








《人工智能AI之计算机视觉:从像素到智能》· 模块一:视觉之门——从经典特征到CNN革命
你是否曾想过,当我们拿起手机,“刷脸”解锁的那一刻,它真的“认识”你吗?
当我们驾驶的汽车在毫秒间识别出前方横穿的行人并紧急刹车时,它真的“看见”危险了吗?
当我们在产线上部署的SaaS系统,24小时不知疲倦地从传送带上挑出有微小瑕疵的产品时,它真的“理解”什么是“完美”与“缺陷”吗?
这些场景,我们早已习以为常。它们背后都指向一个共同的技术奇迹——计算机视觉(Computer Vision, CV)。
作为一个在IT/CT(信息技术/通信技术)与AI融合领域摸爬滚打了30多年的老兵,我见证了无数企业(尤其是电信、银行、保险行业)从“信息化”走向“智能化”的历程。我发现一个有趣的“认知裂隙”:
- 终端用户 看到的是:“哇,真方便,扫一下脸钱就付了!”
- 工程师 看到的是:“模型在LFW数据集上准确率99.7%,mAP达到0.92!”
- 决策者(如VP、总监) 在意的则是:“这套系统上线后,我们的欺诈率降低了多少?质检人力成本节省了多少?”
用户、工程师、决策者,三者都在谈论“视觉”,但他们谈论的,是同一件事吗?
“看见”,这个我们与生俱来、几乎不假思索的能力,恰恰是人工智能领域最深刻、最复杂、也最具价值的挑战之一。本篇文章,作为我们整个专栏的开篇,我想和你一起,不聊高深的数学公式,也不堆砌最新的模型,而是回到原点,共同探讨一个最根本的问题:
机器究竟如何“看见”?它“看见”的世界,和我们“看见”的,一样吗?
这不仅是一次技术探秘,更是一次帮助我们(无论是AI从业者、管理者还是爱好者)填补认知裂隙、看清智能本质的旅程。
一、 “看见”的两种形态:人类的“直觉”与机器的“计算”
我们首先要拆解的,就是“看见”这个词。
1.1 人类视觉:一部“无意识”的意义加工厂
让我们先来审视自己。当你“看见”时,发生了什么?
光线穿过你的瞳孔,在视网膜上成像。但这仅仅是开始。信号沿着视神经进入大脑,瞬间激活了视觉皮层、记忆中枢、情感区域……你看到的绝不只是像素。
你看到一个“苹果”,你几乎在0.1秒内就知道了它“是水果、可以吃、是甜的、从树上长出来的、甚至可能联想到‘牛顿’或‘乔布斯’”。
你看到一个朋友皱起眉头,你“看”到的不是“五官的特定几何排列”,而是“他可能不高兴了”。
人类的视觉是一个holistic(整体的)、interpretive(解释性的)系统。我们天生就是“意义加工厂”,我们看到的,是经过大脑无数经验、记忆、情感、上下文“瞬间加工”后的结果。对我们来说,视觉近乎直觉。
1.2 机器视觉:一场“有意识”的数字运算
现在,我们切换到机器的视角。当一个摄像头(AI之眼)“看见”同一个苹果时,它得到了什么?
它得到的,是一个巨大的数字矩阵。
如果是一张1000x1000像素的彩色照片,它看到的就是一个由300万个数字(1000 x 1000 x 3个颜色通道)组成的冰冷网格。
这就是计算机视觉的起点,也是它面临的第一个,也是最大的挑战——“语义鸿沟”(The Semantic Gap)。
“语义鸿沟”,指的是原始像素数据(一堆数字)与人类赋予的意义(“这是一只可爱的猫”)之间存在的巨大鸿沟。
机器的“看见”,本质上是一场有意识、有目的、基于数学的计算过程。它必须被明确地“告知”任务。它不会“自动”理解任何东西。
- 我们 看见“猫”,是认知。
- 机器 看见“猫”,是计算——它通过一个复杂的函数(模型),将那300万个数字输入,最终输出了一个标签“cat”,因为这个标签在训练时与成千上万张类似的数字矩阵相关联。
思考小札:为什么分清这一点如此重要?
我刚入行时,在电信机房做运维。我只要扫一眼服务器机柜,凭“直觉”就能发现问题:“嗯?那个指示灯闪烁的频率不对。” 但对当时的监控系统来说,它只能记录“灯在闪”,却无法判断“频率不对”这个“意义”。
这个经历让我很早就明白:我们常说“AI在看”,这其实是一个极具误导性的拟人化说法。它不是在“看”,它是在“执行一个基于数据的模式匹配任务”。
作为管理者或产品经理,如果混淆了这两者,你就会对AI产生不切实际的幻想,你会问:“为什么我换了个摄像头角度,它就不认识了?” 答案很简单:因为“数学输入”变了。
我们必须抛弃“AI在像人一样思考”的幻想,转而建立“AI是在用数学工具解决特定问题”的工程思维。这是我们开启CV之旅的第一块基石。
二、 AI之眼的“技能树”:从看清到看懂的四大任务
既然机器的“看见”是“执行任务”,那么它具体能执行哪些任务呢?
在过去的几十年里,计算机视觉已经分化出了一套清晰的“技能树”。理解这个“技能树”,你就理解了90%的CV应用在做什么。我们可以把它想象成一个孩子学习认识世界的过程:
2.1 任务一:图像分类(Image Classification)
- 它回答什么:“这是什么?”
- 通俗比喻:给孩子看一张卡片,他只需要回答“猫”或者“狗”。
- 工作方式:它“看”整张图片,然后给这张图片打上一个单一的标签。
- 产业应用:
- 你的相册自动将照片归类为“风景”、“美食”、“合影”。
- 在保险理赔中,系统首先要对上传的单据进行分类:“这是‘发票’、‘定损单’还是‘身份证’?” 在医疗影像中,系统判断一张X光片是“正常”还是“疑似病变”。
2.2 任务二:目标检测(Object Detection)
- 它回答什么:“它在哪里?”
- 通俗比喻:孩子不仅要说出“猫”,还要能用手指指出来:“猫在这里”。
- 工作方式:它不再是看整张图,而是要在图上画出一个个“边界框”(Bounding Box),并标注出框里是什么。
- 产业应用:
- 自动驾驶汽车“看见”前方10米处有一个“行人”框,50米处有一个“车辆”框。
- 安防摄像头在“人群”框中检测到“未戴安全帽”的“人”框。
- 在我们的SaaS客户(某大型银行)的视频柜台(VTM)业务中,系统需要实时检测“人脸”框和“身份证”框是否同时出现在指定区域内。
2.3 任务三:图像分割(Image Segmentation)
- 它回答什么:“它的精确边界在哪里?”
- 通俗比喻:孩子不再是指一下,而是要用画笔沿着猫的轮廓,把它完整地涂上颜色。
- 工作方式:这是最精细的任务。它要对图像中的每一个像素进行分类。
- 语义分割(Semantic Segmentation):把所有同类的东西涂成一个颜色。比如,把图上所有的“天空”涂成蓝色,所有的“树”涂成绿色。
- 实例分割(Instance Segmentation):更进一步,它要区分开每一个个体。比如,把图上的“猫1”涂成红色,“猫2”涂成黄色。
- 产业应用:
- 自动驾驶的“可行驶区域”检测:系统必须像素级地分割出哪部分是“路面”,哪部分是“障碍物”。
- 医疗影像(如CT/MRI):医生需要AI精确勾勒出肿瘤的轮廓,以辅助诊断或制定放疗计划。
- 视频会议的“虚拟背景”:系统在实时分割出你的“人物轮廓”,然后替换掉背景。
2.4 任务四:识别/度量(Recognition / Metric Learning)
- 它回答什么:“你是谁?”
- 通俗比喻:孩子不仅认识“人脸”,还能认出“这是妈妈”。
- 工作方式:这是一种更高级的任务。它不是要回答“是什么”,而是要回答“这一个体”与数据库中的“哪一个体”最相似。
- 产业应用:
- “刷脸支付”和“人脸门禁”:系统计算你的人脸特征,并与底库中的“你”的特征进行比对。
- 车辆重识别(Re-ID):在安防中,系统要确认A路口出现的“白色SUV”,是否就是B路口出现的“同一辆”。
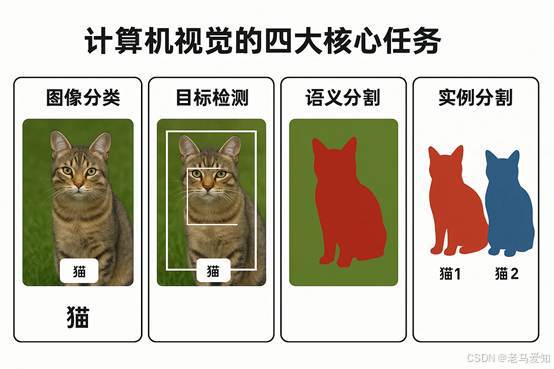
计算机视觉的四大核心任务
三、 为什么是现在?CV成为“AI主战场”的三大驱动力
你可能会问,计算机视觉的概念在20世纪60年代就有了,为什么直到最近十年才“飞入寻常百姓家”?
作为一个见证了通信技术从2G到5G、计算架构从大型机到云计算SaaS的从业者,我深知,任何技术的爆发,都不是“单一”的天才突破,而是“多重”基础设施的共同成熟。
CV的爆发,正是由三大支柱共同撑起的:
3.1 燃料:数据的洪流(Big Data)
AI的燃料是数据。而在过去十年,我们成了“视觉数据”的超级生产者。
- CT(通信技术)的演进:4G、5G的普及,让高带宽的视频流成为可能。
- IoT(物联网)的爆发:无处不在的摄像头(手机、安防、车载、工业),从“被动记录”转向“主动采集”。
- 互联网的激励:社交媒体、短视频平台(如抖音、快手)激励着全球数十亿人每天上传海量的、已标注的(比如带#标签)视觉数据。
在SaaS领域,我们不再愁“没数据”,而是愁“数据处理不过来”。
3.2 引擎:算法的革命(CNN)
如果数据是燃料,那算法就是引擎。
在2012年之前,我们用的是“手动挡”引擎(即下一篇要讲的SIFT、HOG等经典算法)。工程师需要像个老工匠一样,“手动”设计特征,告诉机器“你要去找边缘”、“你要去数角点”。
2012年,ImageNet竞赛。一个名为AlexNet的模型横空出世,它采用了一种叫卷积神经网络(CNN)的“自动挡”引擎。工程师不再需要手动设计特征,而是设计一个“学习框架”,让机器自己从海量数据中“悟”出哪些特征最重要。
这是CV历史上最关键的“iPhone时刻”。它让识别准确率产生了质的飞跃,直接开启了CV的黄金十年。
3.3 道路:算力的基建(Computing Power)
有了燃料(数据)和引擎(算法),还需要有能让它们跑起来的“高速公路”——算力。
- GPU(图形处理器):英伟达(NVIDIA)的GPU最初是为游戏玩家设计的,却意外地发现其并行计算架构完美契合了CNN的数学需求。
- 云计算:云服务商(如AWS, Azure, 阿里云, 腾讯云)将昂贵的算力“SaaS化”,让中小型企业和开发者也能以低成本租用到强大的算力,极大地降低了AI的准入门槛。
数据、算法、算力——这三者的螺旋式上升,共同引爆了计算机视觉的“寒武纪大爆发”。
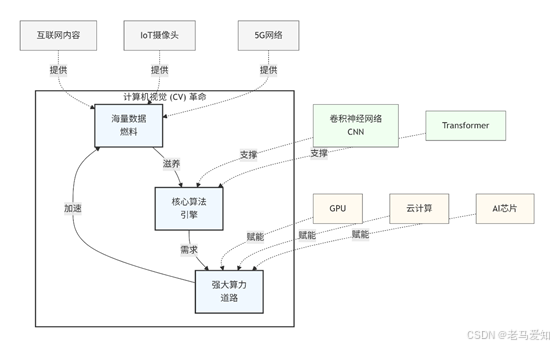
引爆计算机视觉革命的三大支柱
四、 从“看见”到“赋能”:AI之眼在产业中的真实价值
好了,我们理解了CV的“是什么”(四大任务)和“为什么”(三大支柱)。现在,我们回到那个最根本的问题:它有什么用?
作为一名30年的To B(面向企业)从业者,我的答案很直接:CV的价值,不在于“看见”,而在于“赋能”——它通过“看见”来优化业务流程、降低风险、创造新价值。
我们来看几个离我们生活很近的、已经发生深刻变革的领域:
4.1 场景一:智慧安防
- 它解决了什么痛点?
- (过去) 无尽的录像带。传统的安防系统(CCTV)是“被动取证”。事故发生了,我们再去调监控,人力回看几天几夜。
- (现在) AI-CV 实现了“主动预警”。
- CV如何赋能?
- 目标检测:自动识别“人”、“车辆”、“火焰”、“烟雾”。
- 行为识别:在银行、机场等关键区域,系统不再只是“录像”,它在“理解”行为。它能识别“人群异常聚集”、“快速奔跑”、“翻越围栏”、“滞留(如有人在ATM机前逗留过久)”。
- 人脸识别:用于门禁、追逃、访客管理。
- 价值(对决策者而言):不是“装了摄像头”,而是“安全风险被主动管理了”。
4.2 场景二:工业制造(工业4.0)
- 它解决了什么痛点?
- 人工质检的“极限”。在高速产线上,人眼会疲劳、会出错、速度有上限,且无法检测微米级的缺陷。
- CV如何赋能?
- (熟悉) 缺陷检测:利用高分辨率相机+图像分类/分割模型,24/7不知疲倦地检测产品表面的划痕、污点、裂纹、气泡。
- (意外) 引导与定位:它不只是“看”,还在“指挥”。CV系统引导机械臂,实现微米级的精准抓取、装配和焊接。
- 价值:降本增效、提质。机器视觉的精度和速度,直接决定了高端制造业(如芯片、面板、新能源电池)的良品率。
4.3 场景三:自动驾驶
- 它解决了什么痛点?
- 人类驾驶员的“感知局限”——我们会分神、会疲劳、有视野盲区。
- CV如何赋能?
- 这是CV任务的“集大成者”。一辆自动驾驶汽车,在同一时刻,必须并发执行:
- 图像分割:识别可行驶区域、车道线。
- 目标检测:识别行人、车辆、交通信号灯。
- 3D重建(后续专栏会讲):通过多摄像头(立体视觉)或LiDAR(激光雷达)融合,理解世界的“深度”和“空间”。
- 这是CV任务的“集大成者”。一辆自动驾驶汽车,在同一时刻,必须并发执行:
- 价值:安全与效率。虽然完全的自动驾驶(L5)依然遥远,但CV技术已经通过L2/L3辅助驾驶(如车道保持、自动刹车)极大地提升了我们的驾驶安全。
4.4 场景四:银行与保险
- 它解决了什么痛点?
- 海量的纸质单据、身份验证的风险、理赔的效率。
- CV如何赋能?
- OCR(光学字符识别):这是CV在金融业最早、最成熟的应用。自动识别身份证、银行卡、发票、合同,实现“秒级”录入。
- 人脸识别(活体检测):在银行APP远程开户或大额转账时,系统不仅要“识别”你的人脸,还要通过“活体检测”(要求你眨眼、张嘴)来确认你是“真人”,而不是一张照片或一段视频。这是“CV对抗”的典型场景。
- 保险定损:当发生车险时,用户只需拍照上传。CV系统会自动“检测”出“车型”,并“分割”出“损坏部件”(如“左前大灯”、“保险杠”),甚至自动“评估”损伤程度,极大加速了理赔流程。
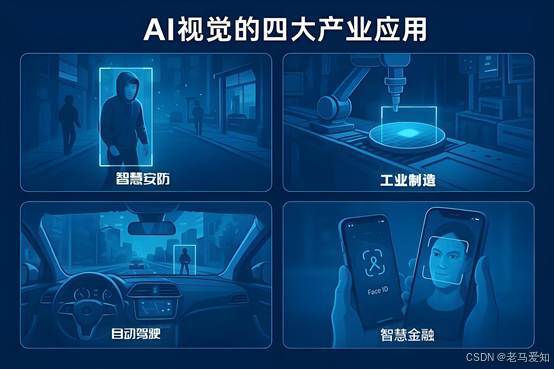
AI视觉的四大产业应用
五、 结语:这不仅是开始,更是“看见”未来的方式
回到我们最初的问题:机器真的“看见”了吗?
通过今天的旅程,我们的答案是:不,它没有像人一样“看见”。但它正在通过数学和计算,在一个个具体的任务上,实现“超越人类”的感知。
- 它没有人类的“直觉”,但它有24/7不眠不休的“精度”。
- 它没有人类的“情感”,但它有不带偏见、严格执行的“客观”。
- 它没有人类的“意识”,但它有处理海量数据、发现人眼无法察觉模式的“洞察力”。
理解CV,不是要让我们惊叹于“AI多像人”,而是要让我们学会“如何利用这种不像人的、强大的计算能力,来解决我们人类世界中真实存在的问题”。
在接下来的专栏中,我们将真正“解剖”这只AI之眼:
- (承上) 我们知道了CV的起点是“数字矩阵”。下一篇,《数字图像的“前世今生”》,我们将深入探索这个“矩阵”的奥秘,看看“像素”、“通道”、“色彩空间”是如何构建起机器视觉的基石。
- (启下) 我们知道了CV的爆发点是CNN。但在CNN出现前,人类最聪明的头脑是如何“手动”教机器“看见”的?《CNN诞生前的“蛮荒时代”》,我们将带你领略SIFT、HOG等经典算法的精妙与局限,只有理解了“过去”,才能真正领会“现在”的革命性。
欢迎你,与我一同踏上这段从像素到智能的旅程。这不仅是关于技术的学习,更是关于我们如何构建未来“智能世界”的深度思考。
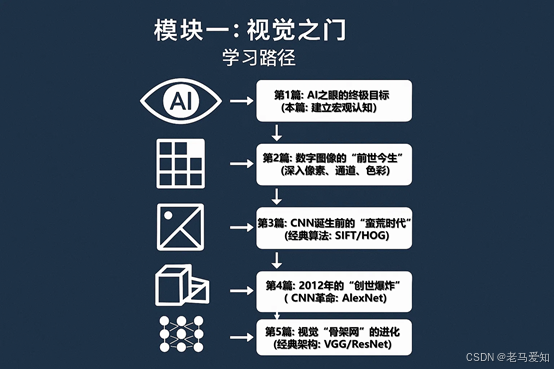
模块一:视觉之门 学习路径


















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











