







前言
在数据处理过程中,乱码是常见的一种现象,它归属于编码问题.
编码问题处理不当会导致解析错误和数据丢失的严重后果.文章主要是展示如何用Python的chardet库或Notepad++的使用来解决编码问题.

常见表现
- 乱码 文本数据在屏幕上显示为不可识别的符号、方框、问号等,这是最常见的编码问题表现。乱码通常是由于数据被用错误的编码方式进行解码导致的。
- 数据丢失 某些字符在从一种编码转换为另一种编码时,如果目标编码无法表示源编码中的某些字符,可能会导致这些字符丢失或被替换为其他符号。
- 解析错误 在处理XML、HTML、JSON等结构化文本数据时,由于编码问题可能导致解析器无法正确识别标签、引号、特殊字符等,从而引发解析失败。
原因
- 编码声明与实际不符 文件或数据流在开始处声明的编码与实际存储数据时使用的编码不一致。
- 数据源编码不确定 从网络、数据库、API等获取数据时,如果没有明确的编码信息,且数据中包含非ASCII字符,可能导致编码识别困难或错误。
- 程序内部编码处理不当 在编写代码处理字符串数据时,如果不注意保持编码的一致性,特别是在进行字符串赋值、拼接、读写文件、数据库交互等操作时,容易因忘记显式指定编码而导致问题。
- 操作系统与应用程序编码差异 不同操作系统(如Windows、Linux、macOS)默认的文本文件编码可能不同,若应用程序未做适配,可能导致在不同平台上处理同一数据文件时出现编码问题。
- 数据库连接配置不匹配 数据库连接参数中未正确设置字符集或编码,可能导致从数据库读取或写入数据时发生乱码。
- Web服务与客户端编码不一致 Web服务器、网页模板、HTTP响应头、浏览器等各环节对字符编码的理解和处理不一致,可能导致网页显示乱码。
解决策略
- 明确数据编码 尽可能获取并记录数据源的编码信息。对于文件,可以通过文件头、元数据或创建该文件的软件来推断其编码;对于网络数据,可以从HTTP响应头、API文档等获取编码信息。
- 统一编码 在处理文本数据的整个流程中,包括数据读取、处理、存储、展示等环节,都应使用相同的编码。推荐使用UTF-8作为通用编码,因为它能表示几乎所有的Unicode字符。
- 正确设置编码参数 在打开文件、建立数据库连接、发送HTTP请求等操作时,明确指定正确的编码参数。
- 使用编码检测工具 对于编码未知的文本数据,可以使用如Python的chardet库自动检测其编码。
- 妥善处理字符集转换 在必须进行字符集转换的情况下,确保目标字符集能够完整表示源字符集的所有字符,避免数据丢失。使用专门的字符集转换库(如ICU)来处理复杂的转换逻辑。
- 严谨的编码测试 针对不同的数据源、操作系统、浏览器等环境,进行充分的编码兼容性测试,确保在各种条件下都能正确处理文本数据。
处理流程的步骤
1. 确认问题现象
观察乱码位置 确定乱码出现在哪个环节(如文件、数据库、网页、API响应等)以及具体表现为哪种形式。
收集错误信息 如果有相关的错误提示或异常堆栈信息,将其记录下来,这可能有助于定位问题原因。
2. 分析可能的原因
检查编码声明 对于文件,查看文件头部是否有明确的编码声明(如BOM、XML/HTML的charset属性等);对于网络数据,查阅API文档或HTTP响应头中的Content-Type字段。
评估数据源特性 考虑数据是否可能包含多语言字符、特殊符号等非ASCII字符,以及数据的来源(如操作系统、软件、设备等)可能使用的默认编码。
审查代码逻辑 检查处理文本数据的相关代码,确认是否在读取、处理、存储、展示等各个环节正确设置了编码参数,是否存在字符串拼接、转义等可能导致编码问题的操作。
3. 初步诊断与尝试
试探性修复 根据初步分析,尝试调整相关编码参数,如修改文件打开模式、更新数据库连接设置、添加HTTP请求头等,看看是否能解决问题。
使用编码检测工具 对于编码未知的文件或数据流,可以使用如Python的chardet库自动检测其编码,以此作为线索。
4. 深入排查与验证
创建最小可复现案例 如果问题复杂,尝试简化环境和数据,构建一个能够稳定重现问题的最小示例,以便于针对性地调试和测试。
逐步排除嫌疑因素 按照数据流向,逐一检查各个环节的编码设置和处理逻辑,通过打印中间结果、日志跟踪等方式,定位问题的具体发生点。
模拟数据转换 对于字符集转换问题,可以手动或使用工具模拟数据在不同编码间的转换过程,观察是否有字符丢失或错误转换。
5. 实施解决方案
修正编码参数 根据诊断结果,修正相关代码、配置文件或系统设置中的编码参数。
字符集转换 如果有必要,编写代码实现字符集的正确转换,确保目标编码能够完整表示源编码的所有字符。
更新数据源 如果问题源于数据源编码不规范或不一致,可能需要联系数据提供方,要求他们更新数据编码或提供清晰的编码声明。
6. 验证与回归测试
确认问题解决 在修改后重新运行程序或访问资源,确认乱码问题已得到解决。
全面回归测试 对修改涉及的代码或功能进行全面的回归测试,确保其他相关功能未受影响,编码问题彻底解决。
编写文档或注释 记录下问题的现象、原因、解决方案以及预防措施,便于日后参考和团队知识共享。
chardet库的使用
安装
直接cmd,采用pip库管理包安装好chardet库
pip install chardet==5.2.0支持的编码类型

基本用法
# 1. 获取网页内容
import urllib.request
rawdata = urllib.request.urlopen('http://yahoo.co.jp/').read()
# 2. 获取网页编码
import chardet
res = chardet.detect(rawdata)
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
# 编码有99%的概率为 utf-8编码类型
print(res)高级用法
注:文件较大的时候建议用这个方法,及时的返回检测的结果.
import urllib.request
from chardet.universaldetector import UniversalDetector
# 获取网页编码
usock = urllib.request.urlopen('http://yahoo.co.jp/')
# 创建一个检测器
detector = UniversalDetector()
# 读取网页内容
for line in usock.readlines():
# 将一段内容传入检测器进行分析
detector.feed(line)
# 检测到编码后退出循环
if detector.done: break
# 告诉探测器已无更多输入数据
detector.close()
# 关闭网页
usock.close()
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
# 编码有99%的概率为 utf-8编码类型
print(detector.result)检测多个文件的编码
import glob
from chardet.universaldetector import UniversalDetector
detector = UniversalDetector()
# 使用glob.glob()函数将找到当前目录下所有以.xml结尾的文件
for filename in glob.glob('*.xml'):
print(filename.ljust(60), end='')
# 每次使用前 重置一下检测器: 将检测器的状态恢复到初始状态。
detector.reset()
for line in open(filename, 'rb'):
detector.feed(line)
if detector.done: break
detector.close()
print(detector.result)准确度
注:混合编码的文本存在误判的可能性.
chardet 提供的编码检测结果并非绝对准确,存在误判的可能性。
特别是对短文本或混合编码、非标准编码、自定义编码等情况,检测精度可能降低。
在实际应用中,应结合其他线索(如文件来源、内容特征等)对检测结果进行验证或调整。
Notepad++的使用
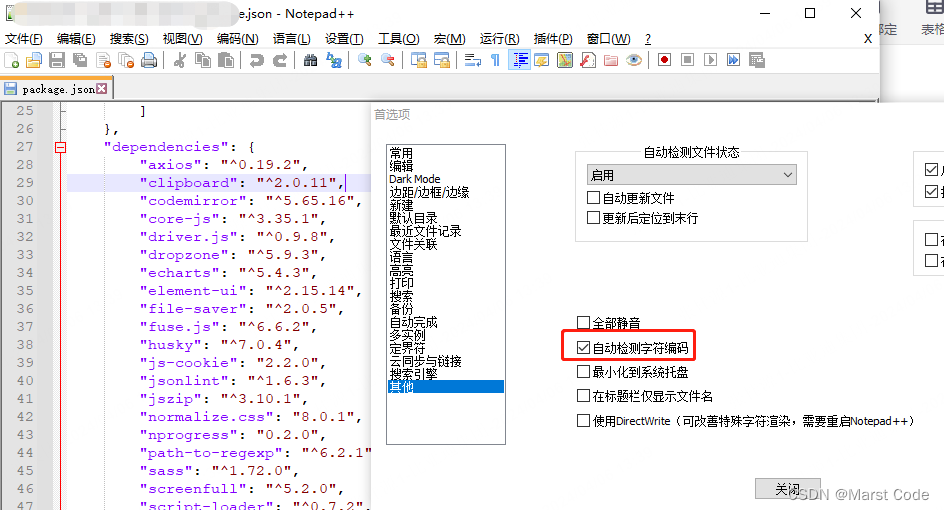
Notepad++是一款文本编辑工具,可以自动检测当前文件的字符编码,
同时,也可以手动另存为其它编码格式.
开启自动检测字符编码
若当前的版本未开启自动检测,可以手动设置
流程: 设置 -> 首选项 -> 其他 -> 自动检测字符编码
转换编码

总结
以下是处理编码问题的关键点
- 明确源编码 尽量从文件的数据来源获取编码信息
- 编码类型 多数据来源时,尽可能统一编码类型为UTF-8
- 文档记录 在项目文档中清晰记录编码相关的决策、约定和实现细节,便于团队成员理解和维护,减少因编码问题引发的协作困扰。
















 2716
2716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











