






在分布式环境下,有许多客户端机器和一个(或多个)服务器。服务器将数据存储在其磁盘上,客户端通过结构良好的协议消息来请求数据。这样的做法,可以方便各个客户端共享数据,也便于数据的集中管理。
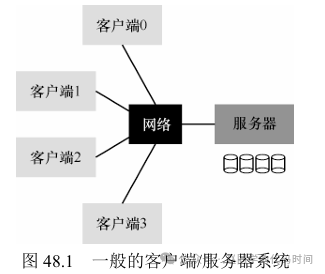
但是,要针对以上场景,设计一个网络文件系统,需要考虑哪些方面?哪些地方容易出错?还是有很多值得斟酌之处。
如何应对随时可能发生的服务器崩溃?
仿照os操作的场景,我们显式调用open操作,向操作系统打开一个文件,并获得了文件描述符fd,fd关联了内核中相应的文件数据结构,之后,使用此描述符,我们再显式地调用read\write操作,完成对文件的写入,最后显式调用close,告诉操作系统,相关的资源已经可以被释放,从而完成了对文件的操作。
但是这个过程放在分布式场景中,有何不妥?我们假设服务器随时可能崩溃,客户端向服务器打开一个文件,服务器返回了fd,遗憾的是,服务器紧接着崩溃了,客户端接着使用这个fd进行文件访问,即使服务器成功重启了,fd这样的内存中数据结构也已丢失,无法完成接下来的访问。同样的,我们亦可以假设客户端也是随时可以崩溃的,当服务器向客户端返回fd后,客户端崩溃了,服务器永远也无法知道何时应当释放对应的fd资源,可能对服务器性能造成影响。
NFS的设计者留意到这些问题,决定采用无状态的方法:客户端的每一个请求都包含了本次访问的所有必要信息,无需服务器维护任何信息,服务器倘若发生崩溃,无需花哨的恢复操作,仅需重启继续提供服务就好,客户端所需要做的仅仅是超时重传请求。
NFSv2
如何定义网络协议来支持无状态操作?如何在支持无状态操作的同时,又能够支持POSIX文件系统的API(open\read\write\close...)?
首先,如何描述一个文件依然是必不可少的。file handle是NFS中最重要的数据结构之一,它包含三个重要组件,卷标识符、inode号和generation号,三项一起构成了用户希望访问的文件或目录的唯一标识符。卷标识符用于通知服务器,请求指向哪个文件系统(NFS服务器可以导出多个文件系统),inode号告诉服务器,请求访问该分区中的哪一个文件,generation号在inode被复用时使用,通过在复用inode号时递增它,以确保具有旧文件句柄的客户端不会意外访问新分配的文件。
协议的重要部分摘要:
| 函数定义 | 解释 |
| null() returns () | 用于测量RTT |
lookup(dirfh, name) returns (fh, attr) | 返回file handle和其属性 |
create(dirfh, name, attr) returns (newfh, attr) | 创建一个新文件并返回其fh和属性 |
remove(dirfh, name) returns (status) | 移除某一路径下文件 |
| getattr(fh) returns (attr) | 返回文件属性 |
setattr(fh, attr) returns (attr) | 设置文件属性 |
read(fh, offset, count) returns (attr, data) | 读fh从offset偏移的count大小数据,返回数据的同时还会返回属性 |
write(fh, offset, count, data) returns (attr) | 写fh从offset偏移的count大小数据,返回属性 |
| ... | ... |
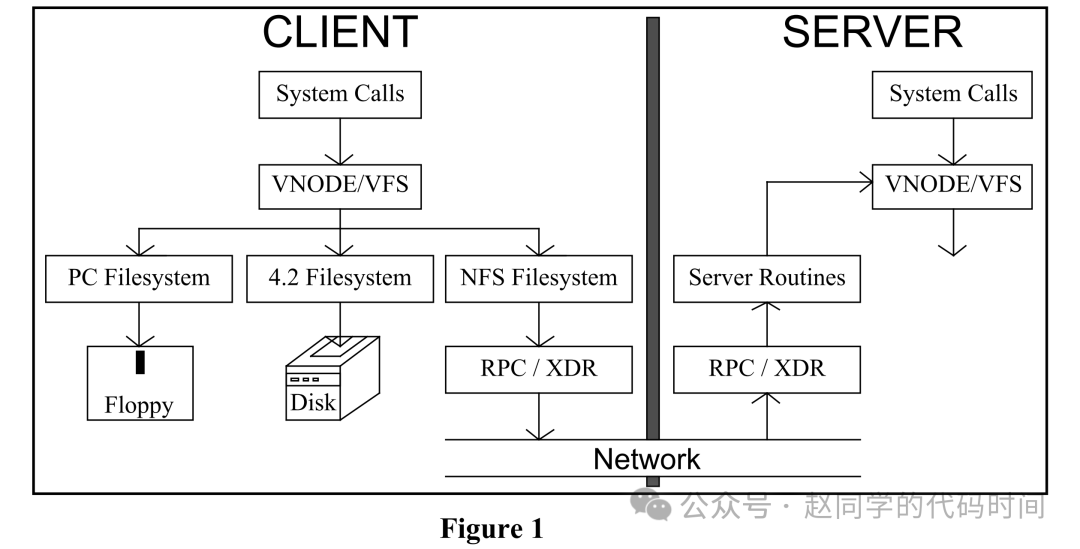
客户端首先使用LOOKUP协议消息获取文件句柄,该句柄用于访问文件数据,有了文件句柄,客户端就可以对一个文件发出READ和WRITE协议消息,读取和写入该文件,他们传递的内容包含了文件、文件的偏移及长度,服务器不用维护任何其他元数据,即可向客户端返回文件数据(或错误),下图表述了一次读取文件操作中客户端与服务器的操作流:

处理服务器故障
当客户端向服务器发送消息时,有时并不会收到回复,失败的原因各种各样,比如网络问题导致消息没有传输到服务器,服务器故障,或者由于网络问题服务器的消息没有传输回来,那么如果遇到这种情况,客户端应该怎么做?
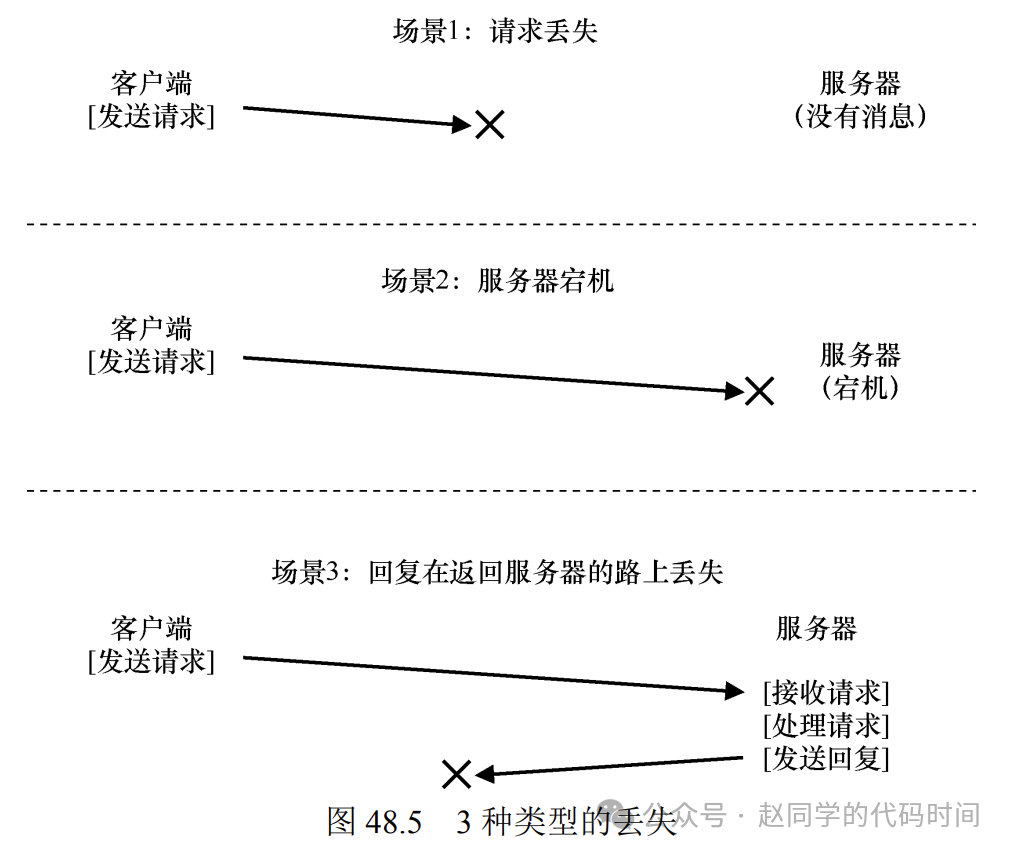
在NFSv2中,客户端只会以一种方式处理所有这些故障,那就是:重试。大多数NFS操作都是幂等的,操作执行多次和执行一次的效果相同,这是客户端可以通过重试来解决崩溃恢复问题的核心,LOOKUP和READ操作是简单幂等的,因为它们不会修改服务器数据,WRITE消息也是幂等的,因为WRITE消息包含了数据确切的位置以及数据,重复多次写入不会对数据正确性造成影响,当然,也存在一些操作并不幂等,比如mkdir,对已经存在的目录再次创建,会产生错误,但是并无伤大雅。
客户端缓存与一致性问题
将所有读写请求都通过网络发送,会导致性能下降,因此,客户端采用缓存来减少网络传输量能够提高性能,但是这会带来缓存一致性问题。
NFSv2主要采用了两种方式解决缓存一致性问题,首先,为了解决数据更新时的一致性,客户端实现了“关闭时刷新”的一致性语义,即,如果在文件打开过程中更新了数据,随后关闭文件时,客户端将所有更新刷新到服务器以确保当文件再次打开时,会看到最新的文件版本。
其次,客户端在使用缓存内容前,向服务器发送GETATTR请求,请求中包含文件修改时间,通过修改时间,客户端可以判断当前缓存中的内容是否为最新版本。
但是这导致了一个问题,为了确保数据没有过期,使得整个网络中充斥了大量的GETATTR请求,“轰炸”了服务器,实际上一个文件大部分时间只会由一个客户端修改,因此,为了提高性能,为每个客户端也添加了一个属性缓存,首次访问该文件时,属性也被缓存,在一定时间后超时,这样在超时时间内,不会有额外的服务器通信。(当然,这在大多数情况下都没问题,但是好巧不巧,也有可能偶尔会导致奇怪的行为)
服务器的写入必须是原子的
我们再额外想一个问题,WRITE的回复时机,服务器是收到了WRITE将其写入写缓冲就向客户端汇报成功,还是必须将其写入持久化内存才能向客户端汇报成功?
有可能有这样的一个场景:客户端C向服务器S写入了数据aaa,覆盖原有数据ccc,服务器收到请求后,将数据存入自己的缓存中,然后向客户端发送请求成功,紧接着,服务器宕机了,客户端下一次再向服务器获取数据,服务器由于缓存丢失,最后向客户端返回了ccc,造成了错误,因此,服务器的写入必须是原子的。
当然,每次都落盘势必会造成性能损失,服务器端也可以通过BBU紧急供电来确保缓存中的数据可以被持久化。
本文仅作简要介绍,作者也没有继续深入了,感兴趣的同学可以继续阅读reference中的内容。
reference:
[1] “The Sun Network File System: Design, Implementation and Experience” Russel Sandberg,这是NFS的原生论文。
[2] Operating Systems: Three Easy Pieces,介绍操作系统的一本好书。
[3] NFS Illustrated, Brent Callaghan,介绍NFS的一本好书, 每个协议都讲得非常彻底和详细。
[4] “NFS: Network File System Protocol Specification” Sun Microsystems, Inc. Request for Comments: 1094, March 1989,规范。
[5] “The NFS version 4 protocol” Brian Pawlowski, David Noveck, David Robinson, Robert Thurlow 2nd International System Administration and Networking Conference (SANE 2000)















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









