







专栏系列:《人工智能AI之机器学习基石》②

高质量的数据是驱动机器学习模型的强大燃料
🚀 引言:无米之炊与数据的重要性
在上一篇文章《什么是机器学习?——开启智能之门》中,我们一起揭开了机器学习的神秘面纱,了解了它的基本概念、与AI和深度学习的关系,以及机器学习的三大核心要素。我们知道了,机器学习就像一个聪明的学生,能够从“经验”中学习。
那么,这个“经验”具体是什么呢?答案就是——数据。
俗话说,“巧妇难为无米之炊”。对于机器学习而言,数据就是那至关重要的“米”。没有数据,再强大的算法也无法施展其能;数据的质量,则直接决定了模型学习的上限和最终的性能。正如汽车需要高质量的汽油才能跑得又快又远,机器学习模型也需要高质量的数据作为“燃料”。
你可能会问:
- 数据真的那么重要吗?难道不是算法更关键?
- 我们从哪里获取数据?是不是所有数据都能直接用?
- 在把数据“喂”给模型之前,我们通常需要对它做些什么“手脚”呢?
这篇文章,就让我们聚焦机器学习的“生命之源”——数据,深入探讨数据在机器学习中的核心地位,以及在模型训练开始前,我们必须进行的那些关键的数据预处理工作。
💎 一、数据:机器学习的基石与“天花板”
在机器学习领域,流传着这样一句话:“Garbage in, garbage out.”(垃圾进,垃圾出)。这句话非常形象地说明了数据质量对于模型性能的决定性影响。
- 数据决定了模型的上限: 即使拥有最顶尖的算法,如果输入的是充满噪声、错误、偏见或者与问题不相关的数据,那么训练出来的模型效果也必然大打折扣,甚至完全不可用。好的数据能够为模型提供丰富且准确的信息,让模型学习到真实世界中潜在的规律和模式。
- 数据量与多样性同样重要:
- 数据量: 通常情况下,越多的高质量数据,越能帮助模型学习到更普适、更鲁棒的规律,减少过拟合的风险。想象一下,只看几张猫的图片就想让机器认识所有品种的猫,显然是不现实的。
- 多样性: 数据需要覆盖各种可能的情况和变化。例如,在训练人脸识别模型时,数据不仅要包含不同人的脸,还要包含不同光照、角度、表情、遮挡情况下的脸,这样模型才能在各种复杂场景下都表现良好。
- 算法与数据相辅相成: 优秀的算法能够更有效地从数据中提取信息,但算法的威力最终还是受限于数据的质量和所包含信息的丰富程度。在很多实际项目中,工程师们花费在数据收集、清洗、整理和标注上的时间,往往远超选择和调试算法的时间。
一个简单的例子:
假设我们要训练一个模型来识别图片中的苹果。
- 高质量数据: 我们提供了大量清晰的、各种品种、各种颜色、各种角度、不同背景下的苹果图片。模型就能很好地学习到苹果的通用特征。
- 低质量数据:
- 如果我们只提供了少量红富士苹果的图片,模型可能就无法识别青苹果或黄元帅。
- 如果图片中混入了很多梨,或者苹果的标签被错误地标成了橘子,模型就会学到错误的信息。
- 如果图片都非常模糊,模型也很难提取有效特征。
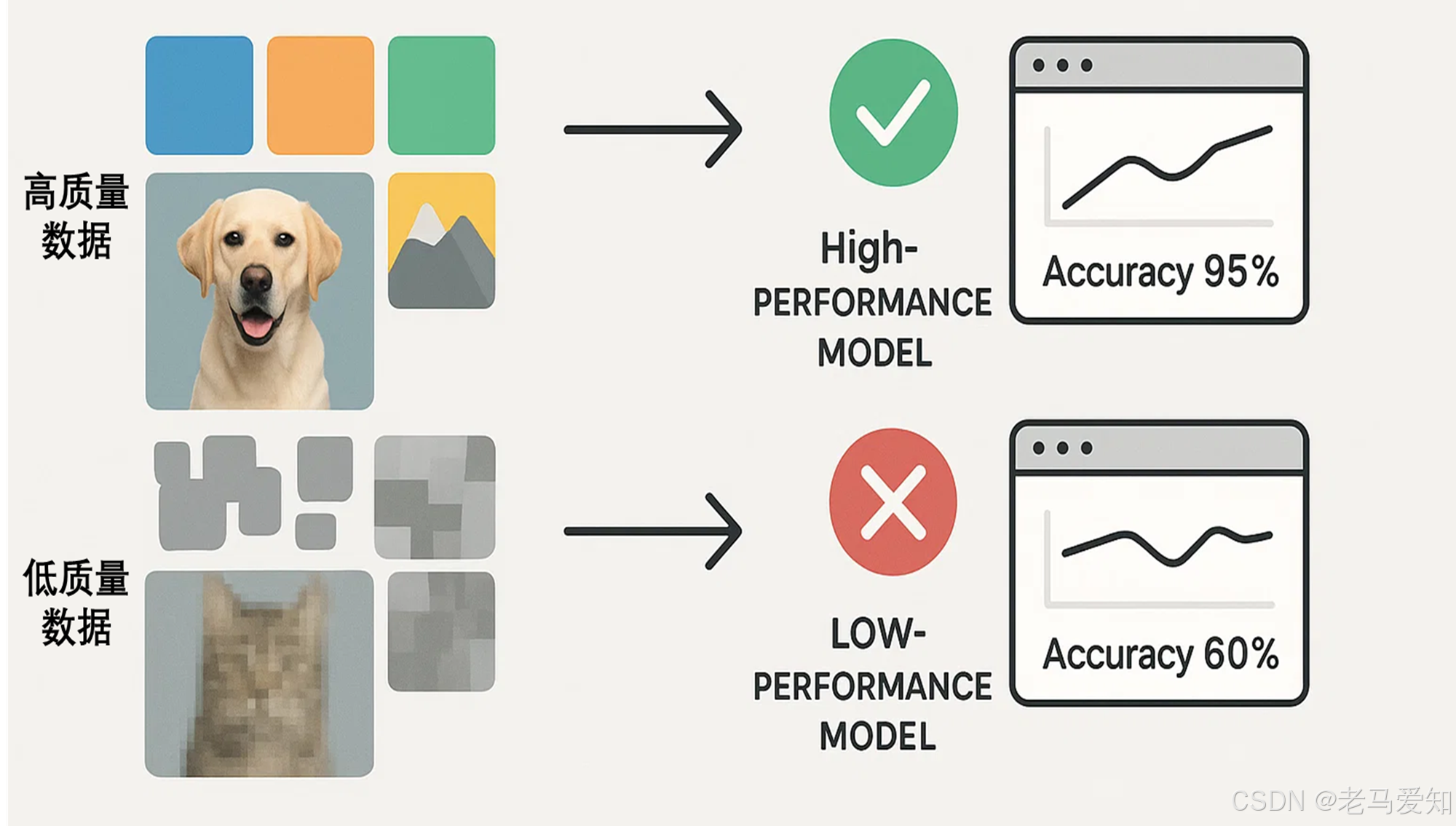 数据质量直接影响机器学习模型的学习效果
数据质量直接影响机器学习模型的学习效果
因此,在启动任何机器学习项目之前,首先要思考的问
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









