







 本文介绍了Redis Cluster 3.0的架构,包括分布式、主从复制和异步复写的概念。集群通过将16384个槽分配给节点来实现数据分布,提供高可用性。在主从复制模型中,节点故障时可自动选举新的主节点。然而,Redis Cluster不保证强一致性,可能存在数据丢失的情况。此外,文章还详细讲述了如何在Linux环境下搭建Redis Cluster,以及Jedis和Spring-data-redis的客户端支持。
本文介绍了Redis Cluster 3.0的架构,包括分布式、主从复制和异步复写的概念。集群通过将16384个槽分配给节点来实现数据分布,提供高可用性。在主从复制模型中,节点故障时可自动选举新的主节点。然而,Redis Cluster不保证强一致性,可能存在数据丢失的情况。此外,文章还详细讲述了如何在Linux环境下搭建Redis Cluster,以及Jedis和Spring-data-redis的客户端支持。
本文内容从redis官方文档整理而来,简要概述redis cluster的优点和缺点
redis cluster需要3.0版本的支持,详细说明参照下面文档
集群指南:http://redis.io/topics/cluster-tutorial
集群规范:http://redis.io/topics/cluster-spec
架构概述
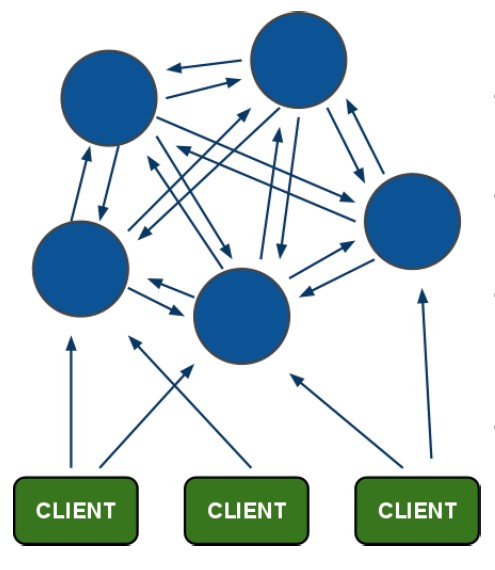
上图是redis cluster的整体架构
分布式
从redis cluster的架构图中可以看出采用分布式架构
键空间被分割为 16384 槽(slot),事实上集群的最大节点数量是 16384 个
然而建议最大节点数量设置在1000这个数量级上,所有的主节点都负责 16384 个哈希槽中的一部分
集群中的每个节点负责处理一部分哈希槽
举个例子, 一个集群可以有三个哈希槽, 其中:
- 节点 A 负责处理 0 号至 5500 号哈希槽
- 节点 B 负责处理 5501 号至 11000 号哈希槽
- 节点 C 负责处理 11001 号至 16384 号哈希槽
这样的好处是便于水平拓展集群环境,如果添加一个新的节点,直接添加就可以了
如果要删除一个节点只需要将该节点中的所有哈希槽移动到其他节点即可
简而言之:
redis cluster自动分割数据到不同的节点上,并非所有节点都存储了全部的数据
整个节点部分节点挂掉不会导致整个集群环境宕机,保证了一定程度上的可用性
主从复制
对于集群环境而言,容灾是必须要考虑的问题
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用
集群使用了主从复制模型,每个节点都会有N-1个复制品
如果主节点挂掉,redis cluster会从子节点中选举一个作为新的master
而redis cluster实现了这种模式,举例说明:
- 节点 A 负责处理 0 号至 5500 号哈希槽
- 节点 B 负责处理 5501 号至 11000 号哈希槽
- 节点 C 负责处理 11001 号至 16384 号哈希槽
假设有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
异步复写
这一点是对主从复制的补充,redis cluster并不能保证数据的强一致性
在生产环境中特定的条件下可能会丢失写操作,导致这一现象的本质原因是redis cluster采用异步复制,异步写入
整个执行过程如下:
- 客户端向主节点B写入一条命令.
- 主节点B向客户端回复命令状态.
- 主节点将写操作复制给他的从节点 B1, B2 和 B3
主节点对命令的复制工作发生在返回命令回复之后,即第二部之后
因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低
由此可见redis为了保证性能,在性能和一致性之间做了一定的权衡(也许redis后续版本会支持同步复写)
对于上述情况,我个人对可能会丢失写操作的理解如下:
假设有A B C A1 B1 C1 留个节点ABC为master节点,A1B1C1分别为这三个master节点的slave节点
假设集群环境中存在网络分区,一方包含节点A 、C、A1、B1、C1 ,另一方包含节点 B 和客户端
由于网络分区之间的通信问题,客户端能正常向B写入数据
如果网络分区发生时间较短,这个操作能正常执行,如果分区的时间足够让大部分的另一方将B1选举为新的master,那么客户端写入B中得数据便丢失了
生产环境应当尽量避免网络分区带来的种种问题,据我所知RabbitMQ集群的网络分区容错性也并不是非常高
架构细节
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
- 节点的fail是通过集群中超过半数的节点检测失效时才生效,此时将会判定整个集群不可用
- 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value,官方推荐节点数量为1000个(实际中能用到这么多的有几个)
数据读取表现
在 Redis 集群中节点并不是把命令转发到管理所给出的键值的正确节点上:
1. redis cluster把客户端重定向到服务一定范围内的键值的节点上,
2. 如果这个节点没有客户端需要的数据,将重定向其他节点,直到节点查询完毕为止,或者查询到所需数据就提前终止
3. 客户端获得一份最新的集群表示,里面有写着哪些节点服务哪些键值子集,所以在正常操作中客户端是直接联系到对应的节点并把给定的命令发过去
功能实现
- redis cluster实现了所有在非分布式 redis 版本中出现的处理单一键值的命令
- 多个键值的复杂操作未实现, 比如 set 里的并集(unions)和交集(intersections)操作
因为执行这些复杂操作命令需要在多个redis 节点之间移动数据, 并且在高负载的情况下,
这些命令将降低 Redis 集群的性能, 并导致不可预测的行为,又一次为了性能而舍弃了
集群环境搭建
快速在linux环境下搭建redis cluster集群
准备6个redis节点,3从三主,对应的redis节点的ip和端口对应关系如下
127.0.0.1:7000
127.0.0.1:7001
127.0.0.1:7002
127.0.0.1:7003
127.0.0.1:7004
127.0.0.1:7005下载最新版redis
wget http://download.redis.io/releases/redis-3.0.0.tar.gz解压并安装
tar xf redis-3.0. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









