







决策树概述
关于决策树的原理,网上有个有趣的比喻,这里直接搬过来吧。讲的是母亲给女儿介绍对象的对话。
女儿:多大岁数了?
母亲:26
女儿:帅么?
母亲:帅。
女儿:高么?
母亲:高。
女儿:有钱么?
母亲:有钱的。
女儿:好,那见个面吧。
这个对话是yy的~~哈哈:D,这个对话的过程就像是一个决策树的过程,每一个问题就像是一个决策的节点。女儿根据这个结果来选择(见面/不见面)。
在实际中,对于数据的分类也是可以这样操作,根据不同特征的值,逐个判断,来决定将其归到哪一类。
那么问题来了 ~~
这么多特征,先用哪个特征来判断呢?这里就需要引入信息增益、熵的概念。
信息增益、熵
第一次看到这个词是在大学课本里,那会不知道这个干嘛用的,没想到还能用在这些算法里。其实信息增益越大相当于现在的 “信息量好大”。~~哈哈,信息量大其实也有个衡量标准的。。
我们看书上的定义。
熵定义为信息的期望值,假设某件事发生的概率为
p(xi)
,则信息定义为:
l(xi)=−log2(p(xi))
那么对于所有事件的 信息熵,
H=−∑i=1np(xi)log2(p(xi))
举个栗子,有人说:明天早上的太阳会从东面升起。我们知道这里的概率几乎为1 那么代入公式 会得到一个很小的值,说明信息量不大。其实也很好理解的,因为这句话在我们看来,就是句废话,有啥信息量。
再来一个,有人说:明天会下钱雨,主要以黄金、美元为主。震撼吧,激动吧。先代入公式算下,拍拍脑袋清醒下,这事的概率几乎为0,那么代入公式之后就得到一个很大的值。通俗的说,信息量真大。
信息量大呢,表示我们要确定某件事需要花费更多的资源或者成本。好比刚才的:太阳从东面升起。这事没啥信息量。我们不会发短信给朋友说,如果明天太阳从东面升起,我们就出去玩。前面半句好像是废话,对吧。
ok ,对于信息熵的理解,到这里就够了。
回到刚才的问题, 那么决策树先用哪个特征来判断呢?
这里特征的选择就是需要靠信息增益来确定。我们要根据能给我们带来最大信息增益的特征来对数据分类。因为信息增益越大,能帮我们确定更多的东西。
code
import math
#计算信息熵
def calcShannonEnt(dataSet):
numlen=len(dataSet)
datatype={}
for data in dataSet:
labels=data[-1]
if labels not in datatype.keys():
datatype[labels]=1
datatype[labels]+=2
ent=0.0
for key in datatype:
p=float(datatype[key])/numlen
ent-=math.log(p,2)*p
return ent
#样本数据
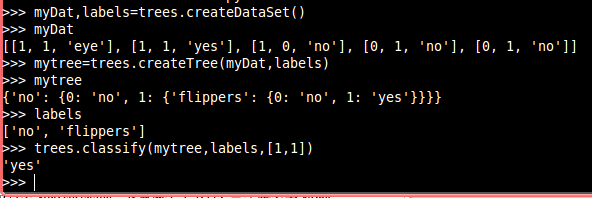
def createDataSet():
dataSet=[[1,1,'eye'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels=['no','flippers']
return dataSet,labels
#根据特征切分数据
def splitData(dataSet,axis,value):
listtemp=[]
for line in dataSet:
if line[axis]==value:
linetemp=[]
linetemp.extend(line)
del linetemp[axis]
listtemp.append(linetemp)
return listtemp
#获得最好的特征
def GetFeatureToSplit(dataSet):
numFeature=len(dataSet[0])-1
baseEnt=0.0
bestFeature=-1
for i in range(numFeature):
featlist=[tmp[i] for tmp in dataSet]
featset=set(featlist)
ent=0.0
for value in featset:
datatemp=splitData(dataSet,i,value)
ent+=calcShannonEnt(datatemp)
if baseEnt<ent:
baseEnt=ent
bestFeature=i
return bestFeature
#特征不足时,用出现最多的类别作为该项的类别
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortClassCount=sorted(classCount.iteritems(),key=lambda d:d[1],reverse=True)
return sortClassCount[0][0]
#创建树
def createTree(dataSet,labels):
classlist=[tmp[-1] for tmp in dataSet]#拿到所有类别
if classlist.count(classlist[0]) == len(classlist):
return classlist[0]
if len(dataSet[0])==1:
return majorityCnt(classlist)
bestFeature=GetFeatureToSplit(dataSet)#获取最适合特征位置
Featurevaluelabels=labels[bestFeature]#获取最适合特征名称
mytree={Featurevaluelabels:{}}
Featurevalue=[tmp[bestFeature] for tmp in dataSet]
FeaturevalSet=set(Featurevalue)
labels1=labels[:]
del(labels1[bestFeature])
for value in FeaturevalSet:#遍历该特征所有可能的值
labelstmp=labels1[:]
mytree[Featurevaluelabels]#递归过程[value]=createTree(splitData(dataSet,bestFeature,value),labelstmp)
return mytree
#分类树
def classify(inputtree,featlabels,testVec):
firstlabels=inputtree.keys()[0]#得到第一个特征名称
featindex=featlabels.index(firstlabels)#得到第一个特征位置
secondekeys=inputtree[firstlabels]
for key in secondekeys.keys():#将第一个特征对应的值与测试数据对应特征的值比对
if testVec[featindex]==key:
if type(secondekeys[key]).__name__=='dict':
claslabel=classify(secondekeys[key],featlabels,testVec)
else:
claslabel=secondekeys[key]
return claslabelrun

end
参考:
《机器学习实战》















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









