







1-认识headers、版本、重要资源
C++ Standard Library
Standard Template Library
标准库 > STL
标准库以header files形式呈现
- C++标准库的header files 不带.h #include
- 新式 C header files 不带.h 例如 #include
- 旧式 C header files 带.h #include <stdio.h>
2-STL体系结构基础介绍
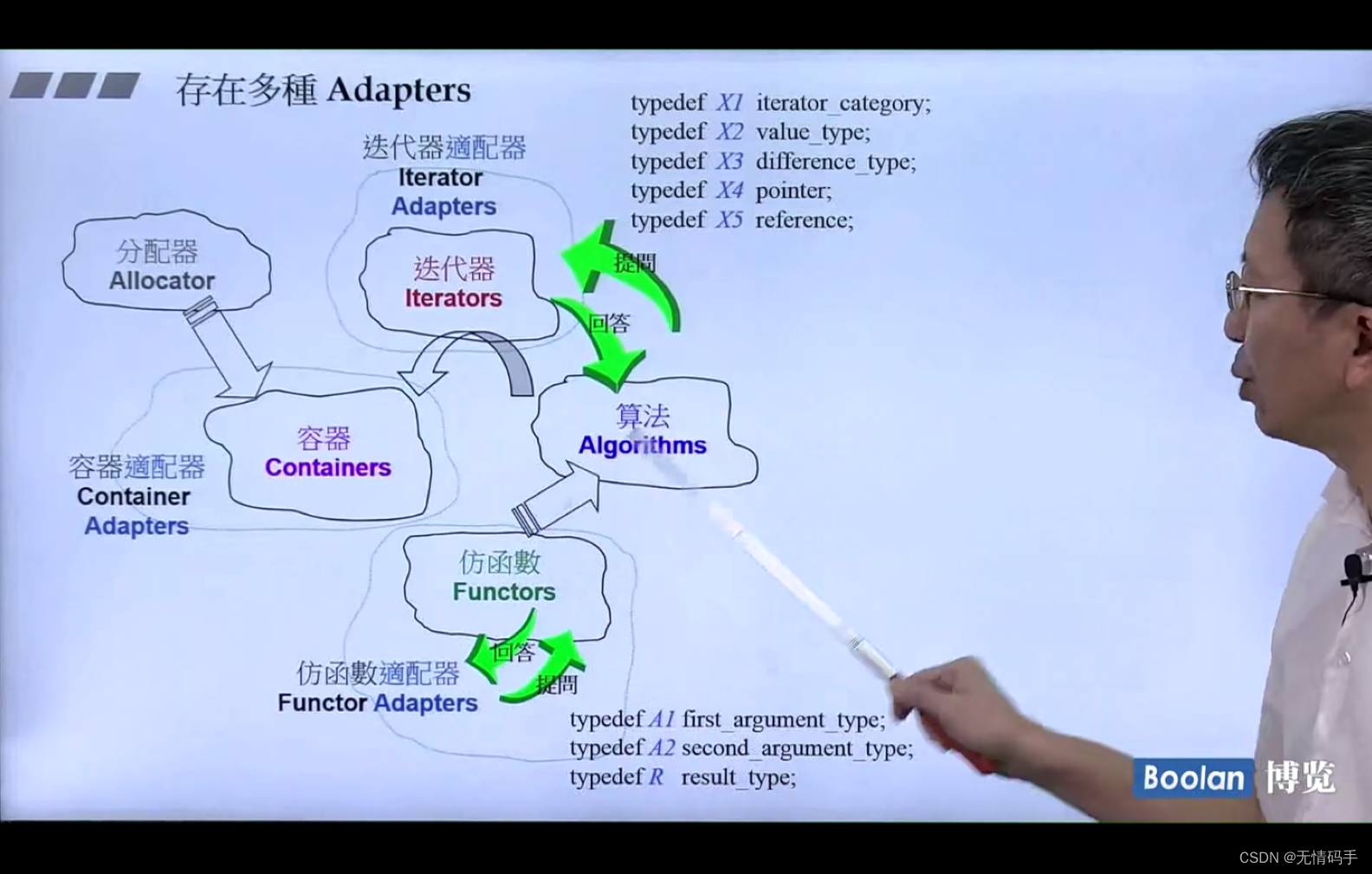
六大部件
- 容器(Containers)
- 分配器(Allocators)
- 算法(Algorithms)
- 迭代器(Iterators)
- 适配器(Adapters)
- 仿函数(Functors)
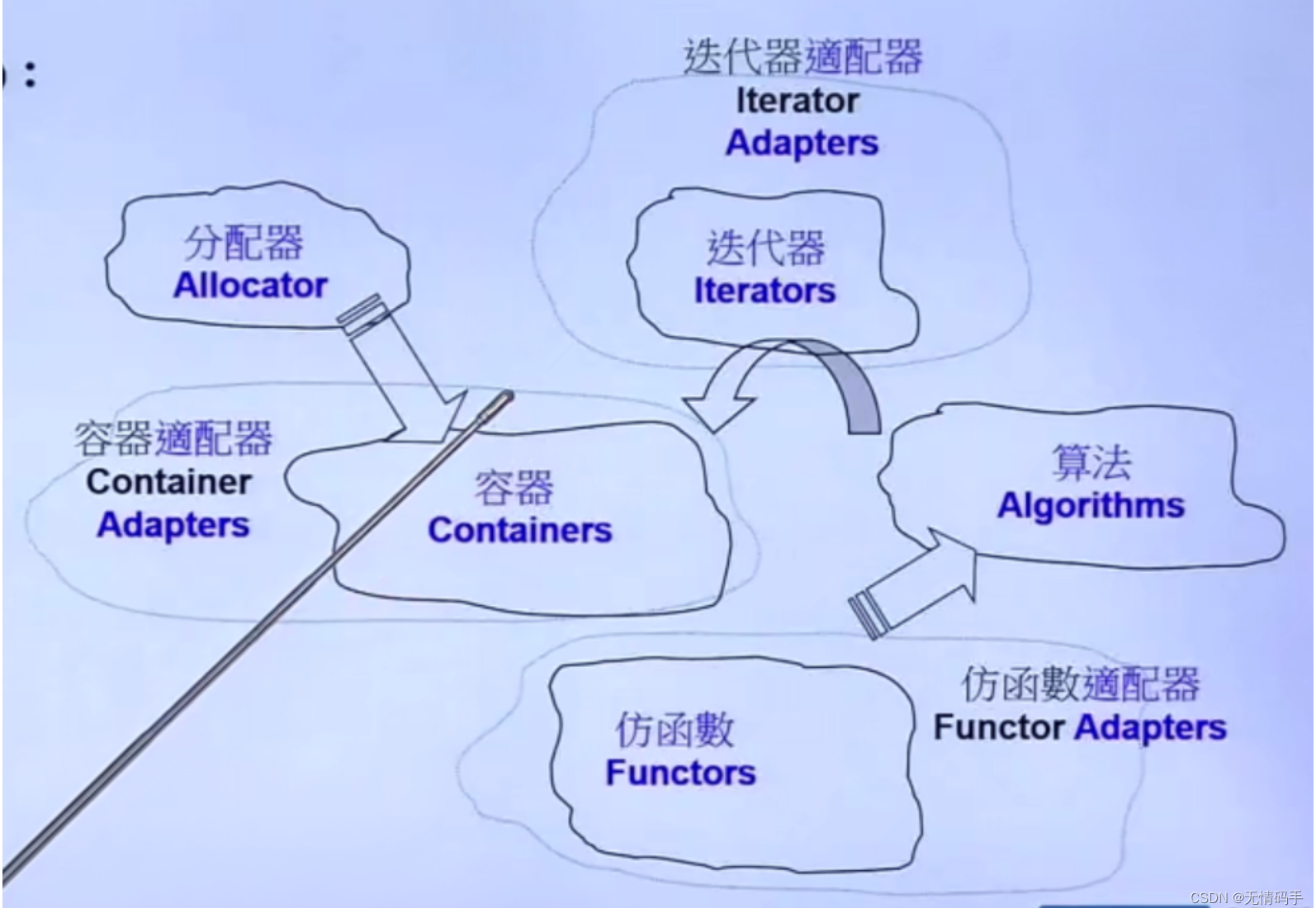
迭代器 -> 泛化指针
Adapter (适配器、变压器) 帮我们转换:容器、仿函数、迭代器、
容器,需要有一个分配器在它背后帮他分配内存
按理说,分配器也可以不写,它会有默认值
count_if:返回在[first, last)范围内满足特定条件的元素的数目。(algorithm)
less:(Function object) 仿函数
bind2nd:(function adapter(binder))
not1:(function adapter(negator))
每个元素和40比,所以用了less,用bind2nd把第二参数绑定为40,再加not1 -> 大于等于40
#include<vector>
#include<algorithm>
#include<iostream>
#include<functional>
using namespace std;
int main()
{
int a[6] = {1, 20, 45, 12, 53, 101};
vector<int, allocator<int>> vec(a, a+6);
cout << count_if(vec.begin(), vec.end(), not1(bind2nd(less<int>(), 40))) <<endl;
return 0;
}
vector<int> vec;
for(auto elem : vec)
{
...
}
for(auto& elem : vec)
{
elem *= 3;
}
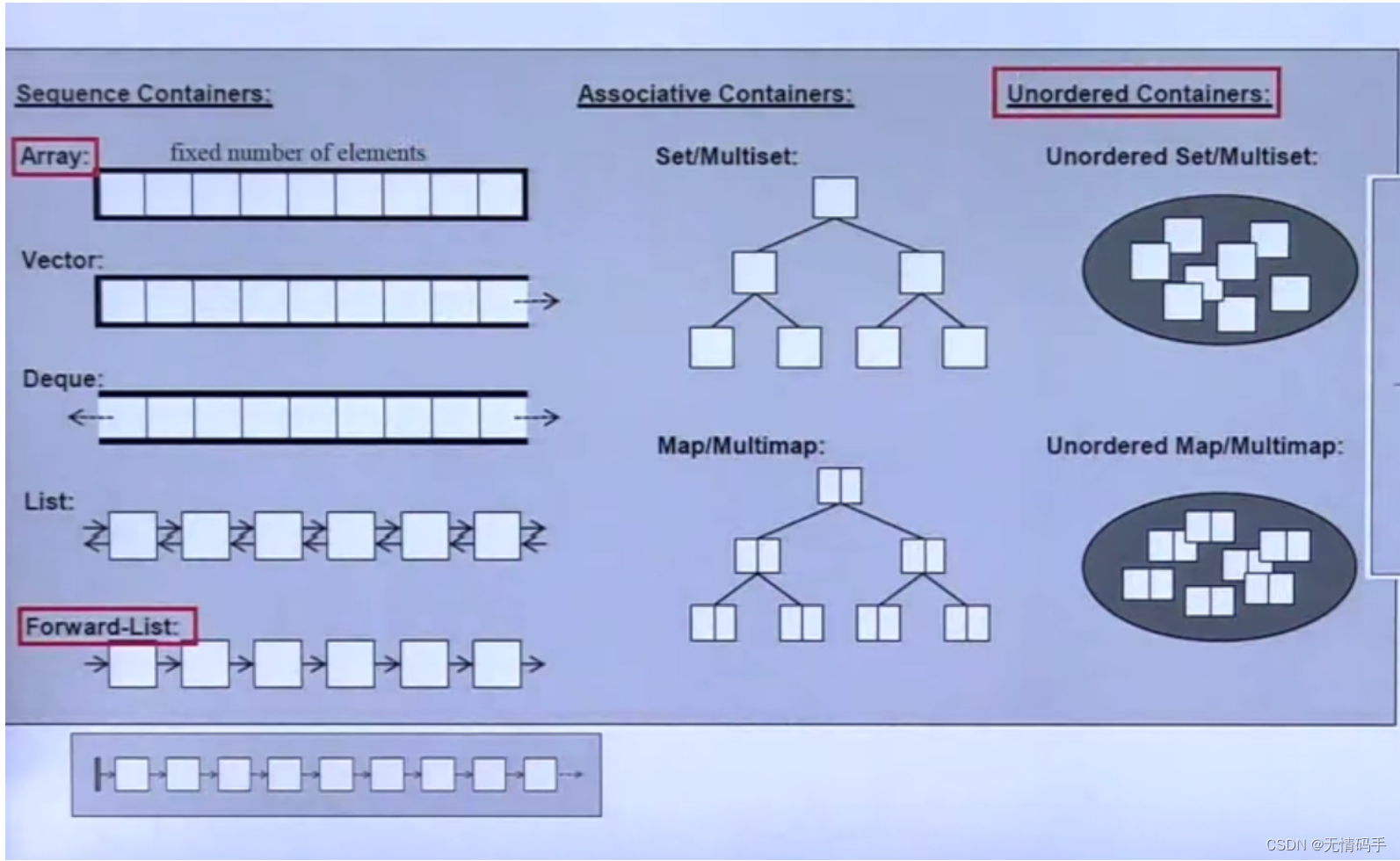
3-容器之分类与各种测试(一)
顺序容器:
- Vector
- Array
- Deque
- List
- Forward-List
Associative 容器:
- Set / Multiset
- Map / Multimap
Unordered 容器:
- Unordered Set/Muitiset
- Unordered Map/Multimap
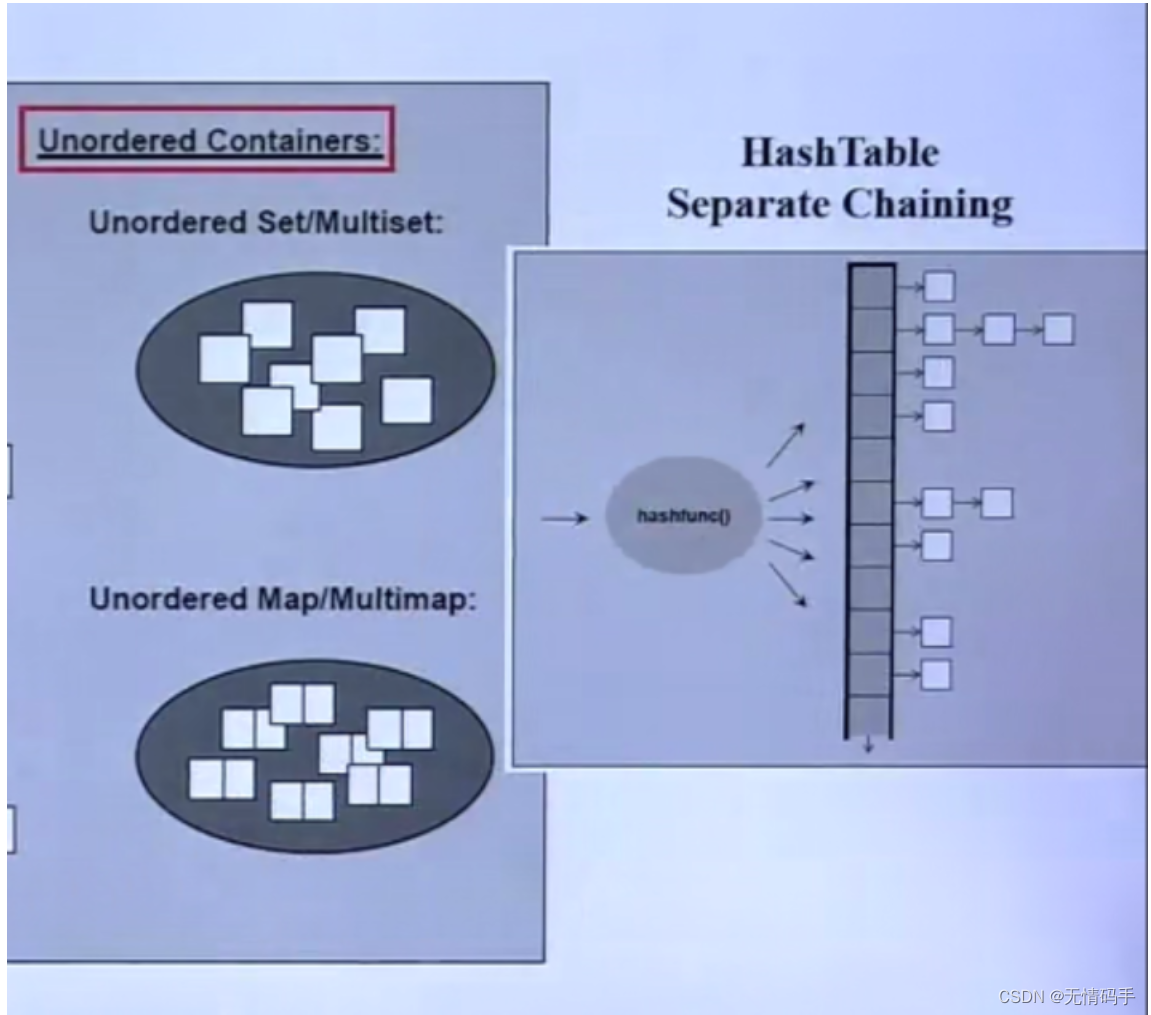
红黑树左右二叉树高度类似,不会出现一查查到最后面的问题,保持平衡。
一开始:碰撞后分开 后来:碰撞后大家都放在这个篮子里好了,篮子是个链表。

注意vector是一直这样往末尾插,如果要从前面插,他要往后推,那么就也要意味着做很多次不必要的构造和析构
vector的空间是两倍两倍的增长,一开始是1,扩大一倍2,再 4,8,…,64,…
bsearch
void *bsearch(const void *key, const void *base, size_t nitems, size_t size, int (*compar)(const void *, const void *))
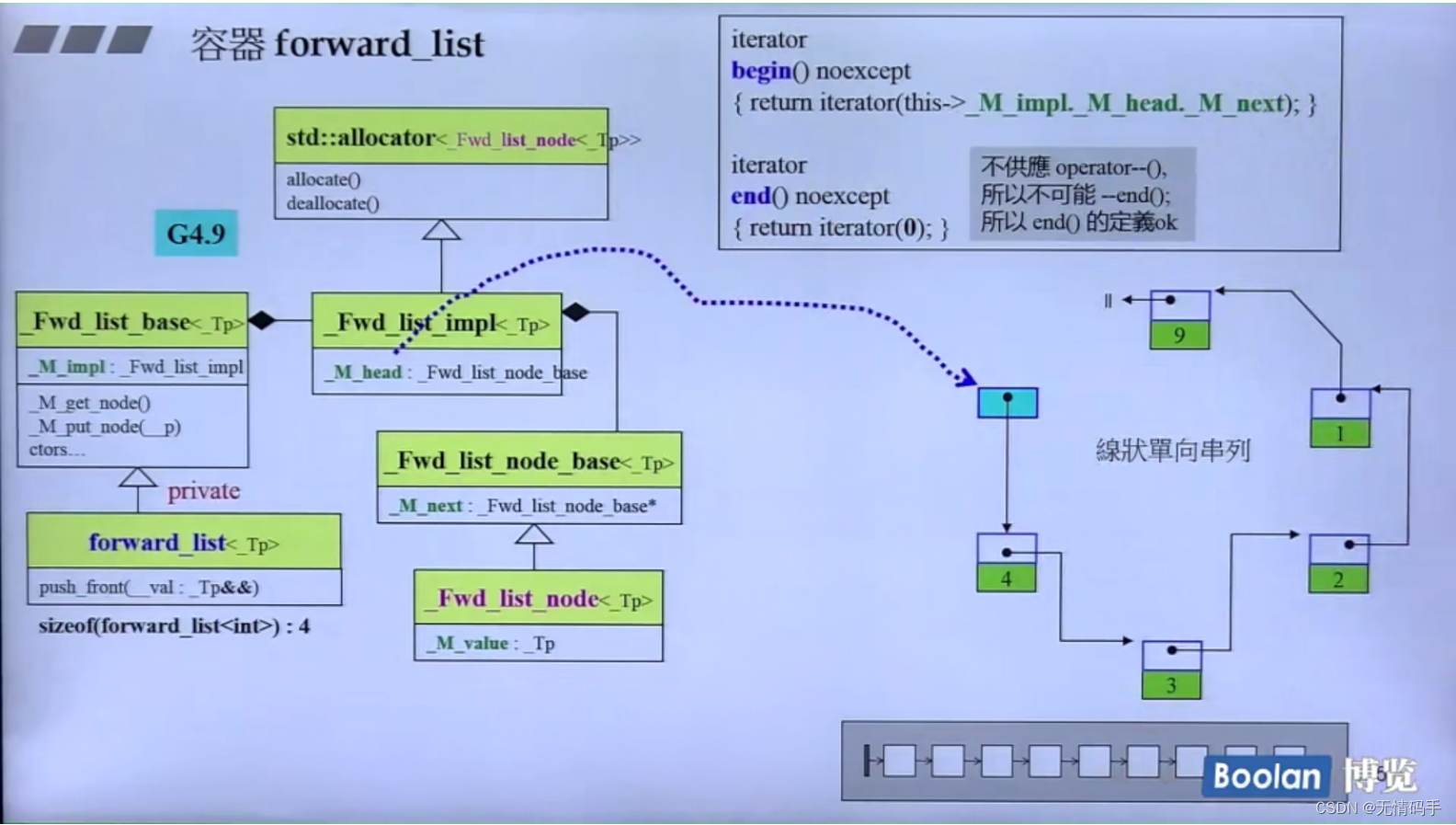
list是双向的、如果是单向的话 是叫 forward-list
对于vector来说,它的扩张不是在原基础上直接成长。而是找了一个新的地方找了一个两倍大的地方,然后把原来的东西复制过去
list一个萝卜一个坑,每放一个元素进去,它占一个位置
C 库函数 int sprintf(char *str, const char *format, …) 发送格式化输出到 str 所指向的字符串。
标准库里有一个全局的sort,某些容器自己里也提供了sort。当它自己提供了的时候,用自己的。
forward_list 只有 push_front
slist 也是单向链表,是非标准库里规定的
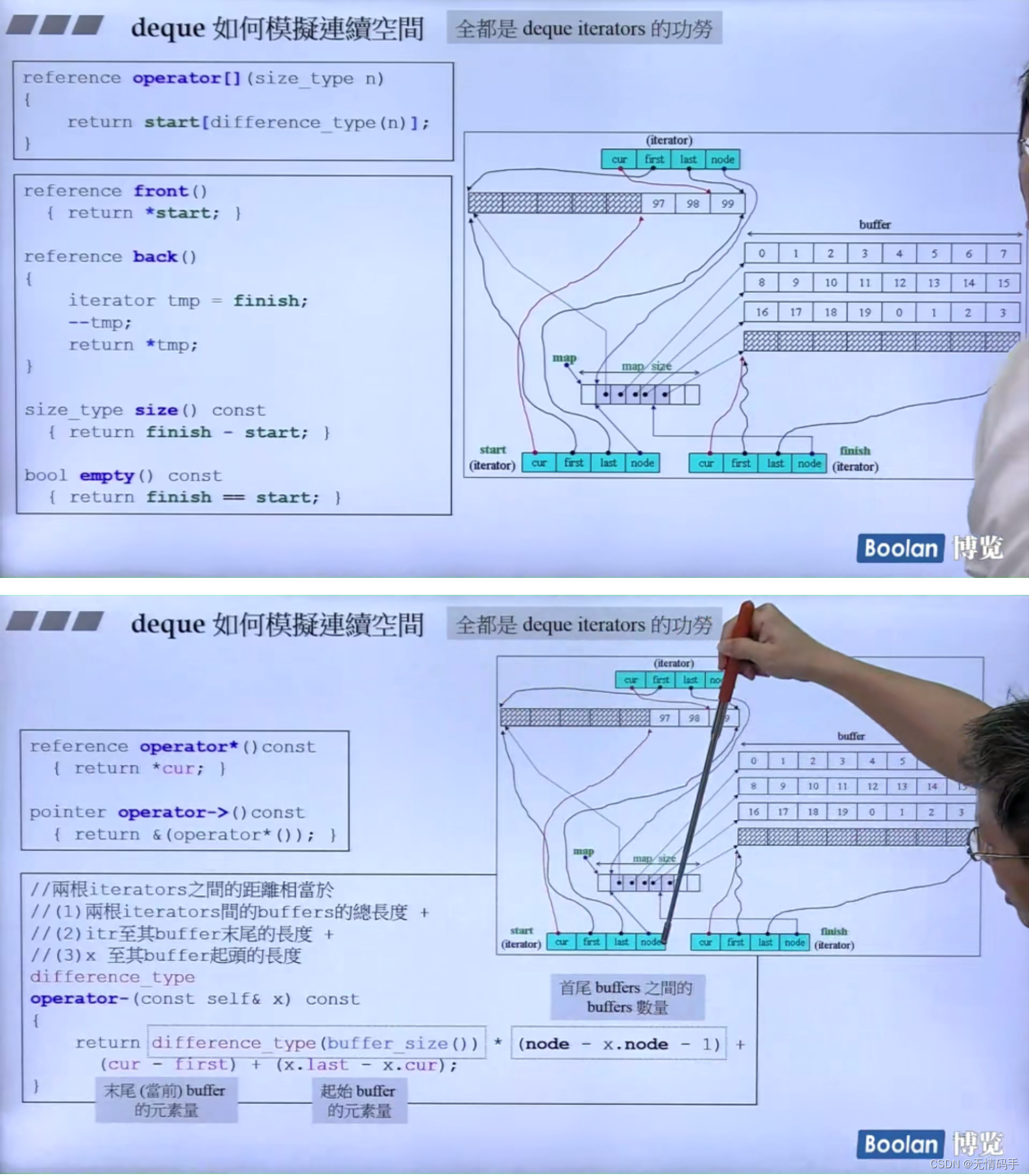
deque 是由一段一段的 buffer 构成的(分段连续)但是让使用者感觉是整个连续的。99的index再++就到了0的index那里。
push_back : 如果这个buffer用完了,就往后再开一个buffer继续添加
push_front:如果这个buffer用完了,就往前再开一个buffer继续添加
比较: array 无法扩充、vector 两倍扩充(会有很多浪费)、deque每次扩充都是buffer扩充
deque里没有自己的sort、用公共的sort去排序
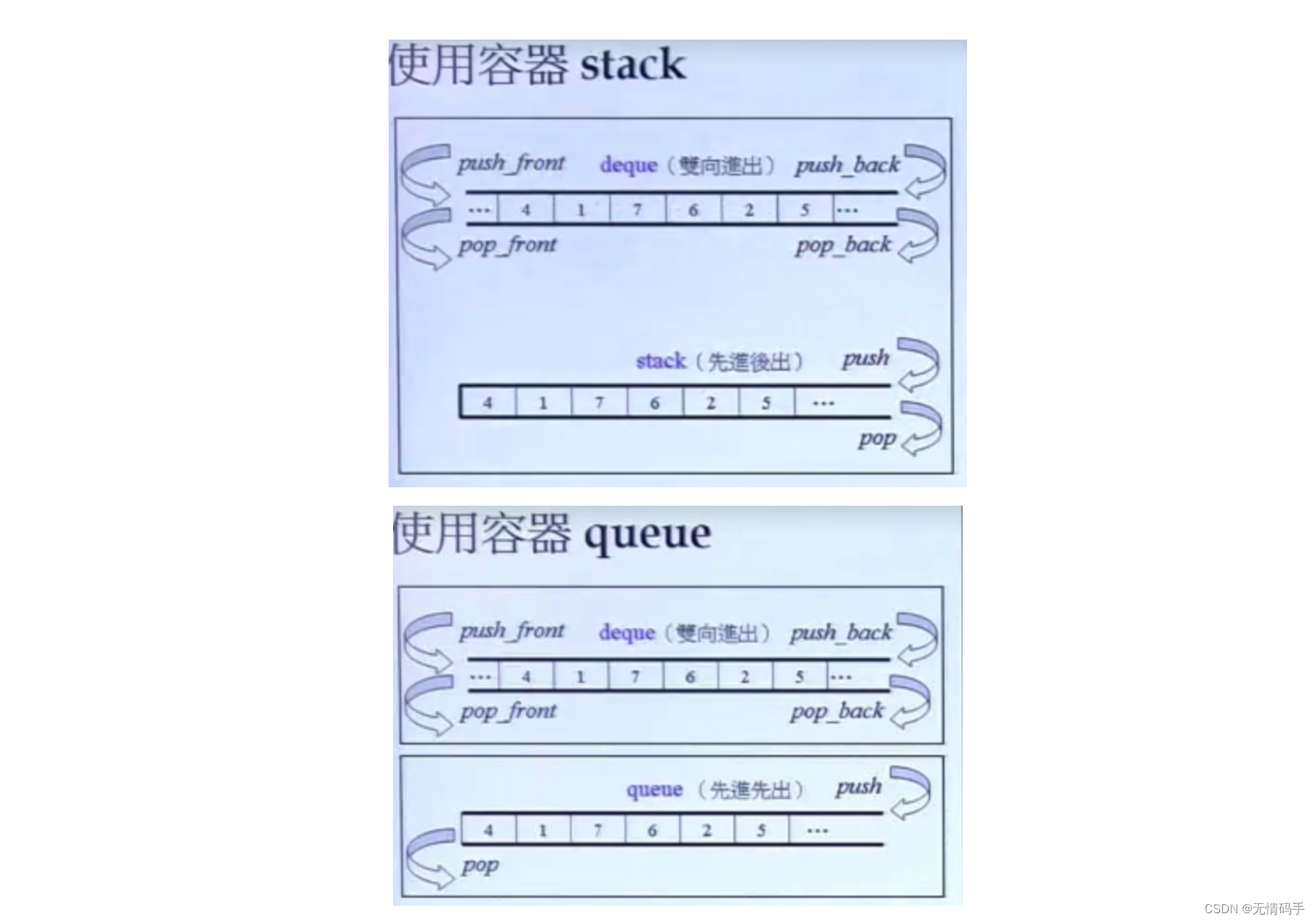
queue 和 stack 都是由 deque 实现
deque 不会设计函数让你得到 iterator ,这会破坏这个容器独特的性质。这个容器只能前后出(修改)
关联容器
multiset -> 红黑树
它里面有自己的find函数 红黑树高度平衡
它安插的时候慢,但是查找的时候很快
multimap 不可以 使用 [] 做 inserttion
auto pItem = c.find(target);
if(pItem != c.end()) cout<<(*pItem).second<<endl;
Unordered 容器
hash table 实现的
//篮子的个数
unordered_multiset.bucket_count()
//篮子里挂了多少个元素 i是指第几个篮子
object.buck_count(i)
篮子一定要比元素多,注意篮子里的链表不能太长,将来找的时候不好找
(元素的个数 >= 篮子,那么篮子就要扩充,让篮子变成两倍,然后把这个长元素打散,再重新挂在篮子上)
对于 (unordered) multiset/map 这四种来说,key是可以重复的
没有 multi时 key 不可重复
rand() 乱数产生的范围是 32727
set 里 插入 一百万个值,最后里面只有32727个
map 可以用 [] 做插入
9-OOP 面向对象编程 GP泛型编程
OOP:将datas和methods关联在一起
template<class T,
class Alloc = alloc>
class list{
...
void sort();
}
GP:将datas和methods分开来
分开来,操作的部分怎么得到数据本身呢?
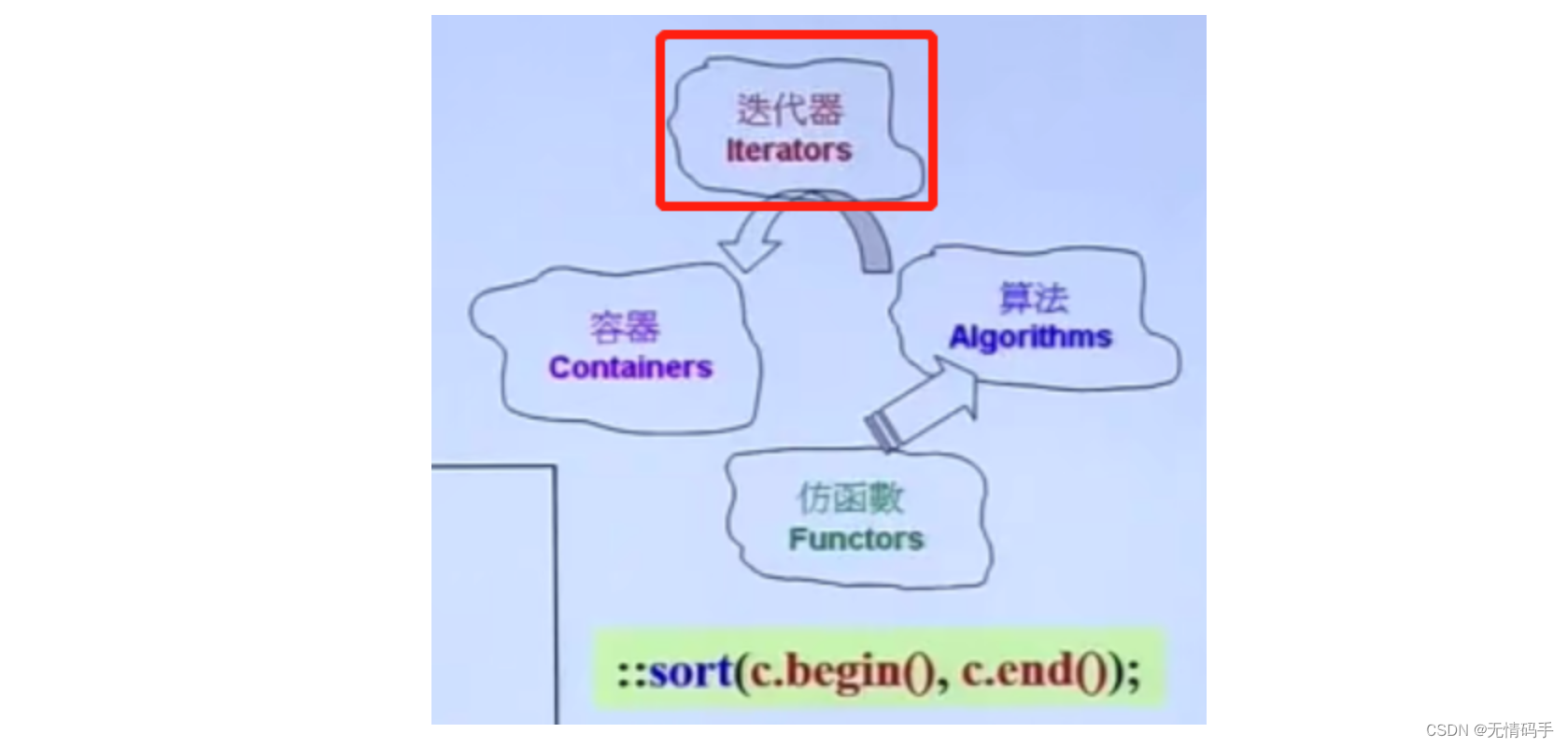
借助iterators实现
迭代器 -> 泛化指针
::sort(c.begin(), c.end());
GP Generic Programming (generic 通用的) ——— Containers 和 Algorithms 团队可以各自独立地开发,其之间用Iterator互通
Algorithm 用Iterators 确定操作范围,并通过Iterators取用Container元素
template<class T>
inline const T& min(const T& a, const T& b)
{
return a < b ? a : b;
}
< 号不由我函数定义,那就和我无关了(Stone自己去定义operator < )
list为什么和vector、deque不一样,不能用公共的sort、要自己定义并使用自己的?sort

迭代器有加、减、还有除 -> 能实现这种的只有RandomAccessIterator
list的空间是一个一个串起来的、它不能+5、-10、它只能通过指向来
重载max函数,换一个比大小的方式

max函数的源码(有很多重载,下面是其中一个):
它也有用模版定义一个参数,可以把函数作为参数传进去
// FUNCTION TEMPLATE max
template <class _Ty, class _Pr>
_NODISCARD constexpr const _Ty&(max)(const _Ty& _Left, const _Ty& _Right, _Pr _Pred) noexcept(
noexcept(_Pred(_Left, _Right))) /* strengthened */ {
// return larger of _Left and _Right
return _Pred(_Left, _Right) ? _Right : _Left;
}
我自己定义了:
#include<iostream>
#include<algorithm>
using namespace std;
bool strLonger(const string& a, const string& b)
{
return a.size() < b.size();
}
int main()
{
string a = "hello";
string b = "zoo";
cout<<max(a, b, strLonger)<<endl;
return 0;
}
函数里面传入函数:
- lambda表达式
- template模版
- 函数指针
四个不能重载的操作符:
- ::
- .
- .*
- ?:
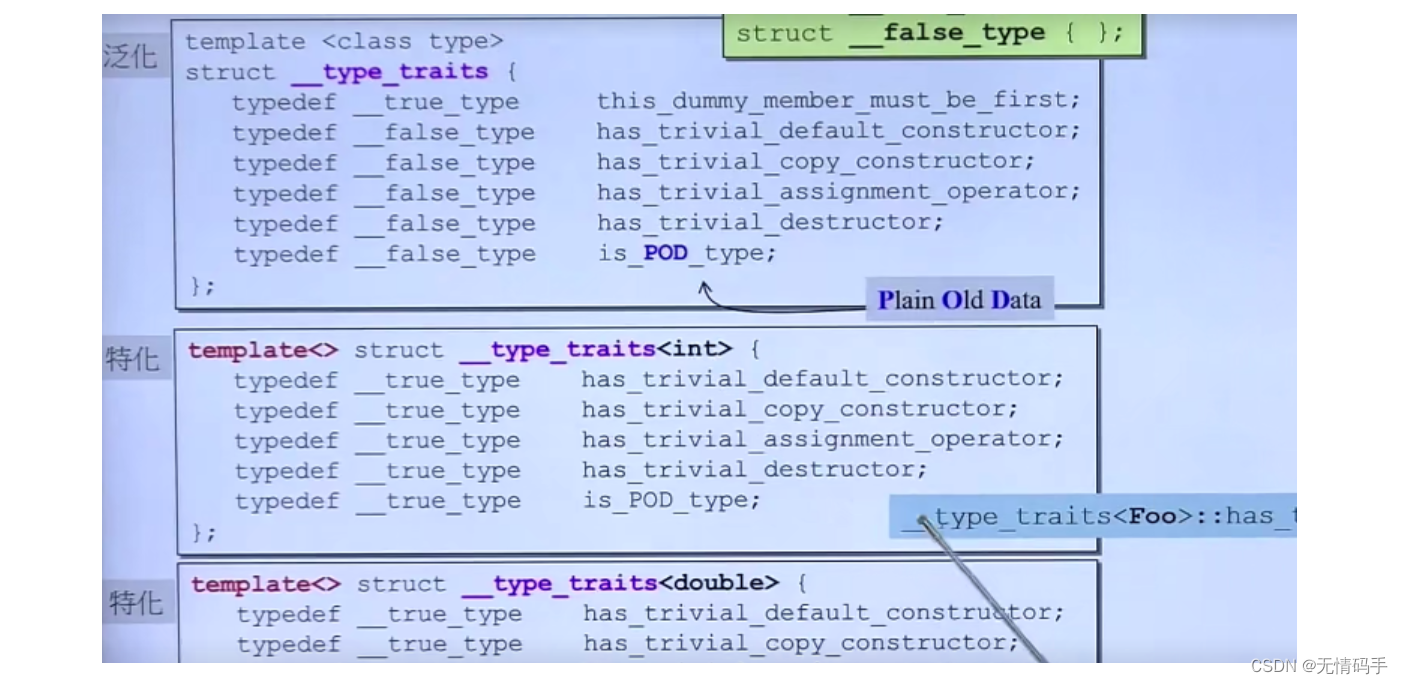
特化:抽空了template里的内容,在要修饰的后面跟东西
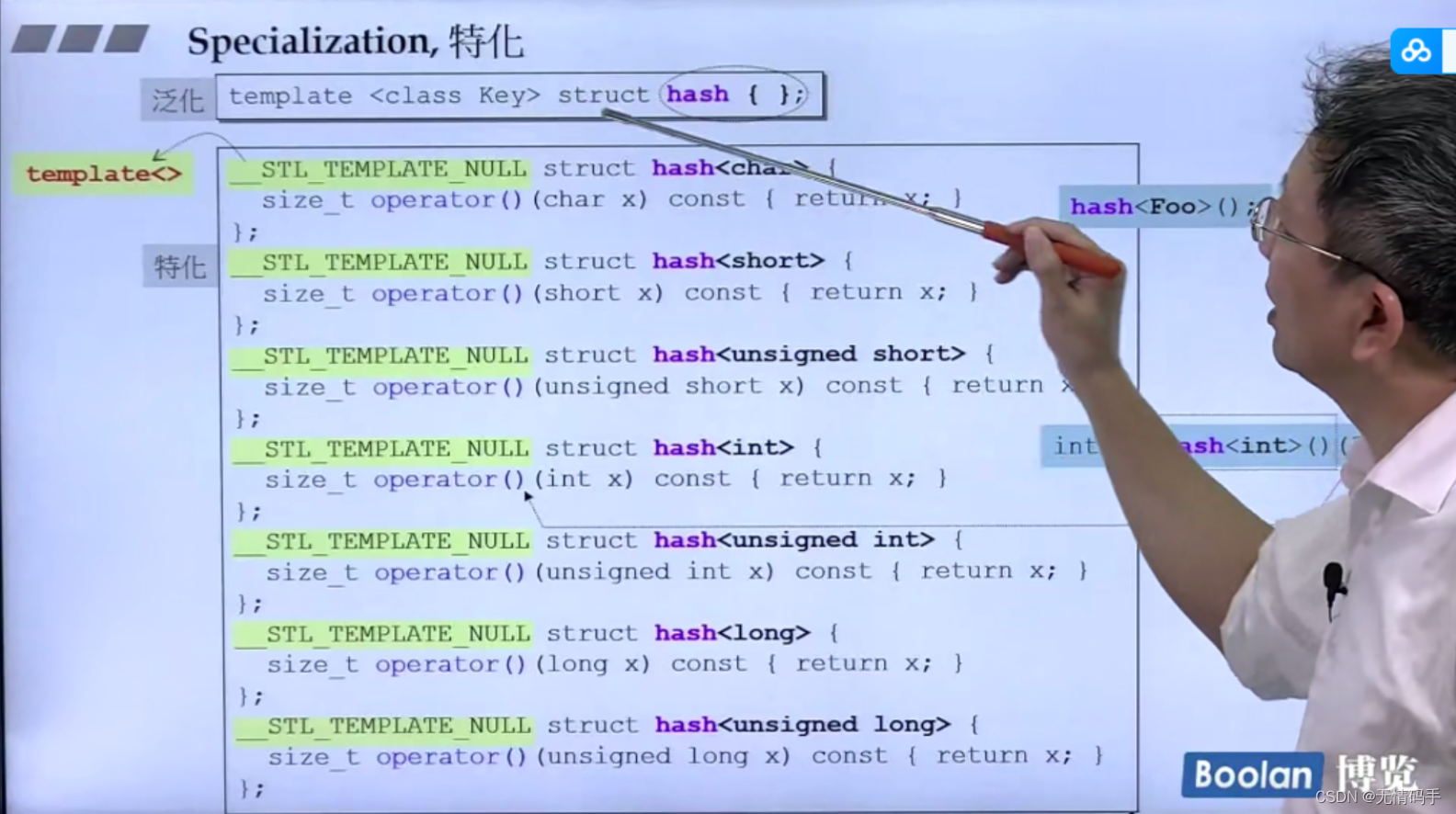
__STL_TEMLATE_NULL 是一个typedef 代表 template<> -> 特化
偏特化

需要注意的是,偏特化有个数上的偏,也有范围上的偏
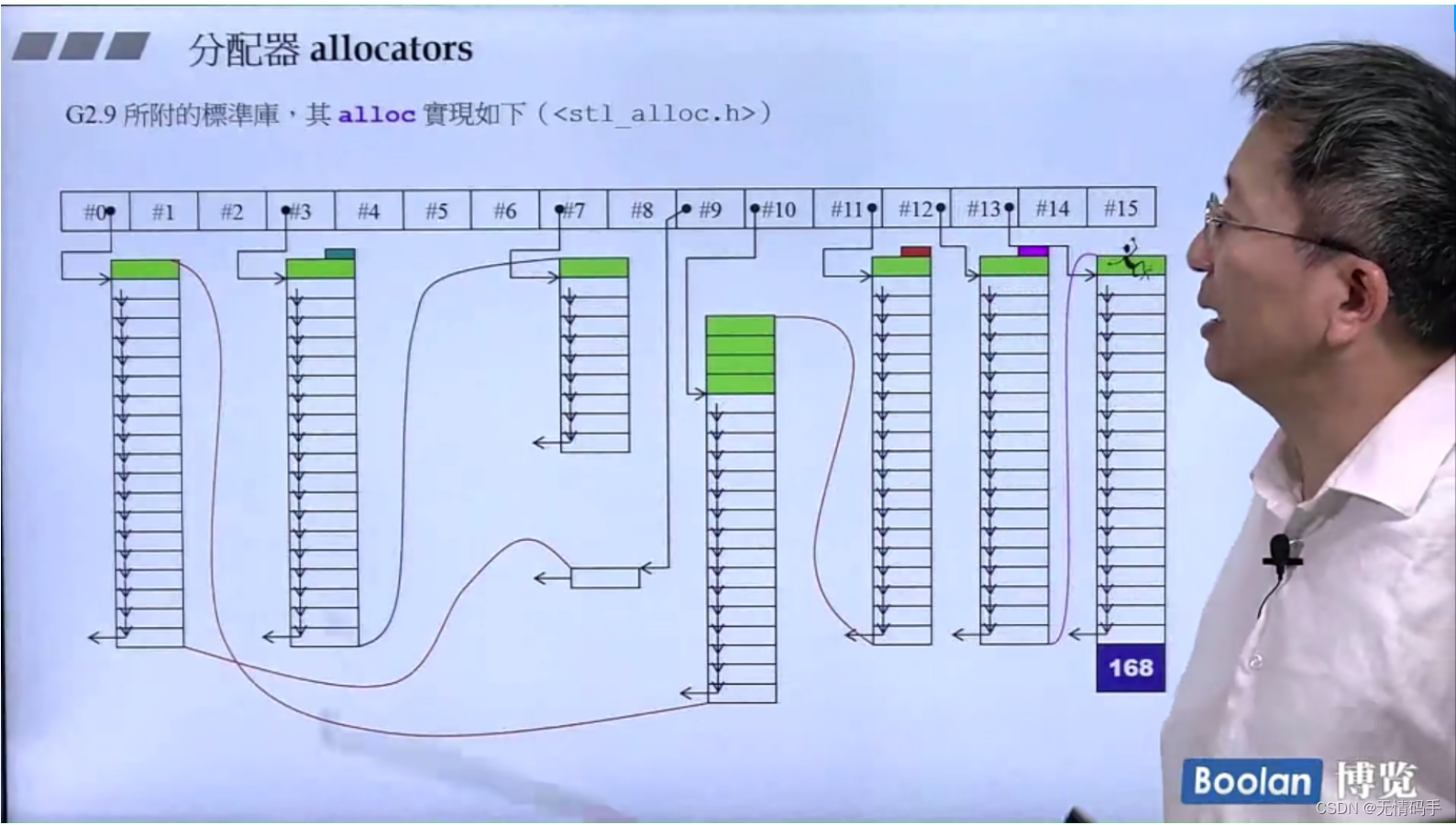
11-分配器
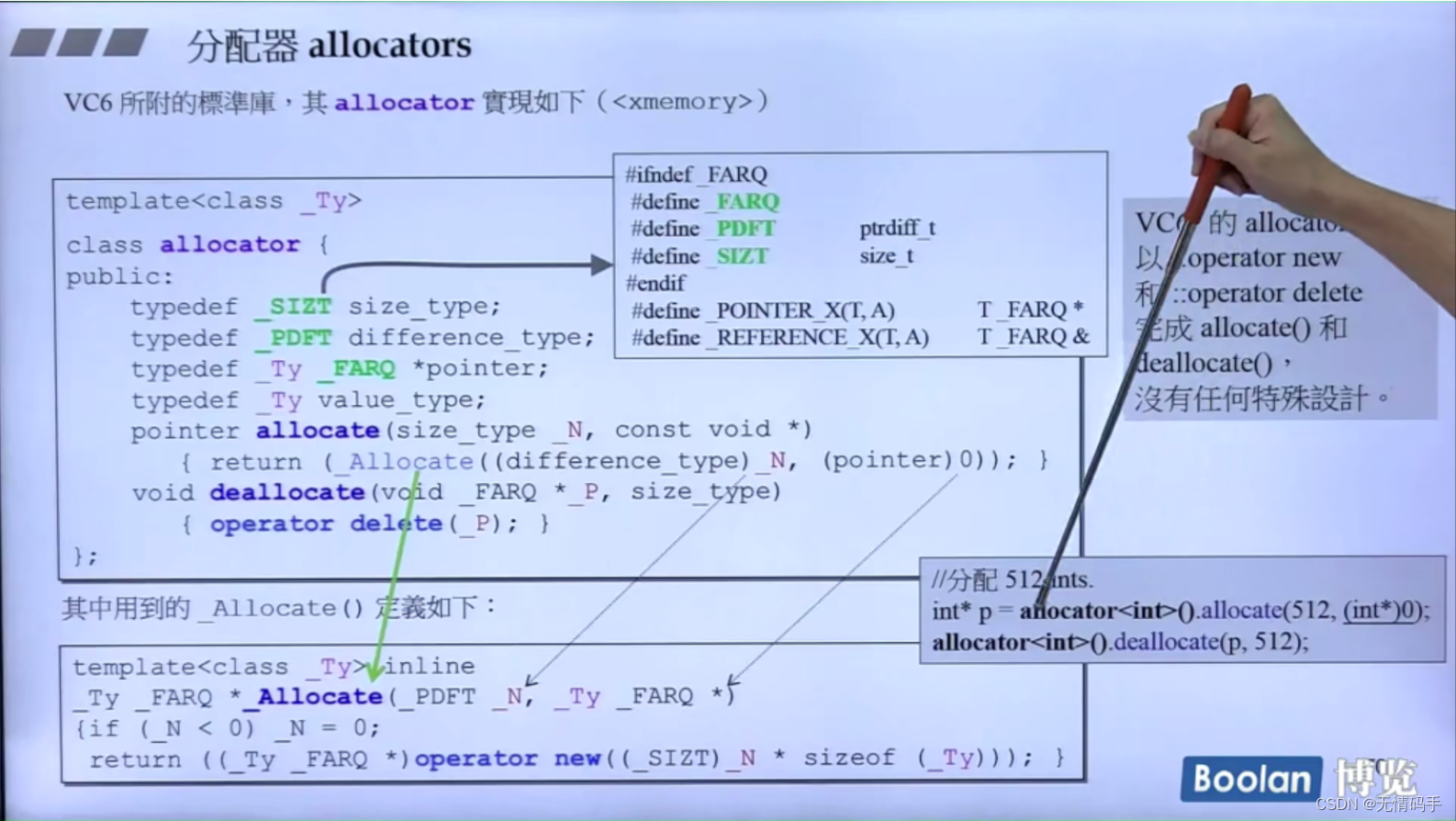
int* p = allocator<int>();//创建临时对象出来了
allocator里调用的还是operator new
Vc里 allocator 里的 allocate函数需要传一个const void *进去,它不在乎你传什么、且没默认值,需要人为传
BC5 里第二个参数有默认值,不需要你给他,只需要你传一个分配个数给他即可
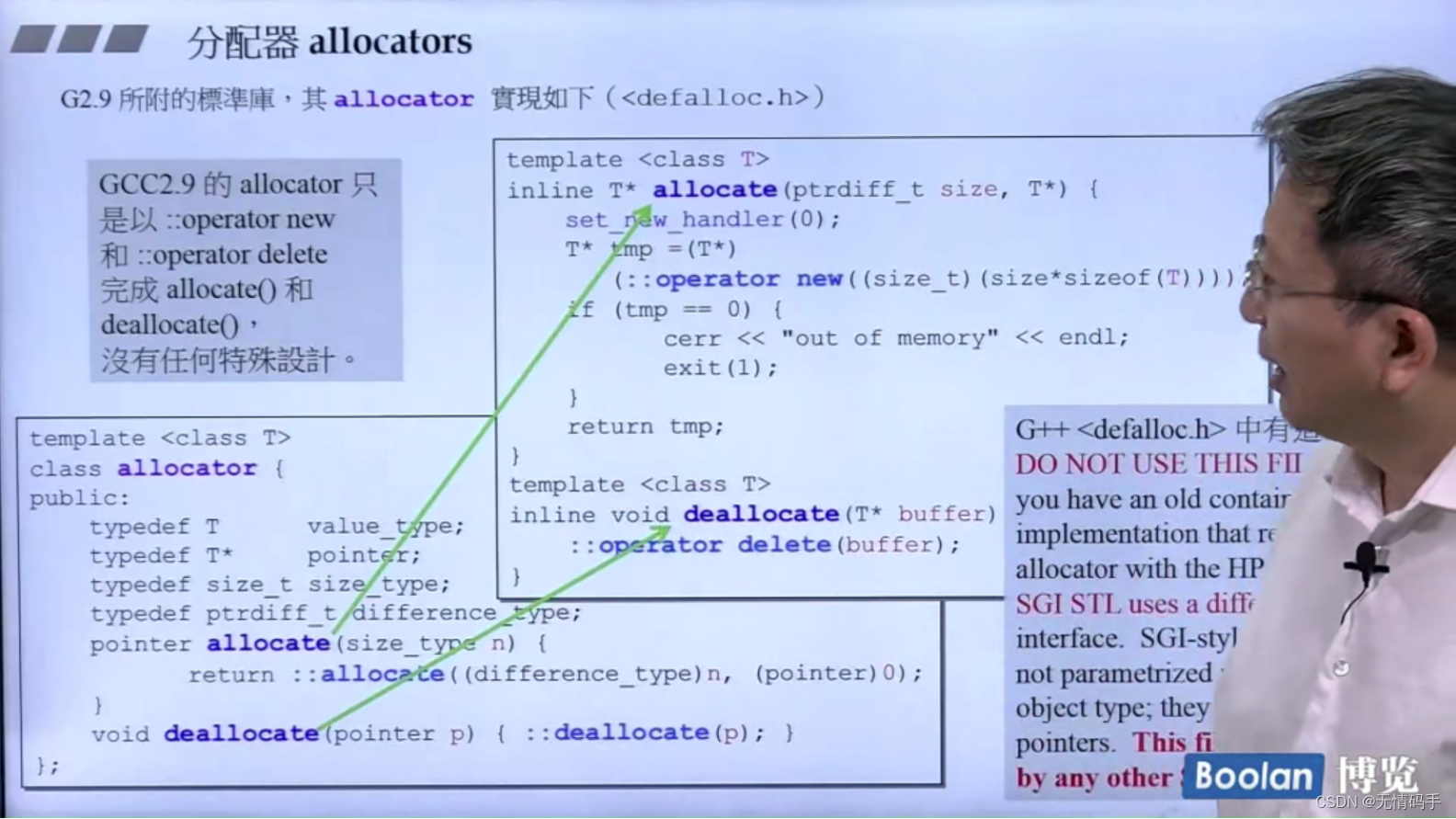
G2.9里标准库的allocator
- size_t是unsigned类型,用于指明数组长度或下标,它必须是一个正数,std::size_t.设计size_t就是为了适应多个平台,其引入增强了程序在不同平台上的可移植性。
- ptrdiff_t是signed类型,用于存放同一数组中两个指针之间的差距,它可以使负数,std::ptrdiff_t.同上,使用ptrdiff_t来得到独立于平台的地址差值.
- size_type是unsigned类型,表示容器中元素长度或者下标,vector::size_type i = 0;
- difference_type是signed类型,一种常用的迭代器型别,用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是其最大容量。vector:: difference_type = iter1-iter2.
- 前二者位于标准类库std内,后二者专为STL对象所拥有。
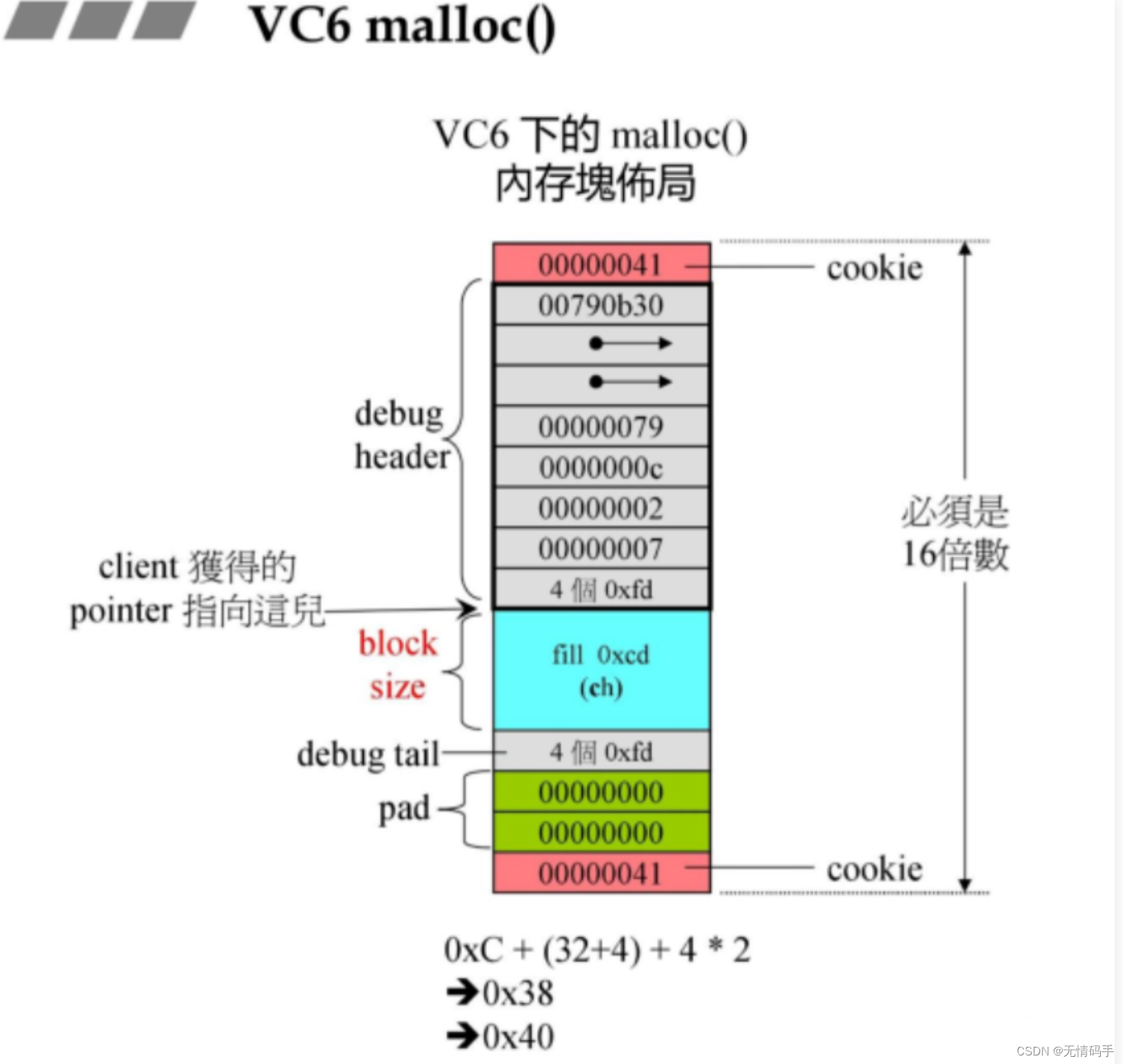
malloc带来的额外开销(主要体现在cookie上面):应该指非调试模式
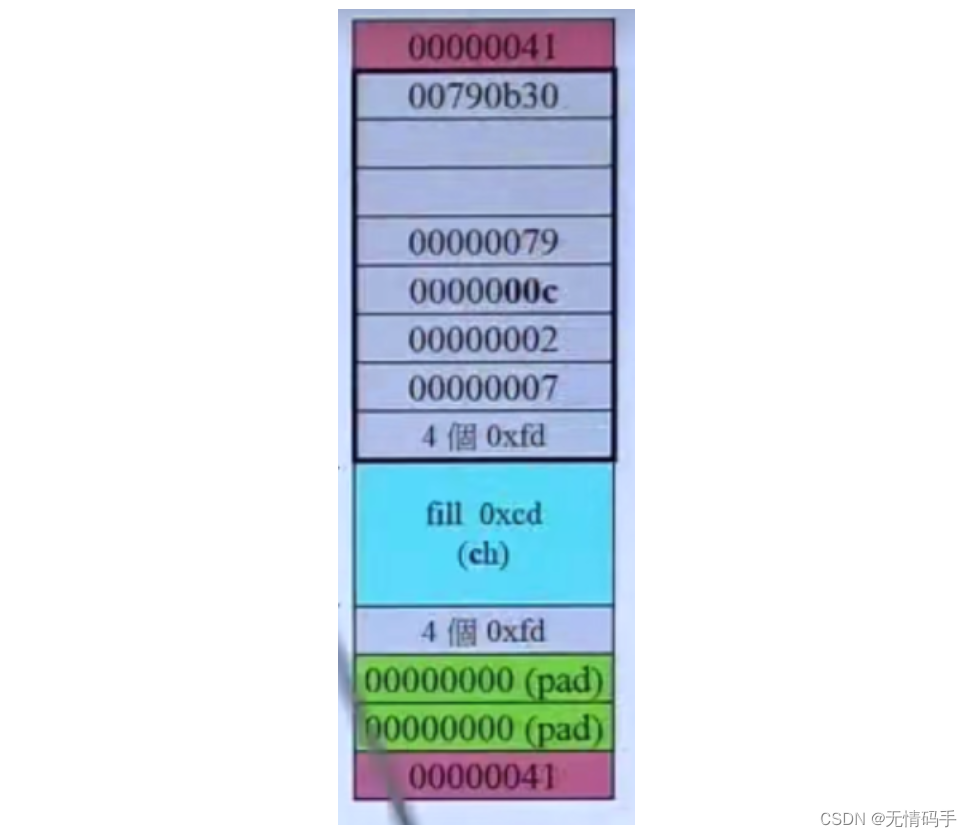
(如果区块小,开销的比例占的就大,不能忍受)
(如果区块大,开销的比例占的就小,可以忍受)
在现实生活中,一般是区块小的,不太能接受
G++<defalloc.h>中虽然有上图定义的allocator,但是在它的容器分配内存时,实际用到的是alloc
如果大量调用malloc的话cookie总和会增多,这会造成较大的浪费,因此减少malloc调用次数,去掉cookie总是好的。
而去除cookie的先决条件是你的cookie大小一致。容器里面的元素是一样的大小,这就满足了先决条件!
分配器的客户不是给你应用程序用,而是给容器用。
容器的元素大小是一样的,不管它是有几个元素,似乎可以不必把元素的大小在每一个元素都附带记着,比如100万个元素,每个元素8字节,前头再带一小块东西说我这是8个字节
它设计了16条链表,每条链表附着某种特定大小的区块,用链表串起来
0-15 以8的倍数增长,0代表8bytes,15代表 16*8 的bytes
容器的元素大小会被调整到8的倍数,50->56
找到这个大小对应的链表,如果没有,那么用malloc要来一块空间,并对它做切割,用链表串起来
100万个元素,都不带cookie,可以省去200万个cookie、一个cookie是4个字节、省去800万字节
举例:3号链表这一串、它一开始也是通过cookie去分配的,所以它上下也各有一个cookie
G4.9后来把原来的alloc摒弃了,它被改名为了__pool_alloc
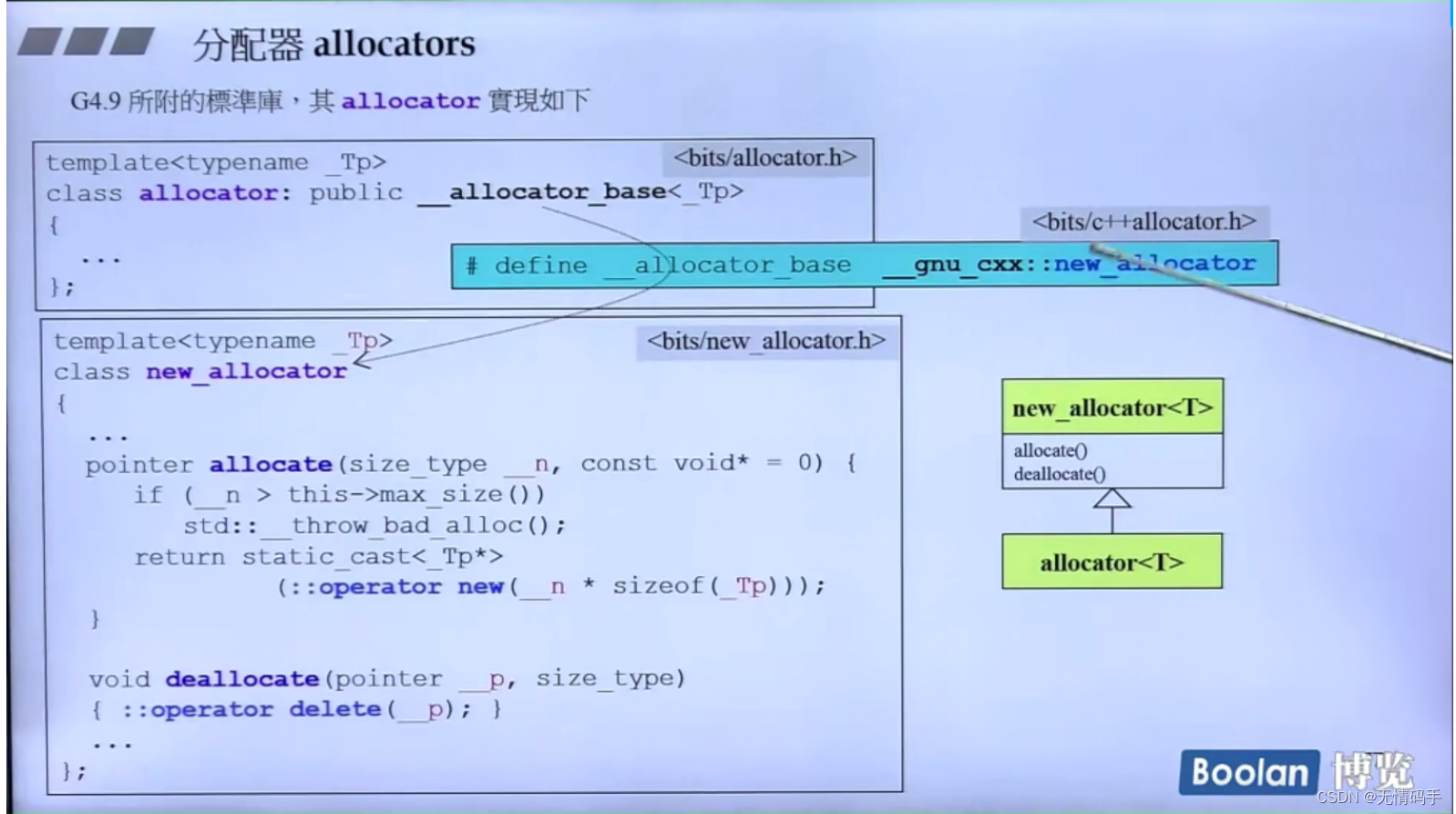
但是,它不是放在std命名空间里,而是
vector<string, __gnu_cxx::__pool_alloc<string>> vec;
对于数据C++定义new[]专门进行动态数组分配,用delete[]进行销毁。new[]会一次分配内存,然后多次调用构造函数;delete[]会先多次调用析构函数,然后一次性释放。
容器里放一百万个元素,他们的大小是一样的,所以不用malloc一百万次,而是直接用G2.9里链表的形式去放
12-容器之间的实现关系与分类

set里有一个 rb_tree(而不是继承)
heap里有一个vector(不是继承)
list的大小 容器本身的大小 -> 和里面有多少元素无关
13-list(上)
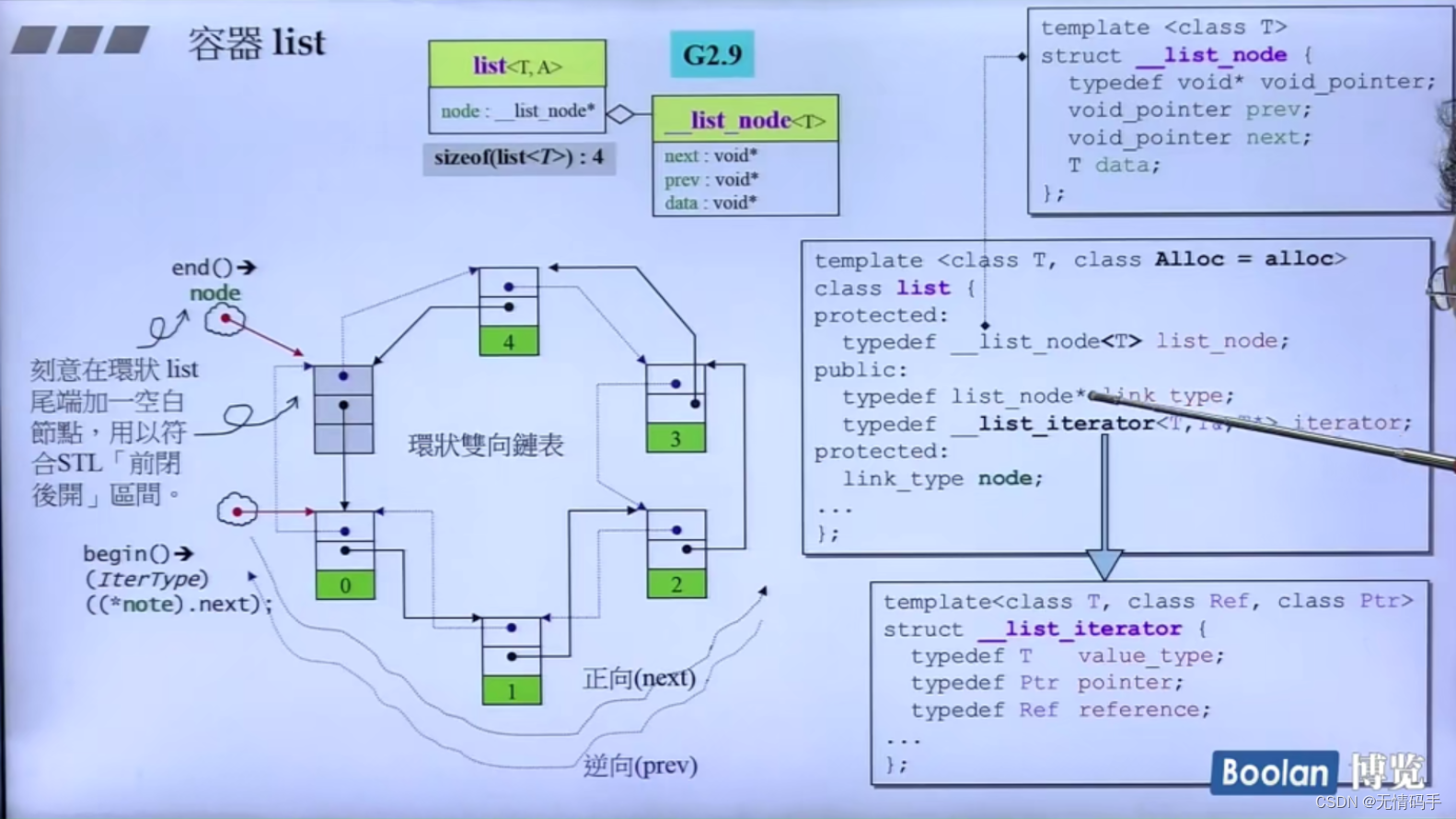
两个泡泡分别代表iterator(有起点、有终点)
link_type 是一个指向list_node的指针
list 在G2.9里面的大小是4,后面版本里的大小是8
template<class T>
struct __list_node{
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
}
template<class T, class Alloc = alloc>
class list{
protected:
typedef __list_node<T> list_node;
public:
typedef list_node* link_type;
typedef __list_iterator<T,T&,T*> iterator
protected:
link_type node;
...
}
template<class T, class Ref, class Ptr>
struct __list_iterator{
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
}
所以list在和分配器要内存的时候,是一块一块的在要 (数据 + 两个指针)
iterator必须设计成class、才能达到符合聪明的指针
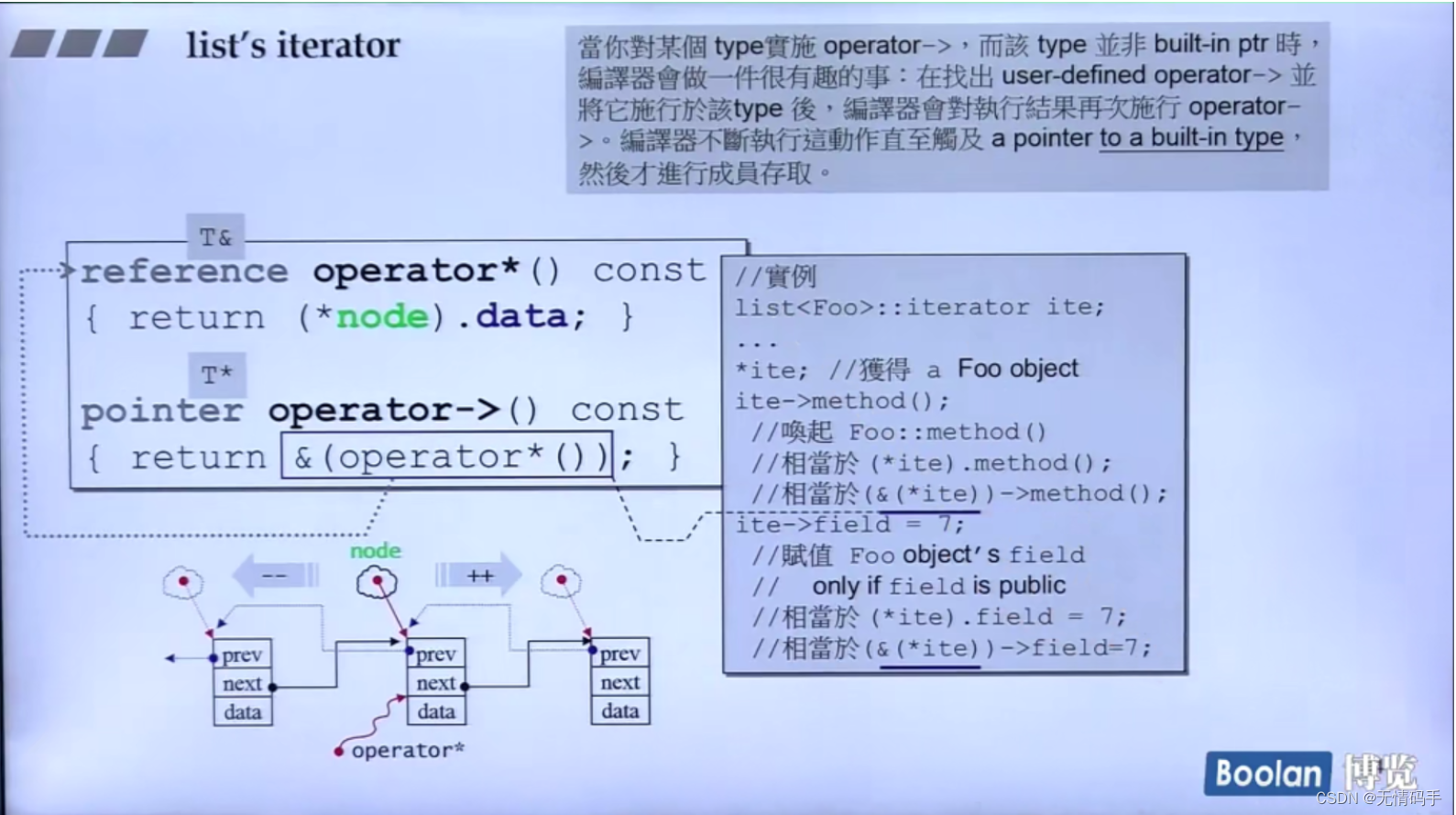
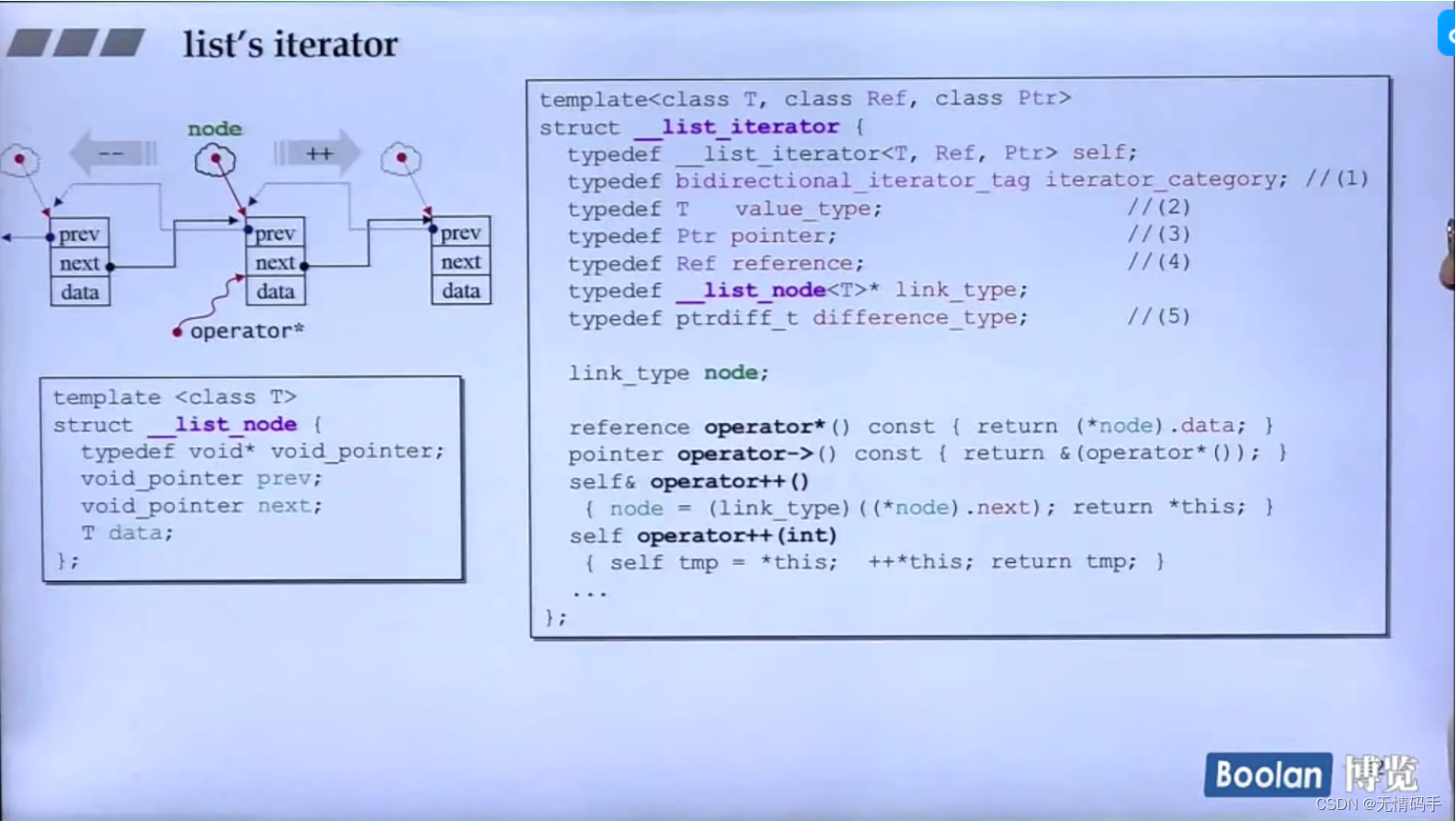
template<class T, class Ref, class Ptr>
struct __list_iterator{
typedef __list_iterator<T, Ref, Ptr> self;
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef __list_node<T>* link_type;
typedef ptrdiff_t difference_type;
linke_type node;
reference operator*() const { return (*node).data; }
//这是返回data的指针
pointer operator->() const {return &(operator*());}
//前++没有参数
self& operator++()
{
//一开始定义的是void_pointer(void*) 所以这里要转一下
node = (link_type)((*node).next);
return *this;
}
//后++有参数
self operator++(int)
{
self temp = *this;
++*this;
return tmp;
}
}
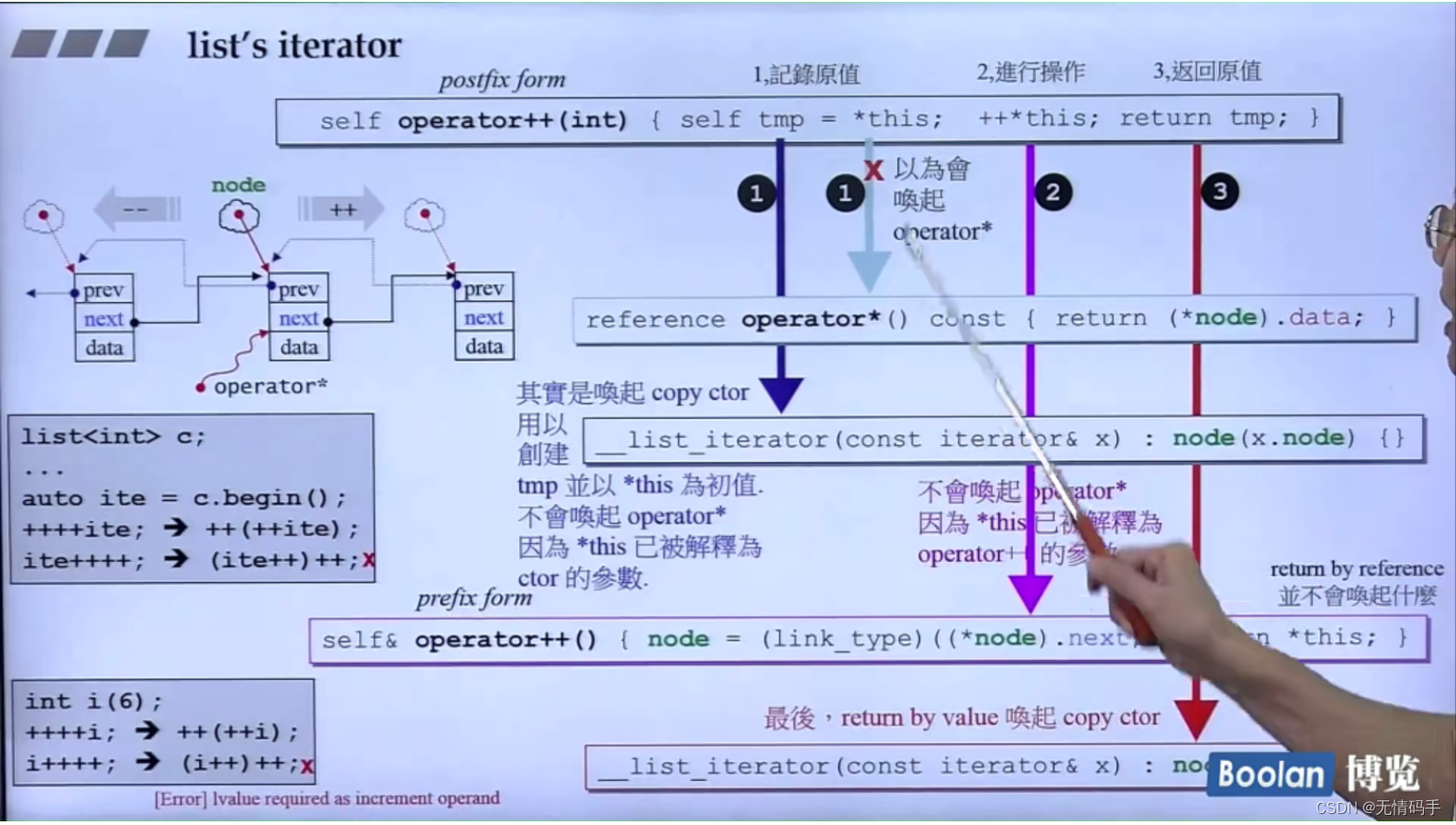
注意看这张图:
**tmp后面紧跟着出现了 = 所以现在是赋值了,那对应的 *this 不会调重载了的那个*,而是将*this 作为初始值,拷贝构造给另一个对象 **
*this 被解释为了ctor的参数
拷贝构造:
__list_iterator(const iterator& x):node(x.node) {}
不允许连续两次后++
因为注意:后++是返回操作之前的对象,而且后++返回的是一个临时对象,而不是引用。(注意这个后++内部的值已经变了哦,但是返回的是+之前的)
a++ 到这里已经没人接收了,所以没法再++
前++是传的引用,所以可以:++(++a)—(这一部分作为引用接收了仍然可以前两个++继续调用);

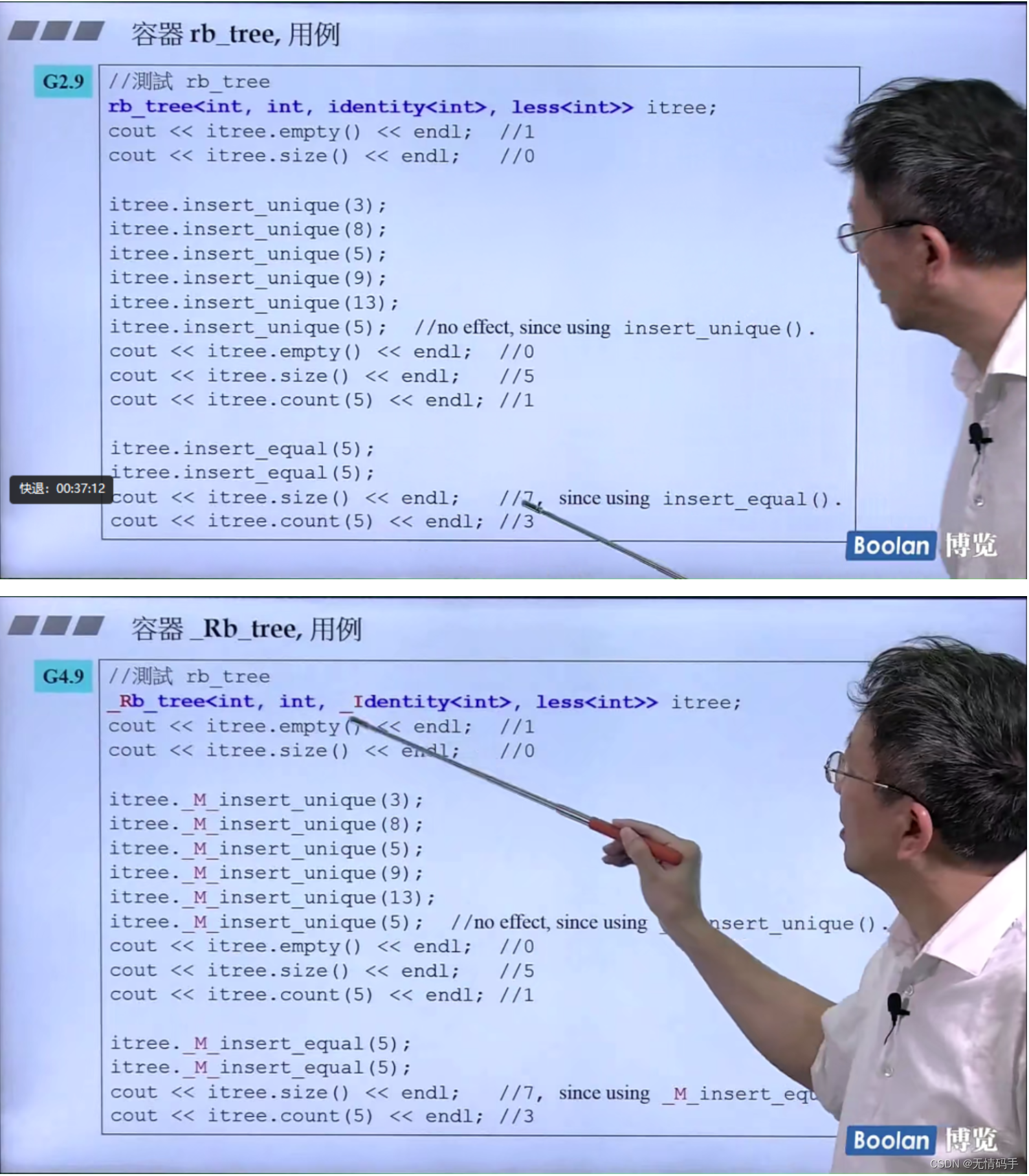
G2.9和G4.9的区别
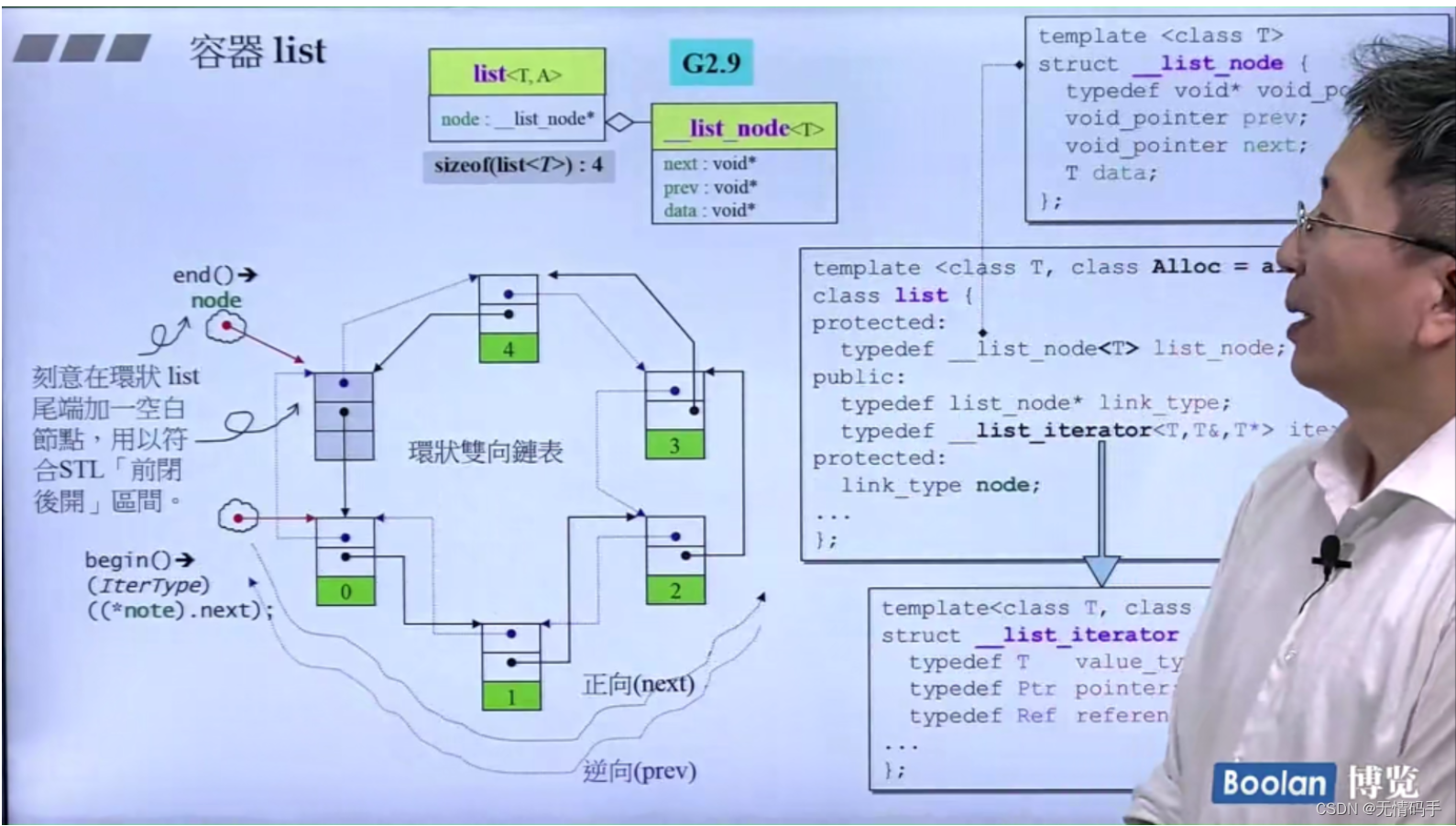
注意 begin() 指的是第一个元素、end()代表最后一个元素的下一个元素
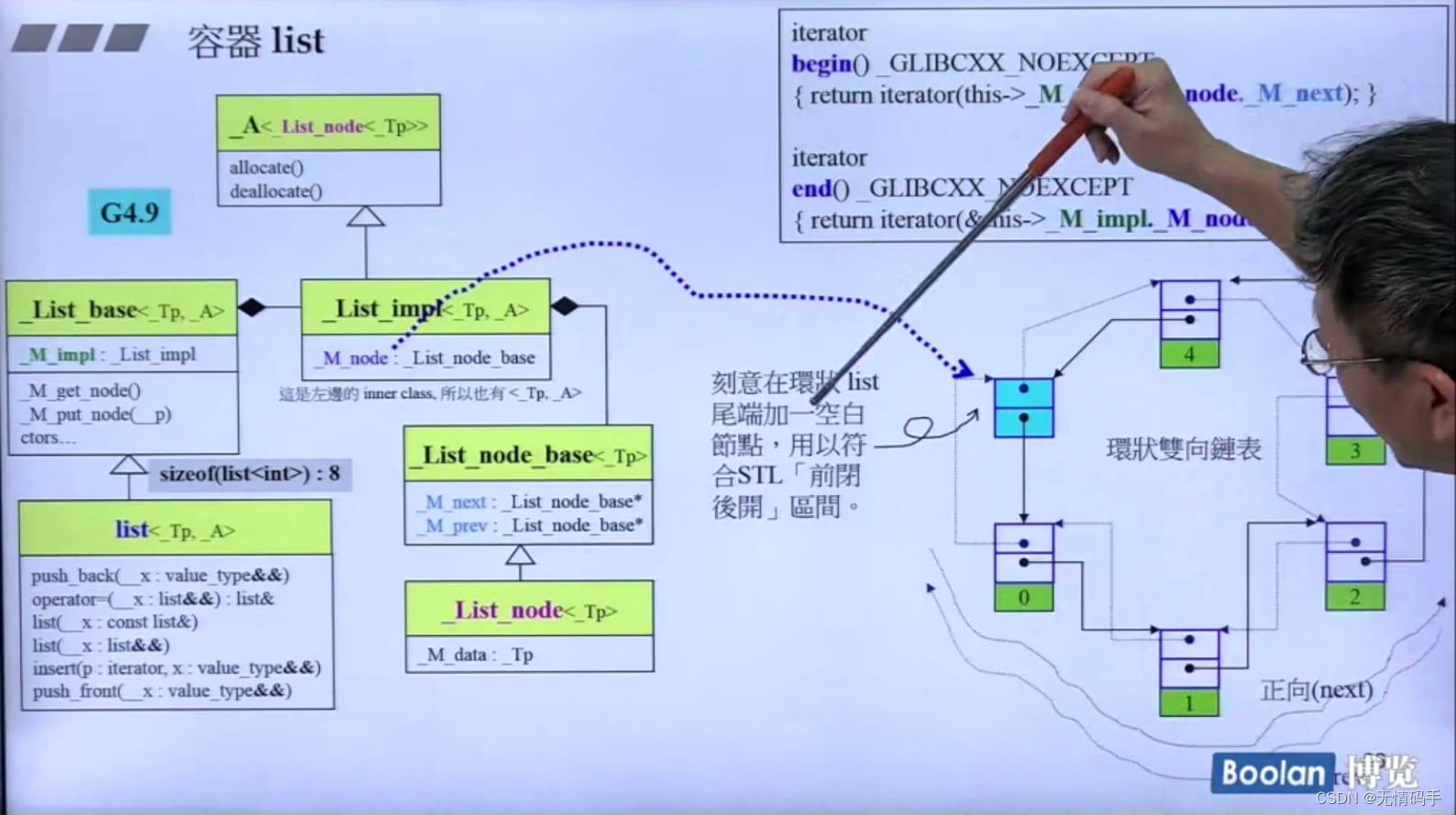
4.9版本的是两个指针 8个byte
15-迭代器原则和Iterator Traits的作用与设计
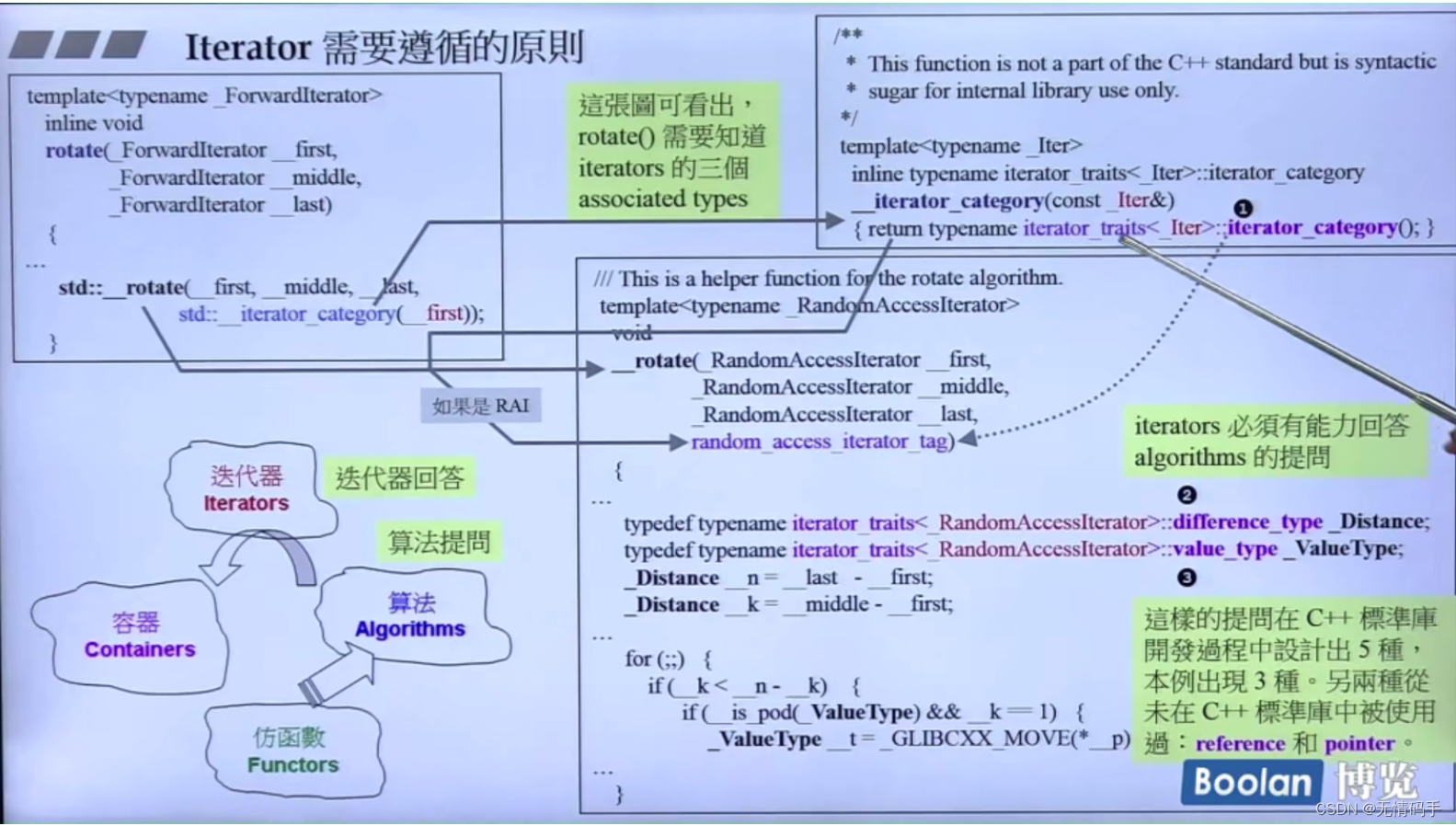
rotate里面需要知道iterator的分类,有的只能++、有的还能–、有的还能+=
Iterator必须提供的5种associated types
- iterator_category
- value_type
- pointer (不会用到)
- reference (不会用到)
- difference_type
算法会提问Iterator、Iterator要回答
template<typename I>
inline void algorithm(I first, I last)
{
I::iterator_category
I::pointer
I::reference
I::value_type
I::difference_type
}
只有class才能做typedef 那就没办法做问答了
如果传进去的只是native pointer 不是 iterator -> Traits
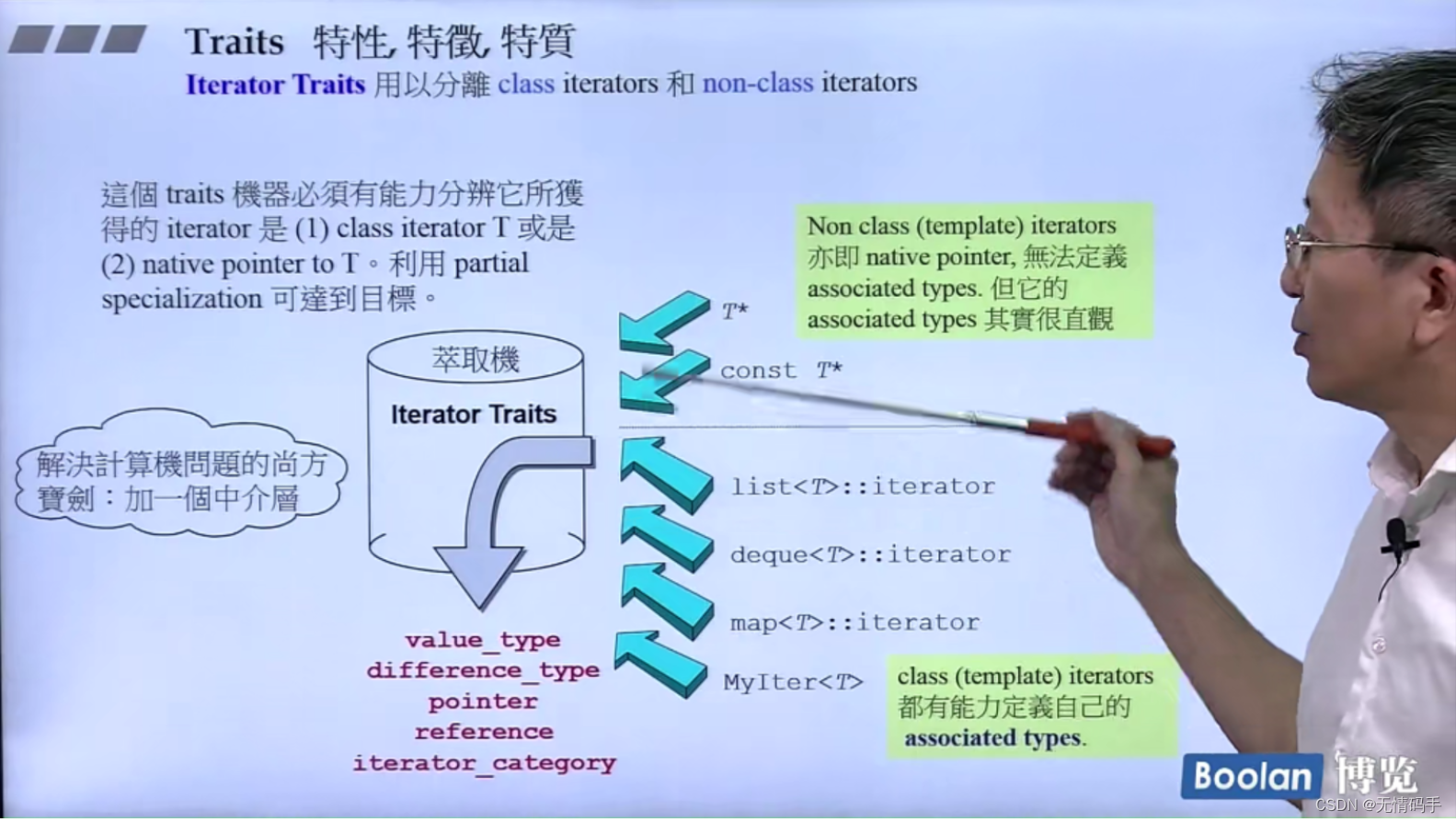
如果是class的iterator 就可以 用问答形式
算法问 traits 、traits转问I
利用偏特化的语法,去分离出类和指针
(分离出了:类、指针、指针指向const)
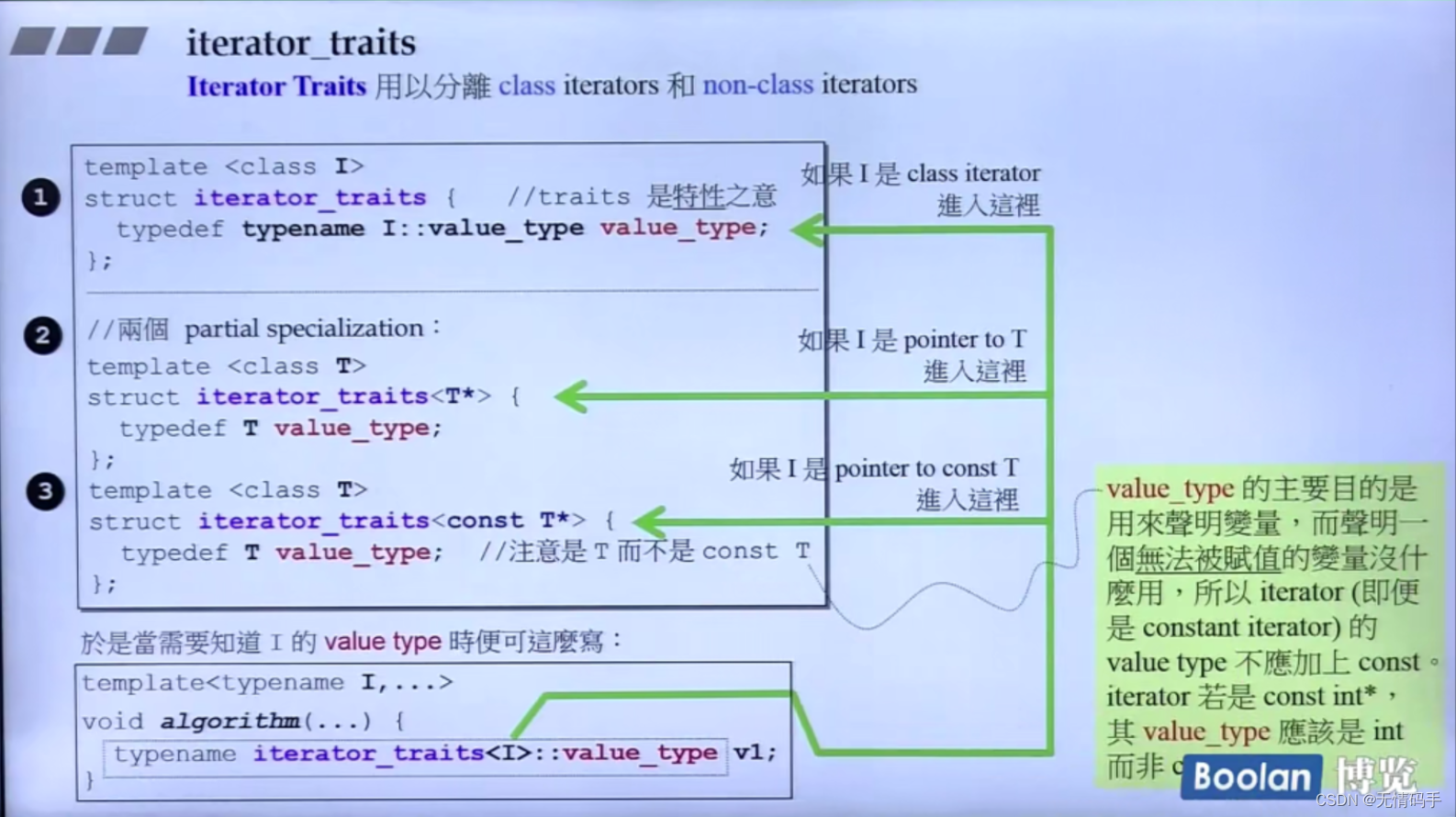
为什么3里面是 typedef T value_type 而不是 typedef const T value_type?
加const 没办法被赋值,没有意义
完整版本:
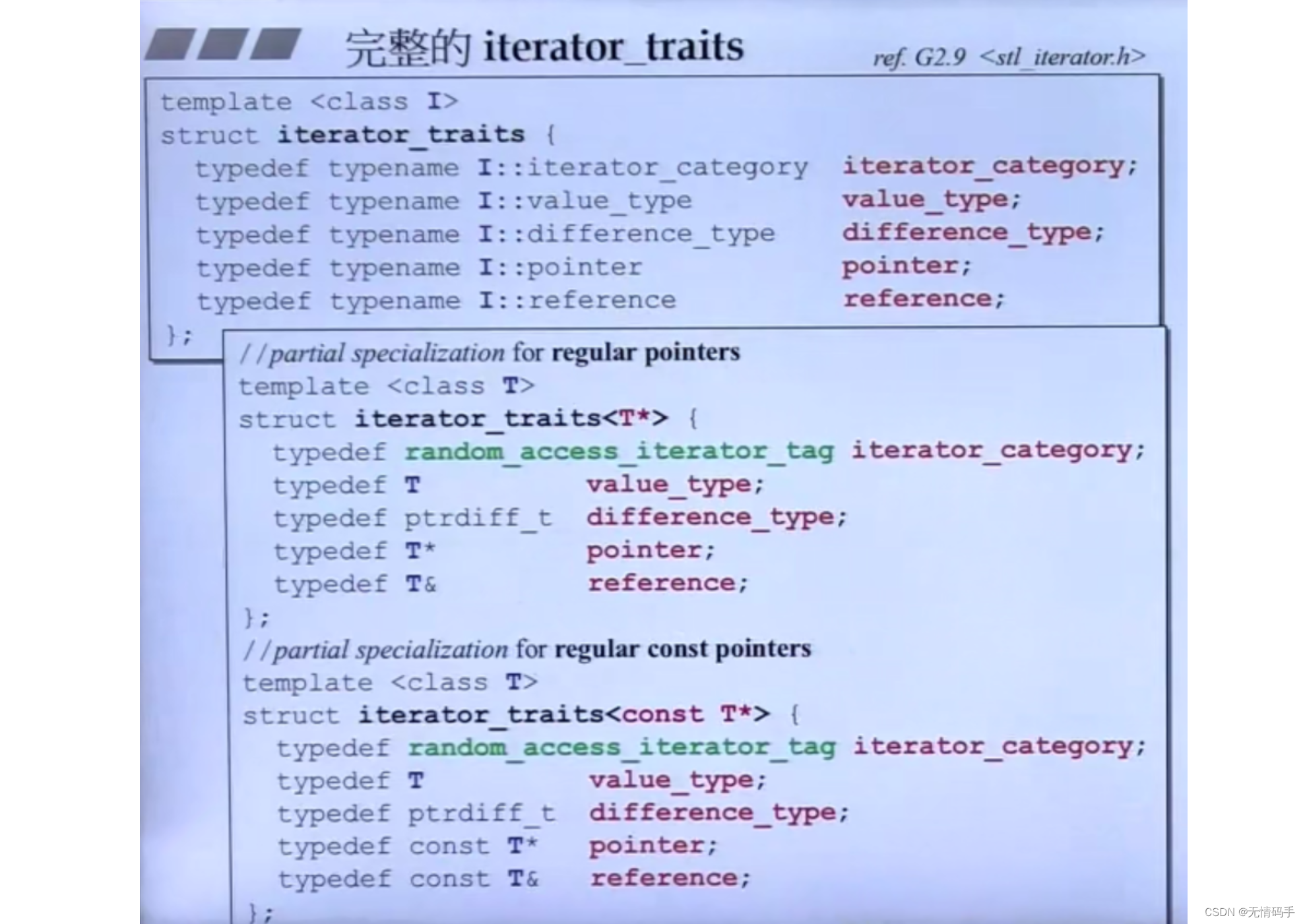
这里指针的iterator_category 是 random_access_iterator_tag
刚刚双向链表的是 bidirectional_iterator_tag
16-vector深度搜索
vector两倍扩充

注意:容器提供连续连续空间,就必须带有operator[]函数
重新开空间的时候,要大量调用vector里对象的拷贝构造函数和析构函数

为什么insert_aux还要再检查一遍是否等于end_of_storage?上面不是已经检查过了吗?
因为这个函数还有可能被其他的函数调用,不只是push_back调用。
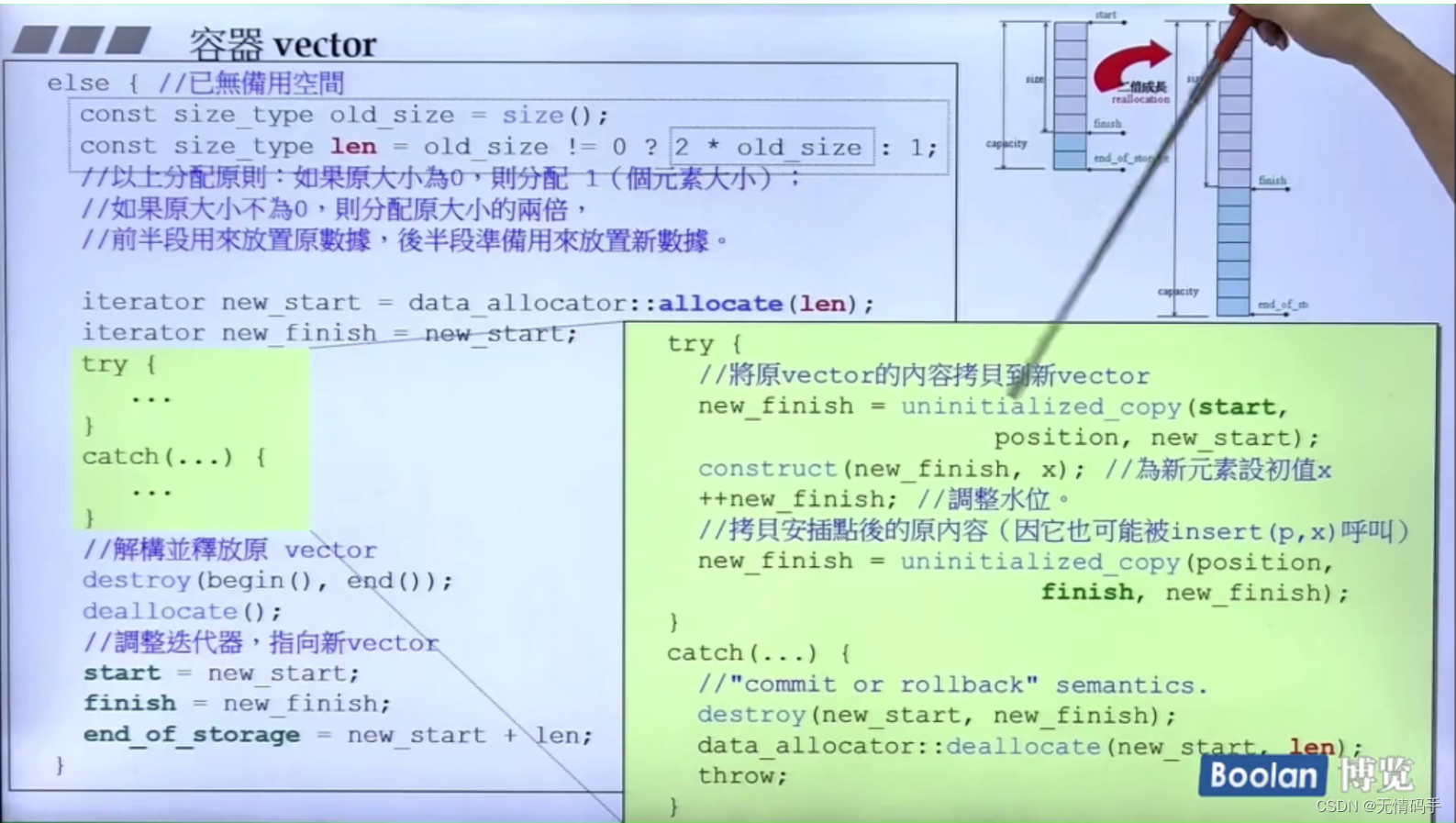
注意try_catch中还要拷贝安插点后的原内容,因为有可能还要被insert调用
vector’s iterator
既然它是连续空间,那么它的迭代器就不需要设计的太复杂,设计成一个class 不必
链表的迭代器需要设计成类,因为它是两头要跑来跑去,它的结点是分离的、它还需要重载operator++、operator、operator->*
G2.9的vector
template<class T, class Alloc = alloc>
class vector{
public:
typedef T value_type;
typedef value_type* iterator; //T*
}
算法通过traits去看它的iterator类型
vector<int> vec;
vector<int>::iterator ite = vec.begin();
//(1)
iterator_traits<ite>::iterator_category;
//(2)
iterator_traits<ite>::difference_type;
//(3)
iterator_traits<ite>::value_type;
G4.9版:
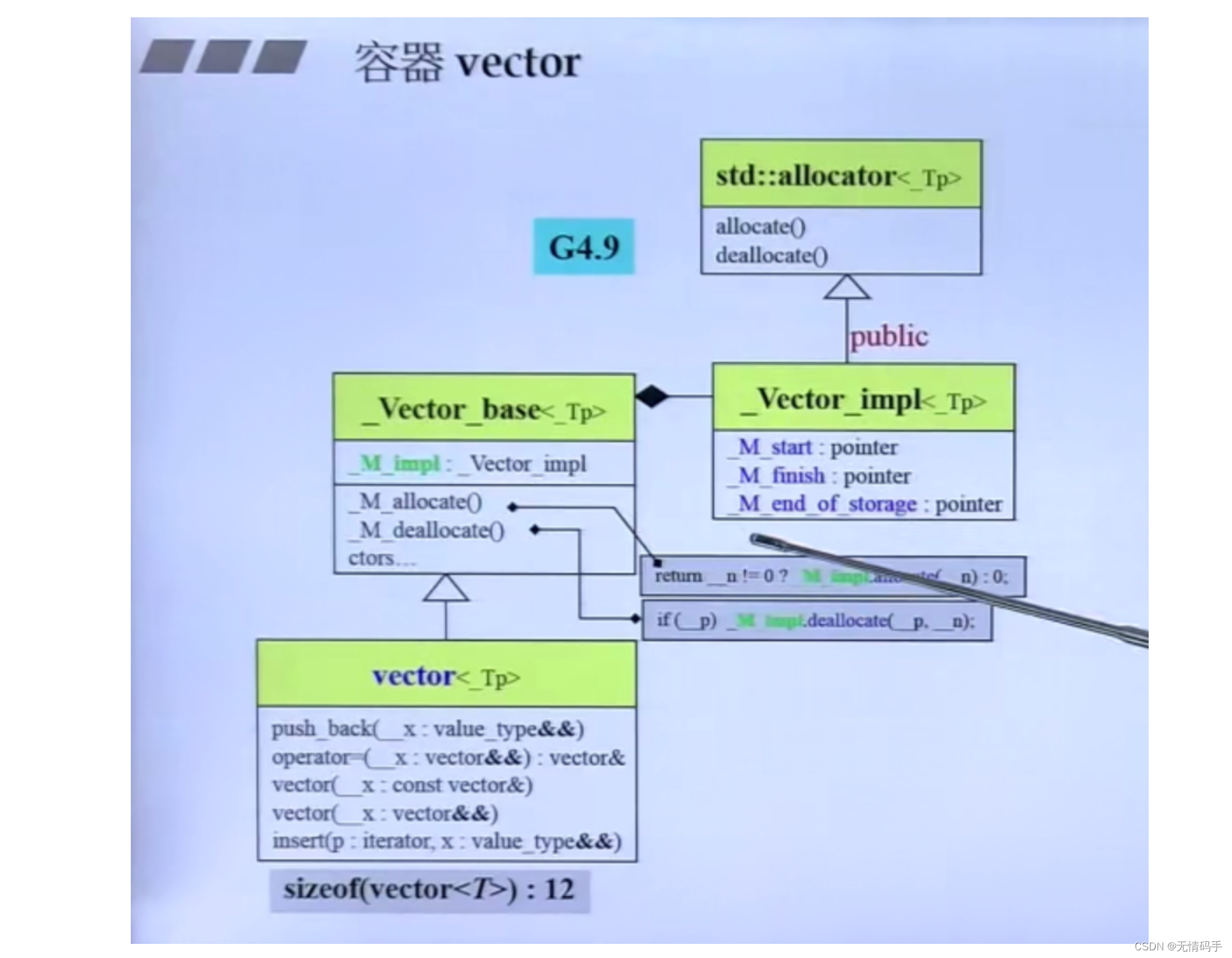
里面有三个指针,所以vector大小为12
public继承 : is a
这里的继承只是为了使用上面的方法,其实应该用private
G4.9版的vector iterator
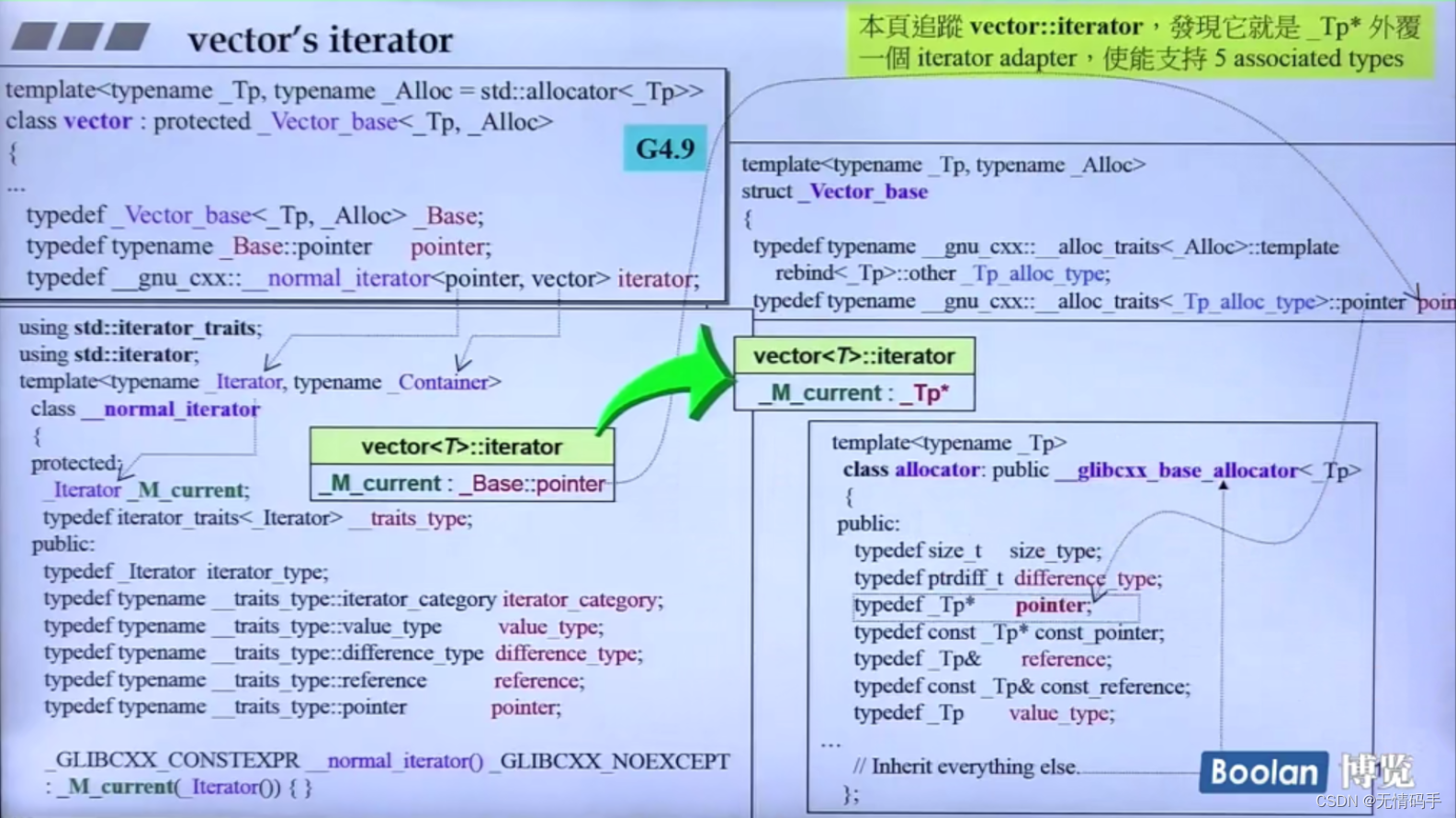
_M_current搞了半天是_Base::pointer类型的,根据定义,它就是_Tp*
4.9版本里的iterator 其实说白了最终指向还是 :_TP*
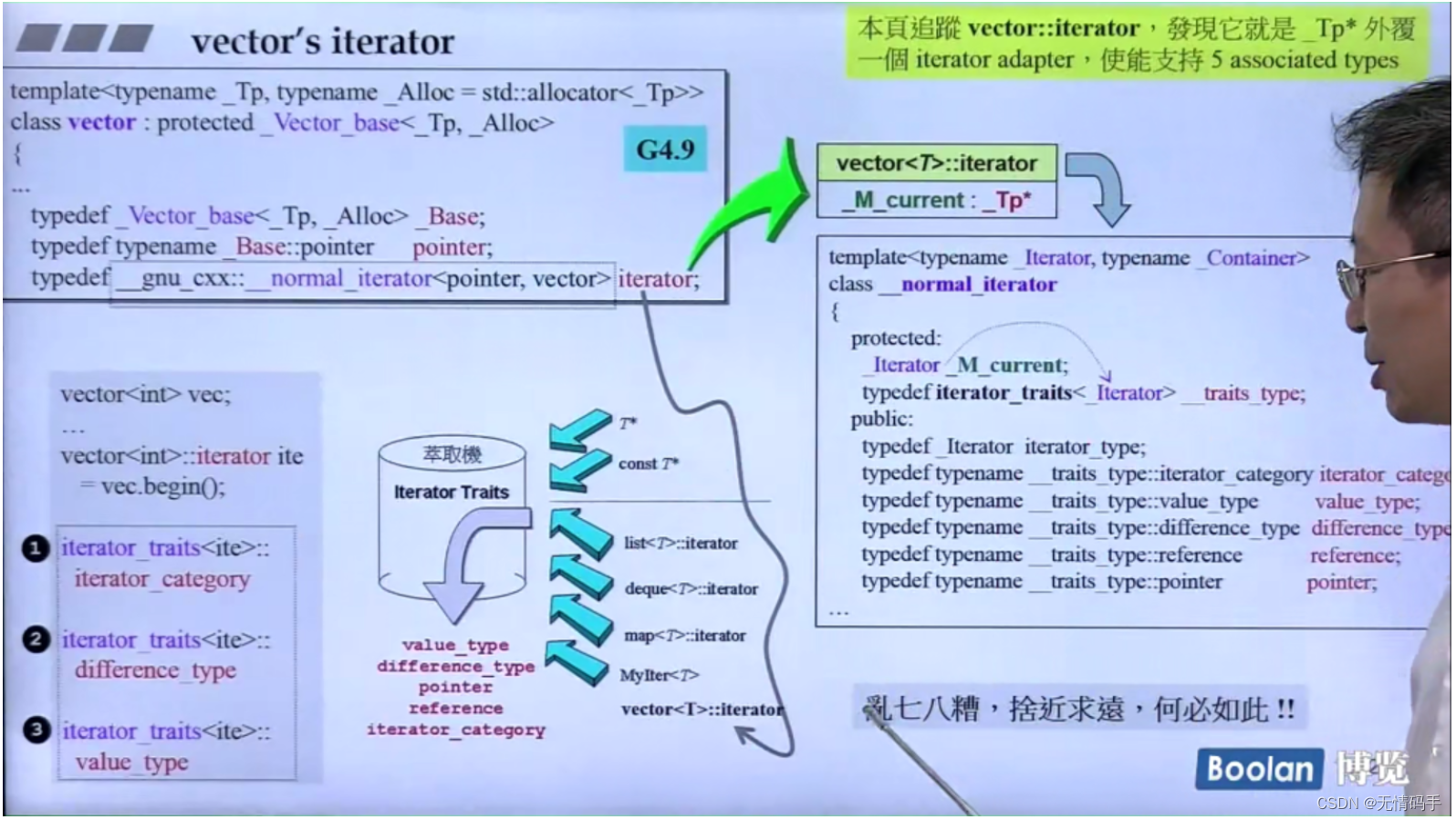
此时再把ite丢给traits,它不再是指针,而是一个class了
为了与traits的兼容性,类里面依然要定义:traits 去获得 它的五个相应的类型
traits 是中间桥梁、它是一个类,它可以再去定义typedef
注意这种定义方法:上面_normal_iterator类里的 itrator_traits<_Itrator> 也是模版,它是在下面才完全定义好的
17-array、forward_list深度搜索
array 不可扩充,需要一开始指定大小
array没有ctor 和 dtor

注意:G4.9中以这样的方式定义处array数组出来
typedef _TP _Type[_Nm];
//使用的时候可以:
_Type _M_elems;
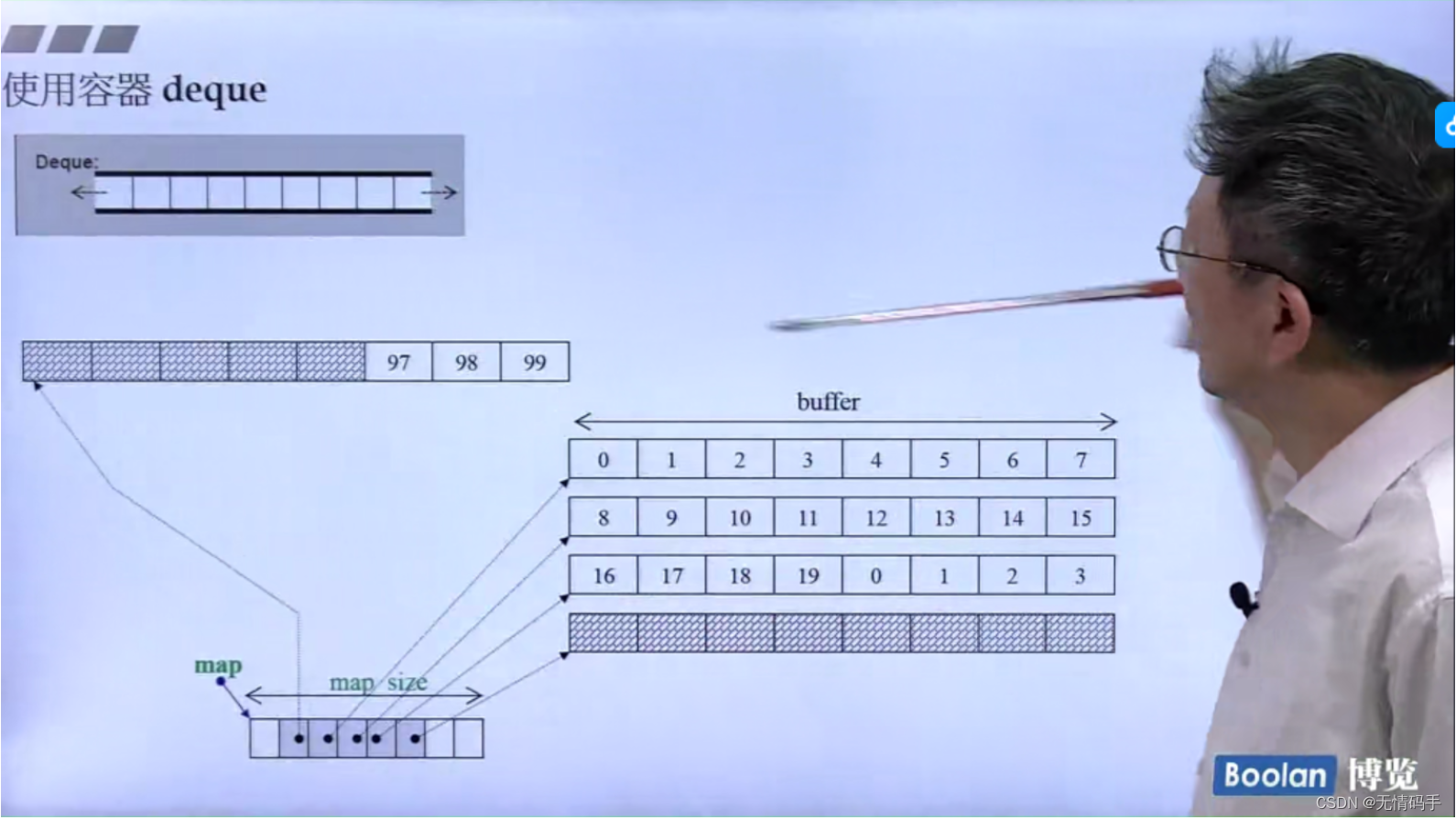
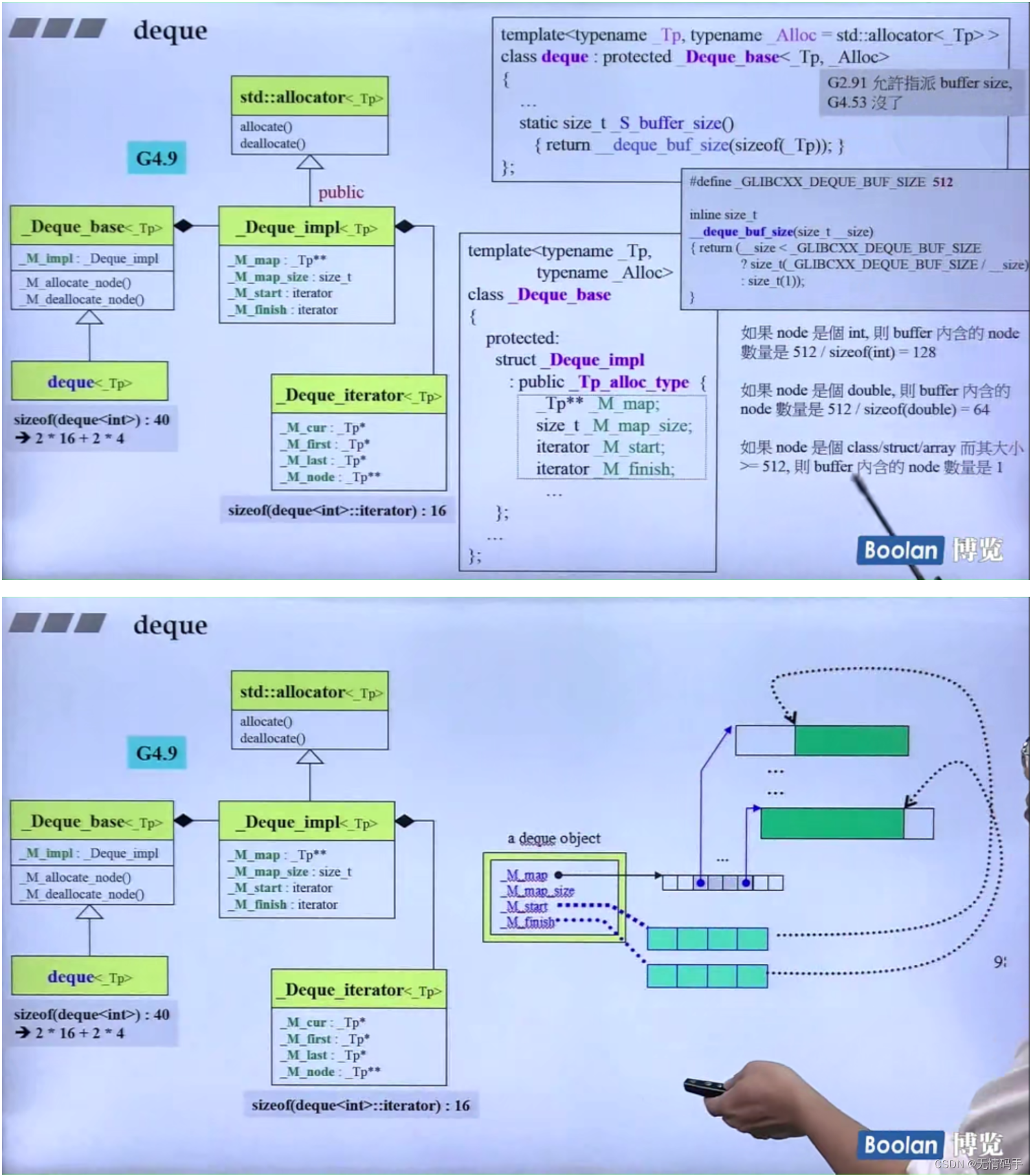
18-deque、queue 和 stack深度探索(上)
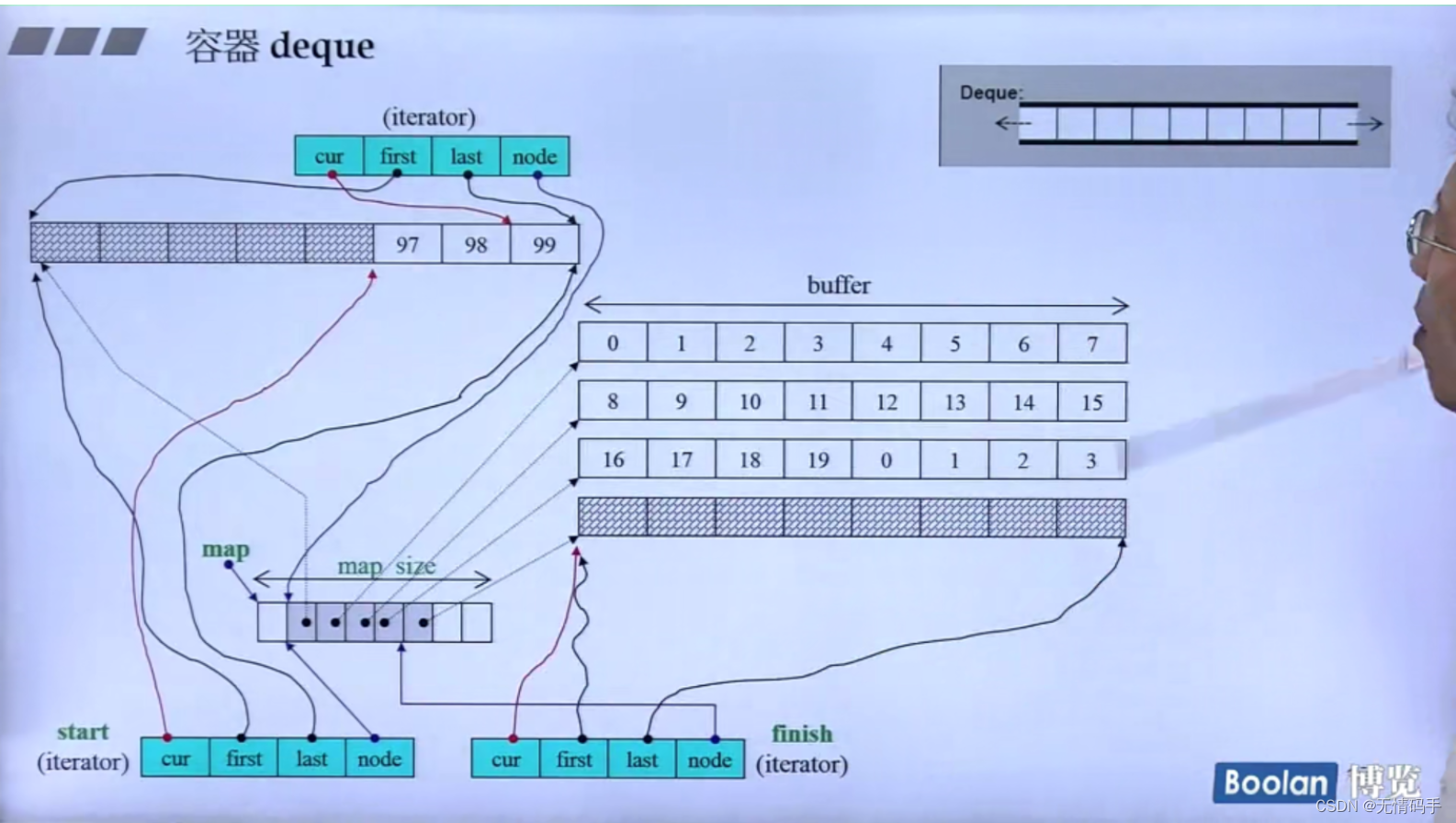
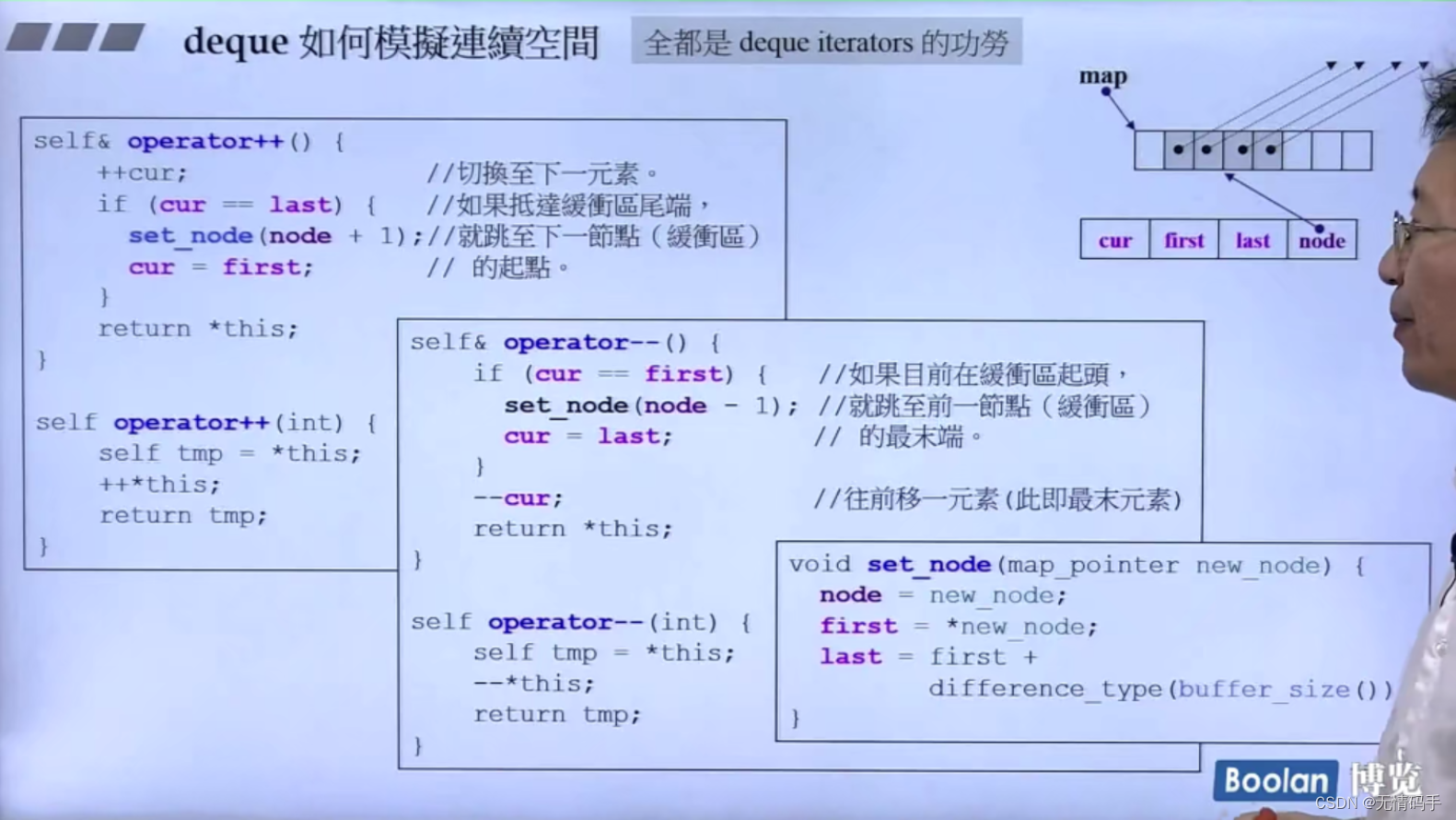
deque 分段连续、迭代器为了维持连续的假象,当迭代器走到了边界(无论尾巴边界还是头边界,都要有能力跳到下一个缓冲区。怎么跳到下一个缓冲区? 靠node指针回到控制中心)
为什么画出3个iterator?
所有的容器都维护了两个迭代器,分别指向头和尾
看分配空间:n不为0,buffer size为自定。 如果n为0,表示buffer size使用预定值
如果size>512字节,就默认让一个缓冲区就放一个元素
如果放的是int 4个字节,那么buffer的大小是128
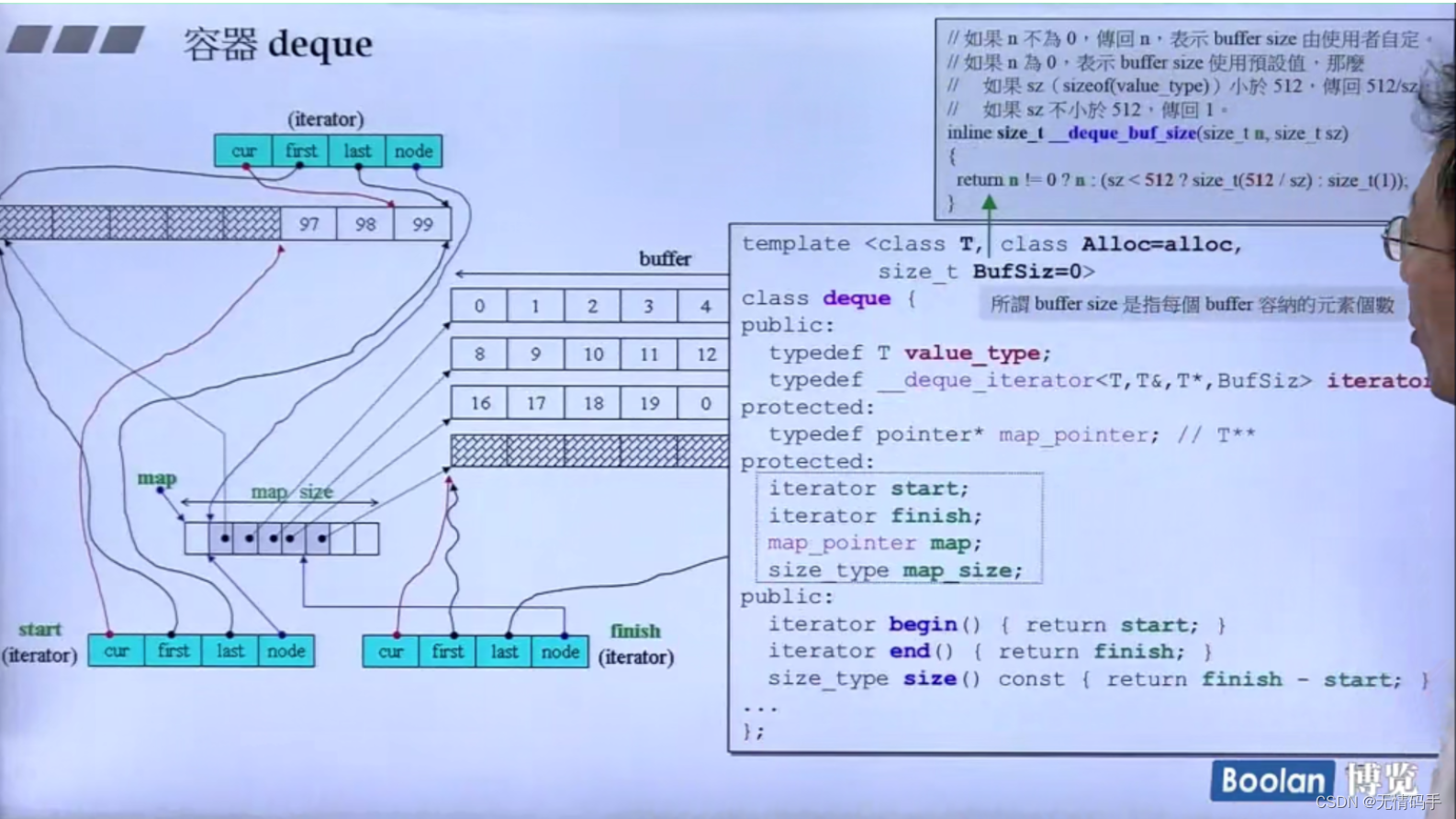
map是控制中心,它是一个vector,它也是2倍增长
为什么map 是 T**类型? 因为map里每一个元素都是指针类型
map 里的元素 是T* 类型
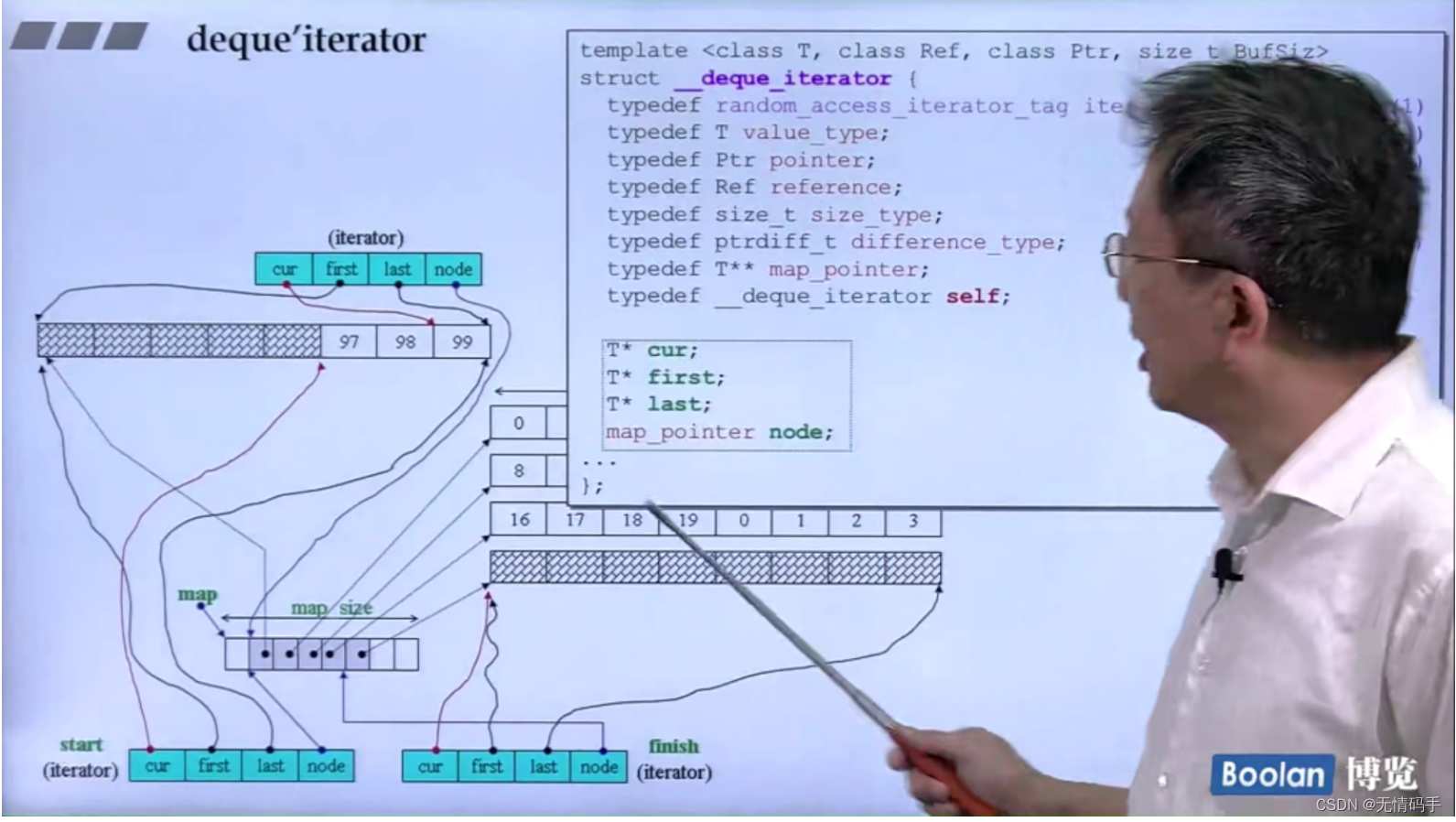
deque 的 iterator 大小为16
那么deque是两个iterator、一个map(T**)、一个map_size(size_type),一共是16*2+4*2 = 40
注意 deque的iterator是 random_access_iterator_tag 可以跳
deque要插入元素,是要往前推动,还是往后推动?看它哪个代价更小
看看是不是头位置?尾位置?都不是的话就调用insert_aux

19-deque、queue 和 stack深度探索(下)
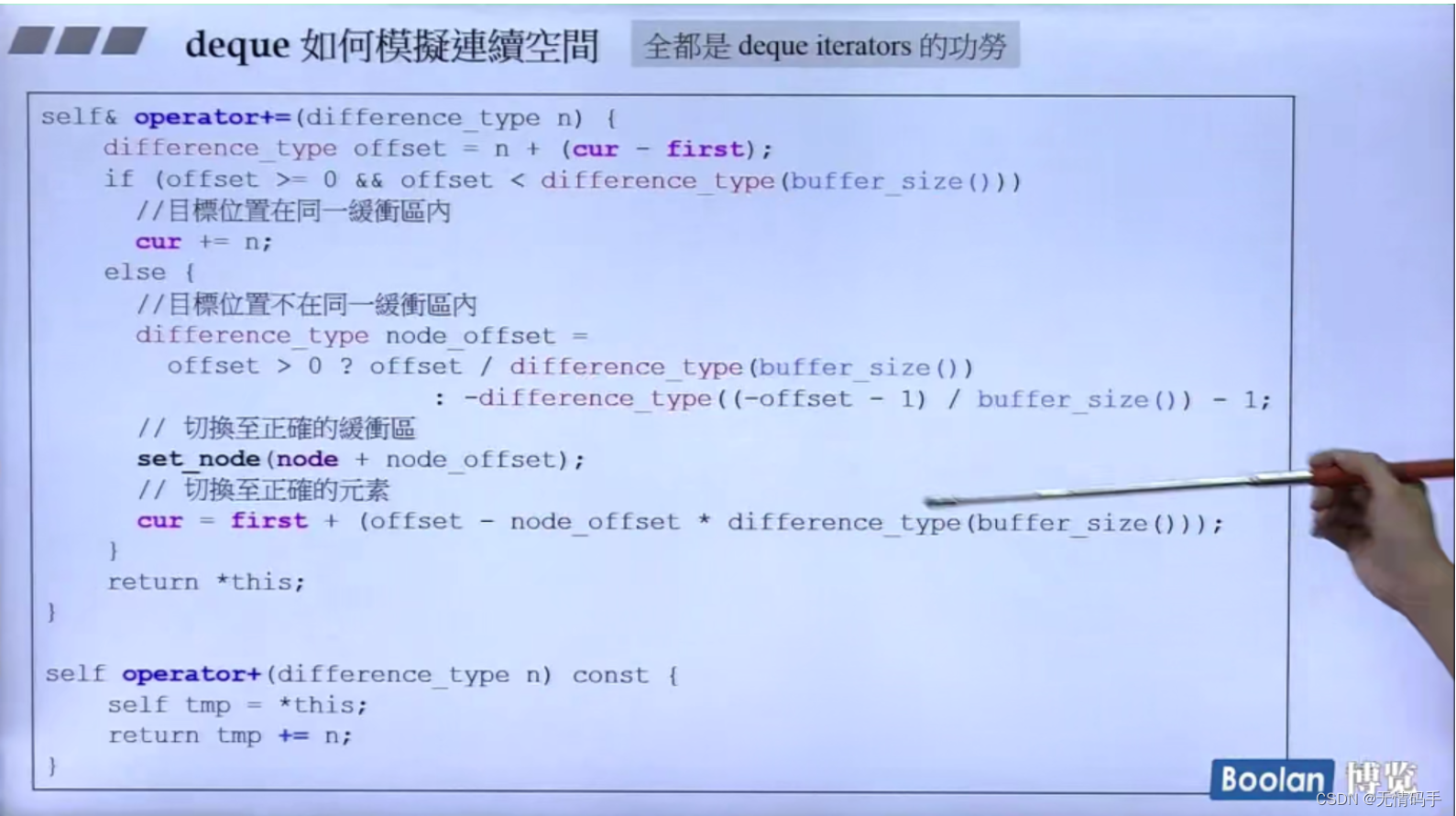
node相减:控制中心在迭代器里的距离
node - x.node - 1 (算完整的buffer块有几个)
cur - first(末尾(当前)buffer元素量)
x.last - x.cur 起始buffer的元素量
往deque里插入元素的时候,插入位置等于start的cur push_front()、让cur–
first本身就是指针、单独用first就是它自己本身的地址么、first + difference_type(buffer_size()) 就是last指针的地址
加完 / 减完 看看有没有跨越缓冲区
G4.9
queue 和 stack 是使用deque


不允许你任意地往里面放元素,这样会破坏这个容器的初衷。因此这个容器不提供迭代器

20-RB-tree 深度搜索
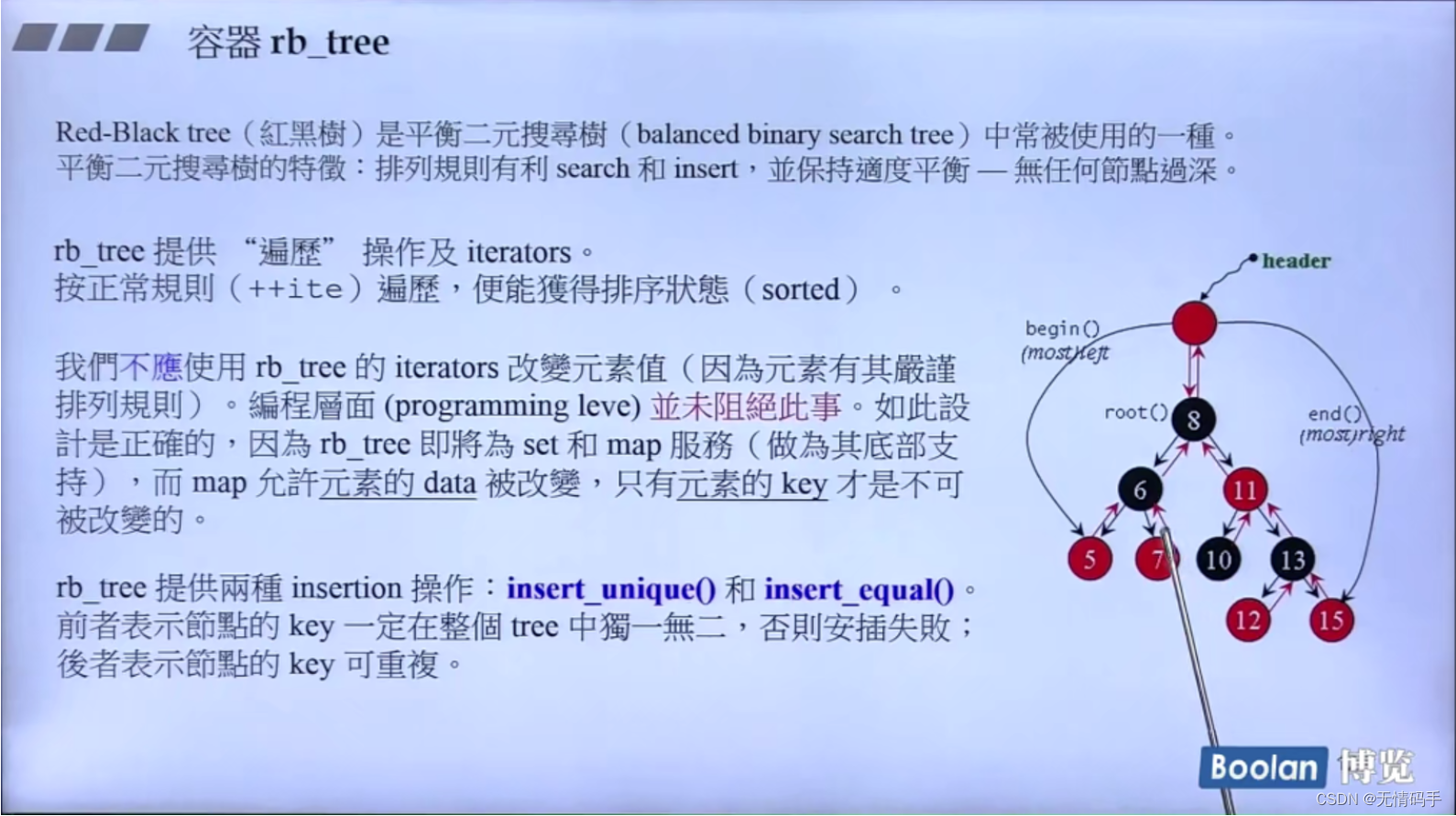
begin() 记录最左边的节点
end() 记录最右边的节点
正常遍历就可以得到排序状态
不应使用 rb_tree 的iterators 改变元素值(因为元素有其严谨的排列规则)
将来要为map / set 做支撑,map允许元素的data被改,key不能被改,所以这里没有直接写死成不能改
用 insert_unique 如果里面的key已经存在,那么是放不进去的
用insert_equal 是可以放进去的
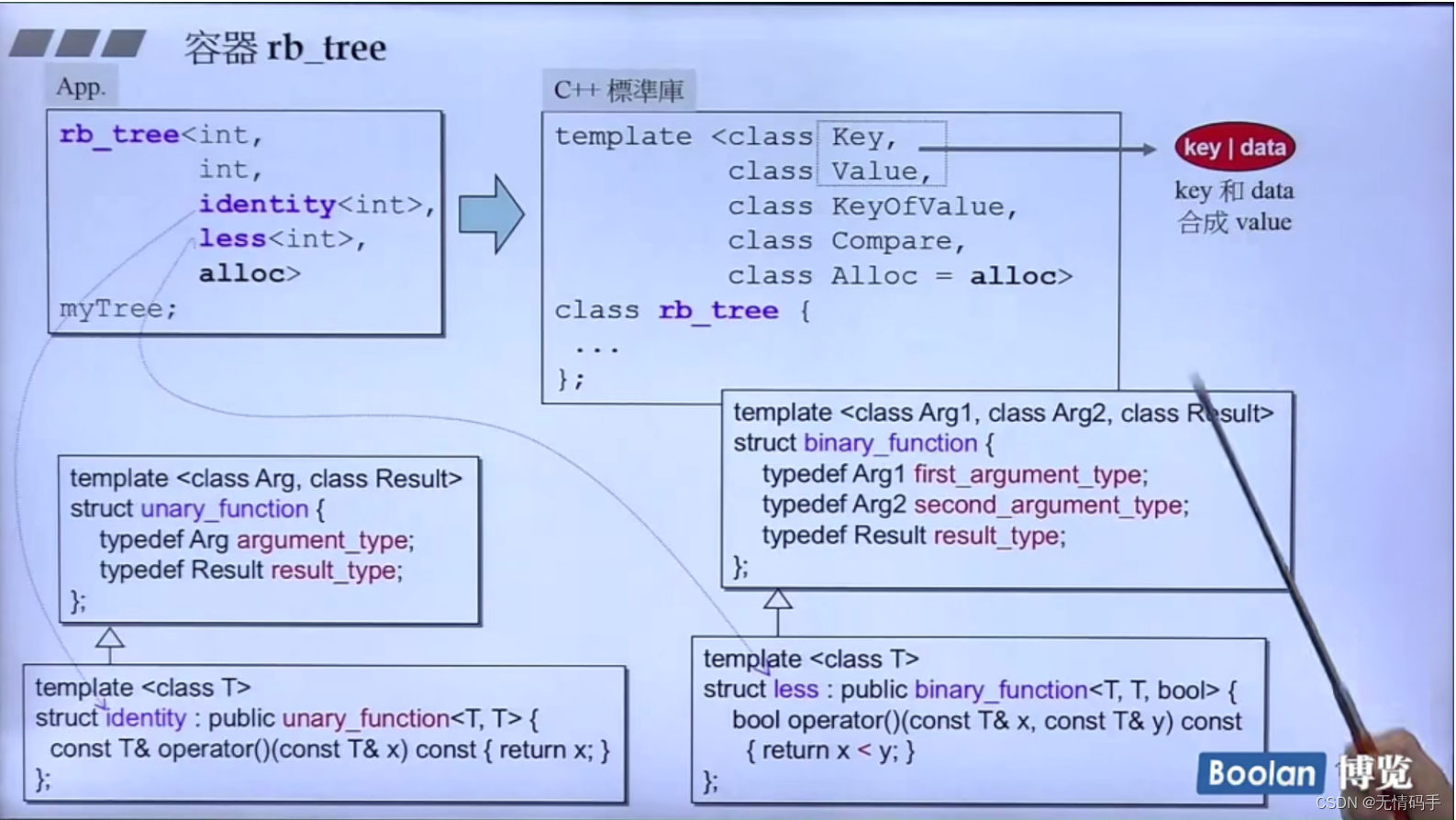
key 和 data 加起来 合称 value
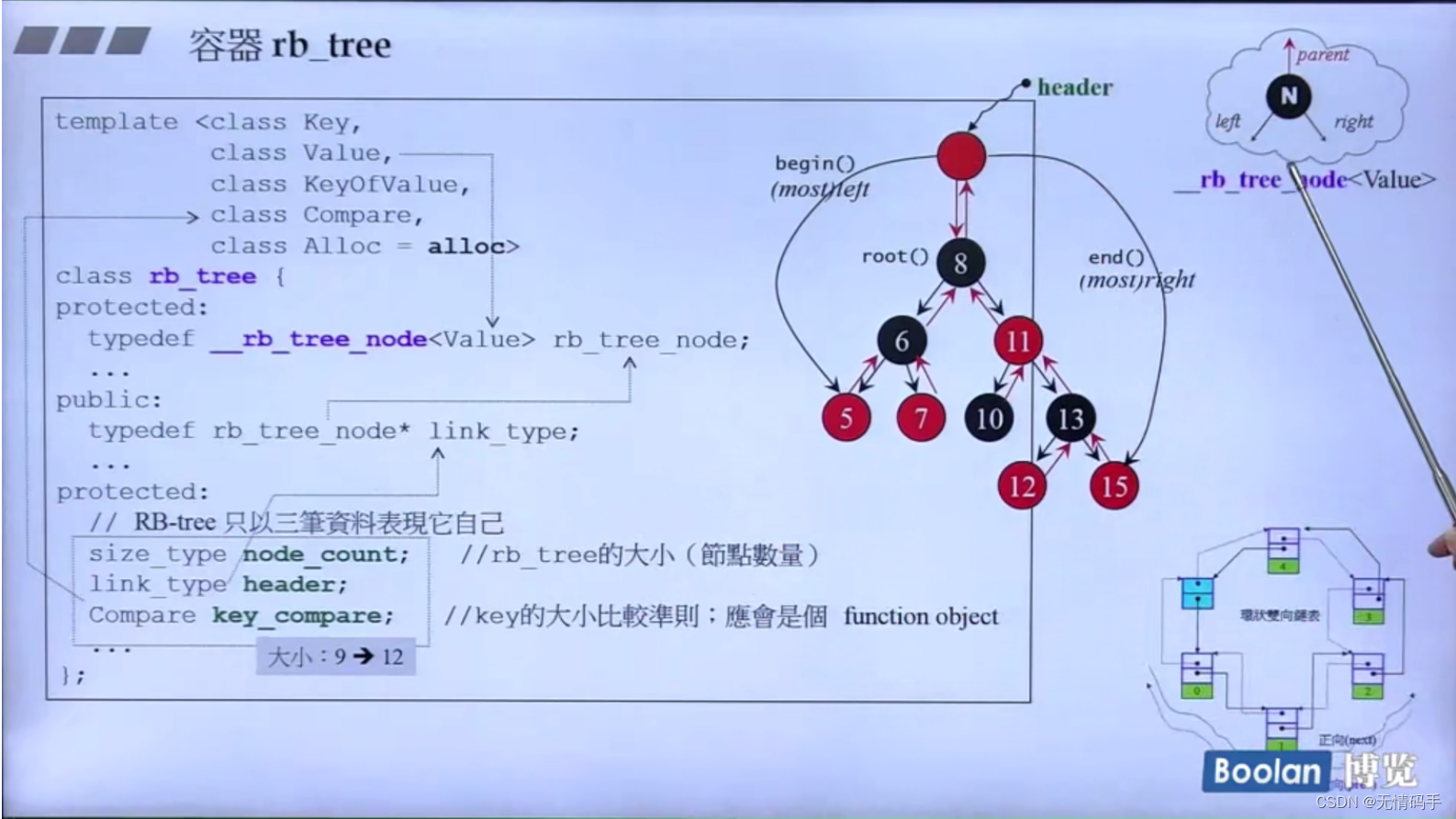
对于大小为0的class,实现上创建出的对象大小为1,因此它整体的大小是 4+4+1 = 9 -> (12)
红黑树的大小:
G2.9里:12
G4.9里:24
和双向链表一样,为了达到前闭后开,设计了蓝色部分的虚空的东西
红黑树也一样,它的header也是方便于实现
rb_tree<int,
int,
identity<int>,
less<int>,
alloc>
myTree;
//这里的Value 只是int,说明它的Key 是int value没有
//identity
//这是一个class,但是它对小括号做了操作符重载
//所以这个class做出来的object对象 行为就像function -> 仿函数(函数对象)
template<class T>
struct identity:public unary_function<T, T>{
const T& operator()(const T& X) const {return x;}
}
template <class T>
struct less:public binary_function<T, T, bool>
{
bool operator()(const T& x, const T& y) const
{
return x < y;
}
}
4.9 和 2.9 的对比:
21-set、muitiset深度搜索
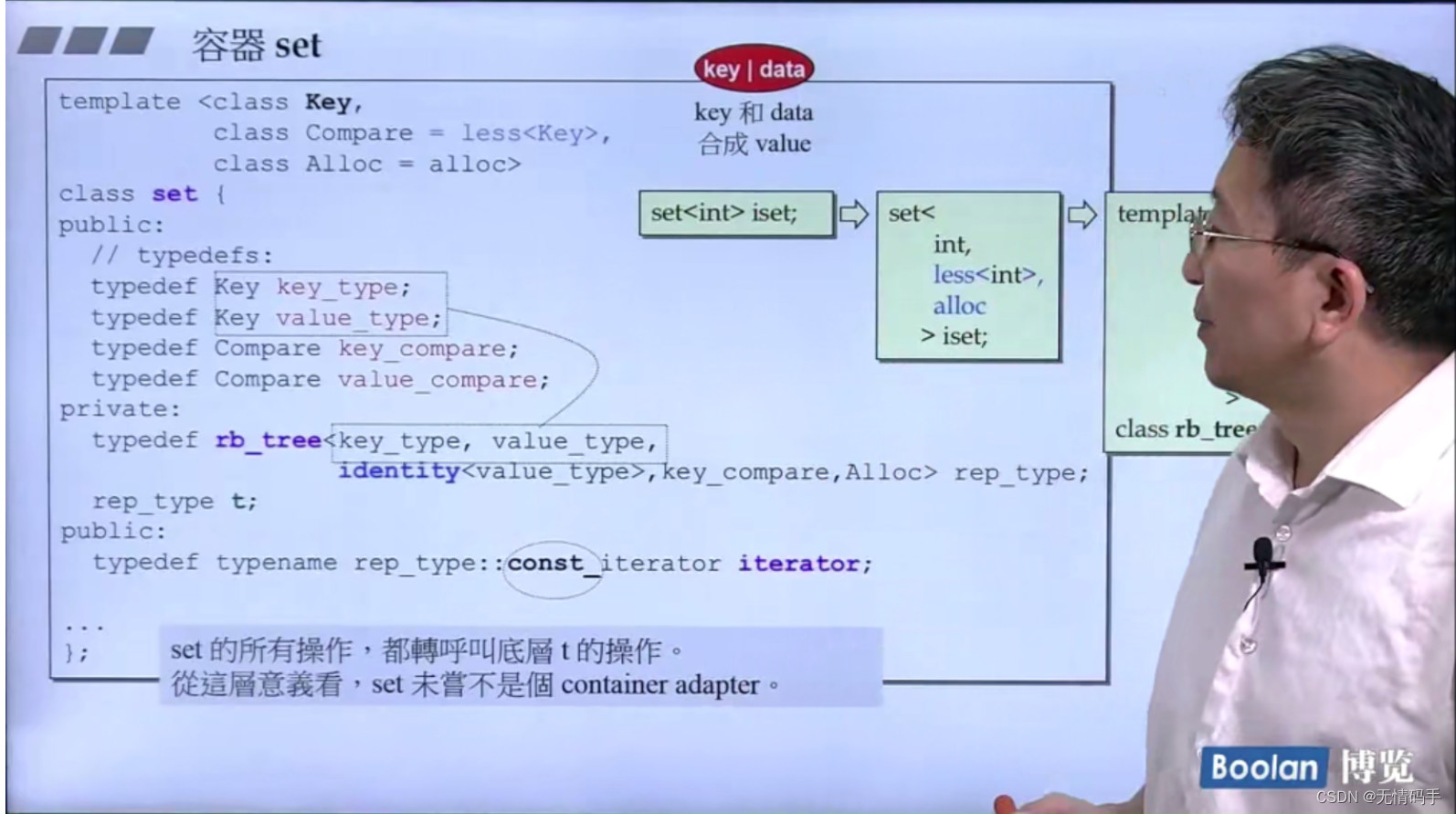
set 元素的 key 必须独一无二,因此insert() 用的是insert_unique()
multiset 元素的 key 可以重复,因此insert() 用的是 insert_equal()
怎样用value去取key呢?对于set来说,key就是value,用identity去取
set也是调用底层容器,其实它也是一种container adapter!
set 里的 iterator 是const_iterator 不可以用它去改变里面的东西

VC6 不提供identity()

22-map、multimap深度搜索
无法使用迭代器改变元素的key
map元素的key必须独一无二、multimap的key可以重复

map里的value_type 是pair类型,之后也会把它再次放到红黑树的模版里
这里map 自动地把 Key 设置成了 const,下面的迭代器不是const_iterator
VC6 里的select1st
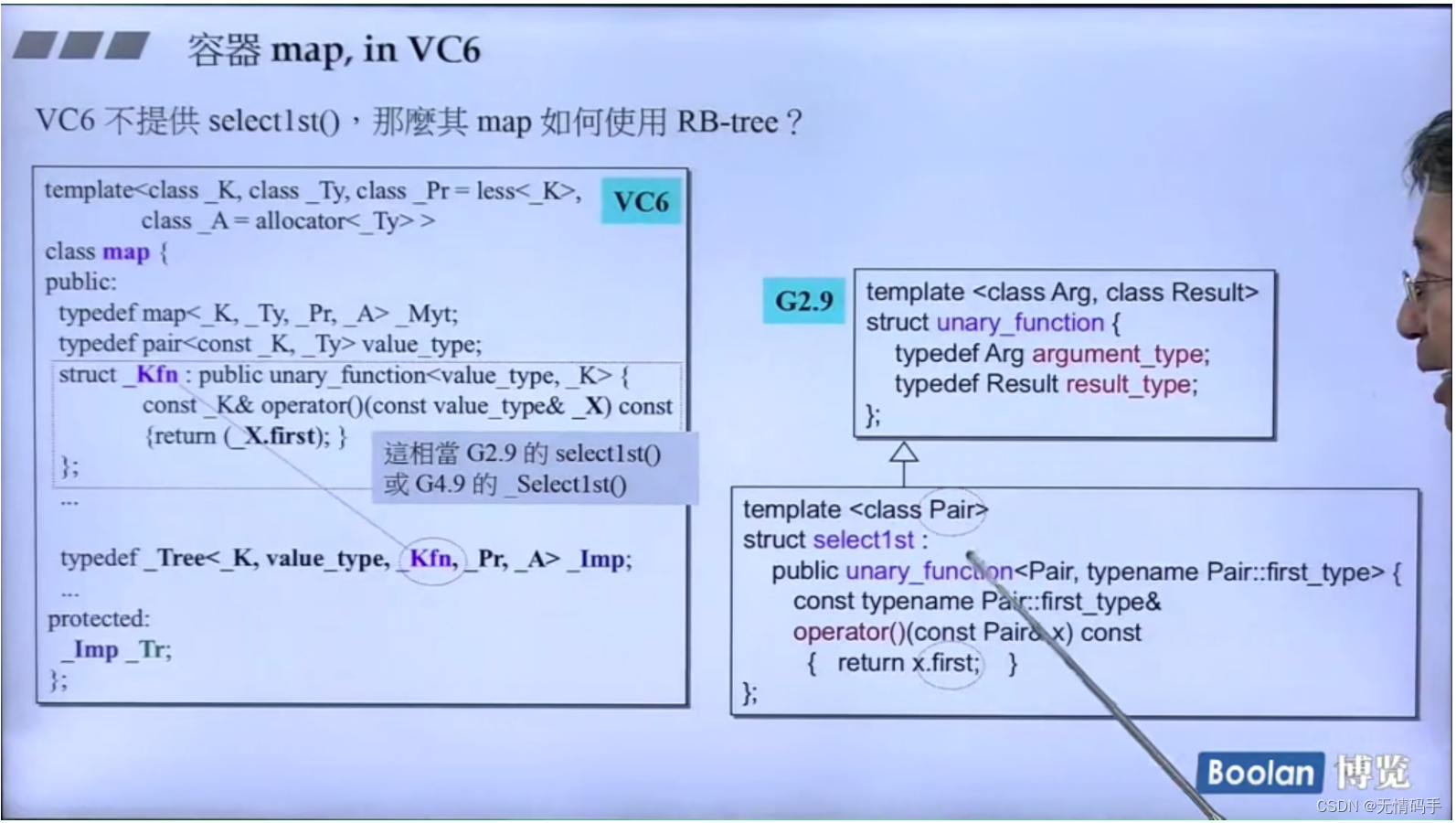
注意:multimap不能用[]做insertion
容器map如果key不存在,会创建一个key放进去

lower_bound() 找 hello 里面如果有7个"hello",他们也是排在一起的,他会返回给第一个
如果没有的话,他会传回最适合放它的位置
所以map 可以 用 map[i] = “xxx”;
operator[] 如果没有找到,不仅在红黑树中插入了新的节点,还返回了第二个值的引用 让我们去赋值
不过它是没有直接insert 快的,因为它里面调的也是insert
23-hashtable深度搜索(上)
Separate Chaining
bucket 篮子
篮子的个数是质数,当元素数大于篮子数目时,篮子会扩张到它两倍后最接近的素数去,再重新对每个元素计算它的id%篮子总长度,进行重新分配

class HashFcn (怎么把对象转变成一个编号的?) -> 算出HashCode
用HashCode % 篮子个数 = 放的位置
ExtractKey -> 现在放的东西是一包东西,告诉他怎么从这里取出Key
EqualKey -> 告诉它怎么就是Key 相等 才能去比大小
private 下是三个函数对象
*vector<node ,Alloc> buckets ** -> 一堆篮子
hashtable 的大小 3 + 12(vector的大小) + 4(size_type) = 19 -> 20字节 (调整为4的倍数)
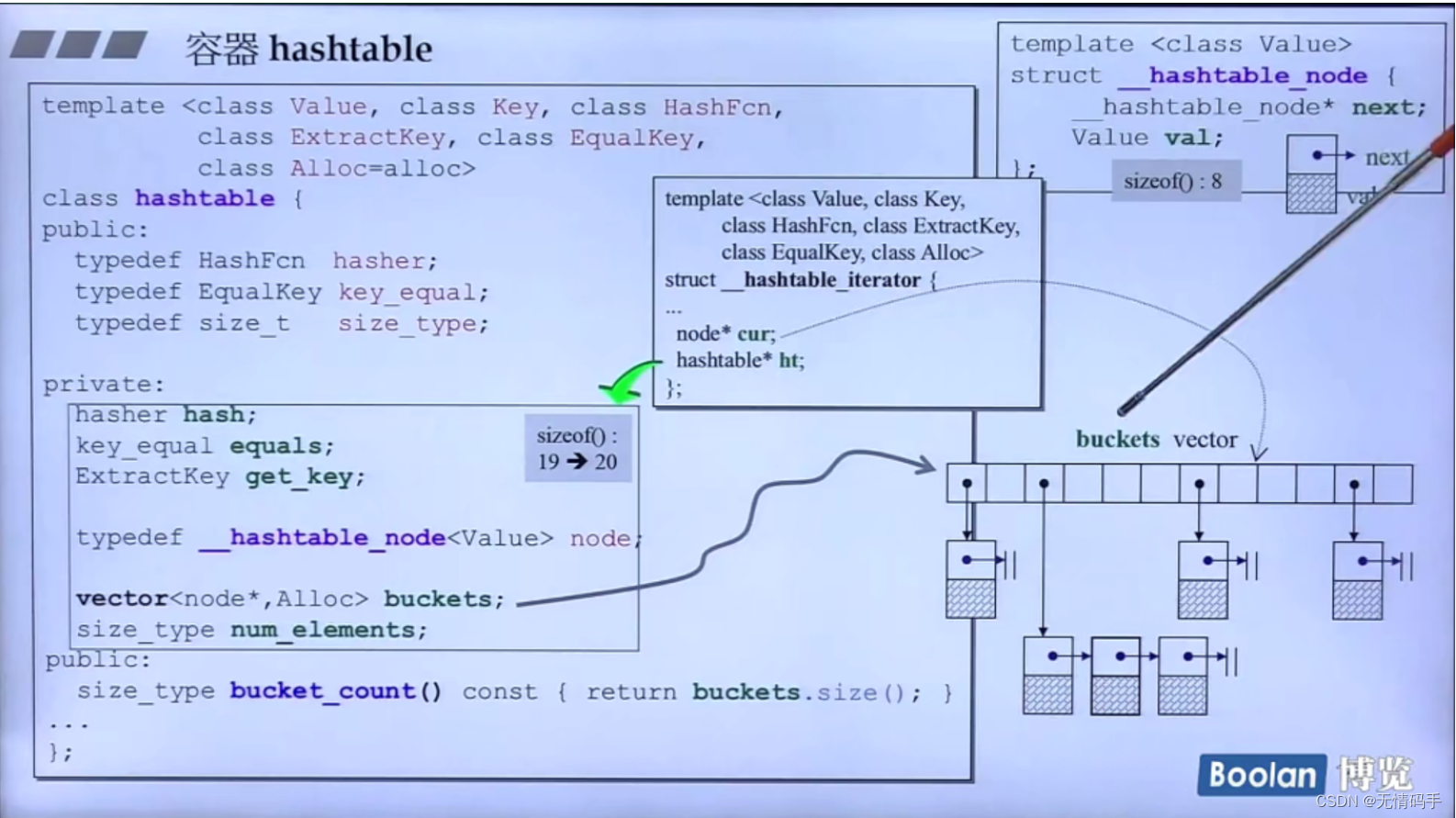
node是_hashtable_node类型的,它是单向链表
注意对于这个iterator来说,当让它++,它走到头的时候,需要进入到下一个bucket里
迭代器里的cur 指向篮子里的某一个节点(图画错了)
当走到尽头的时候,指针cur必须回去,所以有一个指针指向hashtable本身
24-hashtable深度探索(下)

现在Key和Value都是字符串,且Value里只有Key, 所以用ExtractKey(Identity)去提取Key是合理的
这里写了一个判断相等的函数eqstr(是看字符串内容相等,而不是地址)
eqstr里调用的strcmp,为什么不直接将strcmp当作 EqualKey呢? 返回值不同
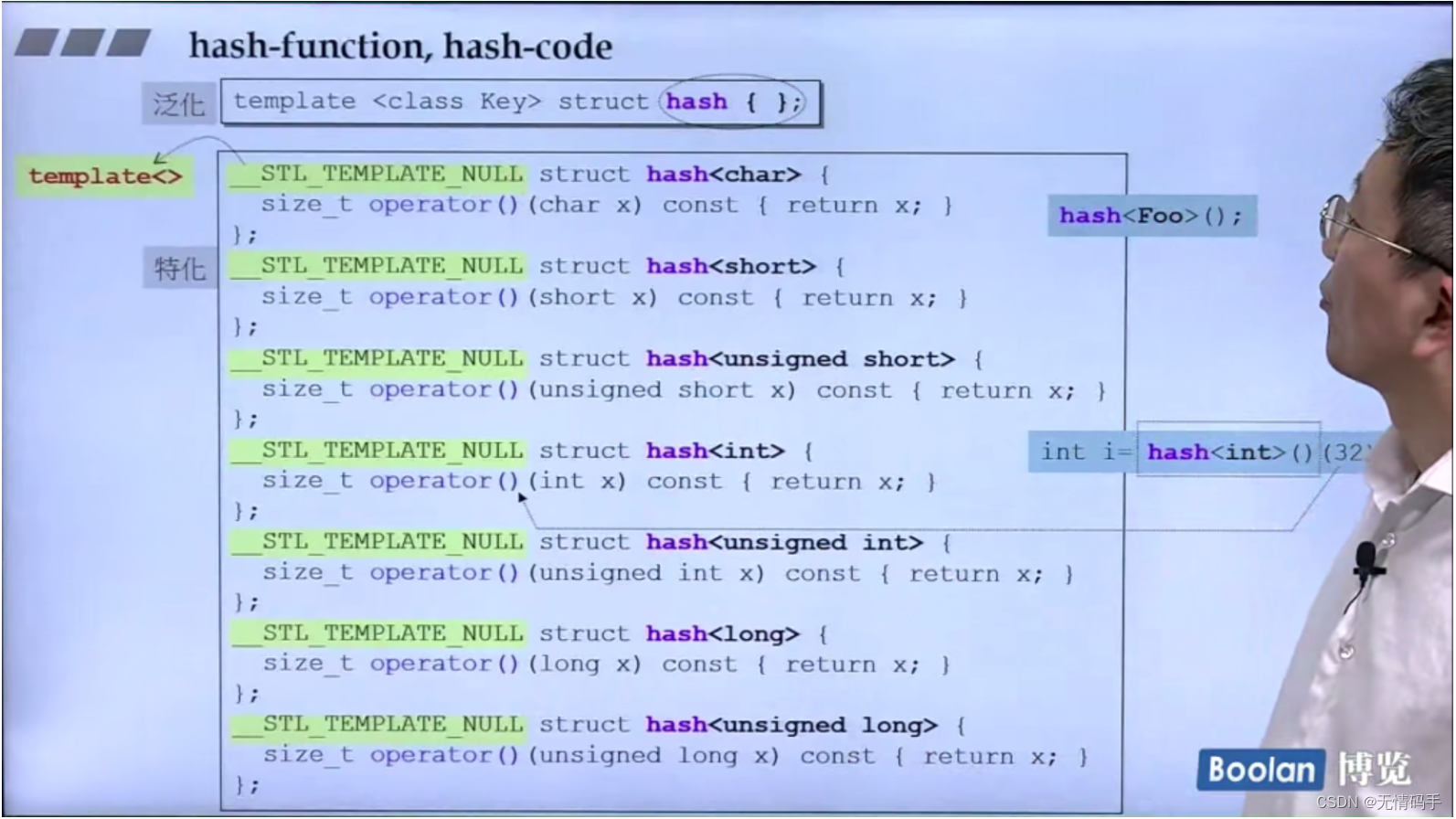
上面的hash-function 表示,如果是数值,就直接把他当编号
如果是字符串呢?
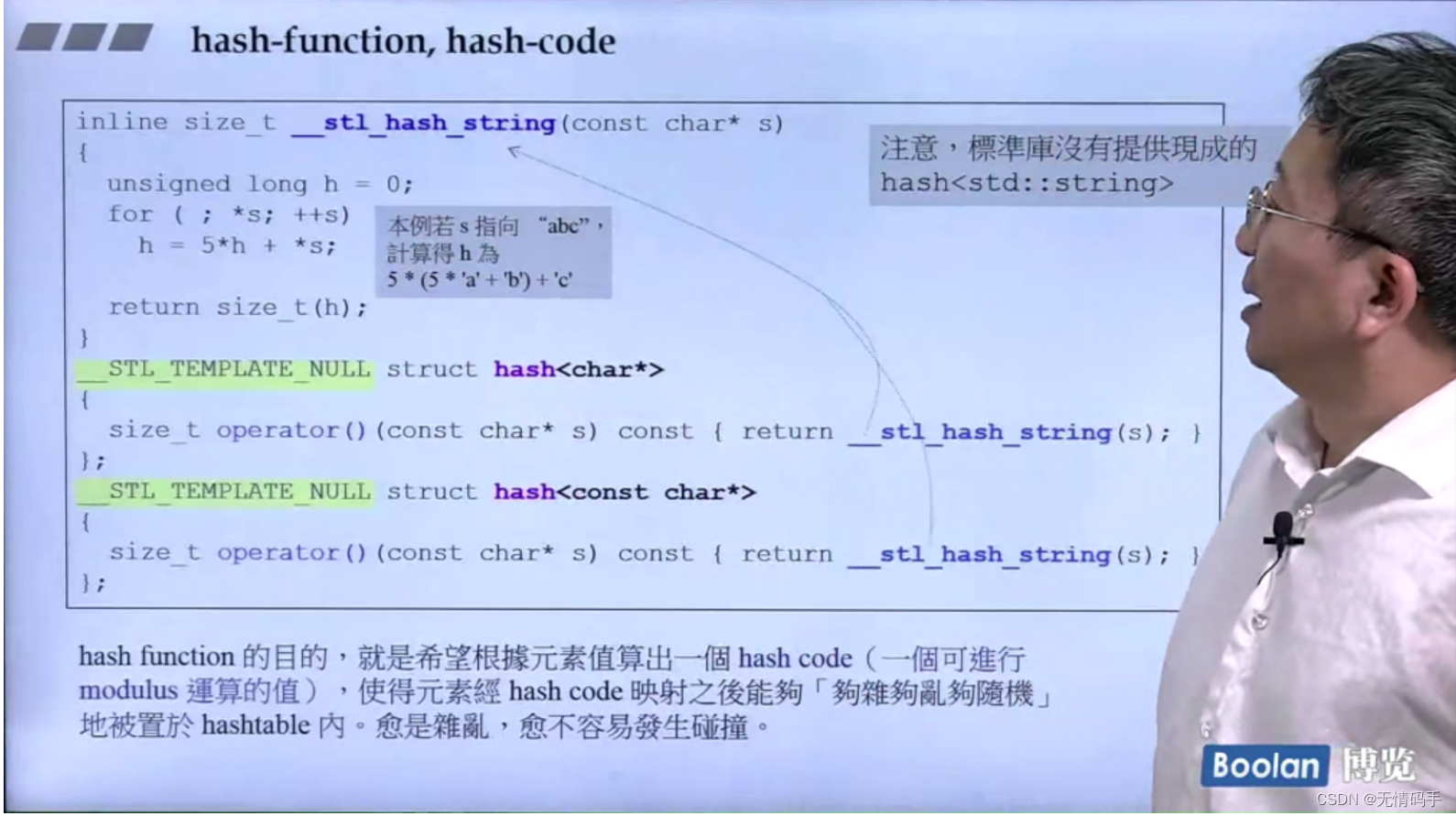
这里是对于C的字符串,标准库有提供hash<char*>
但是标准库没有提供对于C++的 hash<std::string >

最后通通都是调用了bkt_num_key
hash(key) % n;
25-hash_set、hash_map、hash_multiset、hash_multimap
26-unordered容器的概念
C++11改动了它们原来的名字

27-算法的形式
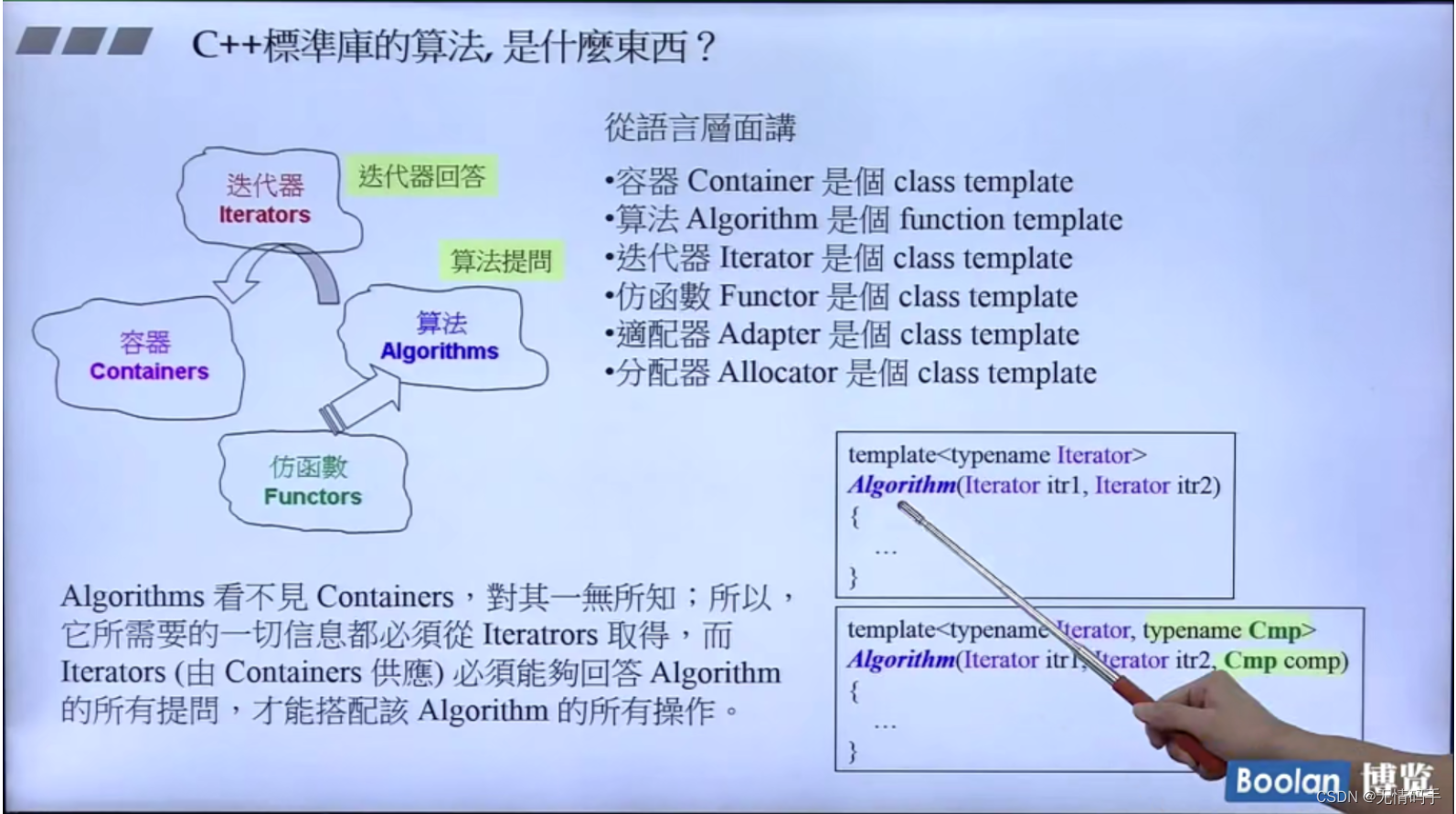
标准库里算法是function template 其他都是 class template
算法通过询问迭代器,得到它对应的回答,会针对不同的容器去实现更加高效的操作
信息一般就是指 迭代器怎么走
算法虽然看不到容器,但是可以通过迭代器看到容器的信息
28-迭代器的分类
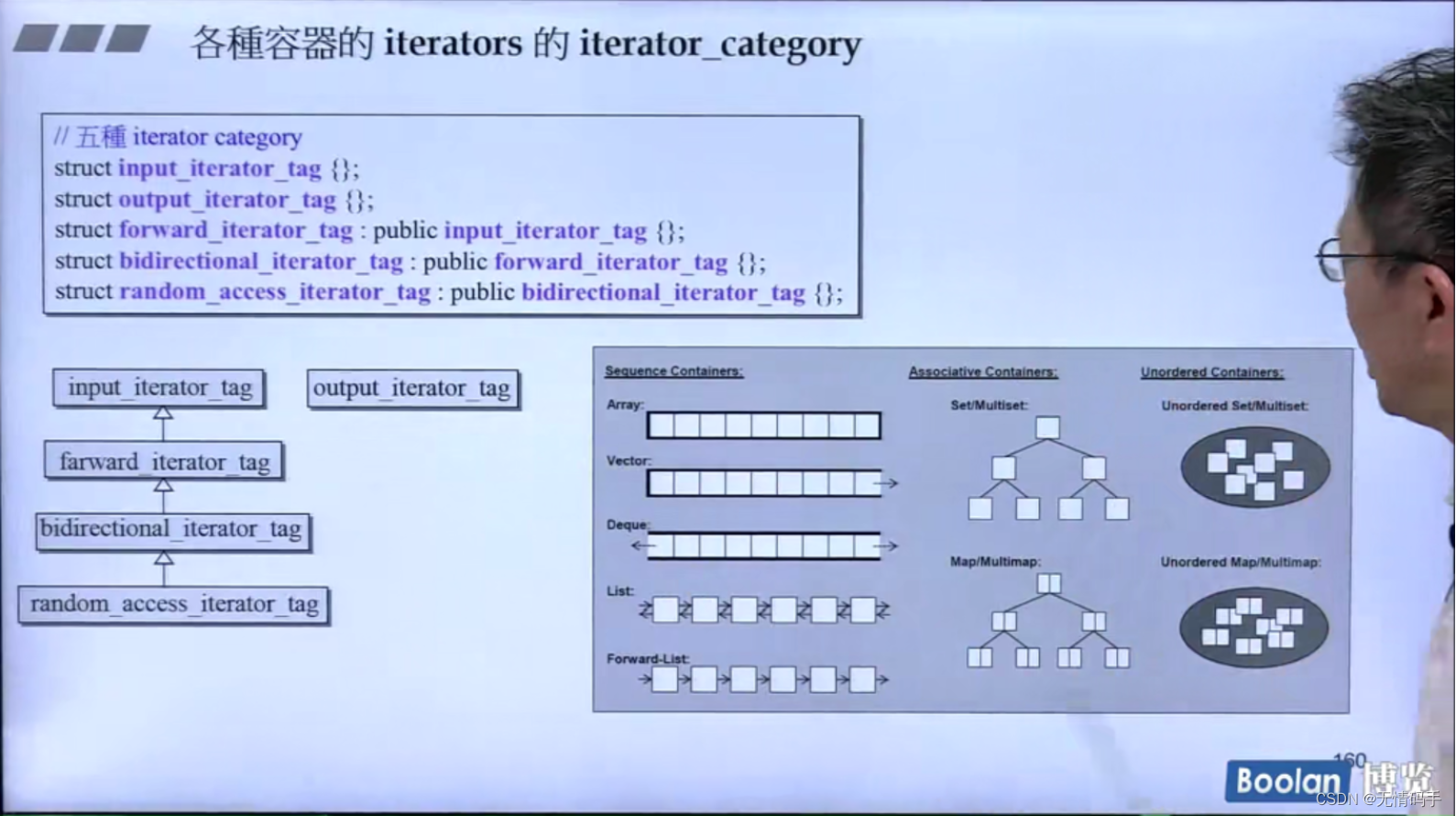
Array vector deque (假连续) 可以跳 它是 random_access_iterator_tag
双向链表 它可以++、-- 但是不能跳 所以它是 bidirectional_iterator_tag
单向链表 只能单向 它是forward_iterator_tag
红黑树 它也是双向的 所以 set/Multiset、map/multimap 是bidiretional_iterator_tag
Unordered set / Multiset
Unordered map / Multimap
要根据他里面链表是单向的还是双向的去决定他是 forward_iterator_tag 还是 bidirectional_iterator_tag
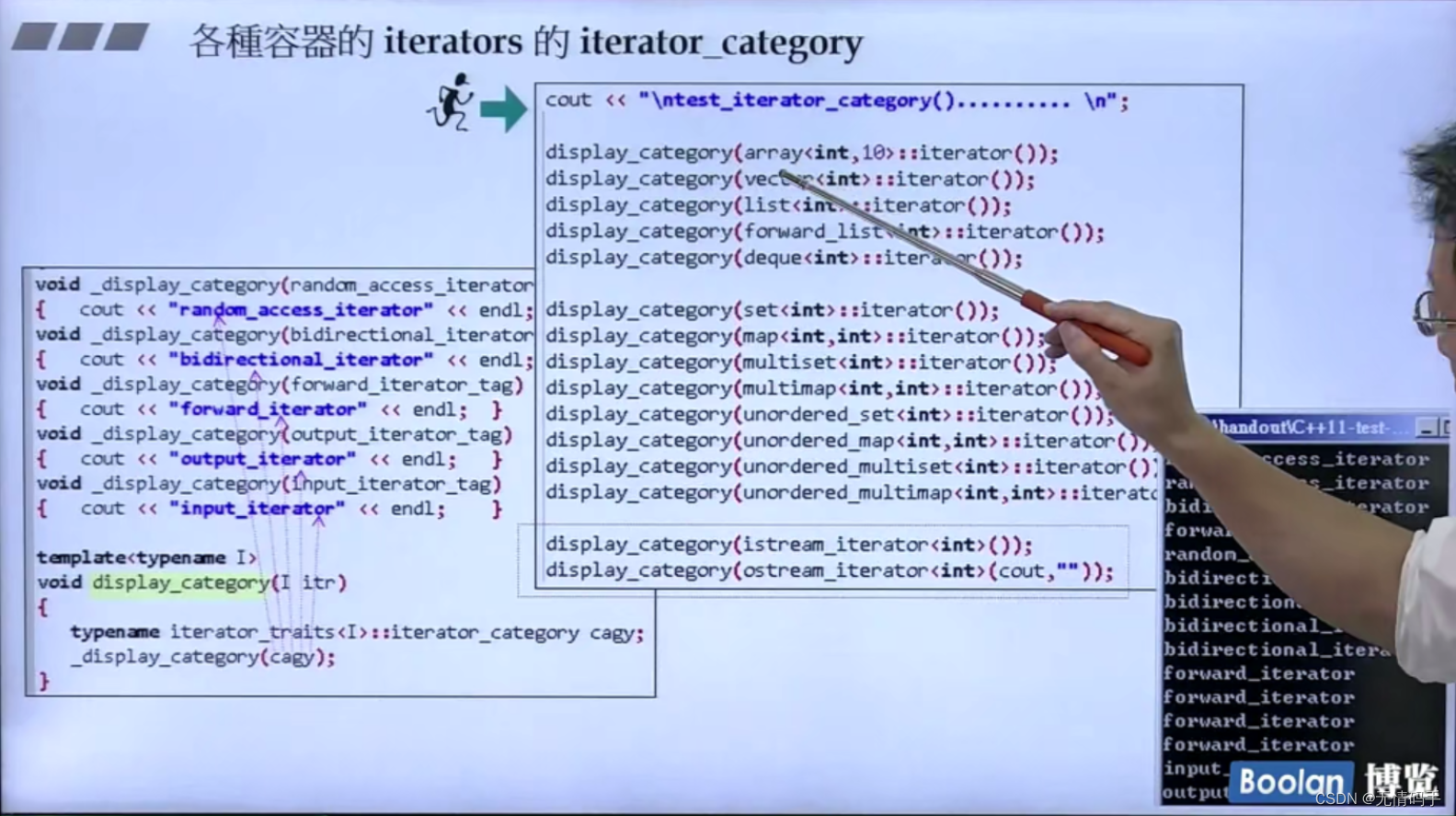
istream_iterator< int >() -> input_iterator_tag
ostream_iterator< int>(cout, “”) -> output_iterator_tag
引入 typeid

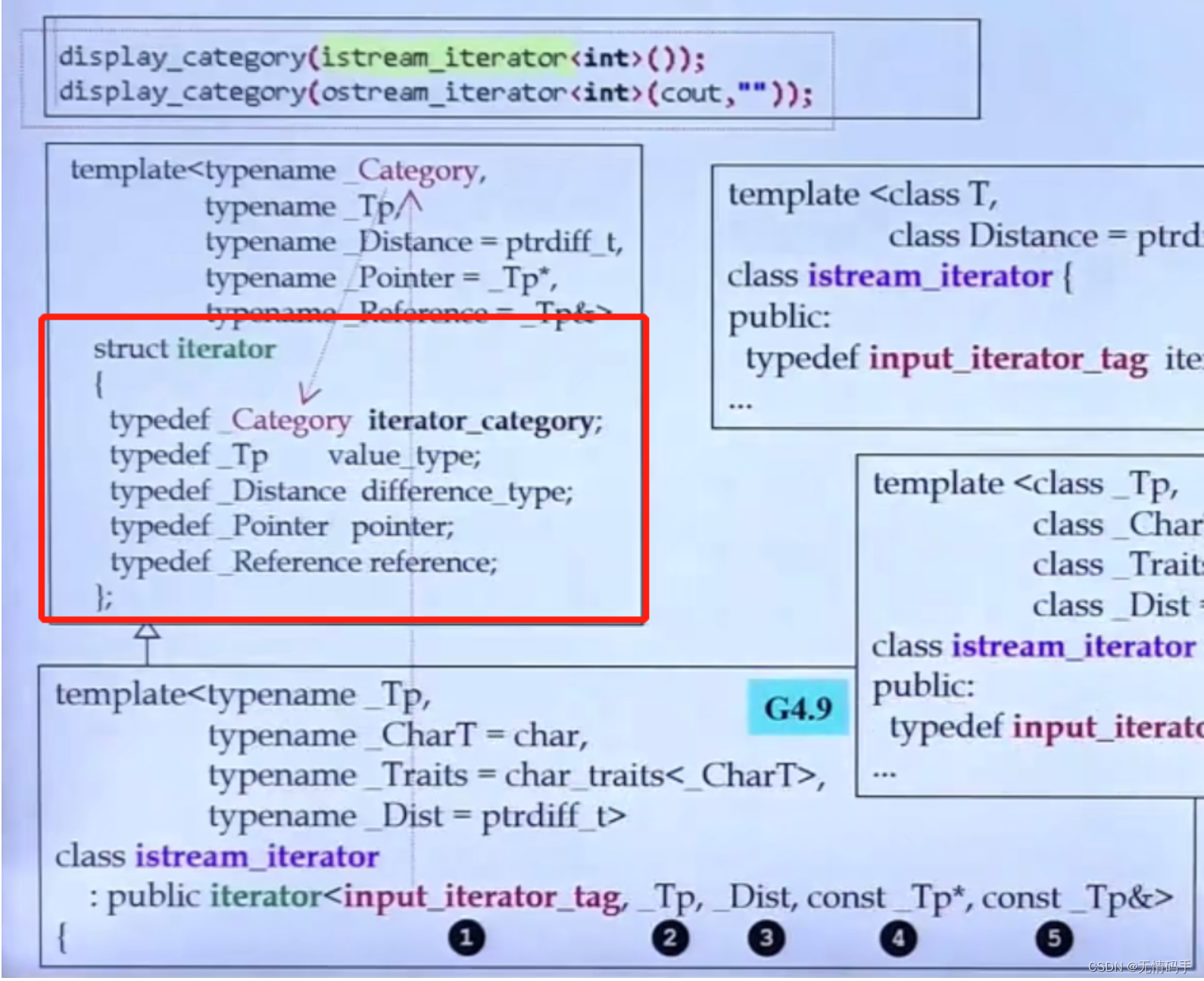
下面的子类继承了父类,也就继承了父类定义的typedef
28-迭代器分类对算法的影响
算法本身是一个主函数,里面又根据不同的分类,调用不同的函数
如果它是random_access_iterator_tag 就直接末尾-起始
如果它是input_iterator_tag 就得一个一个的加
这一页的category是直接丢给traits去问的 注意需要用category创建临时对象才能传入那个cate
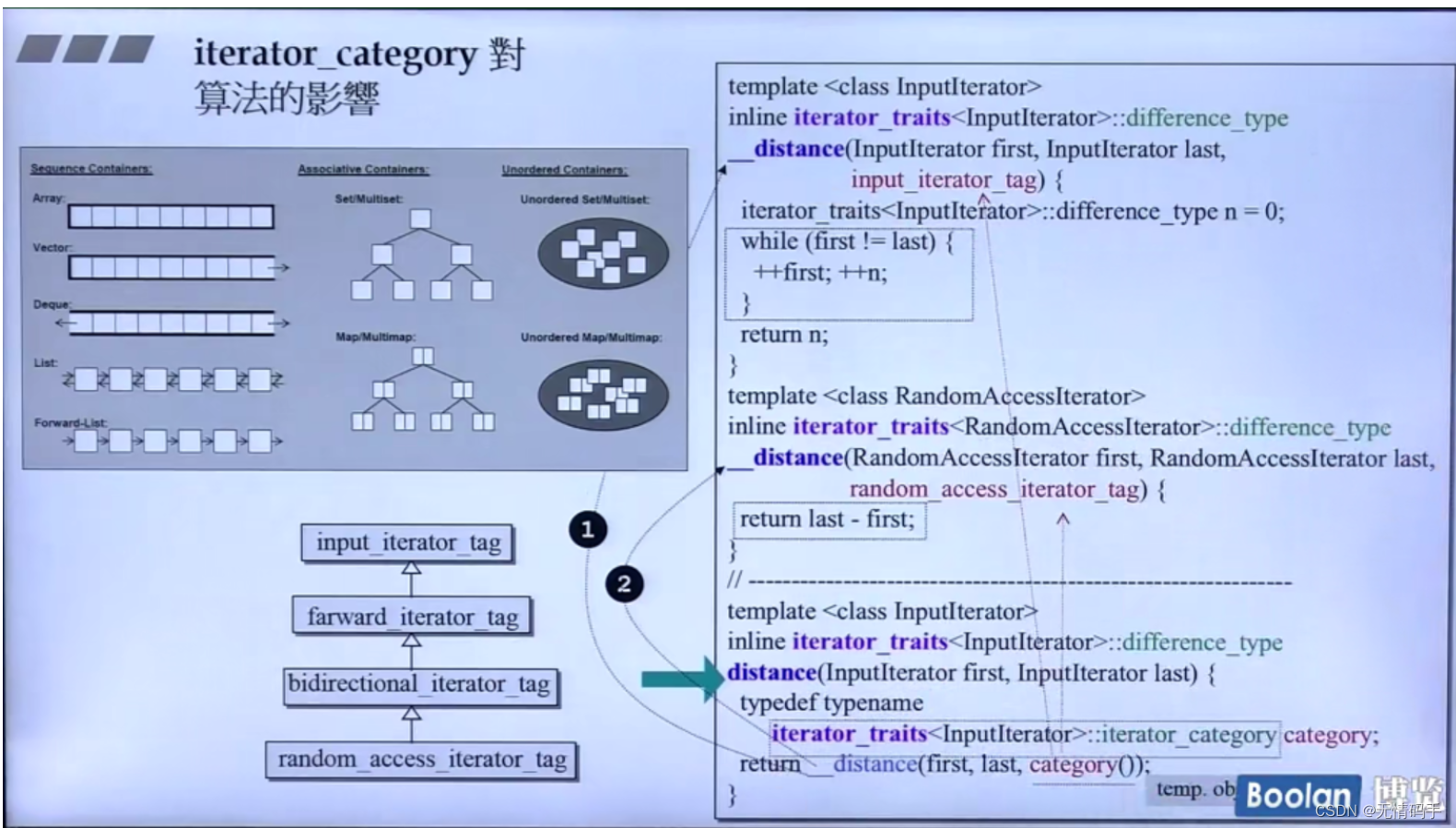
这里的category是通过一个新写的小型的函数去问得到的
注意需要用category创建临时对象才能传入那个cate
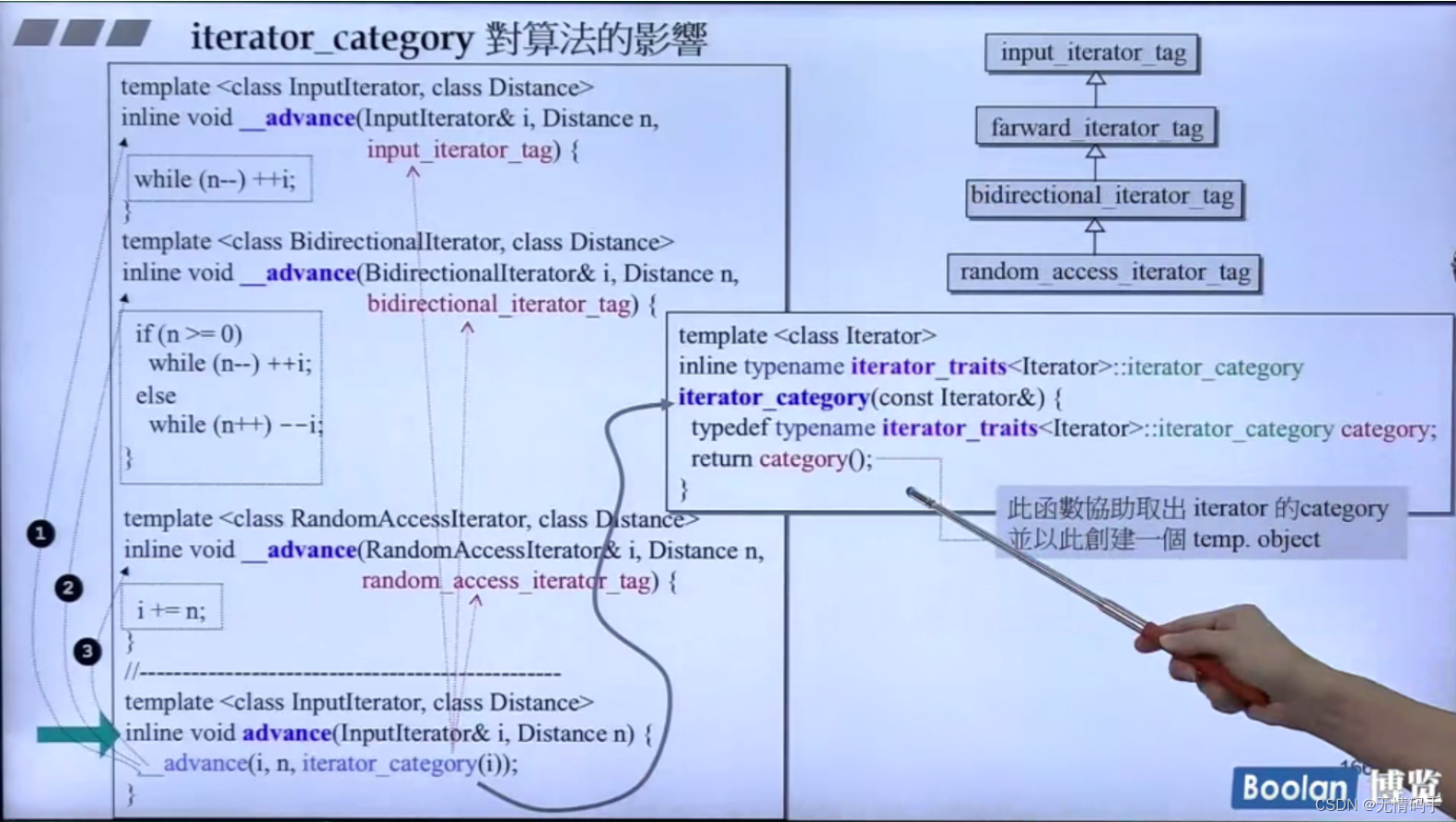
如果问出的是 farward _iterator_tag 如果没又它自己的这个类,那就会落到input_iterator_tag
因为继承代表:is a
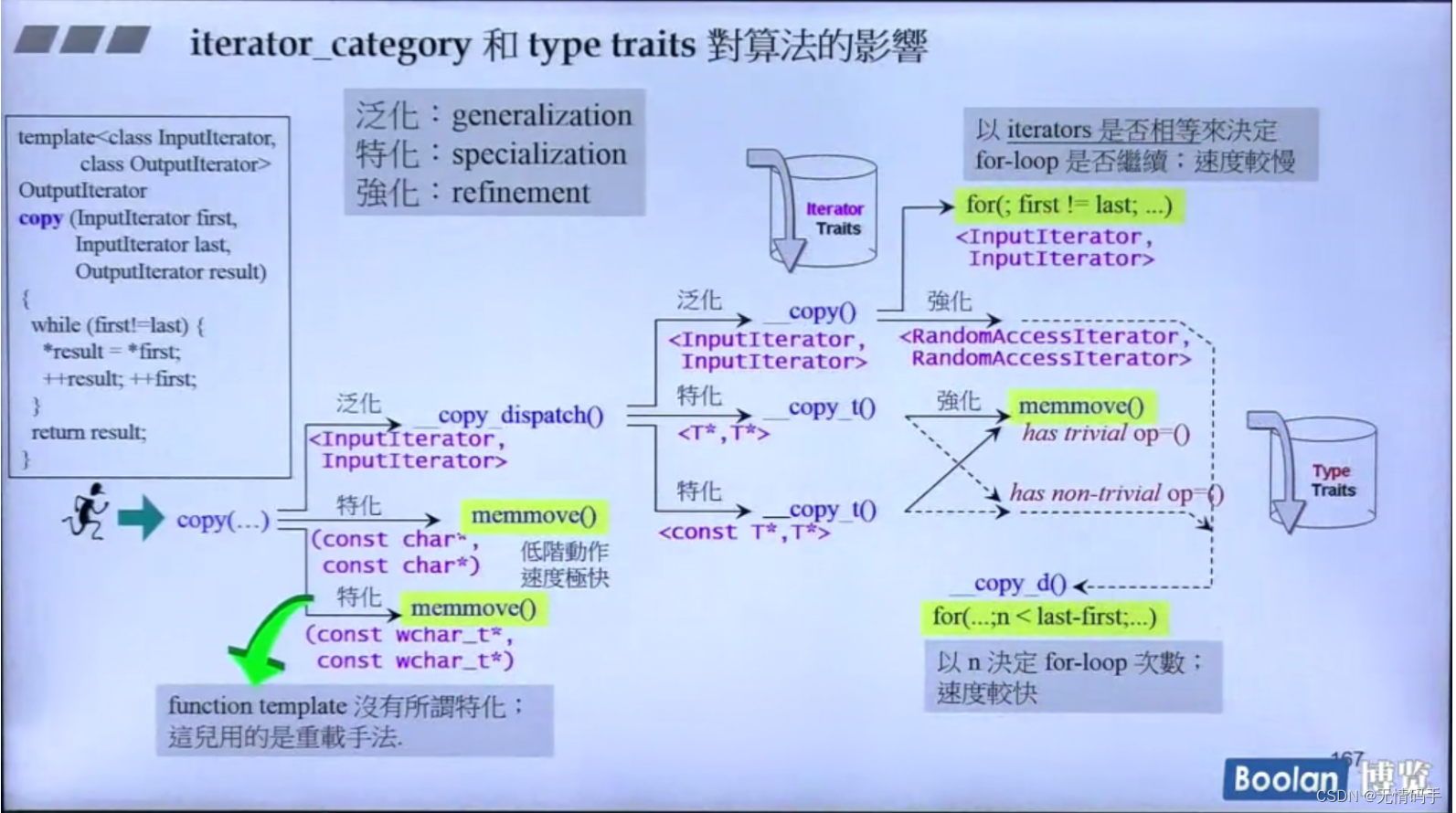
copy 是会发生一层一层的判断的:
copy里一直在做检查,检查它所收到的迭代器是不是特别属于某一种类型,而决定它的动作
进来后:
- 如果是 const char*/ const wchar_t* 直接 调用memmove()
- 不是那两种,那就是上面那一种了
进了_copy_dispatch 特别地看它是不是为指针类型?
-
如果不是指针:
-
不是Random:
for(; first != last; …)
那一部分,从来源端一个一个copy到目的端,copy的过程会发生拷贝构造
-
是Random
如果是RandomAccessIterator的话,forloop判断的条件不一样,它会比较快
-
-
对于指针来说:
- 如果它是trivial op=() 不重要的拷贝赋值,那就调用memmove()
- 如果它是 non-trivial op=() 重要的拷贝赋值 那就每个都要调用拷贝赋值
(traits会来决定说它的拷贝赋值到底做不做)
复数类:
它里面只有实部虚部且都不是指针,它需要写析构函数吗?需要拷贝构造吗?需要拷贝赋值吗?
答案是不需要(编译器会给默认的,不重要的,因为它只是做默认的事情)
如果在类中没有显式的声明一个拷贝构造函数,那么,编译器会私下里为你制定一个函数来进行对象之间的位拷贝(bitwise copy)。这个隐含的拷贝构造函数简单的关联了所有的类成员。许多作者都会提及这个默认的拷贝构造函数。注意到这个隐式的拷贝构造函数和显式声明的拷贝构造函数的不同在于对于成员的关联方式。显式声明的拷贝构造函数关联的只是被实例化的类成员的缺省构造函数除非另外一个构造函数在类初始化或者在构造列表的时候被调用。
我们已经会用构造函数初始化对象,那么我们能不能象简单变量的初始化一样,直接用一个对象来初始化另一个对象呢?答案是肯定的。我们以前面定义的Point类为例:
Point pt1(15, 25);
Point pt2 = pt1;
后一个语句也可以写成:
Point pt2( pt1);
它是用pt1初始化pt2,此时,pt2各个成员的值与pt1各个成员的值相同,也就是说,pt1各个成员的值被复制到pt2相应的成员当中。在这个初始化过程当中,实际上调用了一个复制构造函数。当我们没有显式定义一个复制构造函数时,编译器会隐式定义一个缺省的复制构造函数,它是一个内联的、公有的成员,它具有下面的原型形式:
Point:: Point (const Point &);
可见,复制构造函数与构造函数的不同之处在于形参,前者的形参是Point对象的引用,其功能是将一个对象的每一个成员复制到另一个对象对应的成员当中。
虽然没有必要,我们也可以为Point类显式定义一个复制构造函数:
Point:: Point (const Point &pt)
{
xVal=pt. xVal;
yVal=pt. yVal;
}
如果一个类中有指针成员,使用缺省的复制构造函数初始化对象就会出现问题。为了说明存在的问题,我们假定对象A与对象B是相同的类,有一个指针成员,指向对象C。当用对象B初始化对象A时,缺省的复制构造函数将B中每一个成员的值复制到A的对应的成员当中,但并没有复制对象C。也就是说,对象A和对象B中的指针成员均指向对象C
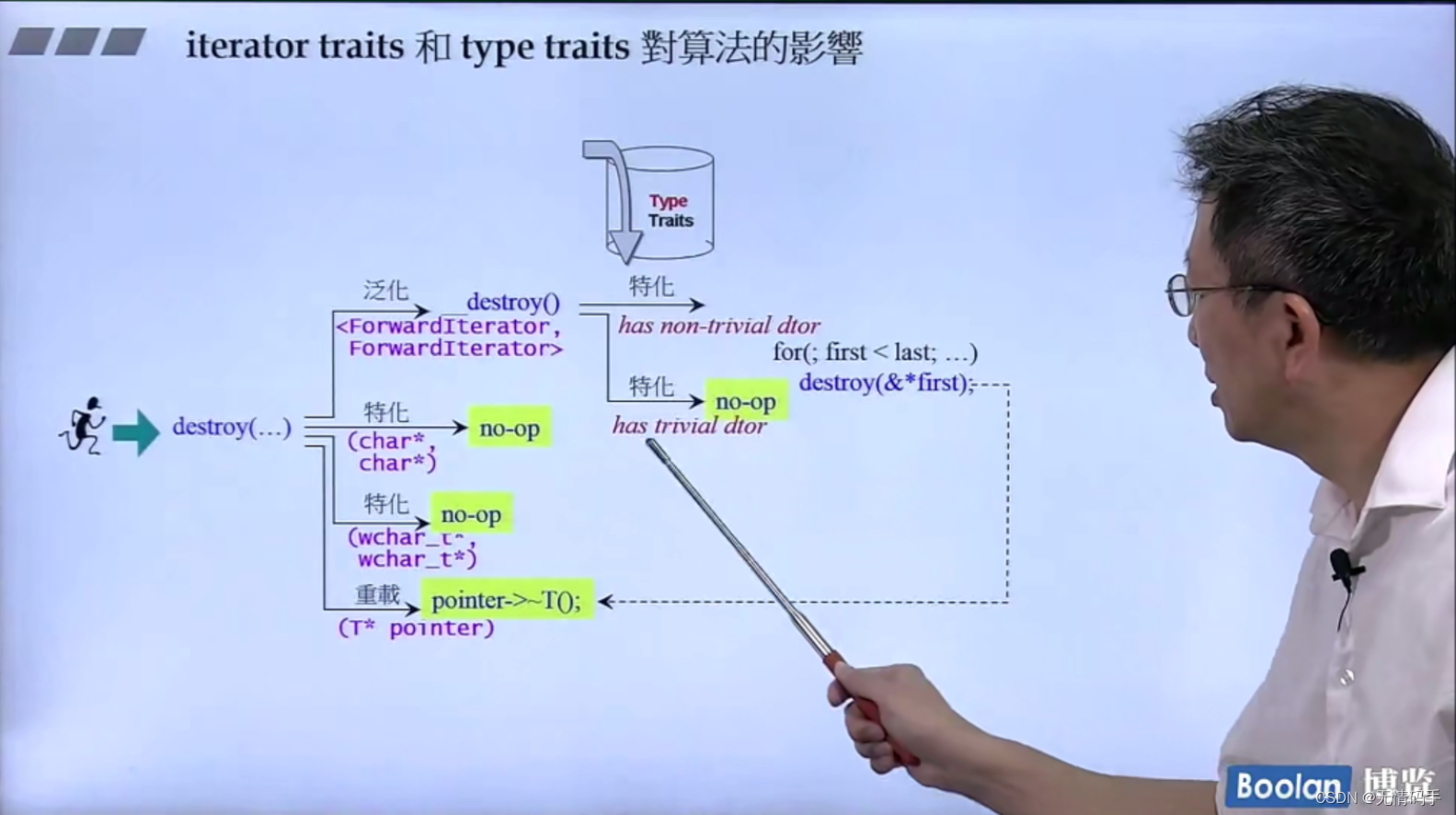
析构函数不重要,那就不归我管了,不调用了。释放内存是这个函数之后才发生的事
算法的效率和他能不能判断出迭代器的分类是有关系的
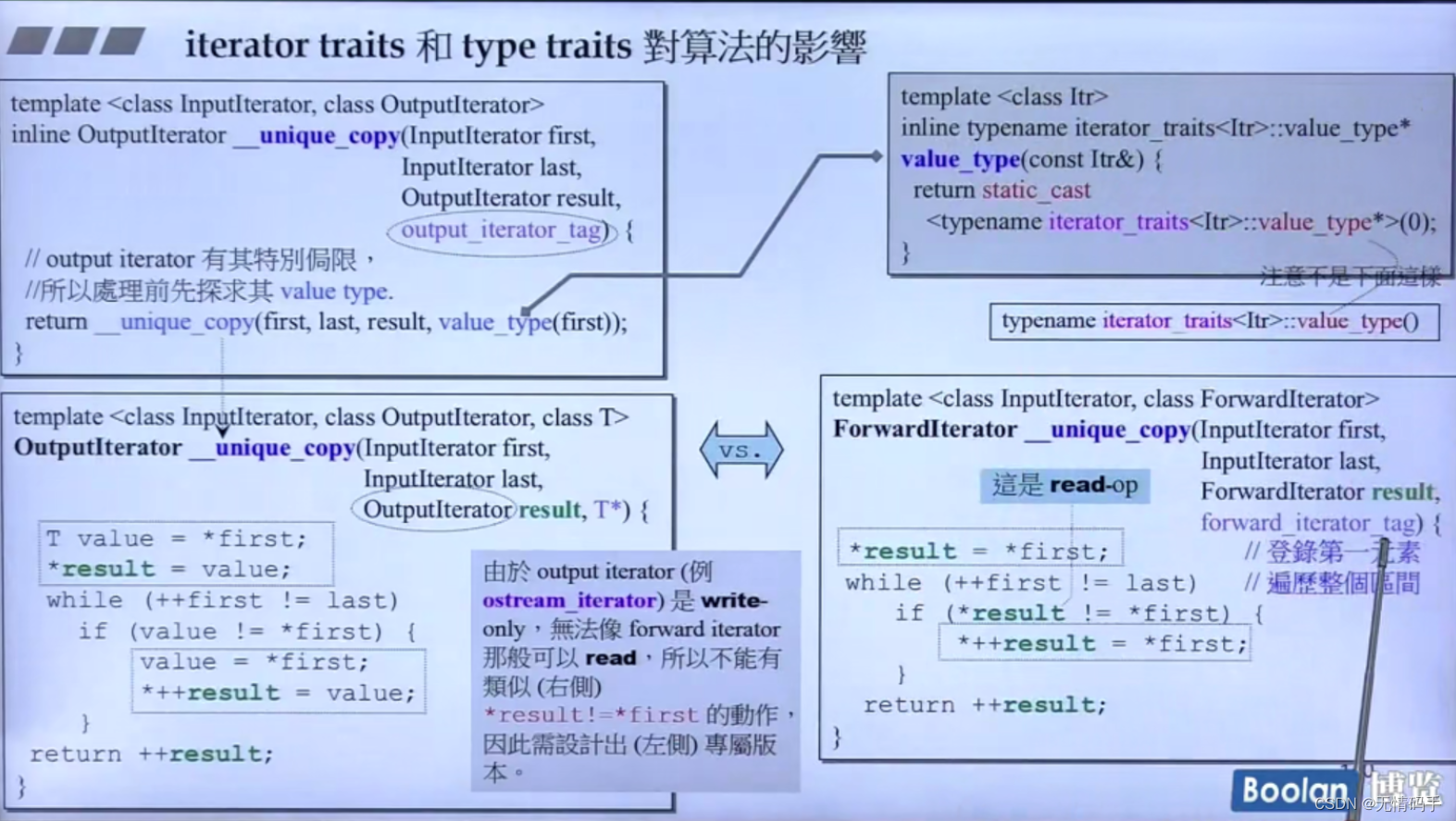

暗示!
例如:
-
sort 要接收的是 RandomAccessIterator,如果不是,其实也可以接受,但是真正到了要做乘除法的那一行,就会出错
-
distance 暗示要收到 InputIterator
-
find 要收 InputIterator
-
rotate 要收 ForwardIterator
-
reverse 要收 bidirectional
30-算法源代码分析
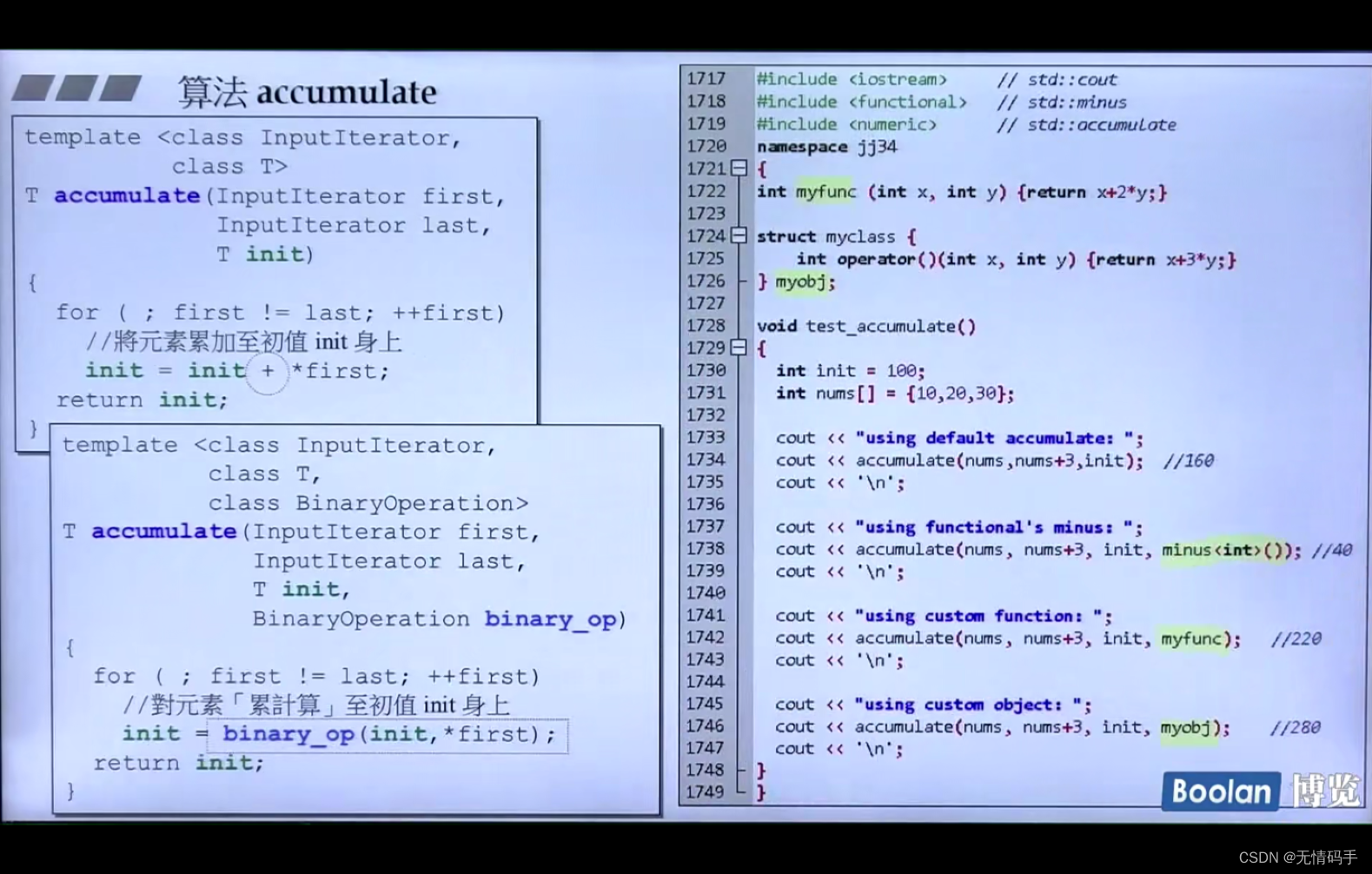
上面是累加,下面是用了自己定义的函数并累积上去
minus< int >() 仿函数,是要不断地做减法
传进去的东西,只要能被小括号作用起来就行
用一般的函数/函数对象
//直接定义一个函数
int myfunc(int x, int y) {return x+2*y;}
//定义一个仿函数,重载小括号
struct myclass{
int operator()(int x, int y) {return x+3*y;}
}myobj;
//把myobj 这个对象传进去了
accumulate(nums, nums+3, init, myobj)
对容器中每个元素做指定的同一件事情:for-each
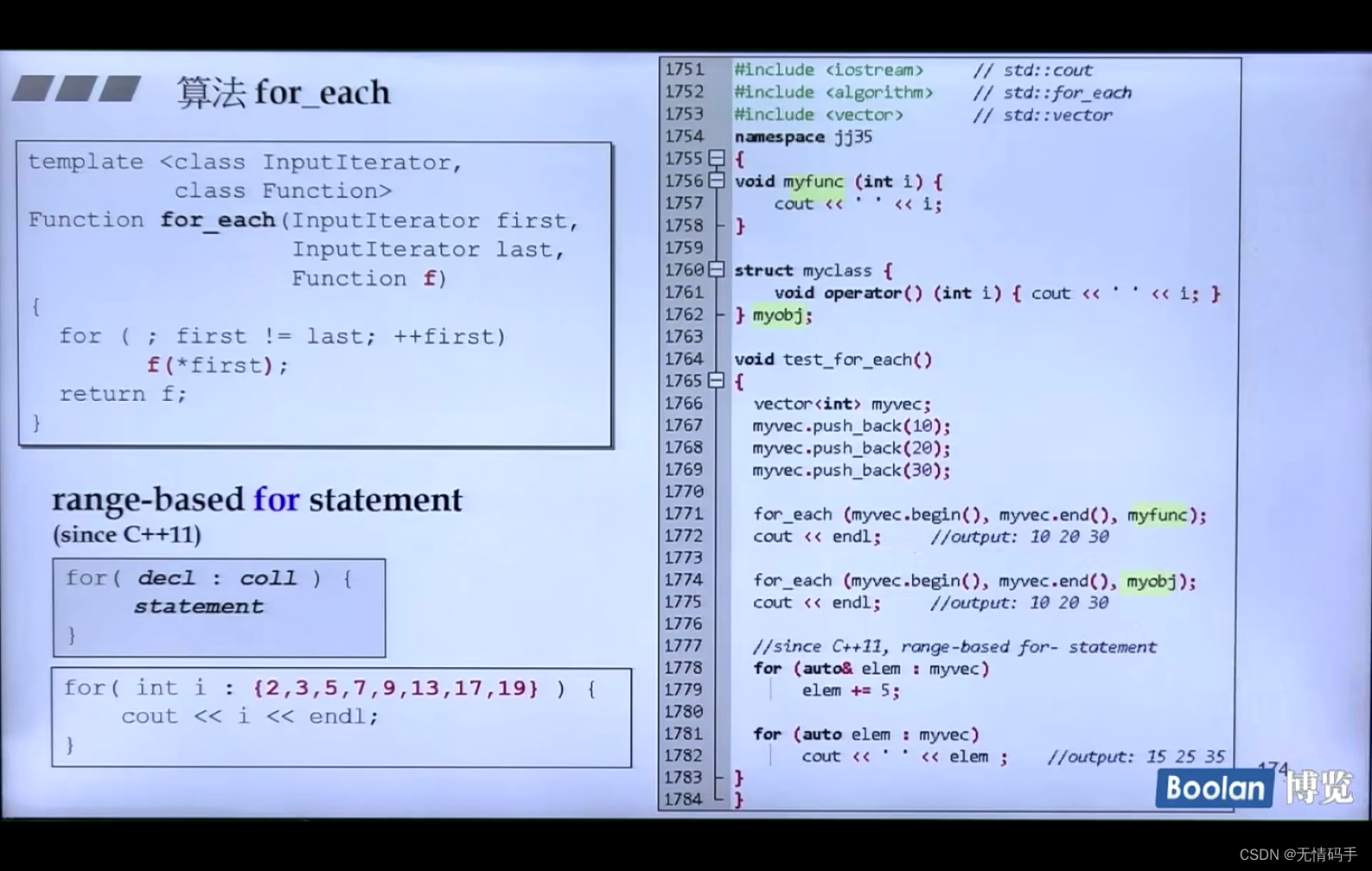
replace、replace_if、replace_copy
接受头尾两个迭代器并遍历,如果和旧值相同,就改为新值

Predicate 是返回一个判断式 返回真/假
replace_copy 等于old_value者都以new_value放至新区间,不符合者将原值放进新区间(注意这个是放到新区间里)
count、count_if
有没有等于value的?
有没有符合pred 的?

容器不带这个成员函数的话,就要用全局的。有的话用自己的版本

对于find() 这8个也有自己的成员函数,因为自己是有key的,所以用自己的方法是更快的
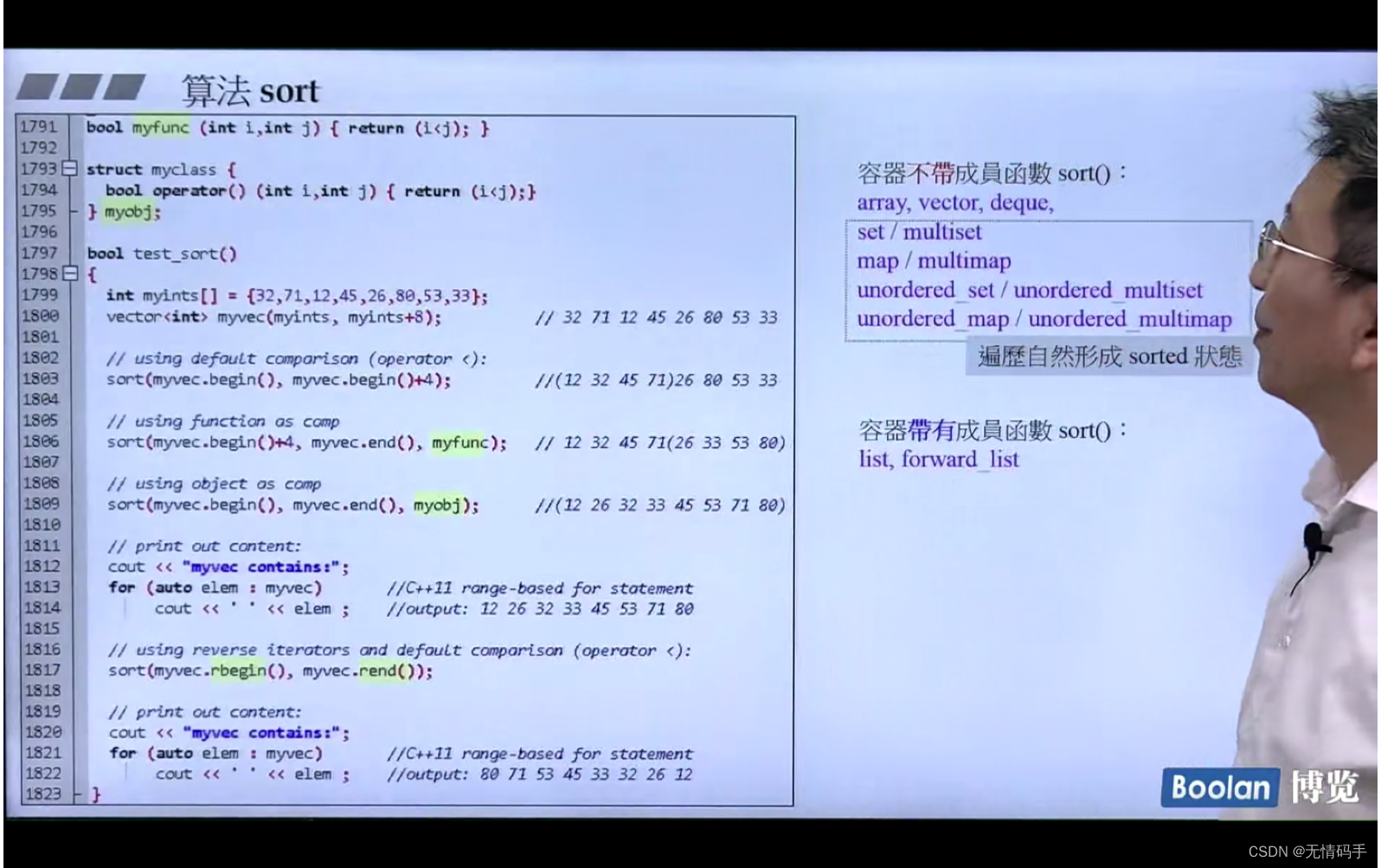
8个 set/map 遍历自然形成sort状态,所以无需sort(也确实不符合sort所需的迭代器的类型)
关联式容器本身已经排序了,不要再排序!
rbegin(), rend() 是逆向的 头和尾 reverse
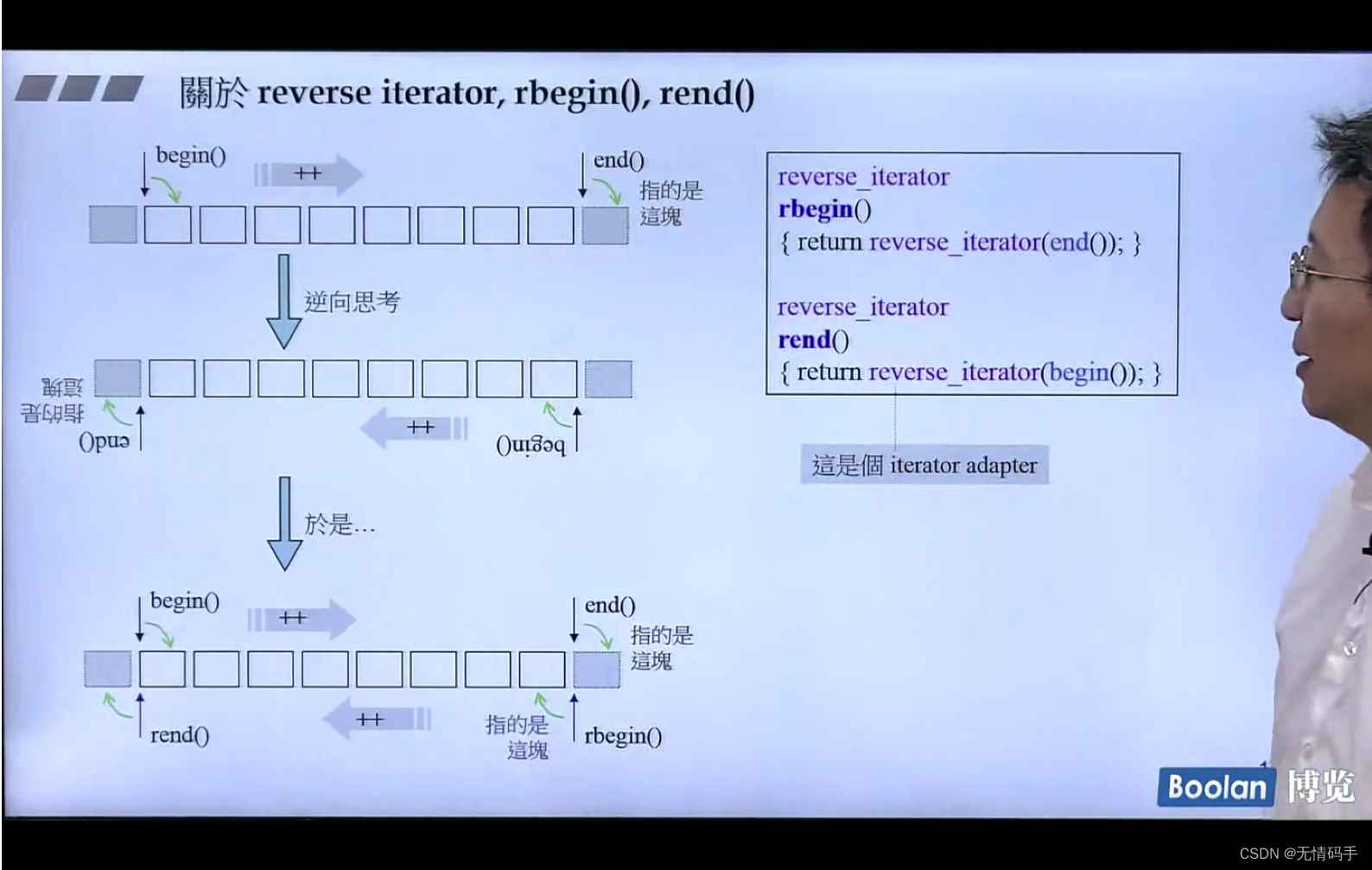
rbegin() 其实就是end()
rend() 其实对应begin()
他们的指针移动的方向也变了
但是需要用adapter再套换一下reverse_iterator
lower_bound() -> 20安插进去的最低点
upper_bound() -> 20安插进去的最高点
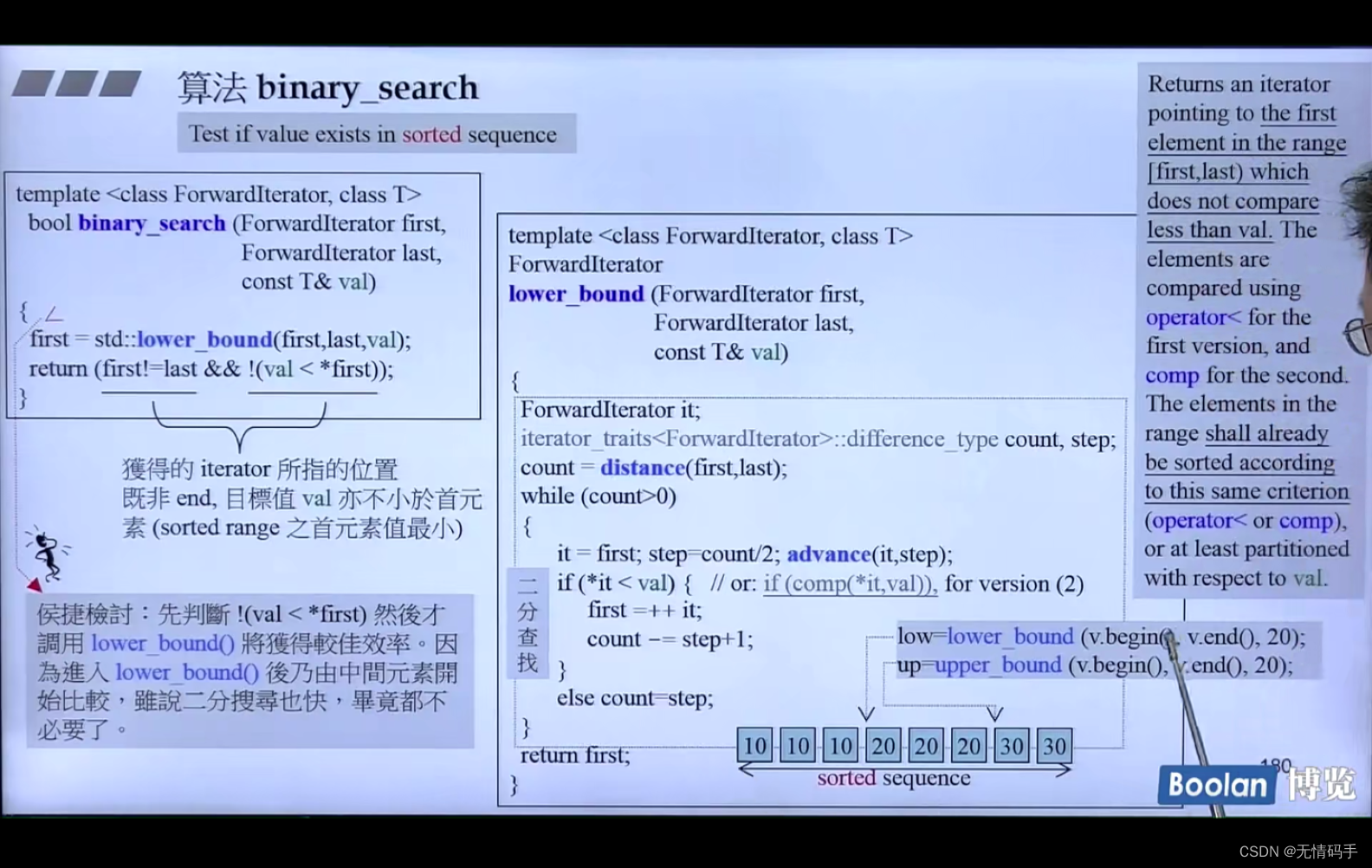
lower_bound 返回的是可安插的位置,如果返回的位置是end 说明是没有找到的
binary_search要的是真/假,看看这个元素究竟在不在里面
所以最后返回的是 first!=last && !(val < *first)
前半部分表示这个位置不在最后 后面表示 且这个位置的值是 >= 要找的这个值
*侯捷讨论说,应该进去函数之后先判断是否 val < first 如果是的话就不用找了,否则白白浪费很多时间
31-仿函数和函数对象
为什么要特意的把 + - * / < > =再定义成仿函数?而不是直接用?
因为还要把他们以模版的形式传到别的function里再去调用

less仿函数,是在比较x和y的大小
那在传到sort函数里的时候,应该是
sort(a.begin(), a.end(), less()); 注意需要把仿函数的对象创建出来
template<T>
struct less : public binary_function<T, T, bool>
{
bool operator()(const T& x, const T& y) const
{
return x<y;
}
}
为什么标准库提供的仿函数都有继承关系?
binary_funtion<T, T, bool>?
没有继承,就没有融入STL体系结构里
下面这两个模版类里,只是定义了typedef,并没有定义实质的数据/方法,他们的大小都是1
unary_function是指只有一个操作数的、binary_function是指有两个操作数的

less 这里继承没有增加大小 ,没有带来额外开销,但同时给它带来了三个typedef
如果你要被Adapter来改造的话,Adapter可能会问你这几个问题
Adapter 问问题 functor 要回答问题
所以仿函数要可适配 adaptable 的条件是:需要继承!
没有继承,就没有可以被改造的机会
32-Adapter (适配器) 转换器
接口改一下,三个参数改成两个参数
函数名称改一下
…
要改造什么,就把它叫成什么:
- Container Adapters
- Functor Adapters
- Iterator Adapters
A 要取用 B 的功能:
- A 继承了 B
- A 内含了 B
容器适配器:stack、queue
他们都是内含容器deque、并且对他们的函数进行了改造,只放开了一部分
33-函数适配器 - binder2nd
bind2nd(less(), 40);
把比大小的第二个参数改为40
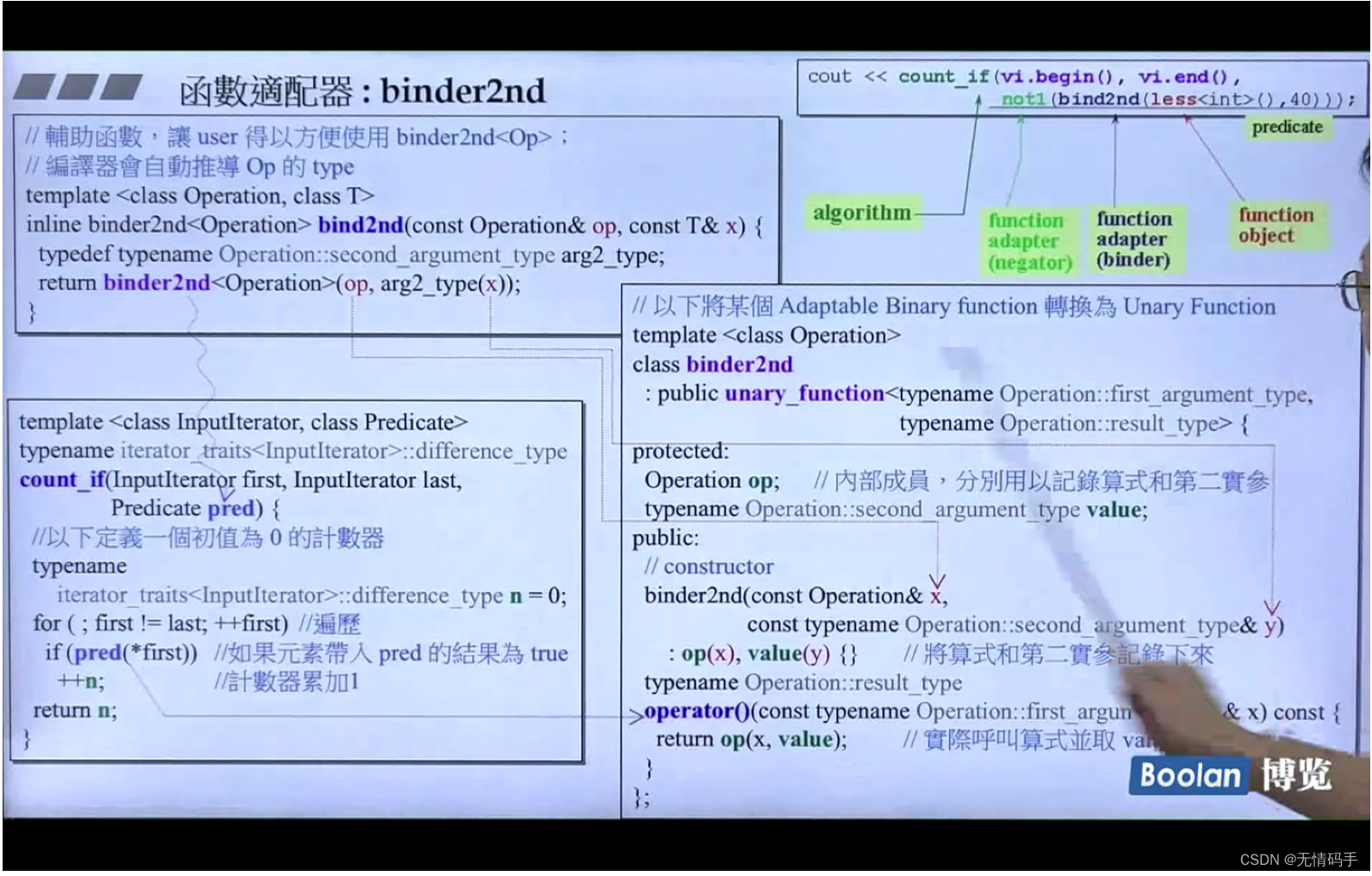
为什么这里是binder2nd 类?我们用的应该是bind2nd? 因为那个类过于复杂,我们再把它抽出来一层
这个binder2nd类 是unary_function 它真正调用operator() 时是直接收一种参数的
它的first_argument_type 是要接收的op的第一个参数的类型
它的返回类型是Operation::result_type
bind2nd 是辅助函数 辅助函数让这个Adapter functor变得对用户更简单
现在Adapter 修饰的是 functor ,所以它也要转变成一个functor 的样子,所以这里要重载小括号
给binder2nd 这个类(以辅助函数的形式实现)重载 () 因为后面还要以括号函数的形式调用它
重载的时候,需要扔一个对象进来,是first_argument_type 类型的
绑定是在operator() 重载这里面做到的,前面只是把它记下来
对象里一开始只是记录,在后面真正调的时候才真正重载
operator() 的返回值 也是通过 Operation::result_type 得知
这里的binder2nd 类 还继承了 unary_function 因为它给外界显示出,它直接收一个参数
我自己也是被代表做只有一个参数
整个过程中一直在 提问 回答
很长的名字前面,加一个 typename 在各个编译器里就肯定可以通过
bind2nd 已经过时 被取代为bind 但是用它还是可以的
34-not1

上一个binder2nd 是里面记了两个成员 一个Operation op 、一个value
这个not1里是记录一个
Predicate 就是整个被not1套着的函数
这个pred里的参数x 是Predicate::argument_type 也就是bind2nd返回对象的 argument_type 也就是被操作的那个数x,这个pred 就是 binder2nd 的那一整个对象
35-bind
std::bind 可以绑定:
- functions
- function objects
- member functions
- data members
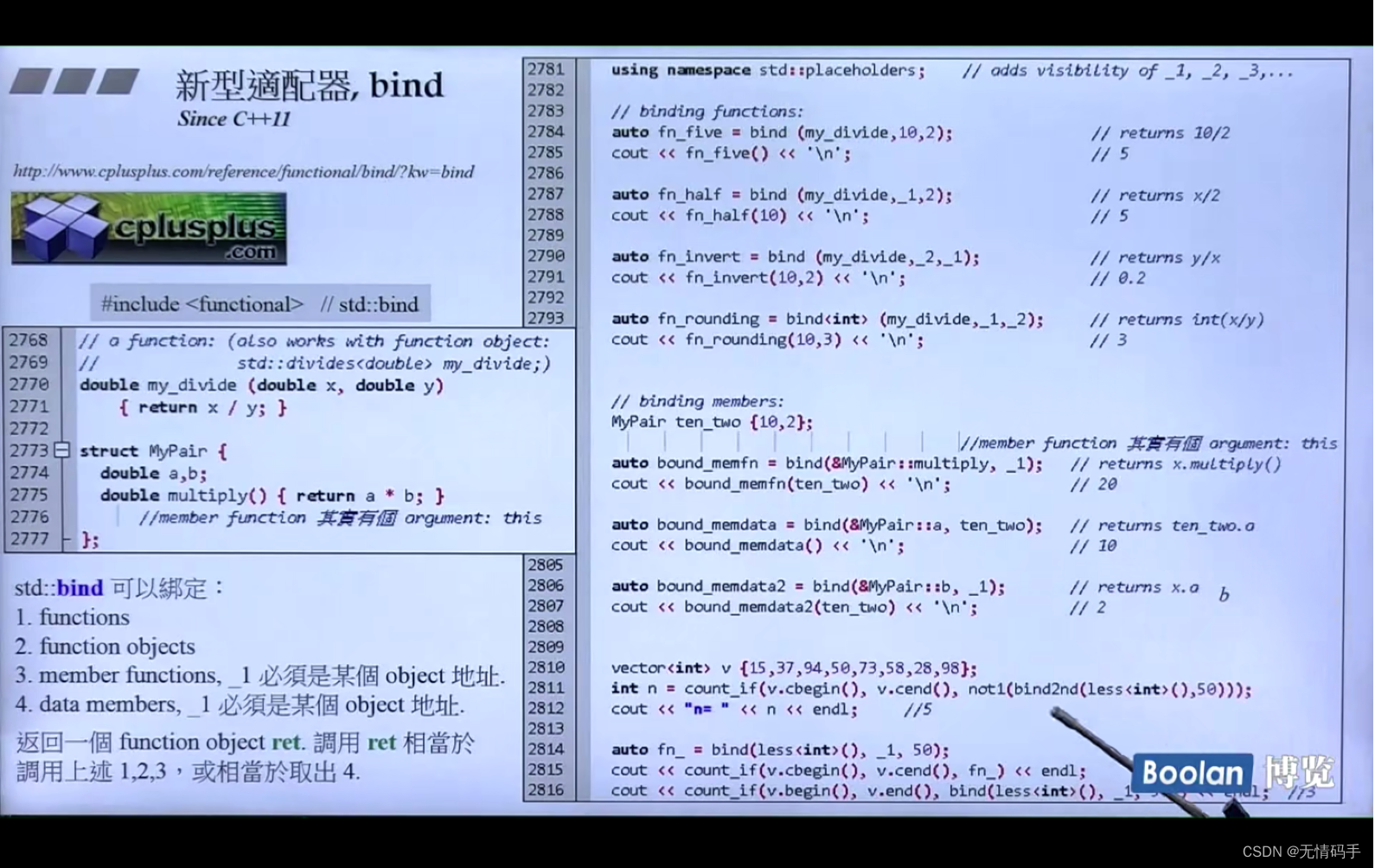
需要用:using namespace std::placeholders
_1 占位符 表示第一实参
_2 占位符 表示第二实参
bind< int> -> 这个int表示它的返回值,如果没有特别指定,返回值就是绑定的函数的返回值,图中显示为double
对于成员函数,其实它是有一个参数this的
Mypair ten_two {10,2};
auto bound_memfn = bind(&Mypair::multiply, _1);
//这里_1占位表示还没有绑定,后面再绑定的 ten_two,也可以像下面那样直接绑定
cout << bound_memfn(ten_two) << '\n';
auto bound_memdata = bind(&Mypair::a, ten_two);
cout << bound_memdata() << endl;
vector<int> v{15, 37, 94, 50, 73, 58, 28, 98};
int n = count_if(v.begin(), v.end(), not1(bind2nd(less<int>(), 50)));
//用bind怎么实现?
auto fn_ = bind(less<int>(), _1 , 50);
cout << count_if(v.begin(), v.end(), fn_) << endl;
//也可以写成
cout << count_if(v.begin(), v.end(), bind(less<int>(), _1, 50)) << endl;
36-reverse_iterator
reverse_iterator
rbegin()
{
return reverse_iterator(end());
}
reverse_iterator
rend()
{
return reverse_iterator(begin());
}
正向是往右边取,逆向是往左边取

Adapter 其实就是把要改造的东西记起来,然后再去看是要怎样改造它
逆向迭代器取值的时候是正向迭代器退一格再取值
前进变成后退、后退再改成前进
37-inserter
Adapter一般都会带一个辅助函数便于操作
template<class Container, class iterator>
inline insert_iterator<Container>
inserter(Cotainer& x, Iterator i)
{
typedef typename Container::iterator iter;
return insert_iterator<Container>(&x, iter(i);
}
借由操作符重载去完成copy
operator=里面调用容器的insert 是做了安插的动作,而不是给谁赋值了
iterator 永远随着 target 贴身移动
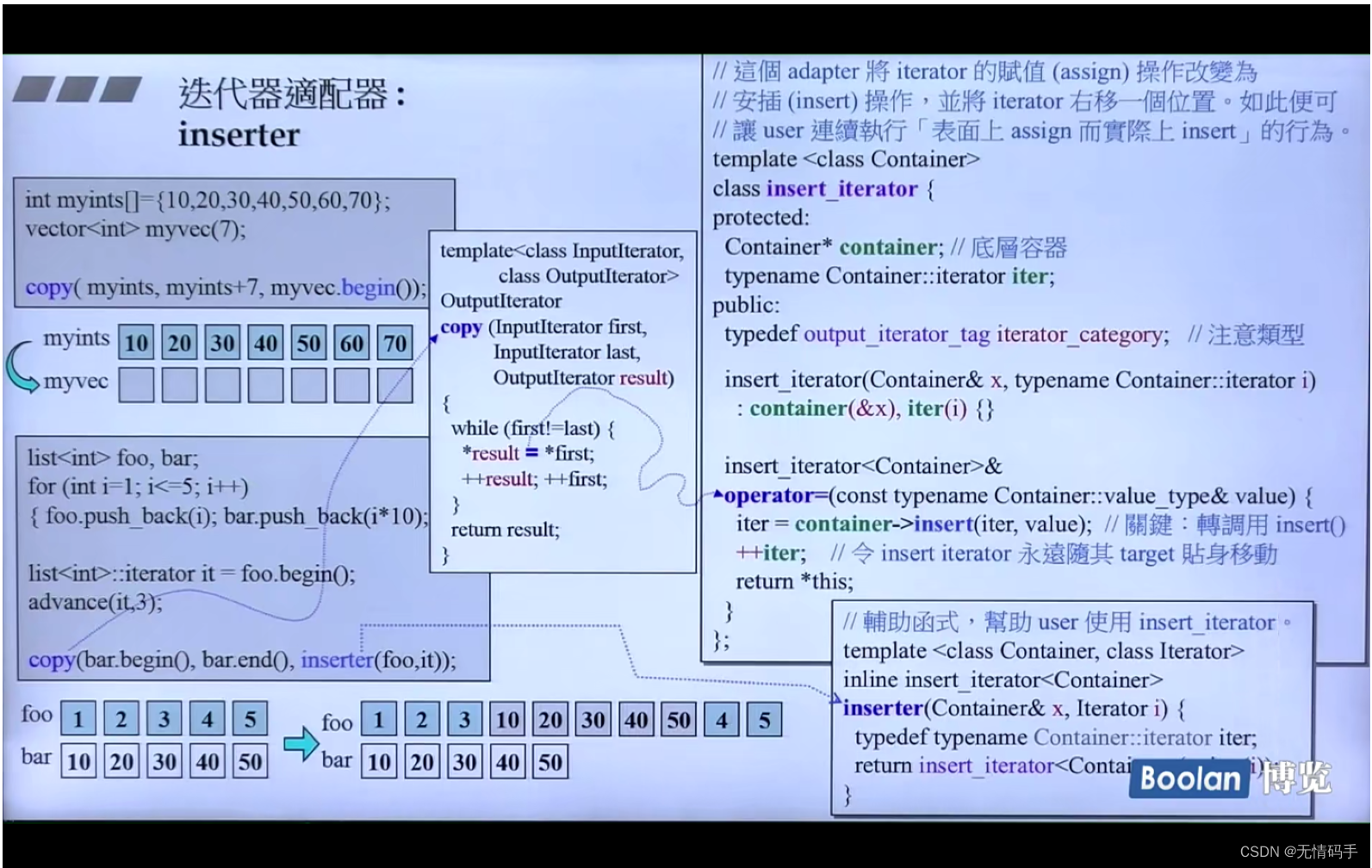
result 是一个 insert_iterator
insert_iterator里有一个 Container* 和一个 Container::iterator
由inserter这个函数来返回insert_iterator这个对象
advance(it, 3); 让iterator 往后走了三步
38-ostream_iterator
迭代器怎么绑定到你的屏幕上的?
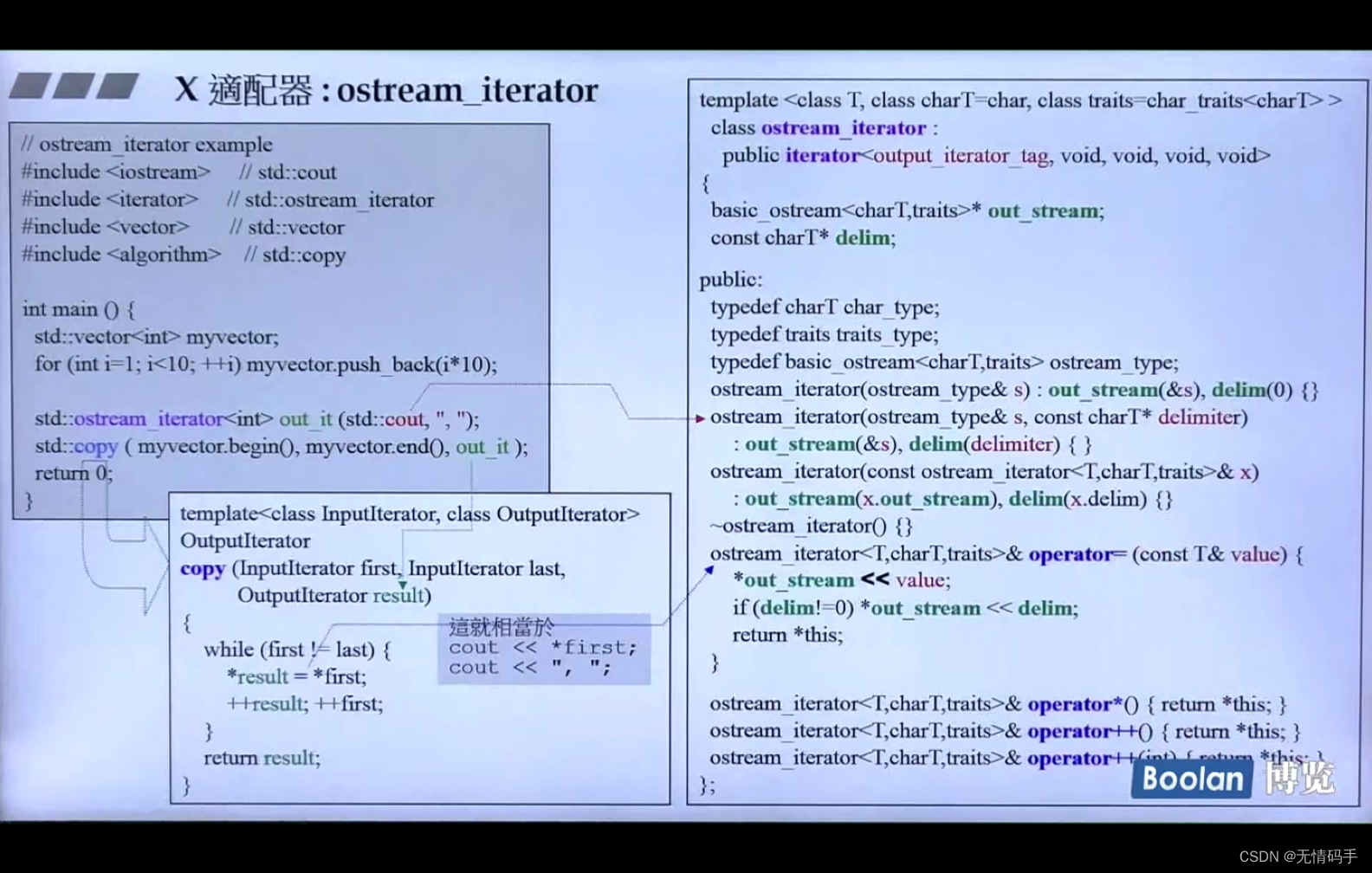
*作用在result上面,返回的还是本身,相当于没有作用
注意绿色的地方
把value << 丢给了 *out_stream 也就是cout
后面会把固定的分割符号也丢到 *out_stream上
X_适配器 :它存的是谁,就是什么的适配器
存的可以是一个函数、可以是一个容器(比如stack、或者Adapter里放一个容器指针和迭代器 ) 、迭代器(reverse_iterator)、也可以是i/ostream(称作X)…
39-istream_iterator
eos是标兵符号,结束符号
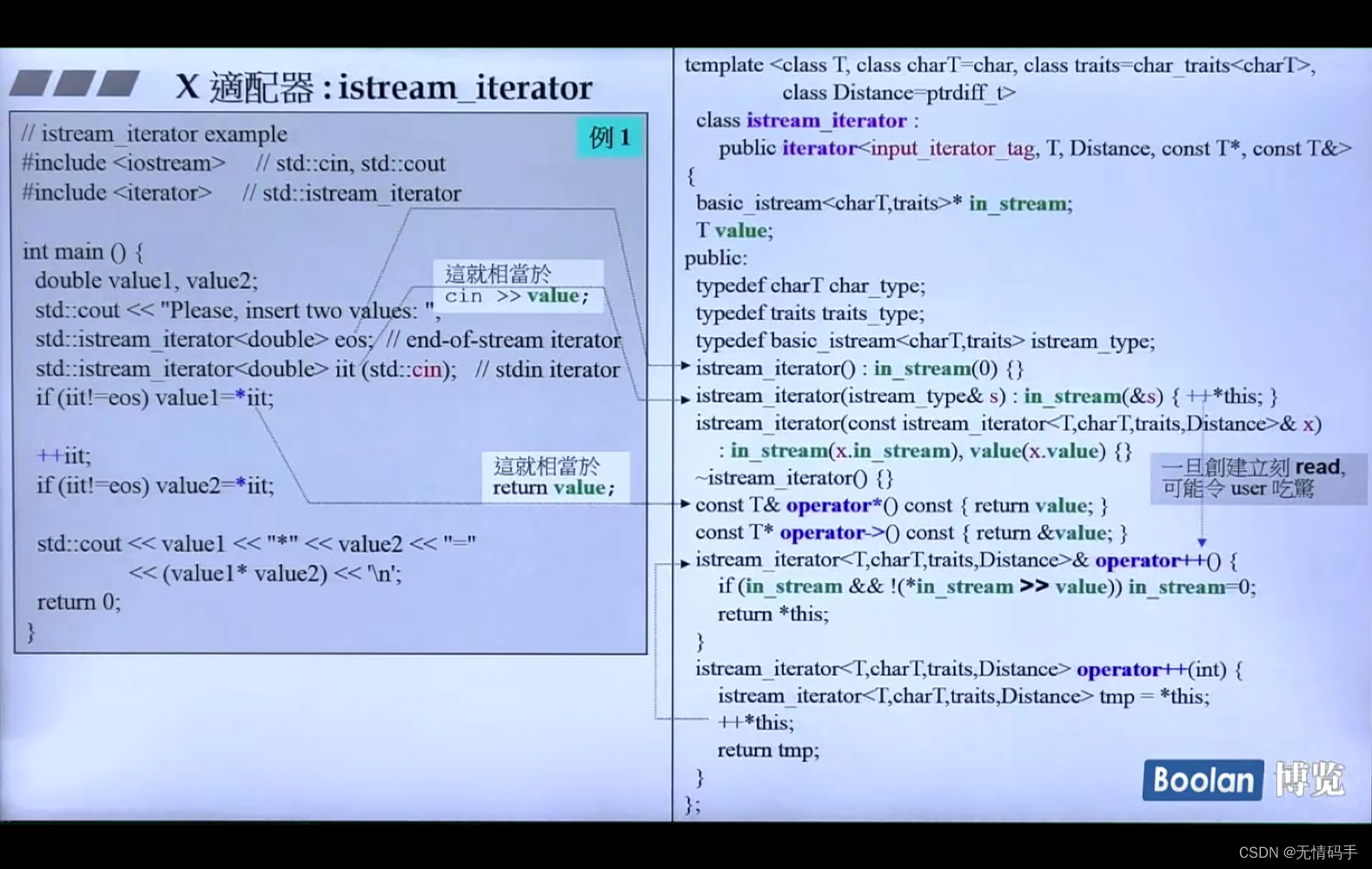
进入构造函数,S被记到in_stream里之后,马上++
重载operator++()
如果in_stream 已经存在,且要等待一个输入值
如果iit!=eos 就把刚刚读到的值给value
所以这两行就相当于 cin 了
后面的++是再次读取
copy和istream_iterator结合
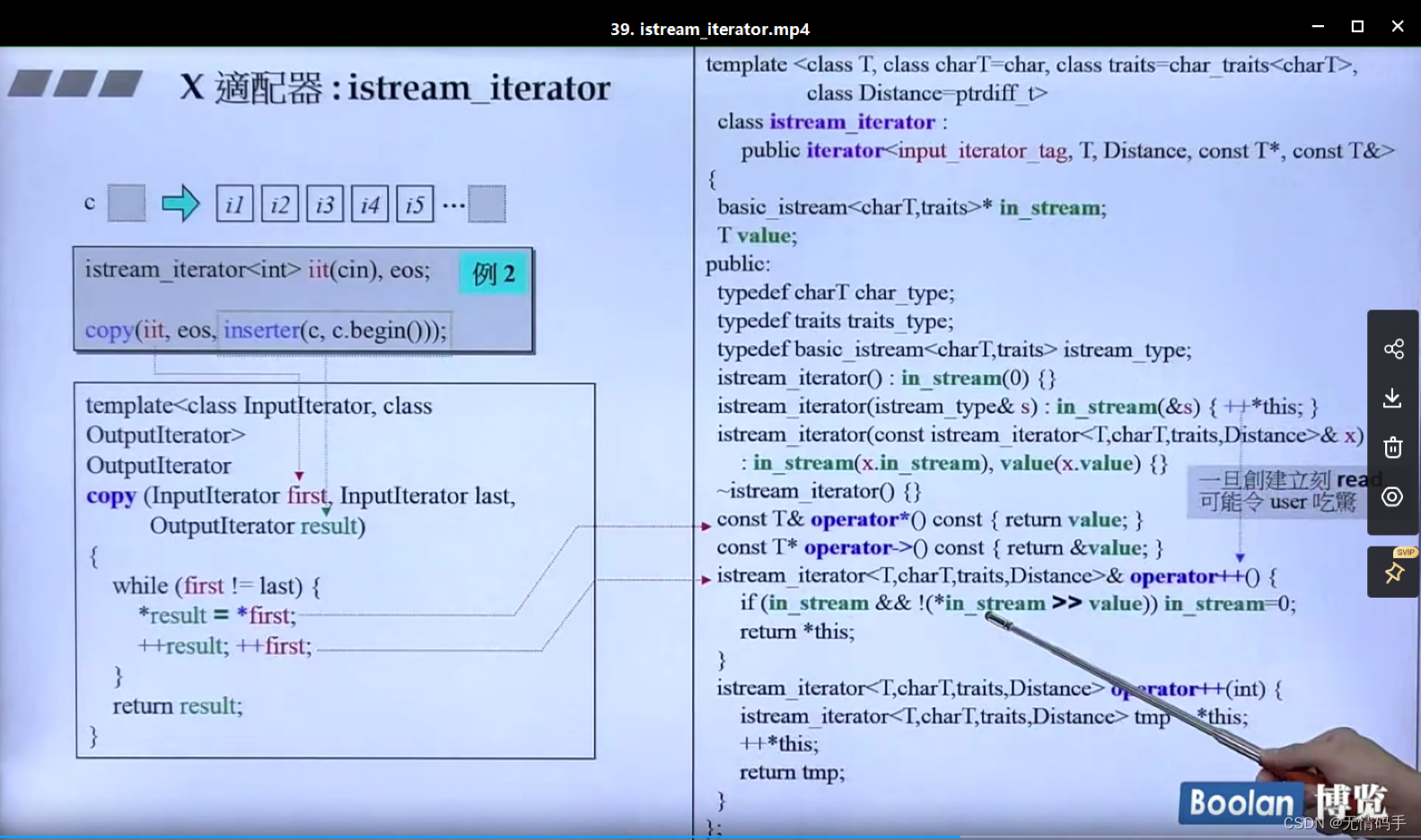
在istream_iterator< int> iit(cin), eos; 这一句的时候,就已经把值cin到了value里
在下面*first的时候,给了result
后面first再次++ cin又可以读内容
就这样循环 读一个 传一个…
40-一个万用的Hash Function
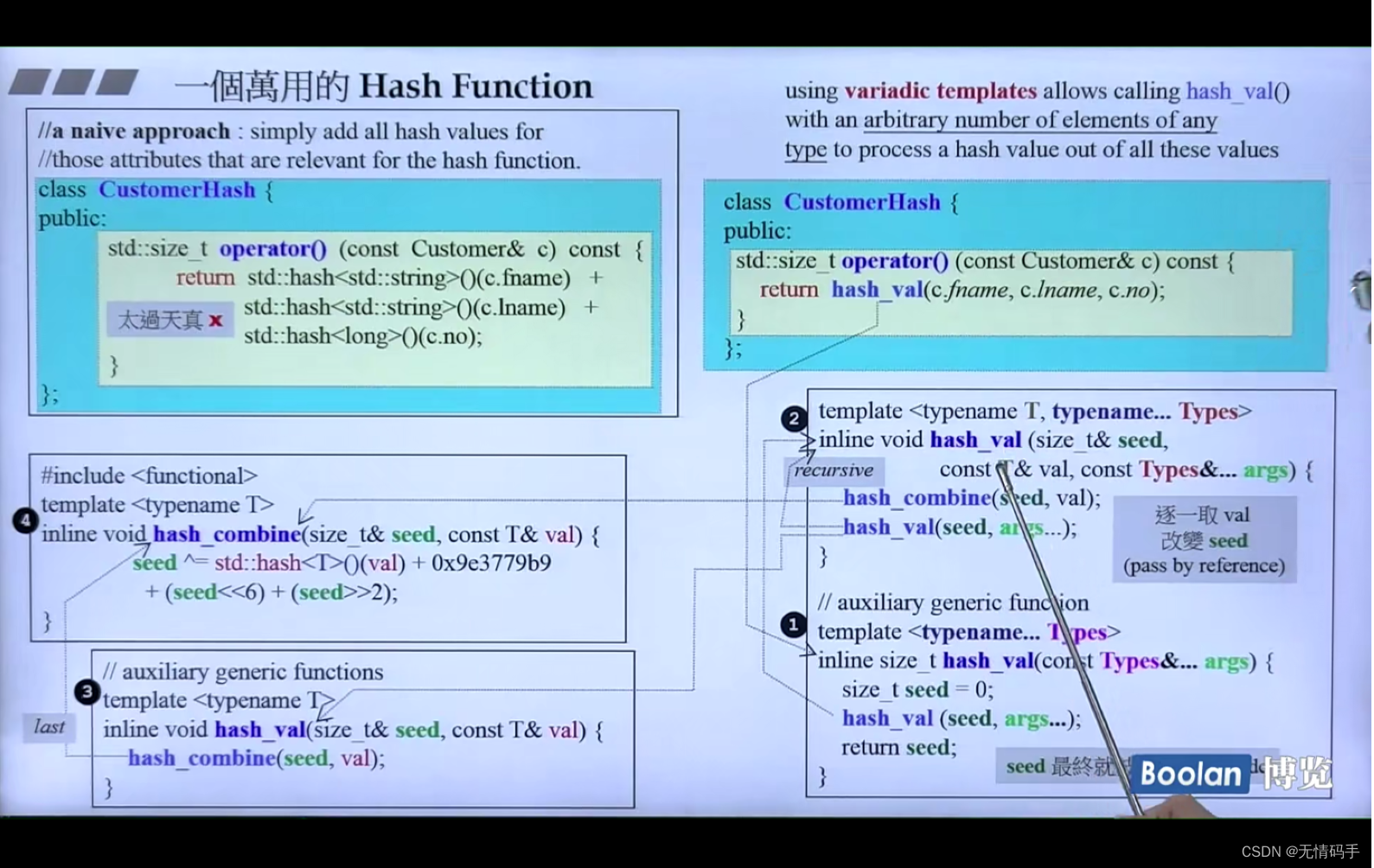
左上角的想法过于简单,会导致碰撞
注意(1)那部分是 可变化模版 …
(2)(3)也是不同的函数 参数类型不同
右上角蓝色,给的第一参数并不是size_t类型,所以调的是函数(1)
进入(1)后调了(2)
(2)把种子和val绑定在一起 并计算(先从args里分出来了一个val)
然后再次从args里分出来再次调用2
当只剩下一个的时候,调用(3)
每次拿一个值去改种子,最后都改完了,剩下的seed就是hashcode

把实际的hashcode值%11(当前篮子数) 看他们是落在哪个篮子里

bucket_count() 是看有多少个篮子
bucket_soze() 是看篮子里有多少个元素

hash 是一个空的 structer 但是对于一些基本数据类型有偏特化的版本
我们也可以自己定义一个自定义的偏特化版本

41-tuple用例
tuple的构建
tuple<string, int, int, complex<double>> t;
sizeof(t);
// 32 不是 28
tuple<int, float, string> t1(22,44.2,"nico");
auto t2 = make_tuple(22, 44, "stacy");
取用tuple
get<1>(t1);
get<2>(t2);
42 type traits
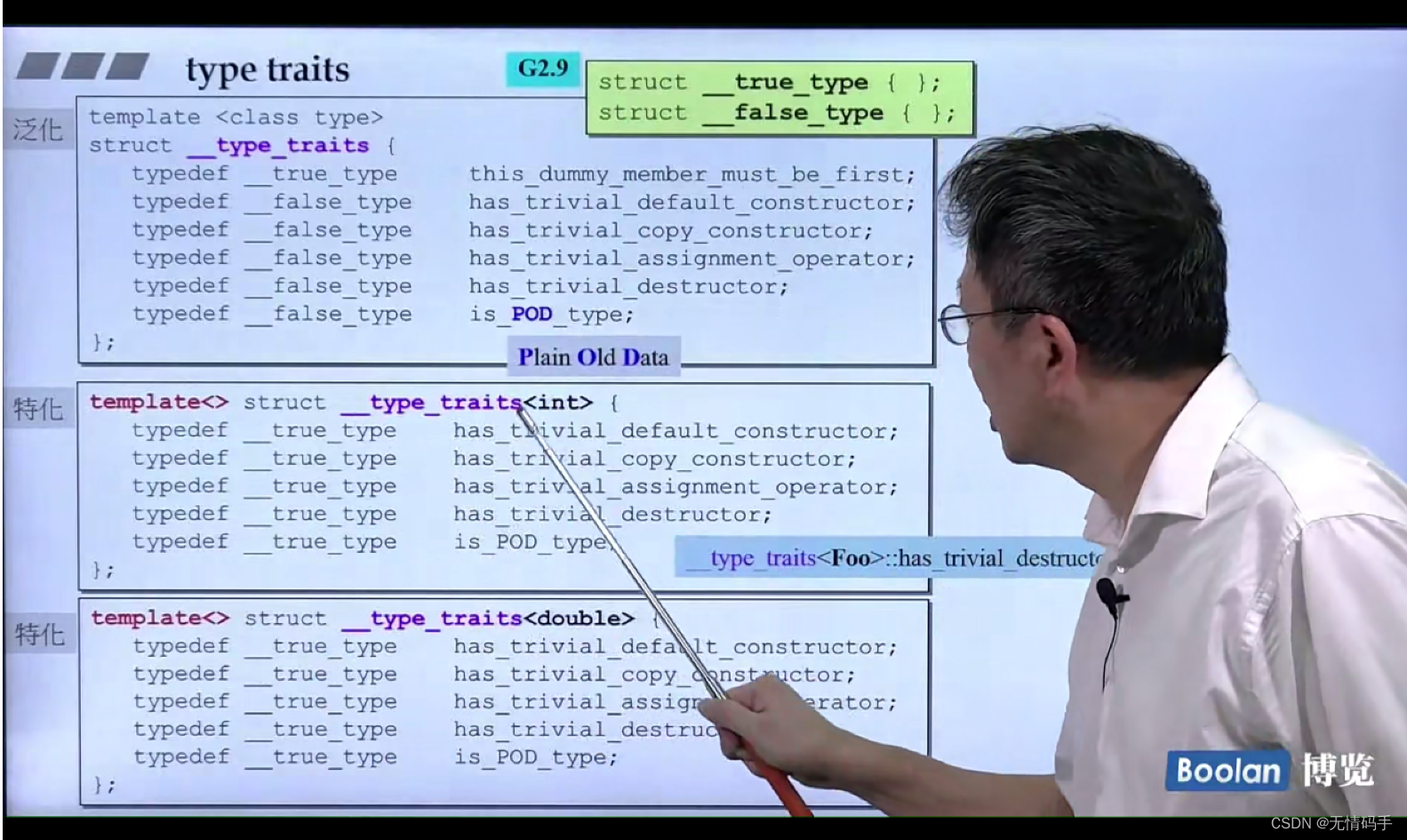
规定哪一部分是否重要
__true_type 是不重要
__false_type是重要
因为他们说的是trivial_xxx



一个类,只有准备把它当成父类的时候,才会有虚函数
String 不会有人把它当父类,他没有虚函数
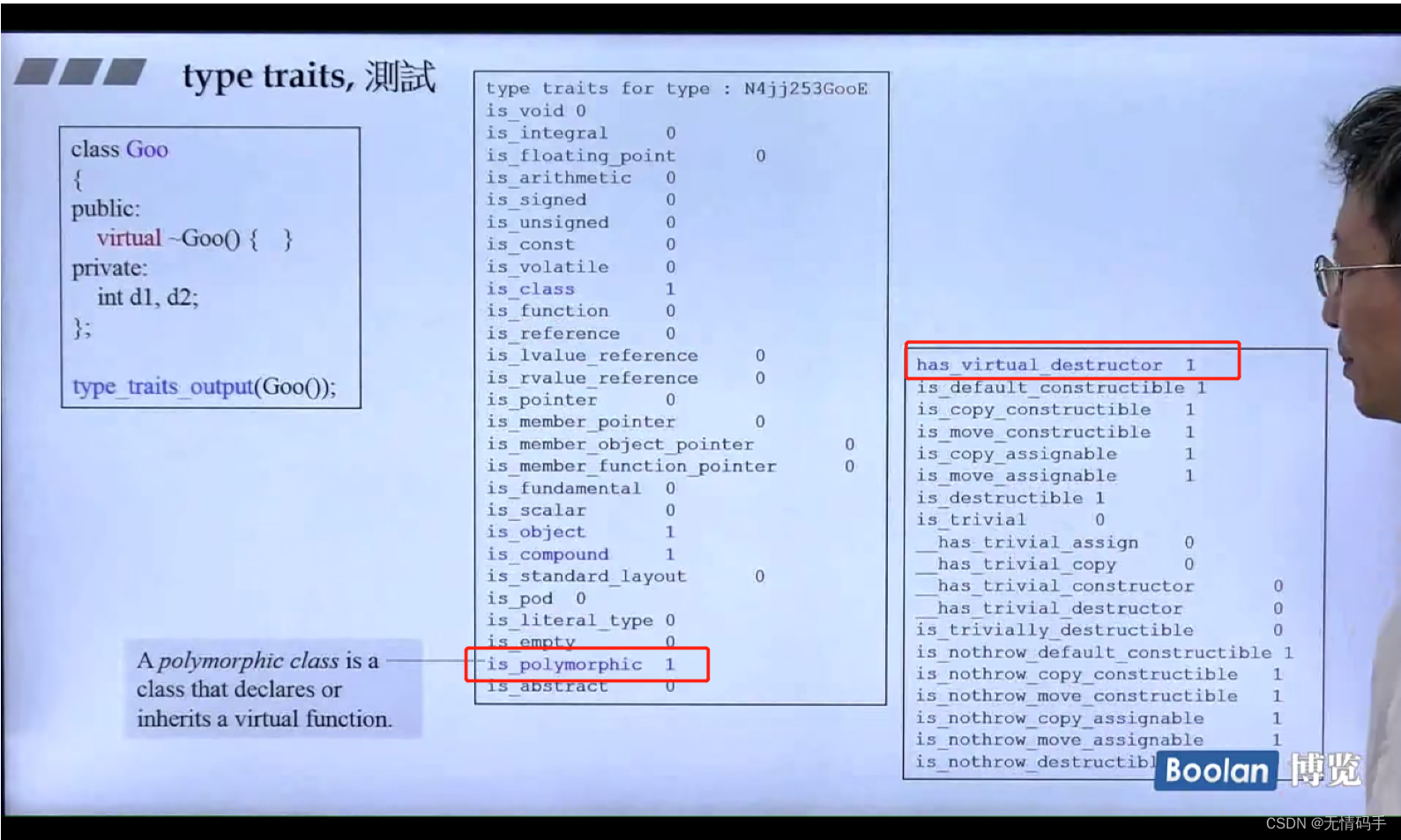
is_polymorphic 是否多态:有虚函数,所以它是1
has_virtual_destructor 有虚函数,所以它是1

四个里面有两个是要的,两个是不要的 default是要的,delete是不要的
(拷贝构造:不要、搬离构造函数(第二个) :要、拷贝赋值:要、搬离赋值:不要)
type traits 实现
怎么实现的?我们并没有一个一个地去偏特化
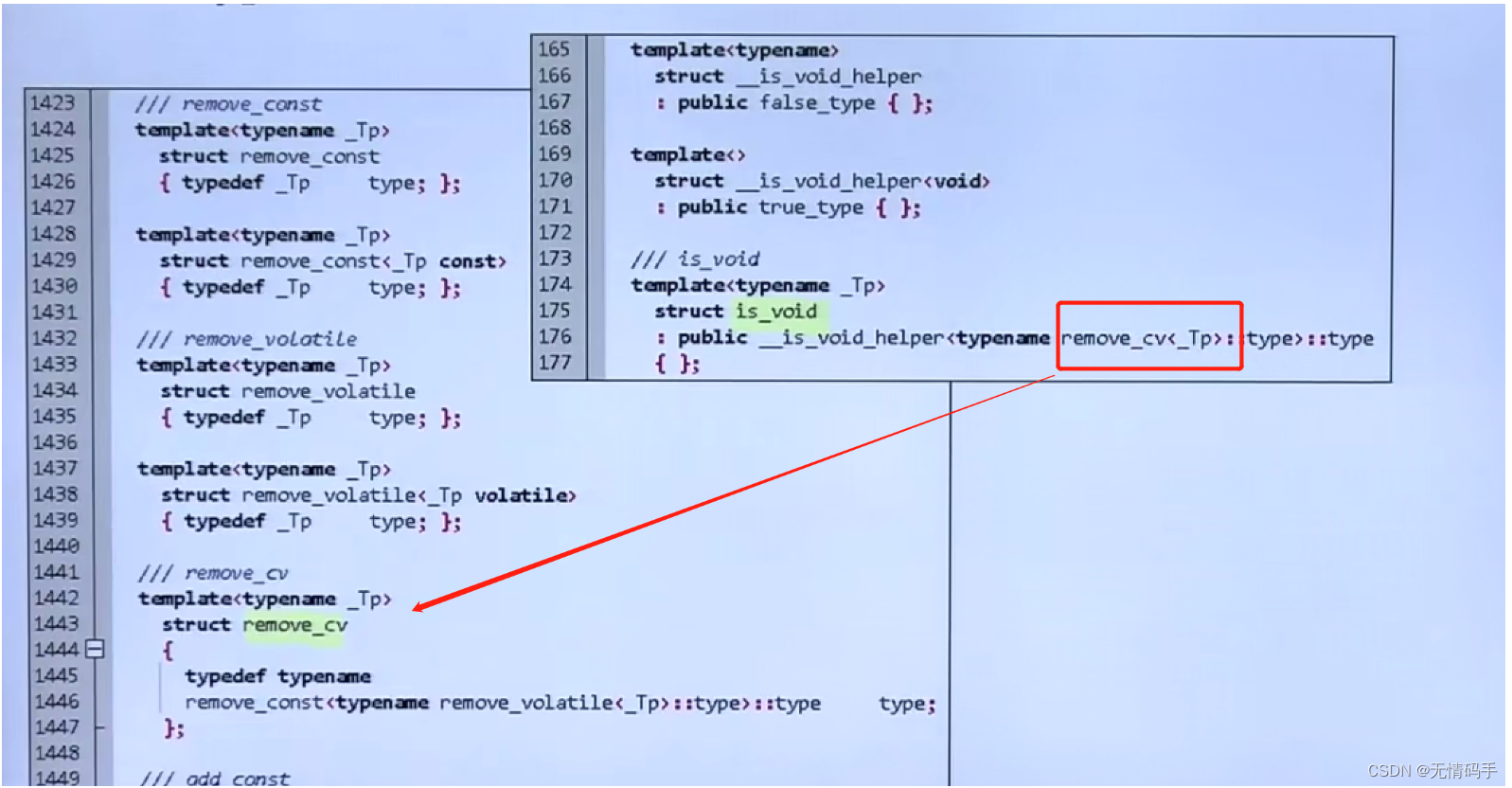
这里冒号的意思是继承
他们最后是会回归到它们的父类__true_type 或者 __false_type
它们是根据泛化/偏特化,并且通过一个一个的继承得到真正的那个类
拿掉const 和 volatile
通过一个泛化+偏特化实现
上面,你传给我一个_Tp 我再把这个_Tp定义为类型传回给你
下面,偏特化,你传给我一个_Tp const 形式的,我换给你的时候把const扔掉了
看remove_cv函数,永远都是用type做回应,它是先取了remove_volatile<_Tp>的type, 在把它传给remove_const去取type
is_void函数里,先去了cv,然后再交给is_void_helper,如果它是void(特化的),返回真,其他的返回假

交给is_integral_helper之后,如果符合这些特化,落到了他们那些任一个里,就是返回true_type,落到泛化里就是返回false_type

深入到class内部,就是编译器暗中帮助
cout
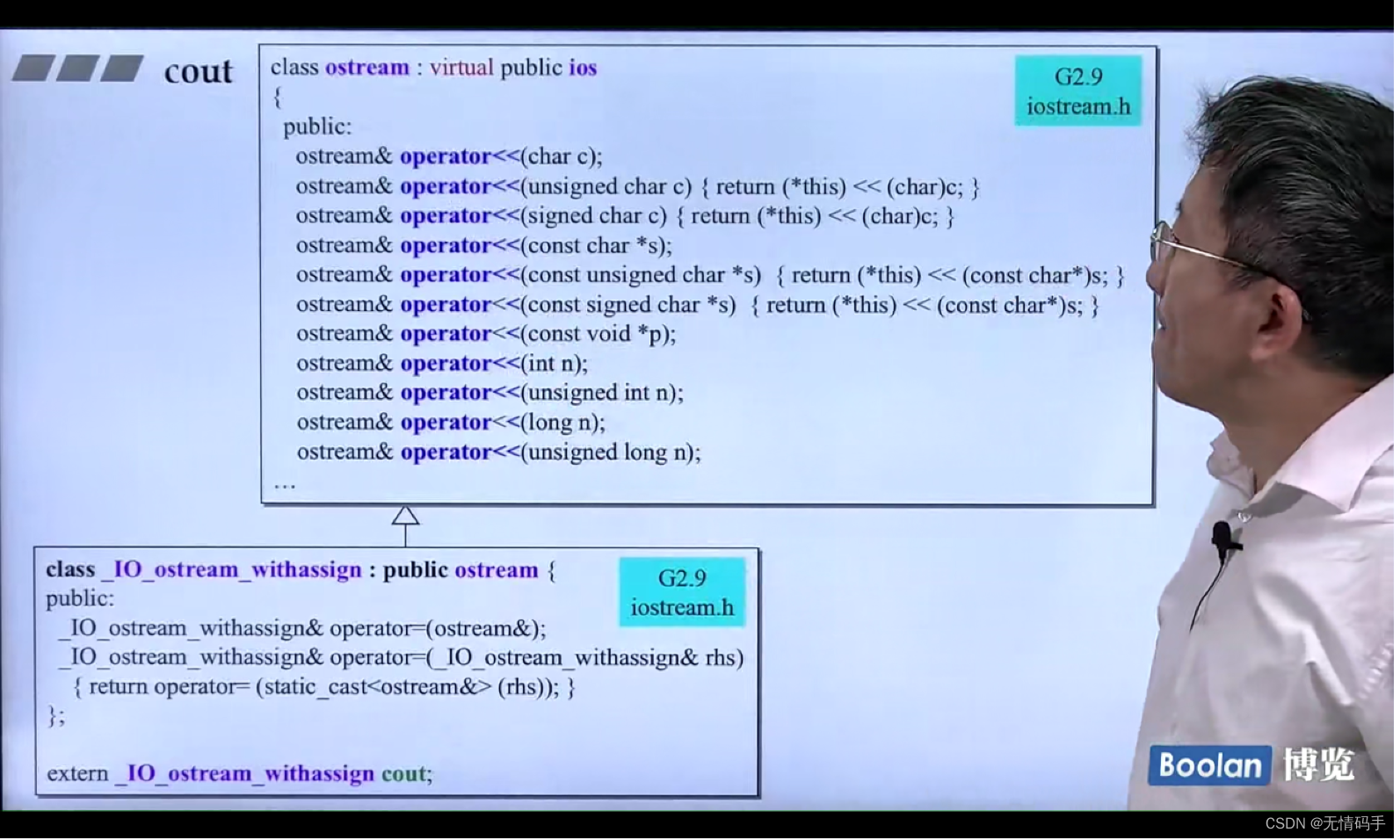
cout extern 类型的,它可以被外界任意使用
cout 这个类 继承自ostream 它早已定义好了一些基本类型的操作符重载出来

自己的类型要用cout,需要像这种形式写操作符重载
movable 元素对于deque速度效能的影响
拷贝构造何时调用:
#include <iostream>
using namespace std;
class A
{
private:
int a;
public:
A(int i){a=i;} //内联的构造函数
A(A &aa);
int geta(){return a;}
};
A::A(A &aa) //拷贝构造函数
{
a=aa.a;
cout<<"拷贝构造函数执行!"<<endl;
}
int get_a(A aa) //参数是对象,是值传递,会调用拷贝构造函数
{
return aa.geta();
}
int get_a_1(A &aa) //如果参数是引用类型,本身就是引用传递,所以不会调用拷贝构造函数
{
return aa.geta();
}
A get_A() //返回值是对象类型,会调用拷贝构造函数。会调用拷贝构造函数,因为函数体内生成的对象aa是临时的,离开这个函数就消失了。所有会调用拷贝构造函数复制一份。
{
A aa(1);
return aa;
}
A& get_A_1() //会调用拷贝构造函数,因为函数体内生成的对象aa是临时的,离开这个函数就消失了。所有会调用拷贝构造函数复制一份。
{
A aa(1);
return aa;
}
int _tmain(int argc, _TCHAR* argv[])
{
A a1(1);
A b1(a1); //用a1初始化b1,调用拷贝构造函数
A c1=a1; //用a1初始化c1,调用拷贝构造函数
int i=get_a(a1); //函数形参是类的对象,调用拷贝构造函数
int j=get_a_1(a1); //函数形参类型是引用,不调用拷贝构造函数
A d1=get_A(); //调用拷贝构造函数
A e1=get_A_1(); //调用拷贝构造函数
return 0;
}

因为vector要连续的两倍的扩充,所以对它的影响是最大的
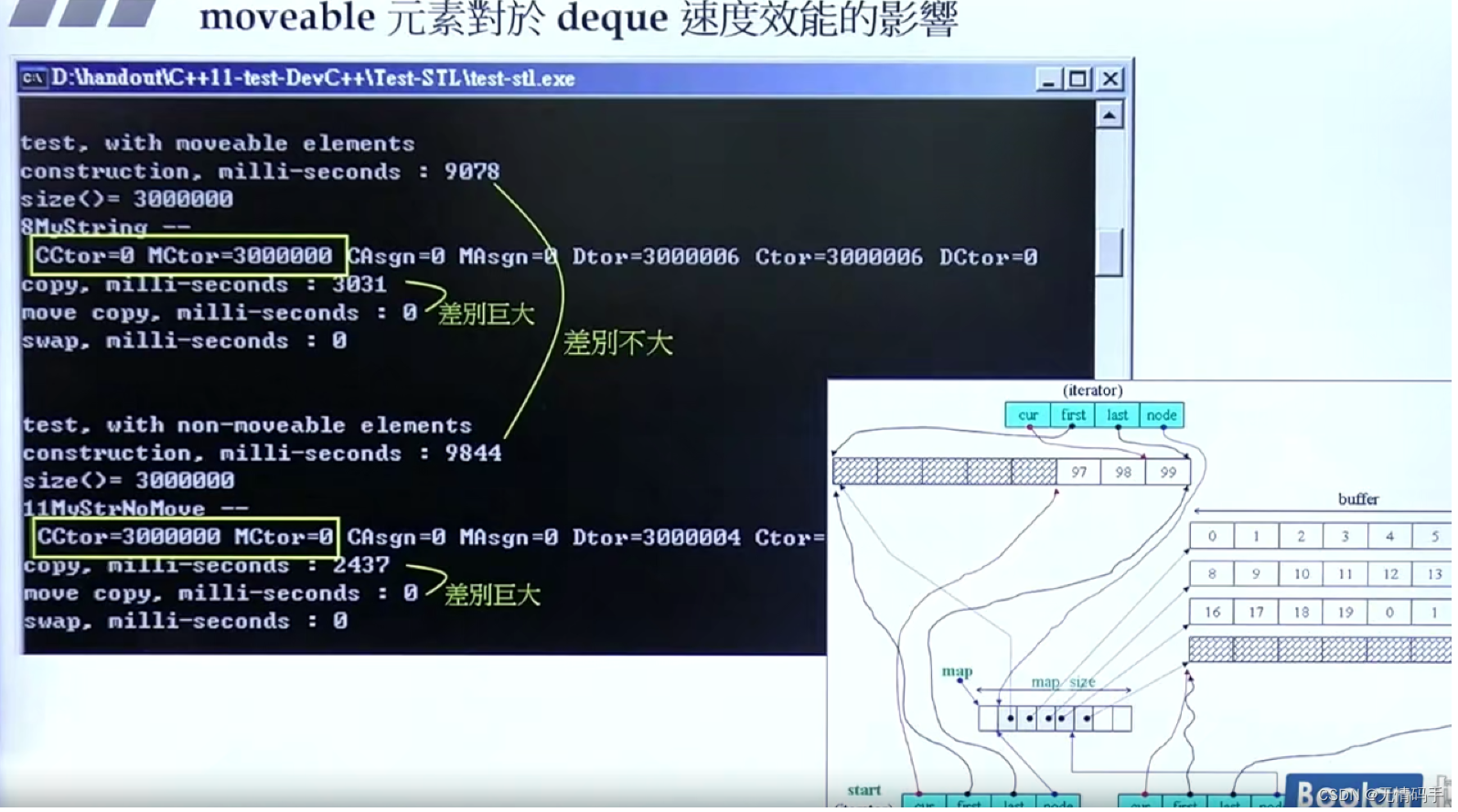
list、deque等四个影响差别不大

构造函数、拷贝构造函数、拷贝赋值都是我们熟悉的。
再看move ctor 主要的区别:reference of reference
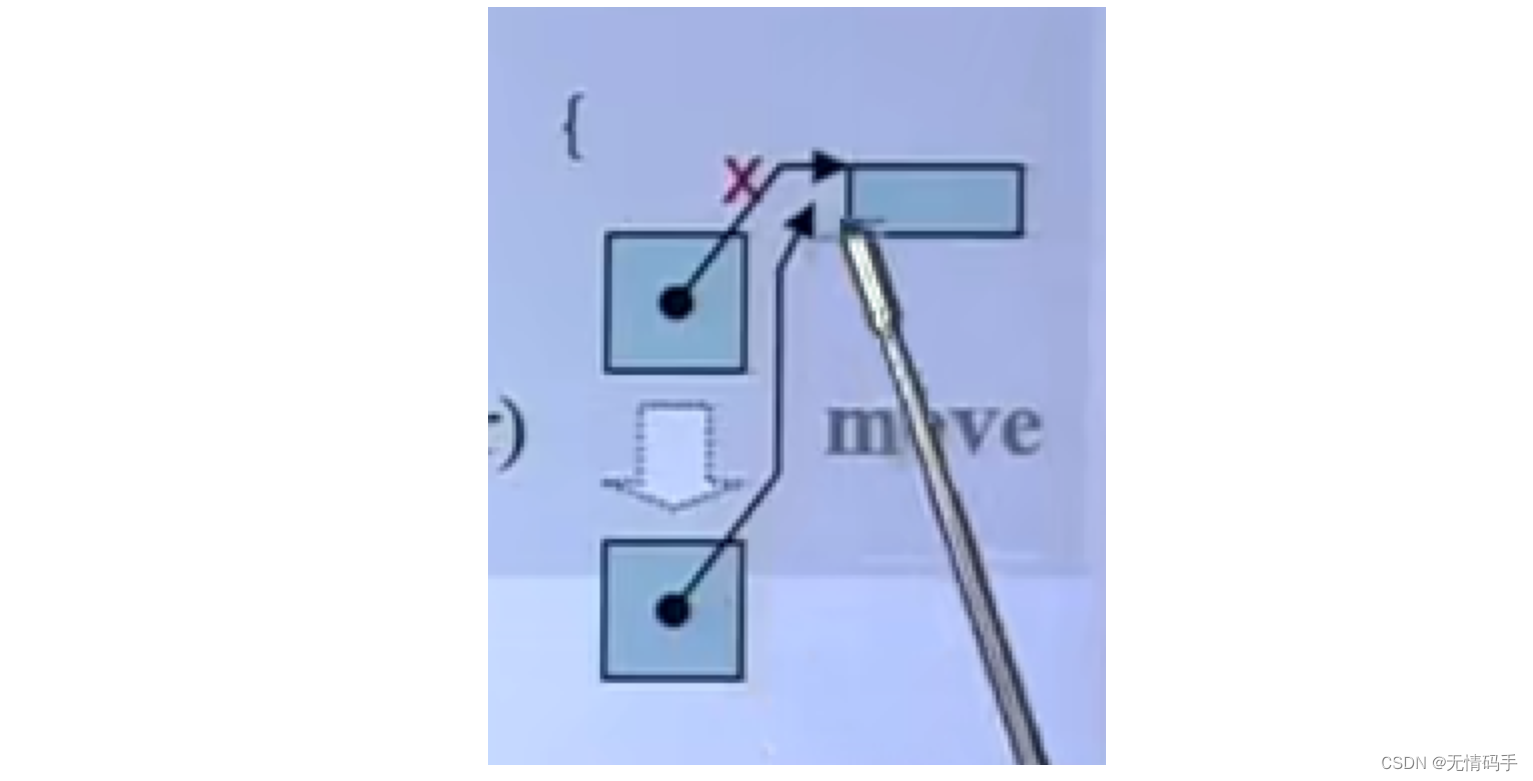
把原来的指针打断,把新的指针指过去
如果没有打断,两个都指向同一个 -> 浅拷贝
所以move版本和copy ctor的区别是:copy 版本是真的有分配,是深拷贝,move版本只是拷贝指针(一种特殊浅拷贝)
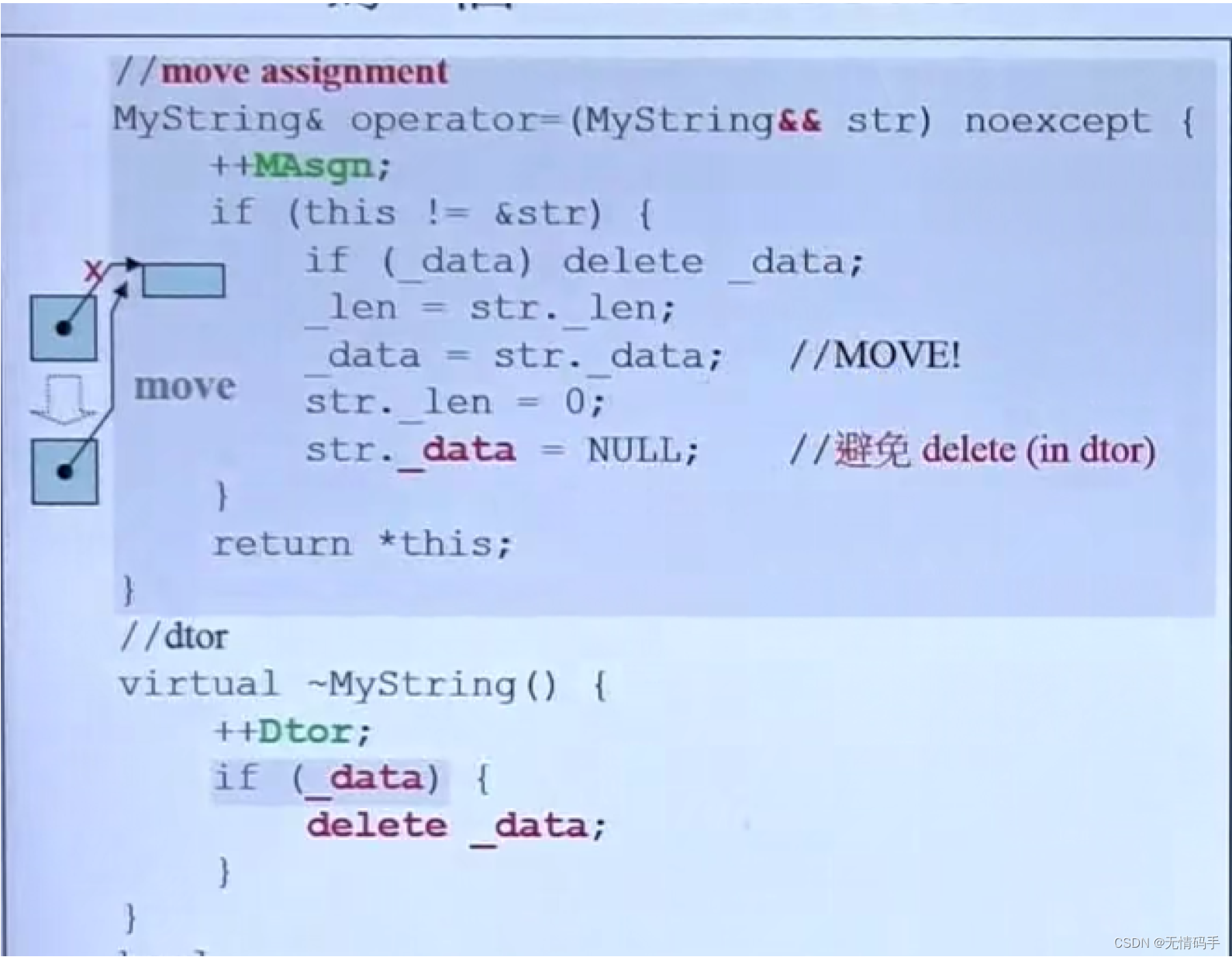
在析构函数里:没有被杀的时候,才会把它杀掉
为什么不直接杀呢?因为这里和其他的类不一样啦,这里有move ctor/assignment ,可能存在已经杀了的情况
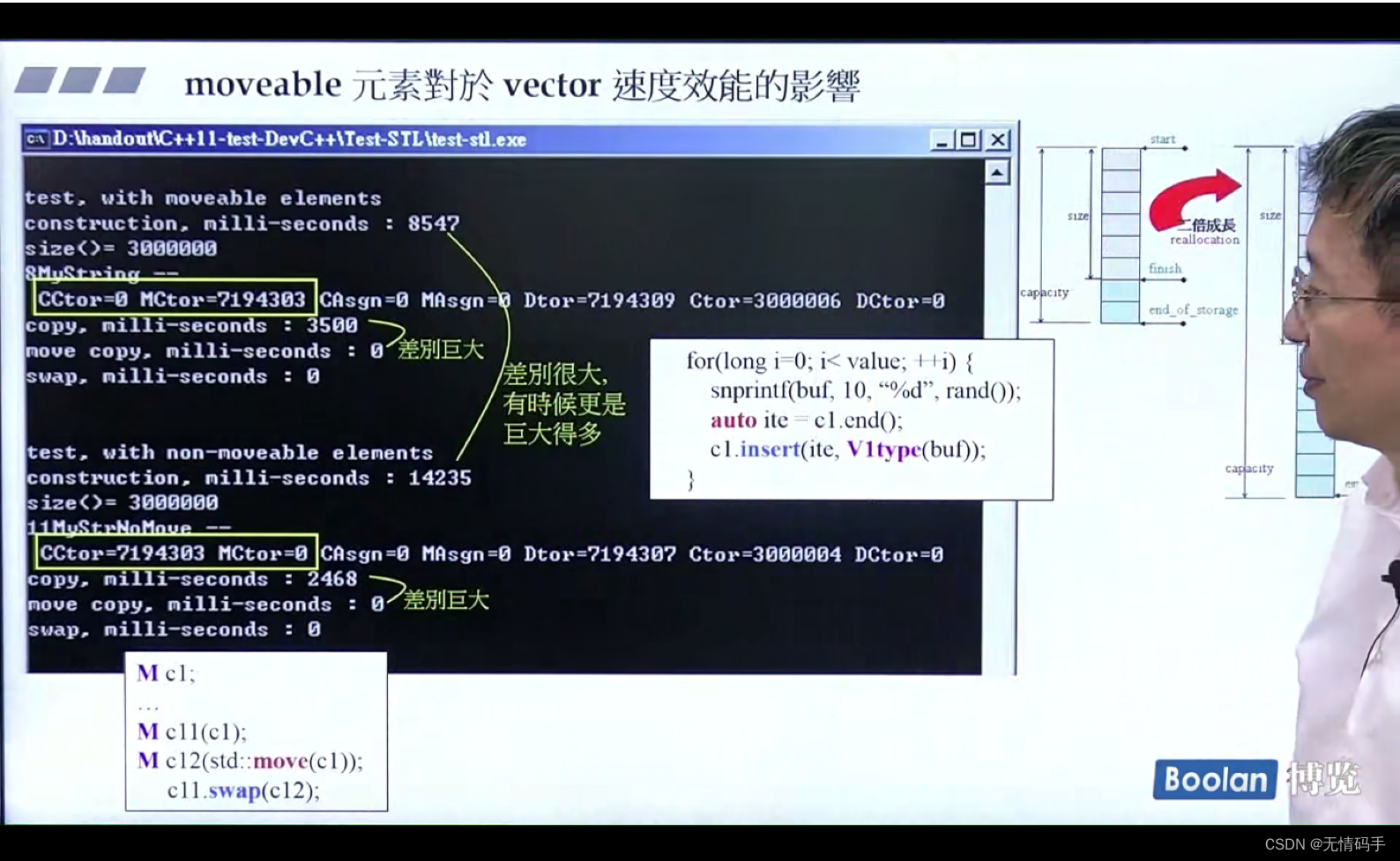
并没有特别的说用move版本/非move版本,而且这里十分高效
测试函数
要用move的条件:
move之后原来的东西不会再用了

因为这里安插的对象是V1type临时对象(没有名字),后面不会再用了,所以编译器会默认使用move copy
像下面的,用c1来copy,它不是临时对象,所以编译器不敢自作主张去用move copy,而是用普通的,除非像下面一样你特别地去指定使用move的,必须确保你后面不会再用
vector 的 浅拷贝(move ctor)
容器本身的深拷贝:

浅拷贝:
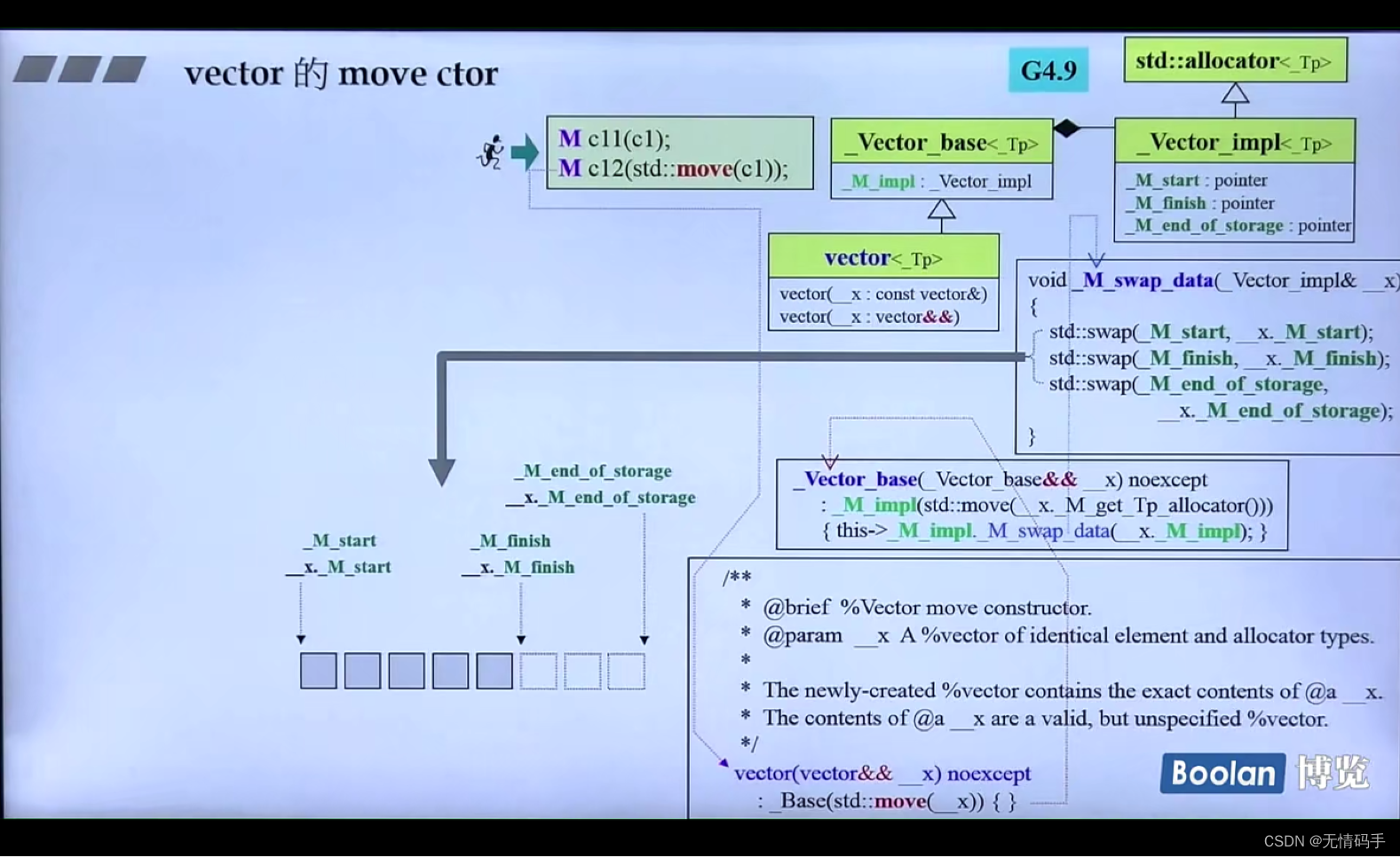
swap三个指针,并且把原来的东西作废














 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









