







考试课程:操作系统(A 卷) 时间:2018 年 05 月 25 日下午 12:45~15:05
答卷注意事项:
1.答题前,请先在试题纸和答卷本上写明 A 卷或 B 卷、系别、班级、学号和姓名。
2.在答卷本上答题时, 要写明题号, 不必抄题。 2. 在答卷本上答题时, 要写明题号, 不必抄题。
3.答题时, 要书写清楚和整洁。
4.请注意回答所有试题。本试卷有 29 个题目,共 5 页。
5.考试完毕, 必须将试题纸和答卷本一起交回。
一、对错题(15 分)
注意:回答请用 V 表示正确,用 X 表示错误;
-
[ ] 在多CPU场景下,多个线程通过自旋锁(spinlock)争抢进入临界区执行,第一个成功进入 临界区的线程是第一个执行自旋锁争抢的线程。
答:√。 用TS指令可以实现自旋锁,属于原子操作指令锁,适用于丹处理器或者共享主存的多处理器的任意数量的进程同步。
-
[ ] 运行在内核态的内核线程共享操作系统内核态中的一个页表。
√。
-
[ ] 操作系统创建用户进程时需要为此用户进程创建一个内核栈用于执行系统调用服务等。
√。
-
[ ] 通用操作系统的调度算法的主要目标是低延迟,高吞吐量,公平,负载均衡。
√。
-
[ ] 单处理器场景下,短剩余时间优先调度算法(SRT)可达到具有最小平均周转时间的效果。
√。短进程优先算法SPN具有最优平均周转时间,而SRT是SPN的可抢占改进版本,应该也是对的。
-
[ ] 单处理器场景下,无法通过打开和关闭中断的机制来保证内核中临界区代码的互斥性。
×。可以。
-
[ ] 信号量可用于解决需要互斥和同步需求的问题。
√。
-
[ ] 属于管程范围的函数/子程序相互之间具有互斥性。
×。感觉管程内的函数应该不是互斥的。
-
[ ] 操作系统处于安全状态,一定没有死锁;操作系统处于不安全状态,可能出现死锁。
×。处于安全状态是指系统能按某种顺序如<P1,P2,…,Pn>(称<P1,P2,…Pn>序列为安全序列),来为每个进程分配其所需资源,直到最大需求,使每个进程都可顺序完成。 如果处于安全状态,但不按照安全序列来分配资源,也可能进入死锁状态。
-
[ ] 80386取指地址是base+eip,base是隐藏寄存器,初始化为0xffff0000,eip初始化为0xfff0,故执行的第一条指令是0xfffffff0。
√。根据ucore_docs P106:
在PC系统开机复位时,CPU进入实模式,并将CS寄存器设置成0xF000,将它的shadow register的Base值初始化设置为0xFFFF0000,EIP寄存器初始化设置0x0000FFF0。所以机器执行的第一条指令的物理地址是0xFFFFFFF0。80386的BIOS代码也要和以前8086的BIOS代码兼容,故地址0xFFFFFFF0处的指令还是一条长跳转指令
jmp F000:E05B。
-
[ ] 在x86-32 CPU下,操作系统可以实现让用户态程序直接接收并处理硬件中断。
答:×。硬件中断需要进入内核态。
-
[ ] 由于符号链接(软链接)实际上是一类特殊的文件,它的内容就是其所指向的文件或目录的路径,所以符号链接可以指向一个不存在的文件或目录。
答: ×。文件的符号链接(SYMLINKD),如没有参数指定,则创建文件的符号链接,删除文件链接不影响目标文件,且创建链接时允许目标文件不存在;目录的符号链接(SYMLINKD) /D该参数可以创建目录的符号链接,删除目录链接不会影响目标目录,且创建链接时允许目标目录不存在;
-
[ ] 文件系统中,用于存储“文件访问控制信息”的合理位置是文件分配表。
答: ×。应该是文件控制块FCB。
-
[ ] 在操作系统中一旦出现死锁, 所有进程都不能运行。
答: ×。显然不对,只有那些因竞争资源而无限循环等待的进程才无法执行。
-
[ ] 在ucore for x86-32中,子进程通过sys_exit()执行进程退出时,ucore kernel会先释放子进程自身内核堆栈和进程控制块等,再唤醒父进程(或initproc),最后执行iret返回。
答:×。子进程的内核栈和进程控制块是由父进程帮忙收回的。
根据ucore_docs P252:当进程执行完它的工作后,就需要执行退出操作,释放进程占用的资源。ucore分了两步来完成这个工作,首先由进程本身完成大部分资源的占用内存回收工作,然后由此进程的父进程完成剩余资源占用内存的回收工作。为何不让进程本身完成所有的资源回收工作呢?这是因为进程要执行回收操作,就表明此进程还存在,还在执行指令,这就需要内核栈的空间不能释放,且表示进程存在的进程控制块不能释放。所以需要父进程来帮忙释放子进程无法完成的这两个资源回收工作。
二、填空题(30 分) 小强同学认真上课听讲,参与讨论,并完成了从lab0~lab8的所有实验,在学习过程中,了解和学 到了很多知识。下面是他的学习心得,请补充完整。
-
小强发现完成实验需要在Linux下操作很多命令行工具,于是他认真学习了lab0中的知识,了 解到git的强大版本管理功能,Linux中在命令行模式下可以通过执行一条命令”(__16.1 __) https://github.com/chyyuu/ucore_lab.git ”来首次获得整个实验的代码。如果编写完实验内容,可通过执行一条命令“(__16.2 __)”来完成整个lab的编译和执行代码生成。
答:
git clone;
make;
-
在完成lab1的过程中,了解到在80386保护模式下,如果产生了外部中断,CPU需要开始保存当前被打断的执行现场,以便于将来恢复被打断的程序继续执行。这需要利用栈来保存相关现场信息,即依次压入当前被打断控制流涉及到的(__17.1 __)、(__17.2 __)、(__17.3 __)等具体的硬件信息。
答:
EFLAGS;
CS;
EIP;
-
在完成lab2的过程中,需要了解x86-32的内存大小与布局,页机制,页表结构等。硬件模拟器提供了128MB的物理内存,如ucore kernel需要通过页表管理整个128MB的物理内存,则页表总共需要占用(__18.1 __)KB的内存空间。
答:1024。一个页面4KB,共有128MB/4KB=215 个页面,也就是215 个页表项,每个页表项占4B,故需要215 *4B =220bit=1024KB的内存空间。
-
在完成lab3的过程中,ucore操作系统在页机制基础上,并利用异常机制建立了虚存管理策略与机制。在产生页面访问错误异常时,CPU直接把表示页访问异常类型的值(简称页访问异常错误码,errorCode)保存在(__19.1 __)中。ucore通过 x86-32CPU 中的(__19.2 __)寄存器 可以获得发生页面访问错误异常时的线性地址。
答:
中断栈;
CR2;
见实验手册P196:
CPU会把产生异常的线性地址存储在CR2中,并且把表示页访问异常类型的值(简称页访问异常错误码,errorCode)
保存在中断栈中。
-
在完成lab4/5的过程中,了解到操作系统管理内核线程或用户进程的一个关键数据结构是 (__20.1 __),其中包含了(__20.2 __),用于进程/线程切换涉及的保存与恢复进程/线程上下文,还包含了(__20.3 __),用于用户态/特权态切换涉及被中断/异常打断的执行上下文。
答:
proc_struct;
struct context context;
struct trapframe *tf;
进程创建所需的重要数据结构–进程控制块 proc_struct.
struct proc_struct {
enum proc_state state; // Process state
int pid; // Process ID
int runs; // the running times of Proces
uintptr_t kstack; // Process kernel stack
volatile bool need_resched; // need to be rescheduled to release CPU?
struct proc_struct *parent; // the parent process
struct mm_struct *mm; // Process's memory management field
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for current interrupt
uintptr_t cr3; // the base addr of Page Directroy Table(PDT)
uint32_t flags; // Process flag
char name[PROC_NAME_LEN + 1]; // Process name
list_entry_t list_link; // Process link list
list_entry_t hash_link; // Process hash list
};
● context:进程的上下文,用于进程切换(参见switch.S)。在 uCore中,所有的进程在内核
中也是相对独立的(例如独立的内核堆栈以及上下文等等)。使用 context 保存寄存器的目的
就在于在内核态中能够进行上下文之间的切换。实际利用context进行上下文切换的函数是
在kern/process/switch.S中定义switch_to。
● tf:中断帧的指针,总是指向内核栈的某个位置:当进程从用户空间跳到内核空间时,中断
帧记录了进程在被中断前的状态。当内核需要跳回用户空间时,需要调整中断帧以恢复让进
程继续执行的各寄存器值。除此之外,uCore内核允许嵌套中断。因此为了保证嵌套中断发生
-
在完成lab6的过程中,小强发现执行测试时调度过程的显示结果很不稳定,通过与同学交流, 发现是由于自己在windows中建立了一个virtualbox虚拟机环境,在virtualbox虚拟机环境下, 再执行qemu模拟器导致ucore的实际上执行时间变动很大。为减少这种变动,小强采取了 (__21.1 __)【不超过20个字】的方法,改善了此问题,并取得了稳定的实验结果。
答:
这个我也不知道。
-
在完成lab7的过程中,小强发现本实验主要通过建立(__22.1 __)机制来完成信号量机制,主 要通过建立(__22.2 __)机制来完成管程机制,且此管程的实现采用的是Mesa、Hoare、Brinch Hanson 三种语义方式中的(__22.3 __)语义方式。
答:
屏蔽中断;
等待队列;(或者条件变量)
Hoare;(根据手册中的描述,进程A执行signal,会唤醒进程B,而导致进程A睡眠,符合Hoare这种语义方式。)
ucore实验手册P315:
管程中的成员变量mutex是一个二值信号量,是实现每次只允许一个进程进入管程的关键元素,确保了互斥访问性质。管程中的条件变量cv通过执行 wait_cv ,会使得等待某个条件Cond为真的进程能够离开管程并睡眠,且让其他进程进入管程继续执行;而进入管程的某进程设置条件Cond为真并执行 signal_cv 时,能够让等待某个条件Cond为真的睡眠进程被唤醒,从而继续进入管程中执行。
注意:管程中的成员变量信号量next和整型变量next_count是配合进程对条件变量cv的操作而设置的,这是由于发出 signal_cv 的进程A会唤醒由于 wait_cv 而睡眠的进程B,由于管程中只允许一个进程运行,所以进程B执行会导致唤醒进程B的进程A睡眠,直到进程B离开管程,进程A才能继续执行,这个同步过程是通过信号量next完成的;而next_count表示了由于发出 singal_cv 而睡眠的进程个数。
Hansen管程:当前执行进程更优先,效率更高。
Hoare管程:等待条件变量的线程优先级更高。
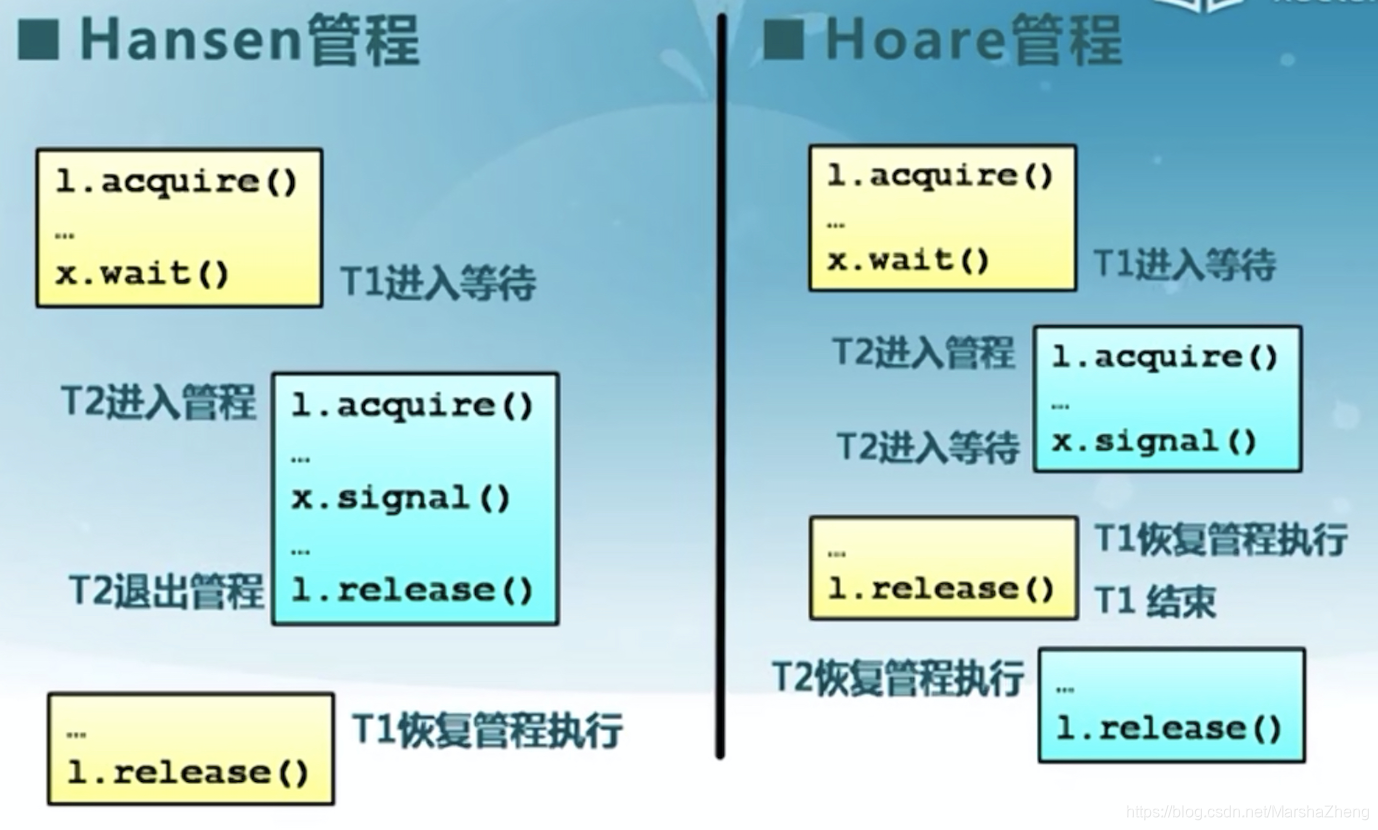

Hoare管程的一个缺点——额外的进程切换,比如P唤醒Q,要从P切换到Q,上下文切换需要开销。为了解决这个问题,使用notify代替signal操作——使条件队列头的进程得到通知,在将来合适的时候且当CPU可用时恢复执行.
由于收到通知时并未执行,所以当进程正真被调度时,条件不一定成立——比如不能保证其他进程进入管程,可以会导致丢失的信号这个问题,所以检查条件要使用while循环而不是if判断.
相比Hoare管程,Mesa对条件变量至少多了一次额外的检测,但是不需要进程的切换,且对等待进程在notify之后何时运行没有任何限制,所以Mesa管程比Hoare管程要简单高效些.(https://blog.csdn.net/xiaoguobaf/article/details/52174285 )
-
在完成lab8的过程中,小强发现ucore设计了文件系统抽象层–(__23.1 __),它提供一个统一 的文件系统操作界面和编程接口,可支持不同的具体文件系统。在对具体文件系统SFS的分析过程中,小强发现SFS在硬盘上的主要内容包括(__23.2 __),记录了所在硬盘的扇区总数量和未用扇区数量;还有(__23.3 __),记录了已用扇区和未用扇区的位置;(__23.4 __)记录了根目录的内容。
答:
VFS;
superblock;
freemap;
root-dir inode;
第0个块(4K)是超级块(superblock),它包含了关于文件系统的所有关键参数,当计算机被启动或文件系统被首次接触时,超级块的内容就会被装入内存。其定义如下:
struct sfs_super { uint32_t magic; /* magic number, should be SFS_MAGIC */ uint32_t blocks; /* # of blocks in fs */ uint32_t unused_blocks; /* # of unused blocks in fs */ char info[SFS_MAX_INFO_LEN + 1]; /* infomation for sfs */ };
可以看到,包含一个成员变量魔数magic,其值为0x2f8dbe2a,内核通过它来检查磁盘镜像是 否是合法的 SFS
img;成员变量blocks记录了SFS中所有block的数量,即 img 的大小;成员
变量unused_block记录了SFS中还没有被使用的block的数量;成员变量info包含了字符 串"simple file
system"。 第1个块放了一个root-dir的inode,用来记录根目录的相关信息。有关inode还将在后续部分介
绍。这里只要理解root-dir是SFS文件系统的根结点,通过这个root-dir的inode信息就可以定位
并查找到根目录下的所有文件信息。 从第2个块开始,根据SFS中所有块的数量,用1个bit来表示一个块的占用和未被占用的情
况。这个区域称为SFS的freemap区域,这将占用若干个块空间。为了更好地记录和管理
freemap区域,专门提供了两个文件kern/fs/sfs/bitmap.[ch]来完成根据一个块号查找或设置对 应的bit位的值。
-
现有一个RAID磁盘阵列,包含6个磁盘,每个磁盘大小都是2TB,最大写入速度 200 MB/s, 最大读取速度 250 MB/s 的硬盘。用它们分别组成RAID级分别为0、1和5。假设在理想情况下(无中断、异常、预先缓存等外在干扰因素等),请回答下列问题。
A) 用它们组成的RAID0阵列的总可用空间为 (__24.1 __),最大写入速度为 (__24.2 __), 最大读取速度为 (__24.3 __);
B) 用它们组成的RAID1阵列的总可用空间为 (__24.4 __),最大写入速度为 (__24.5 __),最 大读取速度为 (__24.6 __);
C) 用它们组成的RAID5阵列的总可用空间为 (__24.7 __),最大写入速度为 (__24.8 __),最 大读取速度为 (__24.9 __)。答:
A) 12TB; 1200MB/s; 1200MB/s;
B) 6TB; 600MB/s; 1200MB/s; (有三块作为备份盘)
C) 10TB; 1000MB/s; 1000MB/s; (有一块盘存储奇偶校验数据)
RAID 0 又称为Stripe(条带化)或striping(条带模式),它在所有RAID级别中具有最高的存储性能(磁盘容量不浪费,读写很快)。
RAID0 提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求,这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。
RAID 1 又称为Mirror 或Mirrooring(镜像),它的宗旨是最大限度的保证用户数据的可用性和可修复性,RAID 1 的操作方式是把用户写入硬盘的数据百分之百的自动复制到另外一个硬盘上,从而实现存储双份的数据。
要制作RAID 1,只支持两块盘,整个RAID大小等于两个磁盘中最小的那块的容量,因此,最好使用同样大小的磁盘,在存储时同时写入两块磁盘,实现数据完整备份,但相对降低了写入性能,但是读取数据时可以并发,相当于两块RAID 0的读取效率。
RAID 是一种存储性能,数据安全和存储成本兼顾的存储解决方案。
RAID 5需要三块或以上的物理磁盘,可以提供热备盘实现故障恢复,采用奇偶校验,可靠性强,只有同时损坏2块盘时数据才会损坏,只损坏1块盘时,系统会根据存储的奇偶校验位重建数据,临时提供服务,此时如果有热备盘,系统还会自动在热备盘上重建故障磁盘上的数据。
- 假定在X86-32平台上的ucore的虚拟存储系统中,采用4KB页大小和二级页表结构。请补全功 能为通过虚拟地址找到对应的页表项的get_pte()函数。
可能需要用到的函数有:
page2pa() 获取物理页对应的物理地址;
page2ppn() 获取物理页对应的物理页号;
pa2page() 获取物理页号对应的物理页数据结构指针; page2kva() 获取物理页对应内核虚拟地址;
kva2page() 从内核虚拟地址获取物理页数据结构指针;
可能用到的宏有:
memset(p,v,n) 对指定地址p开始的长度为n的内存区域进行赋值v PDX(la) 虚拟地址la对应的页目录项序号;
KADDR(pa) 物理地址pa对应的内核虚拟地址;
PADDR(kva) 虚拟地址kva对应的物理地址;
PTE_P:存在标志位
PTE_W:可修改标志位
PTE_U:用户可访问标志位
pte_t *get_pte(pde_t *pgdir, uintptr_t la, bool create){
pde_t *pdep = __25.1 __;
if(!*pdep & __25.2 __){
struct Page *page;
if(!create || (page = alloc()) == NULL){
return NULL;
}
set_page_ref(page,1);
uintptr_t pa = __25.3 __;
memset(__25.4 __,0, PGSIZE);
*pdep =__25.5 __;
}
return &((pte_t *)KADDR(PDE_ADDR(*pdep)))[PTX(la)];
}
答:
&pgdir[PDX(la)];
PTE_P;
page2pa(page);
KADDR(pa);
pa | PTE_U | PTE_W | PTE_P;
(参考另一位博主的实验报告https://blog.csdn.net/qq_19876131/article/details/51706978 )
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
pde_t *pdep = &pgdir[PDX(la)]; // (1) find page directory entry
if (!(*pdep & PTE_P)) { // (2) check if entry is not present
struct Page *page;
if (!create || (page = alloc_page()) == NULL) { // (3) check if creating is needed, then alloc page for page table
return NULL;
}
set_page_ref(page, 1); // (4) set page reference
uintptr_t pa = page2pa(page); // (5) get linear address of page
//注释中给了提示,If you need to visit a physical address, please use KADDR()
memset(KADDR(pa), 0, PGSIZE); // (6) clear page content using memset
*pdep = pa | PTE_U | PTE_W | PTE_P; // (7) set page directory entry's permission
}
return &((pte_t *)KADDR(PDE_ADDR(*pdep)))[PTX(la)]; // (8) return page table entry
}
三、问答题
-
(18分)假定某文件系统采用多级索引分配的方法,普通文件的索引节点(inode)中包括一个 占8字节的文件长度字段和15个占4字节的数据块指针(即块号)。其中,前12个是直接索引块(direct block)的指针,第13个是1级间接索引块(indirect block)指针,第14个是2级间接 索引块(doubly indirect block)指针,第15个是3级间接索引块(triply indirect block)指针。 间接索引块中连续存放占4字节的数据块指针。数据块以及间接块的大小为4KB。请回答下列问题。
A) 计算该文件系统理论上能够支持的单个文件最大长度。
B) 假设读取磁盘上一个块需要1ms,块缓存机制只缓存文件的索引节点,并且所有需要的索引节点都已加载到缓存;不缓存数据块以及间接索引块;读取文件操作不会发生写入操作,访问内存的时间忽略不计。计算从头到尾读取一个8MB(即2048块)文件 需要的时间。
C) 假设读取磁盘上一个块需要1ms,块缓存机制缓存文件的索引节点、数据块和间接索引块,并且所有需要的索引节点都已加载到缓存;开始时缓存没有加载任何数据块或者间接块;读取文件操作不会发生写入操作,访问内存的时间忽略不计。计算从头到尾读取一个8MB(即2048块)文件需要的时间。
答:
A)直接索引有12个数据块,一级间接索引块包含1K个数据块,二级间接索引块包含1M个数据块,三级间接索引包含1G个数据块,故文件最大为(1G+1M+1K+12)* 4KB ~~4TB;
B) 12个直接索引已在缓存中,2048块其中有1024块属于一级间接索引指向的块中,1012块在二级间接索引的第一个索引指向的块中。2048块读取首先需要2048ms,再加上读取一级间接索引和二级间接索引分别需要1024ms和1012*2ms(因为不缓存间接索引块,所以每次都要从磁盘中先去读间接索引块,才能再去找数据块),总共需要5096ms。
C)与B的区别在于:“块缓存机制缓存文件的索引节点、数据块和间接索引块”。所以不需要反复从磁盘中去读间接块的内容,只要读过一次,间接块就会被缓存。所以时间为2048+3=2051ms。
- (5分)无锁 (Lock-Free) 数据结构在工程实践中有十分重要的应用,因而常用处理器的指令
集都提供了相应的指令来帮助我们实现无锁数据结构,如下为 x86 平台的 cmpxchg 指令的
伪代码。
// Pseudocode for CMPXCHG instruction. It executes atomically.
int cmpxchg(void* addr, uint32_t oldval, uint32_t newval) {
if (*addr != oldval) {
return 0; }
*addr = newval;
return 1; }
考虑使用该指令实现一个无锁 LIFO 队列
struct node {
struct node* next;
/* Other data fields */
};
struct node* head = NULL;
void push(struct node* node) {
do {
node->next = head;
} while (!cmpxchg(&head, (uint32_t)node->next, (uint32_t)node));
}
struct node* pop() {
while (1) {
struct node* node = head;
if (node == NULL) {
return NULL;
}
struct node* next = node->next; // (*)
if (cmpxchg(&head, (uint32_t)node, (uint32_t)next)) {
return node;
}
} }
上述实现存在 bug,假设现在有 CPU1 和 CPU2 同时操作该 LIFO 队列,请给出一个操作序列, 使得最终该队列处于一个不一致的状态,即已经弹出的元素仍然在 LIFO 队列中或者未弹出的元素不在 LIFO 队列中。以下给出了 LIFO 队列的初始状态和第一个操作,请补全能够触发 bug 的操作序列
0) LIFO 队列初始状态: head -> node A -> node B -> node C -> NULL
1)CPU1 开始调用 pop,运行至函数体内 (*) 处,此时有 node = A 和 next = B
2) …
答:
- (20分)理发店理有m位理发师、m把理发椅和n把供等候理发的顾客坐的椅子。理发师按如下 规则理发。
1)理发师为一位顾客理完发后,查看是否有顾客等待,如有则唤醒一位为其理发;如果没有顾 客,理发师便在理发椅上睡觉。
2)一个新顾客到来时,首先查看理发师在干什么,如果理发师在理发椅上睡觉,他必须叫醒理 发师,然后理发师给顾客理发;如果理发师正在理发,则新顾客会在有空椅子可坐时坐下来等 待,否则就会离开。
请回答如下问题:
A) 用管程机制实现理发师问题的正确且高效的同步与互斥活动;要求用类C语言的伪代码实 现,并给出必要的简明代码注释。
B) 请按理发规则的要求,给出测试用例;要求至少给出5种可能情况的测试用例。
答:
monitor barbershop {
int num_waiting;
condition get_cut;
condition barber_asleep;
condition in_chair;
condition cut_done;
Barber routine
barber() {
while (1);
while (num_waiting == 0) {
barber_asleep.wait();
}
customer_waiting.signal();
in_chair.wait();
give_hait_cut();
cut_done.signal();
}
Customer routine
customer () {
if (num_waiting == n) {
return;
}
if (num_waiting == 0) {
barber_asleep.signal();
}
customer_waiting.wait();
in_char.signal();
get_hair_cut();
cut_done.wait();
}
}
- (12分)设lab6中使用Stride调度算法,取BIGSTRIDE=100,假定各个进程的stride初始化为0。 (注:lab6中的stride(32位整数,当前总共走了多少)和pass(32位整数,每一次走多少 pass= BIGSTRIDE/priority, 100>priority>1)的含义和论文原文含义相反)请回答下列问题。
A) 如果不考虑进程stride的值的溢出,那么对于任意两个进程A、B的stride值SA和SB,应当恒有abs(SA-SB) ≤ (__1 __) ,为什么?
B) 考虑到abs(SA-SB)这一性质,假设stride值存在溢出,可将stride值的更新变为: stride = (stride + BIGSTRIDE/priority) mod n
那么,只要n> (__2 __) ,那么stride算法就可以正常运行,为什么?
答:
A)pass_MAX;
B)BIGSTRIDE;














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









