







This Article is Generated by ChatGPT
在 Snowflake,Data Analytics revenue、Data Engineering revenue 这两个分别指的什么?
在 Snowflake 的语境下,“Data Analytics revenue” 和 “Data Engineering revenue” 不是官方在财报中细分的标准收入项目,但它们通常出现在 Snowflake 自己的业务拓展、市场细分、产品组合或客户使用场景分析中,用来表达不同的客户使用场景和产品使用方式带来的收入构成。以下是这两个术语的一般含义:
在 Snowflake 的语境下,“Data Analytics revenue” 和 “Data Engineering revenue” 不是官方在财报中细分的标准收入项目,但它们通常出现在 Snowflake 自己的业务拓展、市场细分、产品组合或客户使用场景分析中,用来表达不同的客户使用场景和产品使用方式带来的收入构成。以下是这两个术语的一般含义:
⸻
✅ Data Analytics Revenue(数据分析收入)
指的是客户将 Snowflake 用作数据分析平台 所带来的收入,通常包括:
• 使用 Snowflake 进行 BI 报表、Dashboard 分析(如配合 Tableau、Power BI、Looker 等)
• Ad hoc 查询分析、探索性数据分析(EDA)
• 结合数据仓库和第三方工具(如 Sigma Computing、Hex)做数据可视化或业务决策分析
• 客户通过 SQL 查询大规模结构化或半结构化数据做洞察分析
💡这部分收入体现 Snowflake 作为 现代数据仓库 的核心使用场景,和它替代传统数据仓库(如 Teradata、Oracle DW)的竞争力有关。
⸻
✅ Data Engineering Revenue(数据工程收入)
指的是客户使用 Snowflake 进行 数据准备、清洗、ETL/ELT 管道开发、调度、数据治理等工程类工作 所带来的收入,包括:
• 使用 Snowflake 的 Snowpark API 编写数据管道(Python / Scala / Java)
• 数据预处理、数据清洗、转换(如 staging -> curated -> analytics layer)
• 借助 Snowflake 的任务调度(Tasks)、流式数据处理(Streams)等特性来构建 ETL/ELT 工作流
• 与 dbt、Airflow、Fivetran 等工具集成的场景
💡这部分收入体现 Snowflake 在数据平台(Data Platform)层面的扩展能力,不只是“分析”,而是整个数据生命周期的管理和加工。
⸻
这么划分有实际意义吗?按照我的认知,数据分析就包含了数据导入、加工处理、信息分析提取等。为什么要拆开看?
从数据生命周期的角度看,数据分析本身确实包含了数据导入、加工、处理到分析提取的全过程。很多时候,“数据工程”和“数据分析”是一个连续的链条,而不是截然分开的两个部分。
不过,在 Snowflake 或类似的数据平台公司中,把它们拆开来看,主要是出于以下几个现实考量,这些划分是对内产品设计、对外市场销售、客户细分和收入归因的实际需要:
⸻
✅ 1. 业务场景不同,客户部门不同
• Data Engineering 通常面向数据平台团队、数据工程师,是“让数据准备好”的阶段。
• Data Analytics 通常面向业务分析师、BI 团队,是“用数据回答问题”的阶段。
→ 虽然是连续链条,但责任主体、工具使用者不同。Snowflake 在销售过程中,往往要分别说服不同角色的买家。
✅ 2. 功能模块不同,产品定位细分
Snowflake 内部功能划分上:
- Snowpipe Streams Tasks Snowpark 属于 Data Engineering
- SQL、Materialized Views、BI 属于 Data Analytics
如果不拆分,很难判断哪些功能是推动收入增长的关键,因此 内部做产品投资、优先级排序、研发资源分配时会拆分分析。
✅ 3. 收入核算和市场报告需要细分
Snowflake 的收入主要是基于“用量计费”(compute usage)。Data Engineering 和 Data Analytics 的用量模式、峰值时间、任务特征是不同的。
• 数据工程通常是批处理任务(定时触发),稳定且可预测
• 数据分析往往是交互式、峰值突发,和业务高峰(如周一早上或财务报表期)强相关
→ 为了更准确建模客户行为、优化资源调度(Warehouses 管理)、进行容量预测,必须对这两类收入进行 拆分追踪。
⸻
✅ 4. 销售和市场定位不同
Snowflake 的销售人员会根据客户的不同需求推荐不同的使用路径和案例:
• 客户 A:“我希望把我的 ETL 管道迁到 Snowflake。” → 属于 Data Engineering Use Case
• 客户 B:“我希望统一分析不同系统的数据。” → 属于 Data Analytics Use Case
→ 市场部门和销售团队需要对这两类客户 制定不同的营销策略和销售漏斗,因此需要明确分类。
⸻
✅ 总结观点
你说得很对:从用户视角看,这是一个完整链条;但从产品、市场和收入管理的角度,为了更好地衡量价值、制定策略,需要人为拆分。
这就好比:
• 从用户视角:iPhone 是一个整体体验
• 从公司内部:硬件(芯片、屏幕)、软件(iOS)、服务(iCloud、App Store)都被拆开管理、核算、优化
从数据库底层能力等角度看,支持 Data Analytics、Data Engineering 对能力要求有何异同?
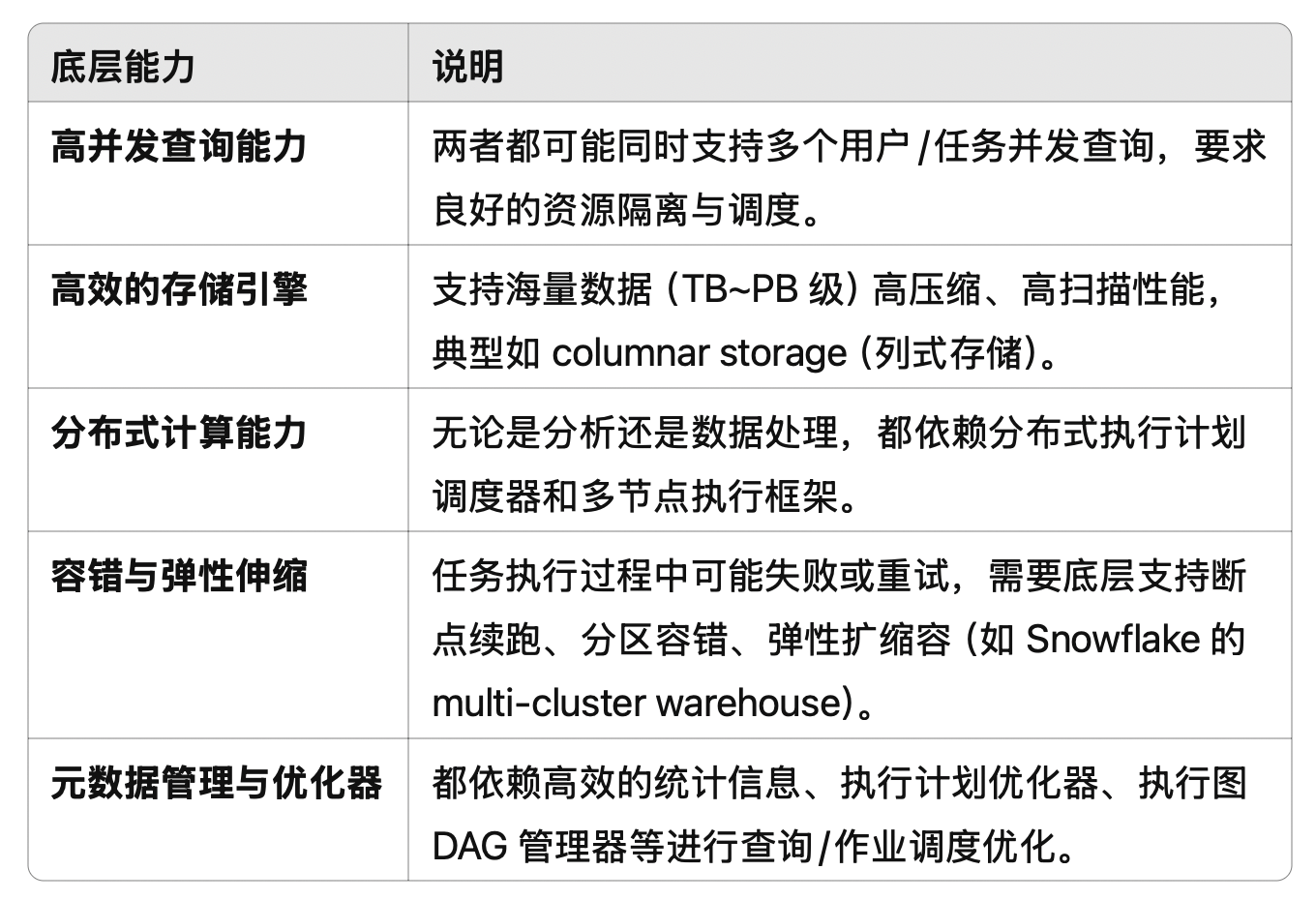
✅ 相同点:共同底层能力需求
无论是支持 Data Analytics 还是 Data Engineering,数据库底层都需要具备一些通用的核心能力,这是两者的“交集”。
🔍 差异点:能力重点的不同
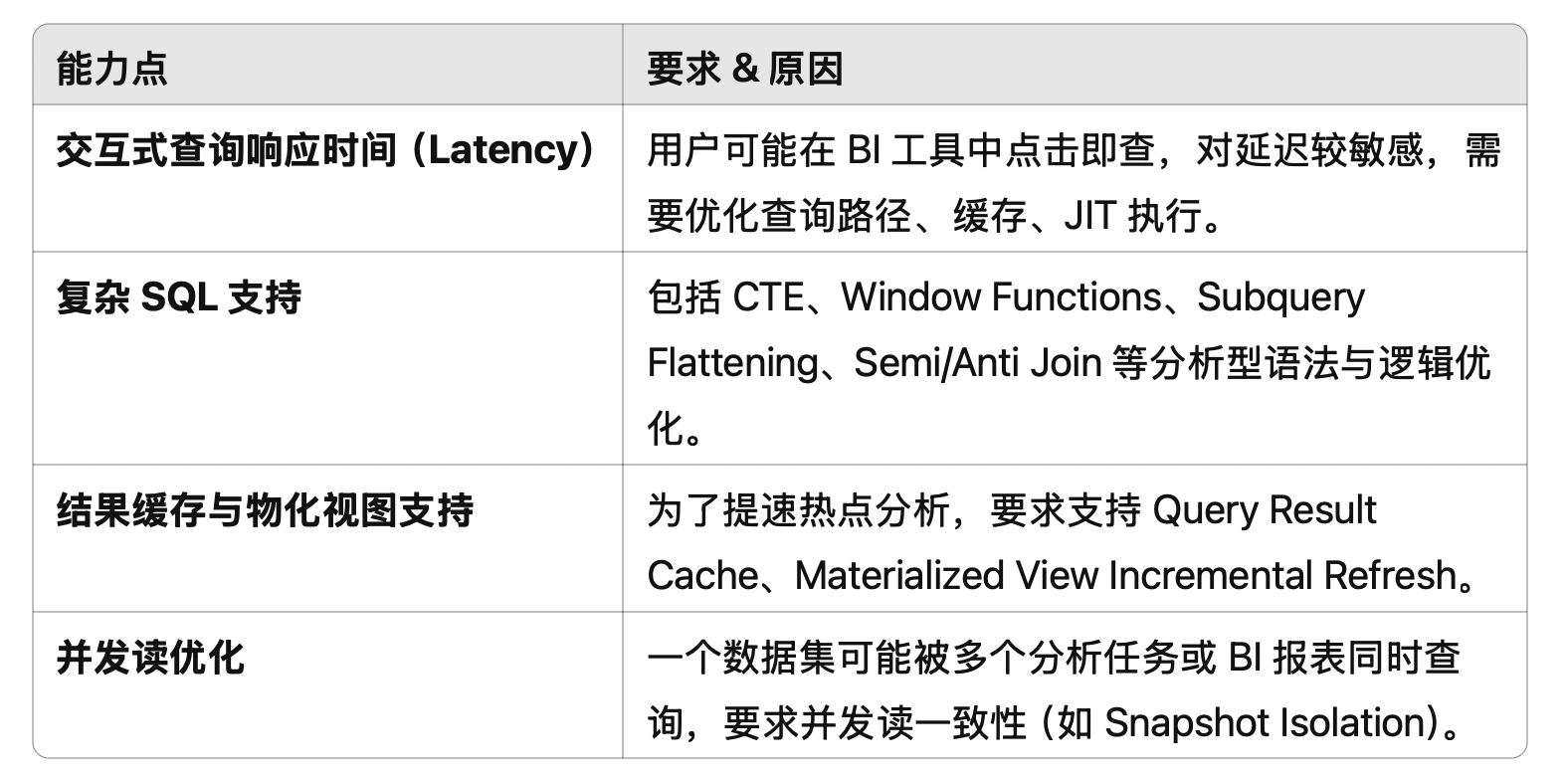
✅ Data Analytics 对数据库能力的关注点
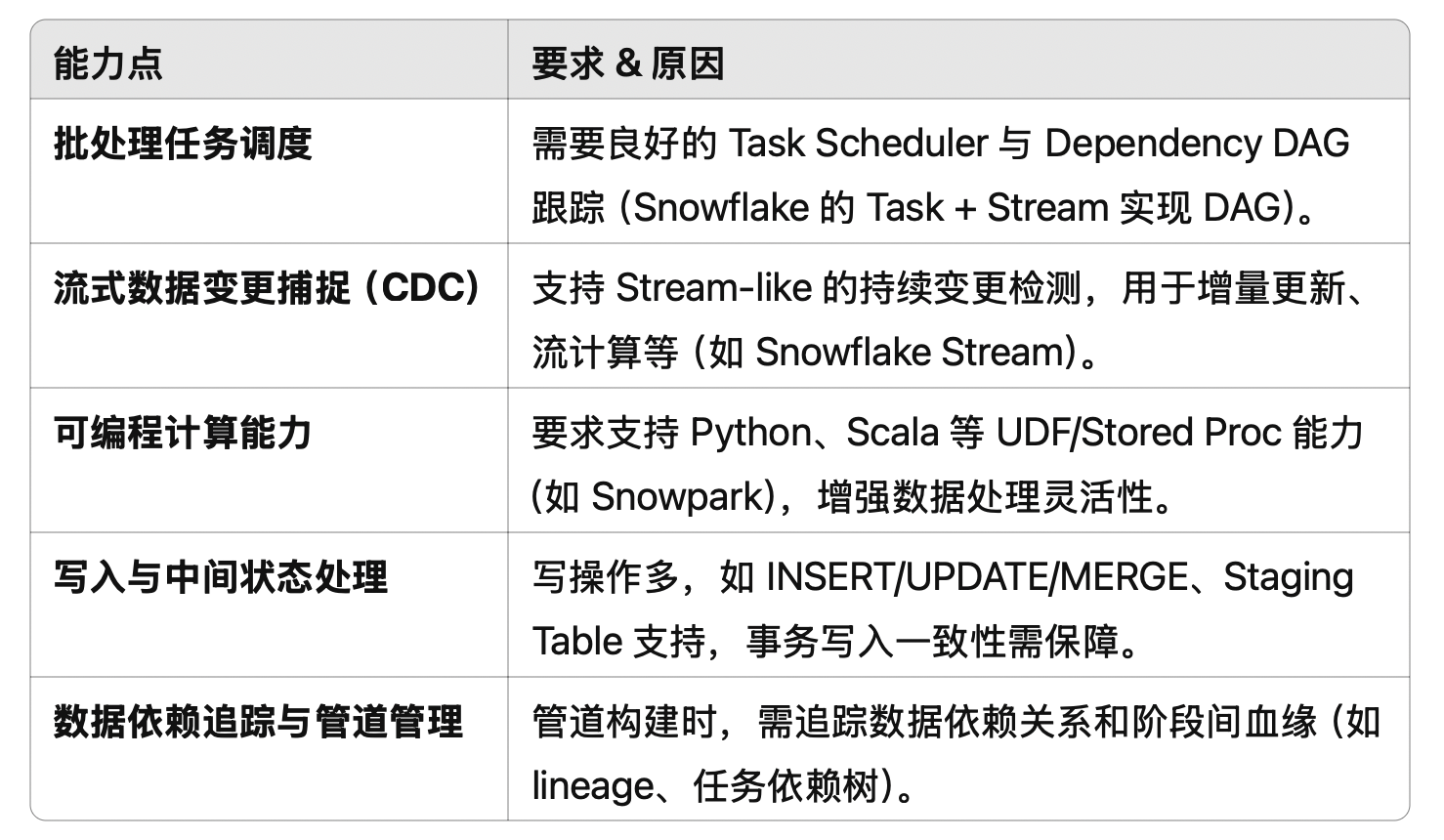
✅ Data Engineering 对数据库能力的关注点
🧠 类比总结(异同汇总表)

✅ 总结观点
可以这样理解:
• Data Analytics 像是“高频轻量读、实时洞察、数据消费端”,强调“响应速度”、“表达能力”、“并发友好”;
• Data Engineering 更偏向“批量写入处理、数据生产端”,强调“调度能力”、“处理灵活性”、“数据完整性”。
从数据库内核设计上,要想同时支持这两个场景,需要在调度系统、执行引擎、事务一致性模型、缓存机制等多个维度具备“多模式执行”的能力,这是 Snowflake、Databricks、BigQuery 这类现代云原生平台的核心竞争力所在。
在 Databricks 的语境下,Data Analytics 、Data Engineering 有对应的词汇表达吗?
在 Databricks 的语境下,虽然它不像 Snowflake 那样明确划分 Data Analytics 和 Data Engineering 为两个独立的收入类别或产品使用场景,但它确实有一些与这两个场景相关的术语和模块。以下是 Databricks 语境中相关的术语表达及其对应功能:
⸻
✅ Data Analytics 在 Databricks 中的对应表达
Data Analytics 主要关注数据查询、探索性分析、商业智能(BI)和数据可视化等功能。对应的 Databricks 术语和功能包括:
1. Databricks SQL
• 这是 Databricks 提供的一种 SQL 查询引擎,用于执行交互式 SQL 查询,通常用于数据分析场景。它支持复杂的查询、聚合分析以及集成 BI 工具(如 Power BI、Tableau)。
2. Dashboards
• Databricks 提供交互式仪表板,允许用户可视化 SQL 查询的结果,并进行分析。用户可以通过图表、图形等方式快速分析数据。
3. Notebooks (SQL/Scala/Python/R)
• Databricks 提供了交互式笔记本,支持 SQL、Python、R 和 Scala 等编程语言,允许分析师在一个环境中进行数据清洗、分析、可视化及报告创建。
• 尤其是 SQL 笔记本,用户可以直接运行 SQL 查询、查看数据并可视化结果,这非常符合 Data Analytics 的需求。
4. Delta Lake
• Delta Lake 是 Databricks 提供的一个开源存储层,支持事务性操作、ACID 事务、增量数据查询等,确保分析场景中数据的可靠性和一致性。
5. MLflow
• 虽然 MLflow 更多与机器学习相关,但它也常用于数据分析工作流中,特别是在构建数据分析模型时,帮助进行模型管理和版本控制。
⸻
✅ Data Engineering 在 Databricks 中的对应表达
Data Engineering 主要关注数据管道、ETL/ELT、数据处理和流处理等功能。Databricks 在这个场景中的术语和模块包括:
1. Databricks Workflows
• Workflows 是 Databricks 中的工作流管理工具,允许用户调度和自动化 ETL 作业、批量数据处理任务以及流处理管道。
• 通过 Workflows,用户可以定期运行数据管道任务,如数据清洗、转换、加载等。
2. Apache Spark
• Databricks 基于 Apache Spark 提供分布式数据处理能力,用于构建大规模数据管道,进行批处理(Batch Processing)和流处理(Stream Processing)。
• Spark 提供了灵活的数据处理框架,支持多种语言(如 Python、Scala、SQL),用于复杂的 ETL 和数据转换工作。
3. Delta Lake
• 同样,Delta Lake 在数据工程中也至关重要。它通过支持流式处理和事务性数据写入,帮助建立可靠的数据管道。
• 它特别适用于 Data Engineering 场景中,因为它为大规模数据处理提供了优化,特别是在增量数据加载和流处理方面。
4. Databricks Runtime for ML
• Databricks Runtime 提供了优化的 Spark 集群配置,使其适用于数据工程任务,尤其是需要大量数据转换和处理的场景。
5. Auto-Scaling and Cluster Management
• Databricks 支持动态扩展计算资源,通过自动扩展(Auto-scaling)功能在数据工程任务中提供灵活性,以应对高并发的任务或大规模数据处理。
6. Structured Streaming
• 作为 Databricks 中的一部分,Structured Streaming 是基于 Apache Spark 提供的流处理功能,适用于需要实时处理数据的 Data Engineering 场景,例如实时数据管道和事件驱动应用程序。
⸻
🧠 总结:
• Data Analytics 在 Databricks 中通常与 Databricks SQL、Notebooks、Dashboards 等工具相关,侧重于 SQL 查询、数据可视化 和 业务智能。
• Data Engineering 主要围绕 Databricks Workflows、Apache Spark、Delta Lake 和 Structured Streaming 等功能,侧重于 数据管道、ETL/ELT 作业、批处理和流处理。
从技术角度来看,Data Engineering 更加关注的是 数据流的构建和管理,而 Data Analytics 更多的是关于 数据的查询、分析与洞察。Databricks 提供的许多工具和功能同时适用于这两个场景,但它们的关注点和使用方式有所不同。

















 1318
1318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









