID: 2)
[2024-01-16 12:24:02] [NOTICE] new standby "slave2" (ID: 3) has connected
[2024-01-16 12:24:02] [NOTICE] new witness "witness" (ID: 4) has connected
1)从日志中看到主节点宕机后repmgr尝试探测了6次,主节点依然不能探活;
2)最新的主节点的时间线
[2024-01-16 12:23:55] [INFO] local node's last receive lsn: 0/2A0000A0
3)slave2节点拥有与主节点一样的时间线
[2024-01-16 12:23:55] [INFO] last receive LSN for sibling node "slave2" (ID: 3) is: 0/2A0000A0
4)slave2和候选节点slave1有相关的时间线
[2024-01-16 12:23:55] [INFO] node "slave2" (ID: 3) has same LSN as current candidate "slave1" (ID: 2)
5)再找witness见证节点进行验证主节点是否存活
[2024-01-16 12:23:55] [INFO] witness node "witness" (ID: 4) last saw primary node 51 second(s) ago
3)最后确认可用节点3个,没有节点在过去4秒内看见到主节点
[2024-01-16 12:23:55] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the
4)提升候选节点slave1为主节点
[2024-01-16 12:23:55] [NOTICE] promotion candidate is "slave1" (ID: 2)
...
[2024-01-16 12:23:56] [DETAIL] server "slave1" (ID: 2) was successfully promoted to primary
5)slave2和witness重新连接到slave1新主库
[2024-01-16 12:24:02] [NOTICE] new standby "slave2" (ID: 3) has connected
[2024-01-16 12:24:02] [NOTICE] new witness "witness" (ID: 4) has connected
slave2查看集群状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
2.5.3 恢复原master为备库
#master节点操作,原来的master修复后进行恢复
#删除pg的数据
rm -rf /opt/pg/pgdata/*
#执行同步主库的数据
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -h 192.168.16.221 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone"
#启动slave2节点数据库
su - postgres
pg_ctl start -w -D $PGDATA -l /opt/pg/pglog/startup.log
#master节点,将master数据库注册到集群,由于之前创建过,需要加--force进行覆盖
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby register --force"
#查看最新集群状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"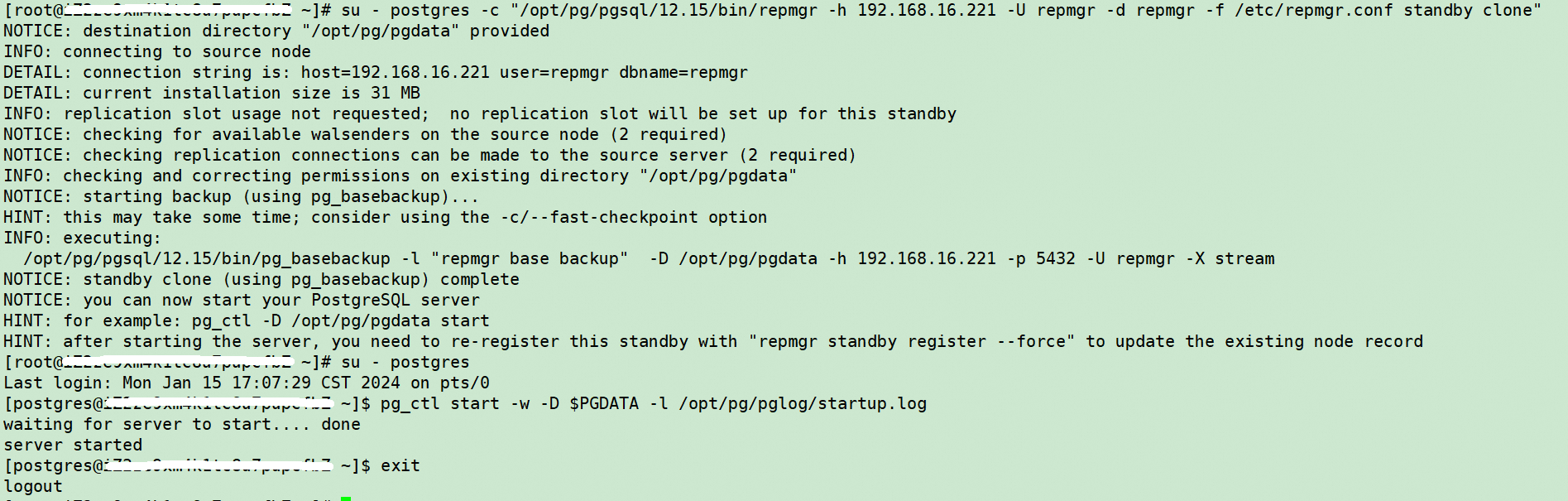

2.5.4 网络中断后witness节点怎么防止脑裂
场景:当主节点master由于网络问题导致备库不能访问,这时候如果备库repmgrd在ping不通主库的情况,repmgr会认为主库已经宕机,会启动故障切换,但是实际主库并没有宕机仅仅是由于网络问题导致不能访问,如果这是提升从库为主库,在整个架构中就会出现两个主库,导致脑裂;如果在有witness见证节点的架构,repmgrd除了检测备库到主库的网络,也会检测witness节点到主库的网络,如果备库到主库是不通,但是witness到主库是通的,那么会认为主库没有宕机仅仅是由于网络原因导致备库不能访问,这是不会引起故障切换,会防止脑裂发生。
模拟场景
1)查看集群的当前状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
2)模拟主节点网络故障
#在主库创建防火墙规则,来限制两个备库的repmgr访问,模拟网络故障
iptables -A INPUT -m iprange --src-range 192.168.16.221-192.168.16.222 -j DROP
#或单条增加
iptables -A INPUT -s 192.168.16.221 -j DROP
iptables -A INPUT -s 192.168.16.222 -j DROP
3) 查看slave1的repmgr日志
tail -fn100 /opt/pg/pglog/repmgr.log
[2024-01-16 16:10:06] [WARNING] unable to ping "host=192.168.16.220 user=repmgr dbname=repmgr connect_timeout=2"
[2024-01-16 16:10:06] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:10:06] [WARNING] unable to connect to upstream node "master" (ID: 1)
[2024-01-16 16:10:06] [INFO] checking state of node "master" (ID: 1), 1 of 6 attempts
[2024-01-16 16:10:08] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 16:10:08] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:10:08] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 16:10:18] [INFO] checking state of node "master" (ID: 1), 2 of 6 attempts
[2024-01-16 16:10:20] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 16:10:20] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:10:20] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 16:10:30] [INFO] checking state of node "master" (ID: 1), 3 of 6 attempts
[2024-01-16 16:10:32] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 16:10:32] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:10:32] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 16:10:42] [INFO] checking state of node "master" (ID: 1), 4 of 6 attempts
[2024-01-16 16:10:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 16:10:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:10:44] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 16:10:54] [INFO] checking state of node "master" (ID: 1), 5 of 6 attempts
[2024-01-16 16:10:56] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 16:10:56] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:10:56] [INFO] sleeping up to 10 seconds until next reconnection attempt
[2024-01-16 16:11:06] [INFO] checking state of node "master" (ID: 1), 6 of 6 attempts
[2024-01-16 16:11:08] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 fallback_application_name=repmgr"
[2024-01-16 16:11:08] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:11:08] [WARNING] unable to reconnect to node "master" (ID: 1) after 6 attempts
[2024-01-16 16:11:08] [INFO] 2 active sibling nodes registered
[2024-01-16 16:11:08] [INFO] 4 total nodes registered
[2024-01-16 16:11:08] [INFO] primary node "master" (ID: 1) and this node have the same location ("myrepmgr")
[2024-01-16 16:11:08] [INFO] local node's last receive lsn: 0/10006D68
[2024-01-16 16:11:08] [INFO] checking state of sibling node "slave2" (ID: 3)
[2024-01-16 16:11:08] [INFO] node "slave2" (ID: 3) reports its upstream is node 1, last seen 1 second(s) ago
[2024-01-16 16:11:08] [NOTICE] standby node "slave2" (ID: 3) last saw primary node 1 second(s) ago, considering primary still visible
[2024-01-16 16:11:08] [INFO] last receive LSN for sibling node "slave2" (ID: 3) is: 0/100073A0
[2024-01-16 16:11:08] [INFO] node "slave2" (ID: 3) is ahead of current candidate "slave1" (ID: 2)
[2024-01-16 16:11:08] [INFO] checking state of sibling node "witness" (ID: 4)
[2024-01-16 16:11:08] [INFO] node "witness" (ID: 4) reports its upstream is node 1, last seen 1 second(s) ago
[2024-01-16 16:11:08] [NOTICE] witness node "witness" (ID: 4) last saw primary node 1 second(s) ago, considering primary still visible
[2024-01-16 16:11:08] [INFO] 2 nodes can see the primary
[2024-01-16 16:11:08] [DETAIL] following nodes can see the primary:
- node "witness" (ID: 4): 1 second(s) ago
[2024-01-16 16:11:08] [NOTICE] cancelling failover as some nodes can still see the primary
[2024-01-16 16:11:08] [NOTICE] election cancelled
[2024-01-16 16:11:10] [WARNING] unable to ping "host=192.168.16.220 user=repmgr dbname=repmgr connect_timeout=2"
[2024-01-16 16:11:10] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2024-01-16 16:11:10] [INFO] node "slave1" (ID: 2) monitoring upstream node "master" (ID: 1) in degraded state
[2024-01-16 16:11:10] [DETAIL] waiting for upstream or another primary to reappear日志说明:
i)除了备库不能看到主节点,还有witness节点能看到主节点
[2024-01-16 16:11:08] [DETAIL] following nodes can see the primary:
- node "witness" (ID: 4): 1 second(s) ago
ii)取消切换,原因是还有一些节点能够看到主节点,这样就防止由于主节点网络问题导致脑裂(原因本身主库并没有宕机)
[2024-01-16 16:11:08] [NOTICE] cancelling failover as some nodes can still see the primary
iii)该节点在等待上游主节点恢复和新的主节点出现
[2024-01-16 16:11:10] [DETAIL] waiting for upstream or another primary to reappear
4)slave1查看集群状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"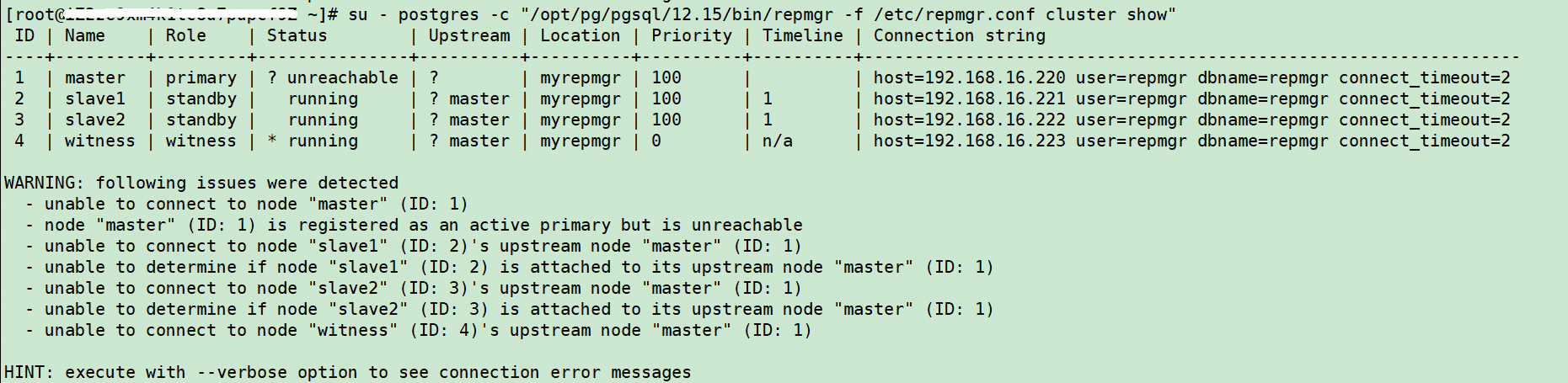
5)主库模拟恢复网络
#[删除方法]
#1)删除防火墙规则命令请参考
iptables -D INPUT -m iprange --src-range 192.168.16.221-192.168.16.222 -j DROP
#2)也可以单条删除
iptables -D INPUT -s 192.168.16.221 -j DROP
iptables -D INPUT -s 192.168.16.222 -j DROP
#3)或者通过规则id删除
iptables -L --line-numbers
#然后通过列出的规则ID进行删除
iptables -D INPUT <id>6)查看集群恢复情况
备库查看日志:tail -fn100 /opt/pg/pglog/repmgr.log
[2024-01-16 16:36:56] [NOTICE] reconnected to upstream node "master" (ID: 1) after 330 seconds, resuming monitoring
[2024-01-16 16:36:56] [INFO] node "slave1" (ID: 2) monitoring upstream node "master" (ID: 1) in normal state
[2024-01-16 16:37:06] [INFO] node "slave1" (ID: 2) monitoring upstream node "master" (ID: 1) in normal state
[2024-01-16 16:37:16] [INFO] node "slave1" (ID: 2) monitoring upstream node "master" (ID: 1) in normal state
[2024-01-16 16:37:27] [INFO] node "slave1" (ID: 2) monitoring upstream node "master" (ID: 1) in normal state
[2024-01-16 16:37:37] [INFO] node "slave1" (ID: 2) monitoring upstream node "master" (ID: 1) in normal state从以上日志看出已重新连接到主数据库
查看集群状态已恢复正常
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
2.5.5 repmgr管理PostgreSQL
功能验证:目前repmgr不能操作pg数据库的启动,所以这里先跳过
为了repmgr更好的接管pg库的启停管理,需要将postgresql数据库的启动进程交给systemd来管理,这样就可以用systemctl来操作啦。
配置如下:
三个节点执行
vi /usr/lib/systemd/system/postgres-12.service
[Unit]
Description=PostgreSQL 12 database server
After=syslog.target network.target
[Service]
Type=forking
TimeoutSec=120
User=postgres
Environment="PGHOME=/opt/pg/pgsql/12.15/"
Environment="PGDATA=/opt/pg/pgdata"
Environment="PGPORT=5432"
Environment="LD_LIBRARY_PATH=/opt/pg/pgsql/12.15/lib:/usr/local/lib:/usr/local/lib64:/usr/lib64"
ExecStart=/bin/bash -c '${PGHOME}/bin/pg_ctl start -w -D ${PGDATA} -l /opt/pg/pglog/startup.log'
ExecStop=/bin/bash -c '${PGHOME}/bin/pg_ctl stop -m fast -w -D ${PGDATA}'
ExecReload=/bin/bash -c '${PGHOME}/bin/pg_ctl reload -D ${PGDATA}'
[Install]
WantedBy=multi-user.target用systemctl启停数据库
#需要注意的是要如果原来pg库已通过pg_ctl启动,需要先停止后再执行
systemctl daemon-reload
systemctl restart postgres-12修改repmgr配置(每个节点都需要修改)
vi /etc/repmgr.conf
#repmgr基本配置信息
node_id=1
node_name='master'
conninfo='host=192.168.16.220 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/opt/pg/pgdata'
replication_user=repmgr
replication_type=physical
location=myrepmgr
#repmgr日志配置
log_level=INFO
log_facility=STDERR
log_file='/opt/pg/pglog/repmgr.log'
log_status_interval=10
#可执行文件配置
pg_bindir='/opt/pg/pgsql/12.15/bin'
#集群faibver设置
failover='automatic'
promote_command='/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --log-to-file'
follow_command='/opt/pg/pgsql/12.15/bin/repmgr standby follow -f /etc/repmgr.conf --log-to-file --upstream-node-id=%n'
#管理postgresql启停
service_start_command='sudo systemctl start postgres-12'
service_stop_command='sudo systemctl stop postgres-12'
service_restart_command='sudo systemctl restart postgres-12'
service_reload_command='sudo systemctl reload postgres-12'控制pg数据库操作
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf node service --list-actions --action=stop"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf node service --list-actions --action=start"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf node service --list-actions --action=restart"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf node service --list-actions --action=reload"2.5.6 其他操作命令
#主备切换并查看
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby switchover --siblings-follow -U repmgr --verbose"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
#从库重新跟随新主库
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby follow"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
#驱逐备库节点
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr standby unregister -f /etc/repmgr.conf"
#注销不活动的主节点
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr primary unregister -f /etc/repmgr.conf"
#主节点故障时,手动升级备库为主节点
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr standby promote -f /etc/repmgr.conf --siblings-follow"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby follow"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
#故障节点修复后,重新加入集群
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr node rejoin -d 'host=slave2 user=repmgr dbname=repmgr' --force-rewind --verbose -f /etc/repmgr.conf"
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
#强制重新注册为主节点
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf primary register --force"
#强制重新注册为备节点
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby register --force"
#节点通信检测
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster matrix"
#节点状态信息
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf service status --detail"
#节点连接信息
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster crosscheck"
| 命令 | 命令说明 |
| repmgr primary register | 初始化repmgr安装并注册主节点 |
| repmgr primary unregister | 注销非活动主节点 |
| repmgr standby clone | 从另一个PostgreSQL节点克隆PostgreSQL备用节点 |
| repmgr standby register | 将备用的信息添加到repmgr元数据中 |
| repmgr standby unregister | 从repmgr元数据中删除备用的信息 |
| repmgr standby promote | 将备用升级为主 |
| repmgr standby follow | 将正在运行的备用连接到新的上游节点 |
| repmgr standby switchover | 将备用升级为主,并将现有主降级为备用 |
| repmgr witness register | 将见证节点的信息添加到repmgr元数据中 |
| repmgr witness unregister | 将见证节点的信息删除到repmgr元数据中 |
| repmgr node status | 显示节点的基本信息和复制状态的概述 |
| repmgr node check | 从复制的角度对节点执行一些运行状况检查 |
| repmgr node rejoin | 将休眠(停止)节点重新加入复制群集 |
| repmgr node service | 显示或执行系统服务命令以停止/启动/重新启动/重新加载/提升节点 |
| repmgr cluster show | 显示复制群集中每个注册节点的信息 |
| repmgr cluster matrix | 在每个节点上运行repmgr群集显示并总结输出 |
| repmgr cluster crosscheck | 交叉检查每个节点组合之间的连接 |
| repmgr cluster event | 输出格式化的集群事件列表 |
| repmgr cluster cleanup | 清除监视历史记录 |
| repmgr service status | 显示集群中每个节点上repmgr的状态信息 |
| repmgr service pause | 指示复制集群中的所有repmgrd实例暂停故障切换操作 |
| repmgr service unpause | 指示复制集群中的所有repmgrd实例恢复故障切换操作 |
| repmgr daemon start | 在本地节点上启动repmgrd守护进程 |
| repmgr daemon stop | 在本地节点上停止repmgrd守护进程 |
2.5.7 常见报错
参考微博:https://www.cnblogs.com/Jeona/p/17378872.html
2.5.7.1 手动执行主从切换时报错
#su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby switchover --siblings-follow -U repmgr --verbose"
NOTICE: using provided configuration file "/etc/repmgr.conf"
WARNING: following problems with command line parameters detected:
database connection parameters not required when executing STANDBY SWITCHOVER
NOTICE: executing switchover on node "master" (ID: 1)
INFO: searching for primary node
INFO: checking if node 2 is primary
INFO: current primary node is 2
WARNING: unable to connect to remote host "192.168.16.221" via SSH
ERROR: unable to connect via SSH to host "192.168.16.221", user ""报错说明:主节点repmgr通过ssh登录远程节点192.168.16.221时不能登录
解决方案:
switchover 需要无密码登录,因此配置postgres 用户免密登录即可
su - postgres
ssh-keygen -t rsa
for i in 192.168.16.220 192.168.16.221 192.168.16.222 192.168.16.223;do ssh-copy-id -i $i;done再次执行成功切换
# su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf standby switchover --siblings-follow -U repmgr --verbose --force"
NOTICE: using provided configuration file "/etc/repmgr.conf"
WARNING: following problems with command line parameters detected:
database connection parameters not required when executing STANDBY SWITCHOVER
NOTICE: executing switchover on node "master" (ID: 1)
INFO: searching for primary node
INFO: checking if node 2 is primary
INFO: current primary node is 2
INFO: SSH connection to host "192.168.16.221" succeeded
INFO: 2 active sibling nodes found
INFO: all sibling nodes are reachable via SSH
INFO: 0 pending archive files
INFO: replication lag on this standby is 0 seconds
NOTICE: attempting to pause repmgrd on 4 nodes
NOTICE: local node "master" (ID: 1) will be promoted to primary; current primary "slave1" (ID: 2) will be demoted to standby
NOTICE: stopping current primary node "slave1" (ID: 2)
NOTICE: issuing CHECKPOINT on node "slave1" (ID: 2)
DETAIL: executing server command "/opt/pg/pgsql/12.15/bin/pg_ctl -D '/opt/pg/pgdata' -W -m fast stop"
INFO: checking for primary shutdown; 1 of 60 attempts ("shutdown_check_timeout")
INFO: checking for primary shutdown; 2 of 60 attempts ("shutdown_check_timeout")
NOTICE: current primary has been cleanly shut down at location 0/30000028
NOTICE: promoting standby to primary
DETAIL: promoting server "master" (ID: 1) using pg_promote()
NOTICE: waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
INFO: standby promoted to primary after 1 second(s)
NOTICE: STANDBY PROMOTE successful
DETAIL: server "master" (ID: 1) was successfully promoted to primary
INFO: node "slave1" (ID: 2) is pingable
INFO: node "slave1" (ID: 2) has attached to its upstream node
NOTICE: node "master" (ID: 1) promoted to primary, node "slave1" (ID: 2) demoted to standby
NOTICE: executing STANDBY FOLLOW on 2 of 2 siblings
INFO: node 4 received notification to follow node 1
INFO: STANDBY FOLLOW successfully executed on all reachable sibling nodes
NOTICE: switchover was successful
DETAIL: node "master" is now primary and node "slave1" is attached as standby
NOTICE: STANDBY SWITCHOVER has completed successfully查看最新集群状态
su - postgres -c "/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr.conf cluster show"
2.5.7.2 连接被拒绝
报错内容:
#/opt/pg/pgsql/12.15/bin/repmgr -f /etc/repmgr/14/repmgr.conf primary register --dry-run
INFO: connecting to primary database...
DEBUG: connecting to: "user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 port=5432 fallback_application_name=repmgr options=-csearch_path="
ERROR: connection to database failed
DETAIL:
connection to server at "192.168.16.220", port 5432 failed: Connection refused
Is the server running on that host and accepting TCP/IP connections?
DETAIL: attempted to connect using:
user=repmgr connect_timeout=2 dbname=repmgr host=192.168.16.220 port=5432 fallback_application_name=repmgr options=-csearch_path=解决方案:
需要将pg数据库的postgresql.conf配置中的listen-addresses ='*'
















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









