






我至今都忘不了,曾经有一次,我在打开一个文件时,最终得到的是一个int类型的数字,一个小小的int类型,竟然能描述一个文件?这让我感到十分奇怪。直到对计算机存储的不断了解,我才知道返回的int类型是一个文件句柄。
总结(太长不看)
打开文件操作的关键在于,分配一个文件描述符file,正确设置f_mapping文件地址空间和f_op文件操作表,在打开文件操作表中找到一个存放它的文件句柄。这样,以后对文件的操作就是根据文件句柄->文件描述符,从描述符中提供的operations完成。
文件句柄
在我们使用文件的时候,文件的打开操作是一个再简单不过的事情,给计算机一个文件路径,这个文件就会被打开,系统所返回的就是一个文件句柄,通过这个文件句柄来对文件进行访问。这个句柄是一个int类型。
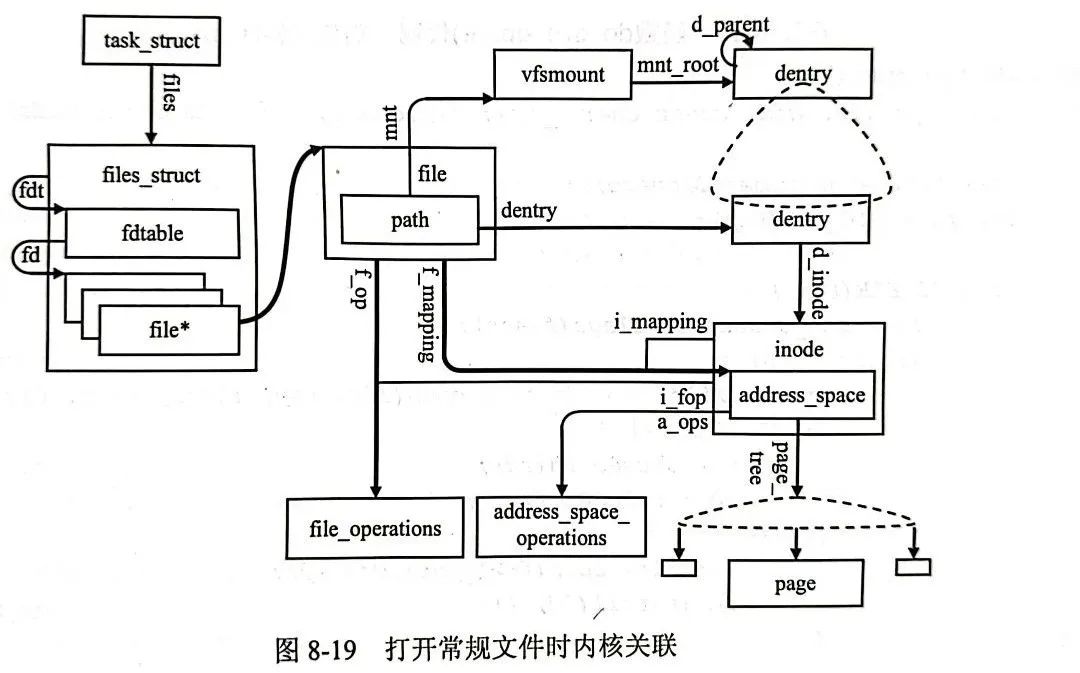
每个进程可以打开多个文件,它们被组织成打开文件表的形式,实际上是指向文件描述符(file类型)的指针数组,数组下标即为文件句柄,因此给定一个文件句柄,可以找到一个file指针,于是可以访问文件描述符file。
数据结构
在内核中,打开文件表由结构体fdtable描述:
struct fdtable {
unsigned int max_fds; // 指针数组项数
struct file __rcu **fd; /* current fd array 指针数组 */
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits; // 三个bitmap结构
struct rcu_head rcu; // RCU机制域
};对于文件描述符file,刻画了一个文件实例的信息:
struct file {
union {
struct llist_node fu_llist; // 链入到所属文件系统超级块的s_files链表链接件
struct rcu_head fu_rcuhead; // RCU机制
} f_u;
struct path f_path; // 文件路径 vfsmount-dentry二元组
struct inode *f_inode; /* cached value */
const struct file_operations *f_op; // 文件操作表
/*
* Protects f_ep, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock; // 用户保护自旋锁
enum rw_hint f_write_hint; // F2FS中这个项和文件热度有关
atomic_long_t f_count; // 文件引用计数
unsigned int f_flags; // 打开文件时指定标志位
fmode_t f_mode; // 进程访问模式
struct mutex f_pos_lock; // 应该是用于保护f_pos的lock
loff_t f_pos; // 文件读写指针偏移值
struct fown_struct f_owner; // 通过信号进行IO事件通知的数据
const struct cred *f_cred;
struct file_ra_state f_ra; // 文件预读状态
u64 f_version; // 文件版本号,使用后递增
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data; // 文件系统或设备驱动的私有指针
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct hlist_head *f_ep; // 轮询等待
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping; // 指向文件地址空间描述符
errseq_t f_wb_err;
errseq_t f_sb_err; /* for syncfs */
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */在这个file结构中,比较重要需要我们关注的还有两个结构,一个是提供的操作表,它告诉我们文件系统对该文件所提供的一些方法的回调函数:
struct file_operations {
struct module *owner;
/* 更新读写指针 第二个参数为偏移值,第三个参数为偏移的相对位置(相对文件头、尾、当前等)*/
loff_t (*llseek) (struct file *, loff_t, int);
/* 读取文件数据 第二个参数为存放数据的缓冲区,第三个参数为读取字节数,第四个参数为读取的开始位置*/
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
/* 写入文件数据 第二个参数为存放数据的缓冲区,第三个参数为写入字节数,第四个参数为写入的开始位置*/
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
/* 异步读出文件数据 第一个参数为内核io控制块指针,第二个参数为存放数据的IO向量 */
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
/* 异步写入文件数据 第一个参数为内核io控制块指针,第二个参数为存放数据的IO向量 */
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, bool spin);
int (*iterate) (struct file *, struct dir_context *);
int (*iterate_shared) (struct file *, struct dir_context *);
__poll_t (*poll) (struct file *, struct poll_table_struct *);
/* 不需要大内核锁 ioctl */
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
/* 在64位系统下进行32位系统调用时 ioctl */
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
/* 用户空间的虚拟内存地址与内核空间的page cache进行映射 */
int (*mmap) (struct file *, struct vm_area_struct *);
unsigned long mmap_supported_flags;
/* 在inode被打开时调用。在VFS打开一个文件时,它创建一个file描述符,针对他调用open方法,在该方法中初始化文件描述符 */
int (*open) (struct inode *, struct file *);
/* 被close系统调用于文件冲刷 */
int (*flush) (struct file *, fl_owner_t id);
/* 在文件最后一个引用关闭时调用 */
int (*release) (struct inode *, struct file *);
/* 同步文件时调用,冲刷到磁盘 */
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
ssize_t (*copy_file_range)(struct file *, loff_t, struct file *,
loff_t, size_t, unsigned int);
loff_t (*remap_file_range)(struct file *file_in, loff_t pos_in,
struct file *file_out, loff_t pos_out,
loff_t len, unsigned int remap_flags);
int (*fadvise)(struct file *, loff_t, loff_t, int);
} __randomize_layout;以F2FS为例,它提供了以下文件操作:
const struct file_operations f2fs_file_operations = {
.llseek = f2fs_llseek,
.read_iter = f2fs_file_read_iter,
.write_iter = f2fs_file_write_iter,
.open = f2fs_file_open,
.release = f2fs_release_file,
.mmap = f2fs_file_mmap,
.flush = f2fs_file_flush,
.fsync = f2fs_sync_file,
.fallocate = f2fs_fallocate,
.unlocked_ioctl = f2fs_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = f2fs_compat_ioctl,
#endif
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fadvise = f2fs_file_fadvise,
};以及对于地址空间的管理文件地址空间描述符address_space结构f_mapping:
/**
* struct address_space - Contents of a cacheable, mappable object.
* @host: Owner, either the inode or the block_device.
* @i_pages: Cached pages.
* @invalidate_lock: Guards coherency between page cache contents and
* file offset->disk block mappings in the filesystem during invalidates.
* It is also used to block modification of page cache contents through
* memory mappings.
* @gfp_mask: Memory allocation flags to use for allocating pages.
* @i_mmap_writable: Number of VM_SHARED mappings.
* @nr_thps: Number of THPs in the pagecache (non-shmem only).
* @i_mmap: Tree of private and shared mappings.
* @i_mmap_rwsem: Protects @i_mmap and @i_mmap_writable.
* @nrpages: Number of page entries, protected by the i_pages lock.
* @writeback_index: Writeback starts here.
* @a_ops: Methods.
* @flags: Error bits and flags (AS_*).
* @wb_err: The most recent error which has occurred.
* @private_lock: For use by the owner of the address_space.
* @private_list: For use by the owner of the address_space.
* @private_data: For use by the owner of the address_space.
*/
struct address_space {
struct inode *host;
struct xarray i_pages;
struct rw_semaphore invalidate_lock;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;该结构体用于管理inode映射到内存页page。将文件系统中的数据与file对应的内存绑定,它由inode->i_mapping而来,而后者在inode创建时赋予(https://blog.csdn.net/jinking01/article/details/106490467)
通过该描述符也提供了对于地址空间的操作表:
struct address_space_operations {
/* 写页面 */
int (*writepage)(struct page *page, struct writeback_control *wbc);
/* 读页面 */
int (*readpage)(struct file *, struct page *);
/* Write back some dirty pages from this mapping. */
int (*writepages)(struct address_space *, struct writeback_control *);
/* 标记脏页 Set a page dirty. Return true if this dirtied it */
int (*set_page_dirty)(struct page *page);
/*
* Reads in the requested pages. Unlike ->readpage(), this is
* PURELY used for read-ahead!.
*/
int (*readpages)(struct file *filp, struct address_space *mapping,
struct list_head *pages, unsigned nr_pages);
void (*readahead)(struct readahead_control *);
int (*write_begin)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
sector_t (*bmap)(struct address_space *, sector_t);
void (*invalidatepage) (struct page *, unsigned int, unsigned int);
int (*releasepage) (struct page *, gfp_t);
void (*freepage)(struct page *);
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
/*
* migrate the contents of a page to the specified target. If
* migrate_mode is MIGRATE_ASYNC, it must not block.
*/
int (*migratepage) (struct address_space *,
struct page *, struct page *, enum migrate_mode);
bool (*isolate_page)(struct page *, isolate_mode_t);
void (*putback_page)(struct page *);
int (*launder_page) (struct page *);
int (*is_partially_uptodate) (struct page *, unsigned long,
unsigned long);
void (*is_dirty_writeback) (struct page *, bool *, bool *);
int (*error_remove_page)(struct address_space *, struct page *);
/* swapfile support */
int (*swap_activate)(struct swap_info_struct *sis, struct file *file,
sector_t *span);
void (*swap_deactivate)(struct file *file);
};每个进程都需要分配一个打开文件表以及对应数量的指针数组,对于大多数进程而言打开文件的数量是有限的,一种优化设计方式是为每个进程分配少量数目的文件描述符指针数组,当进程确实需要更多的指针时,可以动态分配,为此,进程并不直接使用打开文件表,而是引入一个新的files_struct结构,将它作为进程描述符的一个域。
struct files_struct {
/*
* read mostly part
*/
atomic_t count; // 引用计数
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab; // 内嵌的打开文件表
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp; // 锁保护
unsigned int next_fd; // 要分配的下一个句柄值
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1]; // 内嵌的三个位图
struct file __rcu * fd_array[NR_OPEN_DEFAULT]; // 内嵌的文件对象指针数组
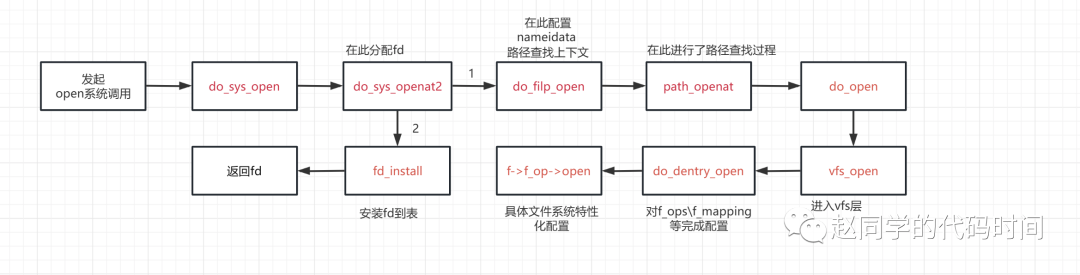
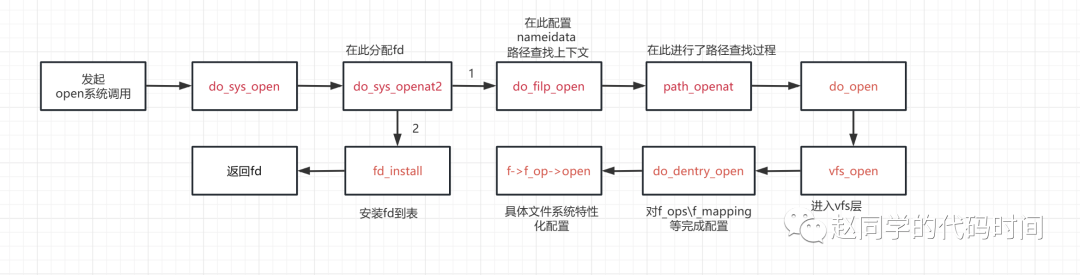
};打开文件
打开文件操作的关键在于,分配一个文件描述符file,正确设置f_mapping文件地址空间和f_op文件操作表,在打开文件操作表中找到一个存放它的文件句柄。这样,以后对文件的操作就是根据文件句柄->文件描述符,从描述符中提供的operations完成。
下面跟踪open系统调用过程:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
---
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_how how = build_open_how(flags, mode);
return do_sys_openat2(dfd, filename, &how);
}
---
static long do_sys_openat2(int dfd, const char __user *filename,
struct open_how *how)
{
struct open_flags op;
int fd = build_open_flags(how, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename); // 将文件路径名从用户空间复制到内核空间
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(how->flags); // 找到一个可用的文件句柄
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op); // 打开文件,返回对应文件描述符
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f); // 将打开文件“安装”到打开文件表
}
}
putname(tmp);
return fd;
}dfd是一个在内核空间解析文件路径时使用的,关于路径解析的部分暂未记录,在解析路径时,如果为绝对路径,那么dfd没有作用,如果为相对路径,相对的起点就是dfd指向的位置,如果dfd为特殊值AT_FDCWD(本次也是),被解释为相对于调用进程的当前工作目录。
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd; // 路径查找上下文结构
int flags = op->lookup_flags; // 路径查找标志
struct file *filp; // 返回的file指针
set_nameidata(&nd, dfd, pathname, NULL); // 设置路径查找上下文nd
filp = path_openat(&nd, op, flags | LOOKUP_RCU); // 打开
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}
---
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
struct file *file;
int error;
file = alloc_empty_file(op->open_flag, current_cred()); // 根据flag生成一个空文件
if (IS_ERR(file))
return file;
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file);
// 按tmpfile方式打开 https://www.jianshu.com/p/a338f0705615
} else if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);
} else {
const char *s = path_init(nd, flags); // 路径查找初始化
while (!(error = link_path_walk(s, nd)) &&
(s = open_last_lookups(nd, file, op)) != NULL)
; // link_path_walk 逐个解析字符串路径分量到最后一个分量
if (!error)
//在这个目录下打开或创建(O_CREAT)
error = do_open(nd, file, op);
terminate_walk(nd);
}
if (likely(!error)) {
if (likely(file->f_mode & FMODE_OPENED))
return file;
WARN_ON(1);
error = -EINVAL;
}
fput(file);
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
return ERR_PTR(error);
}完成路径解析后,调用do_open完成最后一步。
/*
* Handle the last step of open()
*/
static int do_open(struct nameidata *nd,
struct file *file, const struct open_flags *op)
{
struct user_namespace *mnt_userns;
int open_flag = op->open_flag;
bool do_truncate;
int acc_mode;
int error;
if (!(file->f_mode & (FMODE_OPENED | FMODE_CREATED))) {
error = complete_walk(nd);
if (error)
return error;
}
if (!(file->f_mode & FMODE_CREATED))
audit_inode(nd->name, nd->path.dentry, 0);
mnt_userns = mnt_user_ns(nd->path.mnt);
// 如果是进行创建
if (open_flag & O_CREAT) {
if ((open_flag & O_EXCL) && !(file->f_mode & FMODE_CREATED))
return -EEXIST; // O_EXCL表示的是:如果使用O_CREAT时文件存在,就返回错误信息,它可以测试文件是否存在。
if (d_is_dir(nd->path.dentry))
return -EISDIR; // 目录不能创建
error = may_create_in_sticky(mnt_userns, nd,
d_backing_inode(nd->path.dentry));
if (unlikely(error))
return error;
}
if ((nd->flags & LOOKUP_DIRECTORY) && !d_can_lookup(nd->path.dentry))
return -ENOTDIR; // 要求最后一个分量必须是目录但是不是
do_truncate = false; // O_TRUNC标志,使用这个标志,在调用open函数打开文件的时候会将文件原本内容全部丢弃,文件大小变为0;
acc_mode = op->acc_mode; // 访问模式
if (file->f_mode & FMODE_CREATED) {
/* Don't check for write permission, don't truncate */
open_flag &= ~O_TRUNC;
acc_mode = 0;
} else if (d_is_reg(nd->path.dentry) && open_flag & O_TRUNC) {
error = mnt_want_write(nd->path.mnt);
if (error)
return error;
do_truncate = true;
}
error = may_open(mnt_userns, &nd->path, acc_mode, open_flag);
if (!error && !(file->f_mode & FMODE_OPENED))
error = vfs_open(&nd->path, file); // 进入vfs层
if (!error)
error = ima_file_check(file, op->acc_mode);
if (!error && do_truncate)
error = handle_truncate(mnt_userns, file);
if (unlikely(error > 0)) {
WARN_ON(1);
error = -EINVAL;
}
if (do_truncate)
mnt_drop_write(nd->path.mnt);
return error;
}第27行进行了粘滞位检查,对于一个多人可写的目录,如果设置了sticky,则每个用户仅能删除和改名自己的文件或目录;只能作用在目录上.普通文件设置无意义,且会被linux内核忽略,用户在设置Sticky权限的目录下新建的目录不会自动继承Sticky权限(https://zhuanlan.zhihu.com/p/347381358)。
在打开时用到了一些UNIX中的标记位,如:
O_TRUNC标志,在调用open函数打开文件的时候会将文件原本内容全部丢弃,文件大小变为0;
O_CREAT标志,在调用open函数打开文件时不存在则创建;
O_APPEND标志,使用write()写时采用尾追加;
O_EXCL标志: 如果同时指定了O_CREAT,而文件已经存在,则打开文件失败。
之后进入vfs层:
int vfs_open(const struct path *path, struct file *file)
{
file->f_path = *path;
// dentry -> inode
return do_dentry_open(file, d_backing_inode(path->dentry), NULL);
}
---
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *))
{
static const struct file_operations empty_fops = {};
int error;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
f->f_wb_err = filemap_sample_wb_err(f->f_mapping);
f->f_sb_err = file_sample_sb_err(f);
// 通过inode完成了对file的一些配置
if (unlikely(f->f_flags & O_PATH)) {
f->f_mode = FMODE_PATH | FMODE_OPENED;
f->f_op = &empty_fops;
return 0;
}
if (f->f_mode & FMODE_WRITE && !special_file(inode->i_mode)) {
error = get_write_access(inode);
if (unlikely(error))
goto cleanup_file;
error = __mnt_want_write(f->f_path.mnt);
if (unlikely(error)) {
put_write_access(inode);
goto cleanup_file;
}
f->f_mode |= FMODE_WRITER;
}
/* POSIX.1-2008/SUSv4 Section XSI 2.9.7 */
if (S_ISREG(inode->i_mode) || S_ISDIR(inode->i_mode))
f->f_mode |= FMODE_ATOMIC_POS;
f->f_op = fops_get(inode->i_fop); // 配置写操作表
if (WARN_ON(!f->f_op)) {
error = -ENODEV;
goto cleanup_all;
}
trace_android_vh_check_file_open(f);
error = security_file_open(f);
if (error)
goto cleanup_all;
error = break_lease(locks_inode(f), f->f_flags);
if (error)
goto cleanup_all;
/* normally all 3 are set; ->open() can clear them if needed */
f->f_mode |= FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (!open)
open = f->f_op->open;
if (open) {
error = open(inode, f); // 调用了fops里面的open函数
if (error)
goto cleanup_all;
}
f->f_mode |= FMODE_OPENED; // 标记为已打开
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(inode);
if ((f->f_mode & FMODE_READ) &&
likely(f->f_op->read || f->f_op->read_iter))
f->f_mode |= FMODE_CAN_READ;
if ((f->f_mode & FMODE_WRITE) &&
likely(f->f_op->write || f->f_op->write_iter))
f->f_mode |= FMODE_CAN_WRITE;
f->f_write_hint = WRITE_LIFE_NOT_SET; // 默认未设置生命周期,在F2FS中被用于hotness
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC); // 这几个标志位已处理,清除这几个标志位
// 预读状态设置
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
/* NB: we're sure to have correct a_ops only after f_op->open */
if (f->f_flags & O_DIRECT) {
if (!f->f_mapping->a_ops || !f->f_mapping->a_ops->direct_IO)
return -EINVAL;
}
/*
* XXX: Huge page cache doesn't support writing yet. Drop all page
* cache for this file before processing writes.
*/
if (f->f_mode & FMODE_WRITE) {
/*
* Paired with smp_mb() in collapse_file() to ensure nr_thps
* is up to date and the update to i_writecount by
* get_write_access() is visible. Ensures subsequent insertion
* of THPs into the page cache will fail.
*/
smp_mb();
if (filemap_nr_thps(inode->i_mapping)) {
struct address_space *mapping = inode->i_mapping;
filemap_invalidate_lock(inode->i_mapping);
/*
* unmap_mapping_range just need to be called once
* here, because the private pages is not need to be
* unmapped mapping (e.g. data segment of dynamic
* shared libraries here).
*/
unmap_mapping_range(mapping, 0, 0, 0);
truncate_inode_pages(mapping, 0);
filemap_invalidate_unlock(inode->i_mapping);
}
}
return 0;
// 还原操作
cleanup_all:
if (WARN_ON_ONCE(error > 0))
error = -EINVAL;
fops_put(f->f_op);
if (f->f_mode & FMODE_WRITER) {
put_write_access(inode);
__mnt_drop_write(f->f_path.mnt);
}
cleanup_file:
path_put(&f->f_path);
f->f_path.mnt = NULL;
f->f_path.dentry = NULL;
f->f_inode = NULL;
return error;
}到此,一个file就被配置好了。之后,它将被“安装”到打开文件表中:
void fd_install(unsigned int fd, struct file *file)
{
struct files_struct *files = current->files;
struct fdtable *fdt;
rcu_read_lock_sched();
if (unlikely(files->resize_in_progress)) {
rcu_read_unlock_sched();
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
BUG_ON(fdt->fd[fd] != NULL); // 分配到了已经存在的位置,报错
rcu_assign_pointer(fdt->fd[fd], file); // 分配
spin_unlock(&files->file_lock);
return;
}
/* coupled with smp_wmb() in expand_fdtable() */
smp_rmb();
fdt = rcu_dereference_sched(files->fdt);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
rcu_read_unlock_sched();
}观察上面第12行,有一个典型的临界区问题,如果在不加保护的情况下,fd有被重复分配的可能,在files_struct结构体中的file_lock就是避免这个的。
/*
* allocate a file descriptor, mark it busy.
*/
static int alloc_fd(unsigned start, unsigned end, unsigned flags)
{
struct files_struct *files = current->files;
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock); // 上锁
repeat:
fdt = files_fdtable(files);
fd = start;
if (fd < files->next_fd)
fd = files->next_fd;
if (fd < fdt->max_fds)
fd = find_next_fd(fdt, fd);
/*
* N.B. For clone tasks sharing a files structure, this test
* will limit the total number of files that can be opened.
*/
error = -EMFILE;
if (fd >= end)
goto out;
error = expand_files(files, fd);
if (error < 0)
goto out;
/*
* If we needed to expand the fs array we
* might have blocked - try again.
*/
if (error)
goto repeat;
if (start <= files->next_fd)
files->next_fd = fd + 1;
__set_open_fd(fd, fdt); // 修改位图!!很重要
if (flags & O_CLOEXEC)
__set_close_on_exec(fd, fdt);
else
__clear_close_on_exec(fd, fdt);
error = fd;
#if 1
/* Sanity check */
if (rcu_access_pointer(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL);
}
#endif
out:
spin_unlock(&files->file_lock); // 解锁
return error;
}通过锁,确保了临界区安全。在将fd安装上去后,返回fd,内核在打开文件的时候的事就做完了。















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









