









告别Excel地狱:关系数据库如何10倍提升你的数据管理效率
引言:当Excel开始拖累你的工作
还记得那个反复崩溃的200MB Excel文件吗?或者那个公式错误导致财务报表数据全部混乱的下午?也许你正在经历多人同时编辑同一份表格的噩梦,或者被迫创建十几个相互关联的工作表来管理本应简单的数据。
如果这些场景让你感同身受,那么恭喜你,你已经抵达了"Excel地狱"的大门。但别担心,几乎每个数据工作者都曾在此驻足。今天,我们将探索一条通往数据天堂的道路——关系数据库。
Excel思维 vs 数据库思维:根本的范式转变
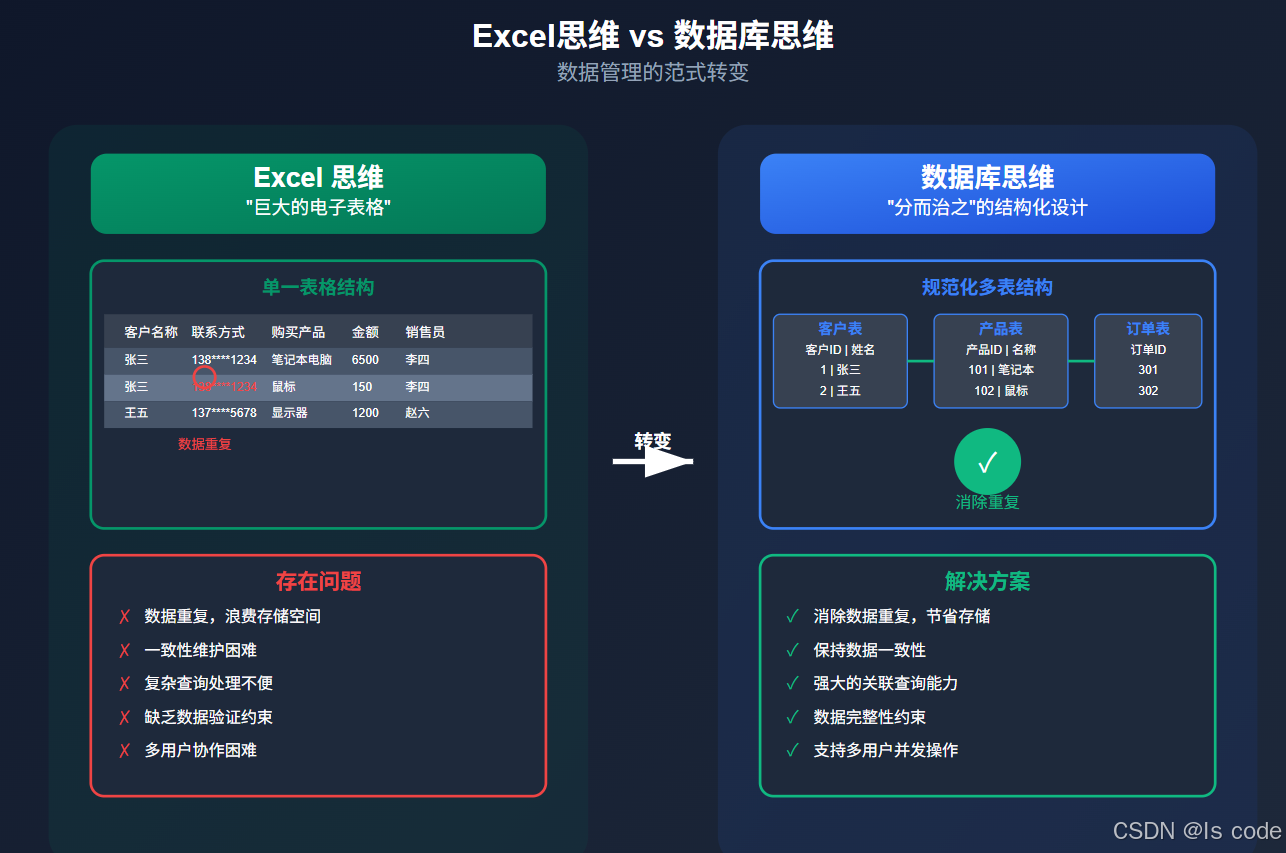
图1:Excel思维与数据库思维的本质区别
Excel思维的局限
想象Excel就像一张巨大的电子纸,你在上面自由地画格子、填数据、设计公式:
| 客户名称 | 联系方式 | 购买产品 | 购买日期 | 金额 | 销售员 |
|---------|-------------|---------------|----------|------|-------|
| 张三 | 1381234**** | 笔记本电脑A型号 | 2023/5/12 | 6500 | 李四 |
| 张三 | 1381234**** | 鼠标M型号 | 2023/5/12 | 150 | 李四 |
| 王五 | 1371234**** | 显示器D型号 | 2023/5/13 | 1200 | 赵六 |
这种自由度看似便捷,却埋下了隐患:
- 数据重复:张三的联系方式重复输入
- 数据一致性:如果张三换电话了,需要找出所有记录并修改
- 数据关联:无法简单查询"李四卖出的所有产品"
- 数据验证:没有强制约束防止错误输入
数据库思维的革命
关系数据库采用"分而治之"的思路,将数据分解成彼此关联的表:
客户表:
| 客户ID | 客户名称 | 联系方式 |
|-------|---------|-------------|
| 1 | 张三 | 1381234**** |
| 2 | 王五 | 1371234**** |
产品表:
| 产品ID | 产品名称 | 单价 |
|-------|------------|-----|
| 101 | 笔记本电脑A型号 | 6500 |
| 102 | 鼠标M型号 | 150 |
| 103 | 显示器D型号 | 1200 |
销售员表:
| 销售员ID | 销售员名称 |
|---------|----------|
| 201 | 李四 |
| 202 | 赵六 |
订单表:
| 订单ID | 客户ID | 销售员ID | 订单日期 |
|-------|-------|---------|-----------|
| 301 | 1 | 201 | 2023/5/12 |
| 302 | 2 | 202 | 2023/5/13 |
订单明细表:
| 明细ID | 订单ID | 产品ID | 数量 |
|-------|-------|-------|------|
| 401 | 301 | 101 | 1 |
| 402 | 301 | 102 | 1 |
| 403 | 302 | 103 | 1 |
乍看之下,这种方式似乎更复杂了。但正是这种"复杂",解决了Excel的核心问题:
- 消除重复:每条信息只存储一次
- 保持一致:修改张三的电话只需更新一处
- 强大的关联:可以轻松查询"李四销售的所有产品"
- 数据完整性:可以强制约束确保数据正确性
关系数据库的核心概念:比你想象的更直观
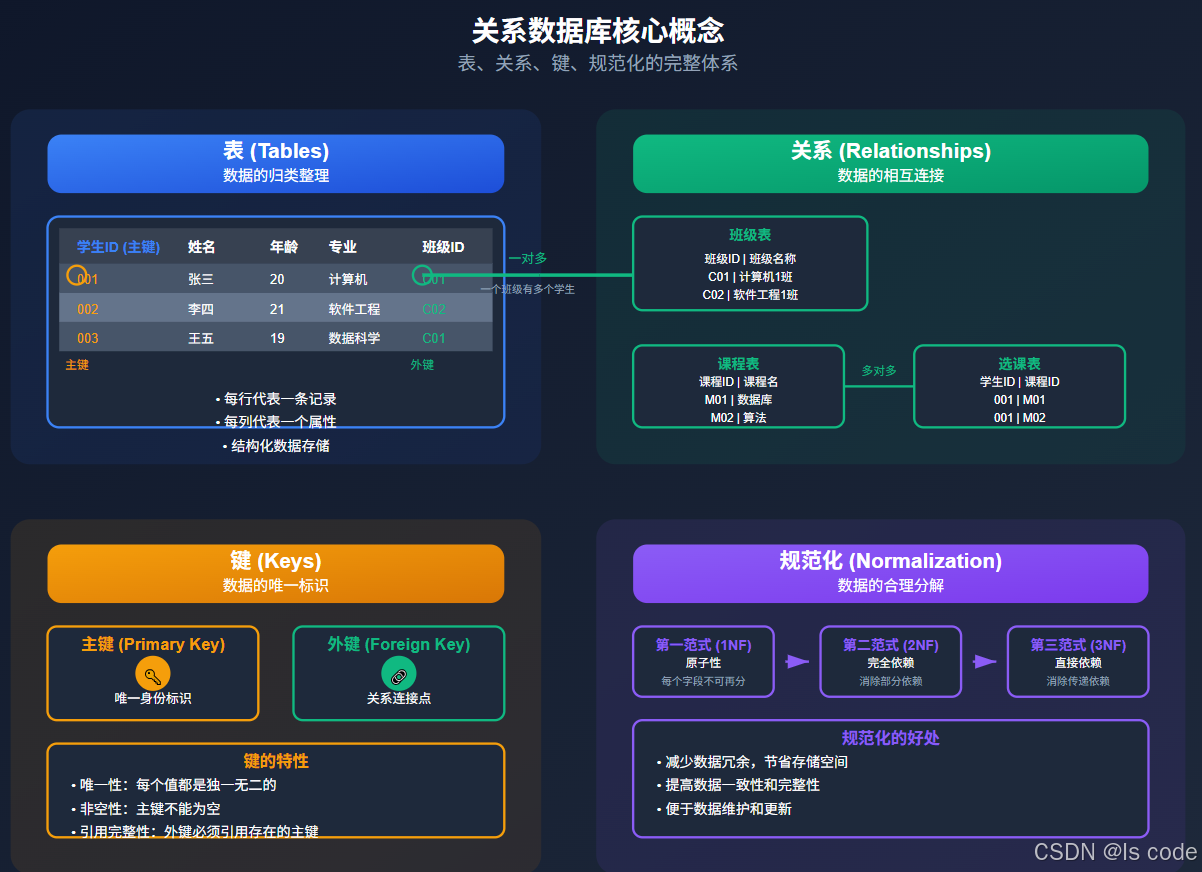
图2:表、关系、键、规范化的完整体系
表(Tables):数据的归类整理
表就像是专门的Excel工作表,但有严格的结构规定:每一列代表一个属性,每一行代表一条记录。
就像你家里的收纳系统:
- 衣柜只放衣物,每件衣物都有品牌、颜色、尺寸等属性
- 书架只放书籍,每本书都有作者、出版社、页数等属性
关系(Relationships):数据的相互连接
关系是表之间的逻辑连接,通过关键字段(键)建立。这就像现实世界中的关系网络:
- 学生和课程是多对多关系:一个学生可以选多门课,一门课可以有多个学生
- 客户和订单是一对多关系:一个客户可以有多个订单,但一个订单只属于一个客户
键(Keys):数据的唯一标识
- 主键(Primary Key):每张表的唯一身份证,如客户ID
- 外键(Foreign Key):指向其他表主键的引用,建立表间关系
这就像社会中的身份证系统,和人与人之间的关系网络。
规范化(Normalization):数据的合理分解
规范化是将数据分解成多个表的科学方法,遵循一系列规则(范式)。这就像整理衣柜:
- 第一步:把所有物品分类(衣物、书籍、厨具)
- 第二步:给每类物品合理归位(夏装、冬装分开)
- 第三步:进一步细分(T恤、衬衫、毛衣分类存放)
从Excel到数据库:一个真实案例
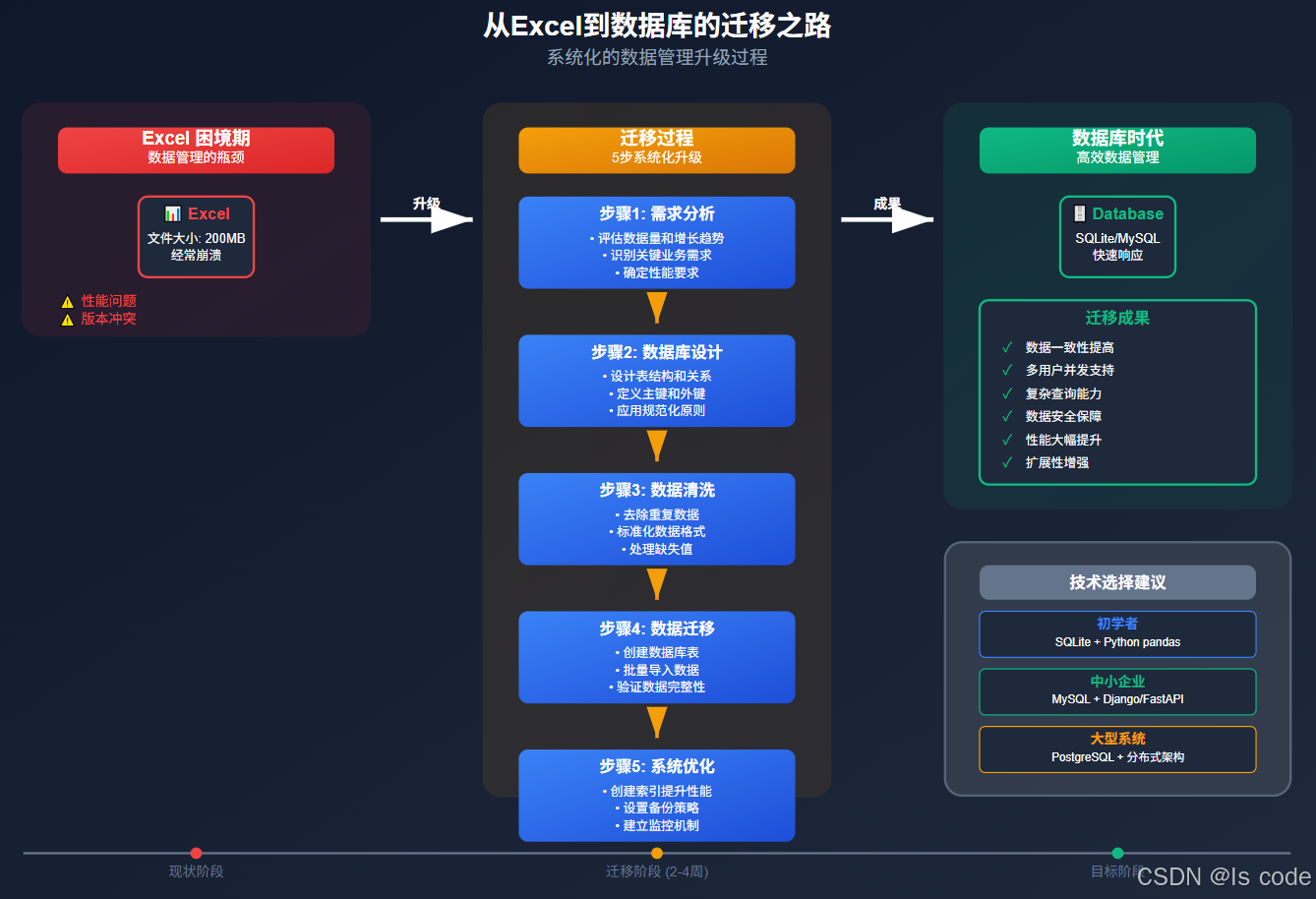
图3:系统化的数据管理升级过程
场景:小型电商库存管理
张小姐经营一家小型电商,最初用Excel管理库存和订单。随着业务增长,她面临了经典的Excel问题:
- 文件越来越大,经常崩溃
- 多人同时编辑导致版本冲突
- 数据重复造成不一致
- 复杂查询(如"哪些畅销产品库存不足")困难重重
数据库解决方案
张小姐决定升级到SQLite数据库(轻量级关系数据库),使用Python进行管理:
import sqlite3
import pandas as pd
# 创建数据库连接
conn = sqlite3.connect('ecommerce.db')
# 创建产品表
conn.execute('''
CREATE TABLE IF NOT EXISTS products (
product_id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
category TEXT,
price REAL,
stock INTEGER
)
''')
# 创建订单表
conn.execute('''
CREATE TABLE IF NOT EXISTS orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER,
order_date TEXT,
status TEXT
)
''')
# 创建订单明细表
conn.execute('''
CREATE TABLE IF NOT EXISTS order_items (
item_id INTEGER PRIMARY KEY,
order_id INTEGER,
product_id INTEGER,
quantity INTEGER,
FOREIGN KEY (order_id) REFERENCES orders (order_id),
FOREIGN KEY (product_id) REFERENCES products (product_id)
)
''')
# 从Excel导入数据
products_df = pd.read_excel('inventory.xlsx', sheet_name='Products')
products_df.to_sql('products', conn, if_exists='append', index=False)
# 简单查询:库存不足的产品
low_stock = pd.read_sql_query('''
SELECT name, category, stock
FROM products
WHERE stock < 10
ORDER BY stock
''', conn)
print("库存不足产品:")
print(low_stock)
# 复杂查询:最畅销的产品
top_selling = pd.read_sql_query('''
SELECT p.name, p.category, SUM(oi.quantity) as total_sold
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
GROUP BY p.product_id
ORDER BY total_sold DESC
LIMIT 5
''', conn)
print("\n最畅销产品:")
print(top_selling)
conn.close()
这个简单的迁移为张小姐带来了显著改进:
- 数据一致性提高
- 多用户同时操作不再冲突
- 复杂查询变得简单
- 数据可靠性大幅提升
何时该从Excel升级到数据库?
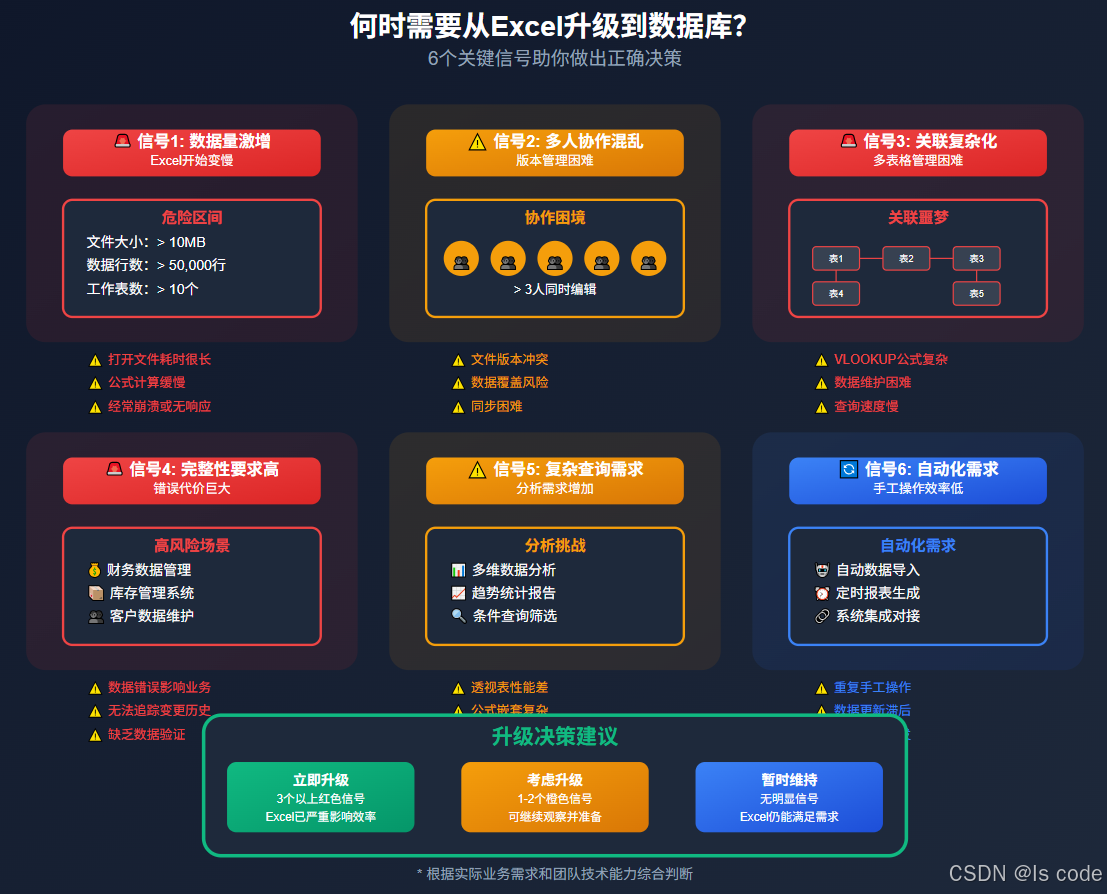
图4:6个关键信号助你做出正确决策
考虑以下信号:
- 数据量增长:Excel文件超过10MB或5万行
- 多人协作:多人需要同时编辑数据
- 数据关联复杂:需要维护多个相互关联的表格
- 数据完整性要求高:错误数据可能导致严重后果
- 查询需求复杂:需要频繁执行复杂的数据筛选和统计
- 自动化需求:需要程序自动处理和更新数据
数据库带来的性能提升

图5:10倍效率提升的真实数据对比
从性能角度看,数据库相比Excel有显著优势:
- 文件打开速度:从30-60秒提升到1-3秒(20倍提升)
- 查询响应时间:从5-30秒提升到0.1-1秒(30倍提升)
- 并发用户支持:从1人提升到100+人(100倍提升)
- 数据处理量:从100万行提升到数亿行(1000倍提升)
入门关系数据库的实用步骤
-
从SQLite开始:轻量级、零配置、单文件数据库,完美的学习起点
-
学习基本SQL:掌握SELECT、INSERT、UPDATE、DELETE等基础命令
-
设计第一个数据库:将你现有的Excel表格转化为数据库设计
-
使用Python操作数据库:pandas和SQLAlchemy是友好的入门工具
-
逐步迁移数据:不要一次性迁移所有数据,从一个简单模块开始
结语:数据管理的进化之路
从Excel到关系数据库不仅仅是工具的变化,更是思维方式的转变。这种转变帮助你从被动应对数据问题,到主动塑造数据资产。
关系数据库并非万能灵药——Excel在快速原型和简单分析方面仍然出色。但当你的数据开始成长,学会使用合适的工具和思维方式将为你节省无数时间,并开启数据价值的新篇章。
在接下来的系列文章中,我们将深入学习SQL语言、数据库设计原则及如何用Python高效操作数据库。数据世界的大门已经为你打开,你准备好迈出第一步了吗?
本文是"数据库技术系列·数据库基础概念(入门篇)"的开篇文章,通过生动的案例和可视化图表,深入浅出地解析了从Excel到关系数据库的思维转变。在下一篇文章中,我们将探索SQL查询语言的艺术,学会用代码与数据对话。
📚 推荐阅读:
- 《数据库系统概念》- 权威的数据库理论教材
- 《SQL必知必会》- SQL语言入门经典
- 《利用Python进行数据分析》- pandas操作实战




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











