






Python和Java一样是基于虚拟机的语言,并不是像C/C++那样将程序代码编译成机器语言再运行,而是解释一行执行一行,速度比较慢。使用Numba库的JIT技术编译以后,可以明显提高程序的运行速度。
import numpy as np
from numba import jit
import time
@jit
def sum_jit(arr):
s_time = time.time()
m = arr.shape[0]
result = 0.0
for i in range(m):
result += arr[i]
e_time = time.time()
return (e_time-s_time)
def sum(arr):
s_time = time.time()
m = arr.shape[0]
result = 0.0
for i in range(m):
result += arr[i]
e_time = time.time()
return (e_time-s_time)
def main():
n = int(10.0*1e6)
array = np.random.random(n)
t1 = sum_jit(array)
t2 = sum(array)
print("Time with JIT:", t1)
print("Time without JIT:", t2)
if __name__ == '__main__':
main()上面代码的sum()和sum_jit()两个函数完全相同,区别在于sum_jit()添加了@jit注解,表面该函数使用Numba JIT进行编译以后再运行,而sum()是不编译的运行。对main()中n的值取1×106~10×106,计算每个值两个函数运行的时间,单位为Second,如下图所示:
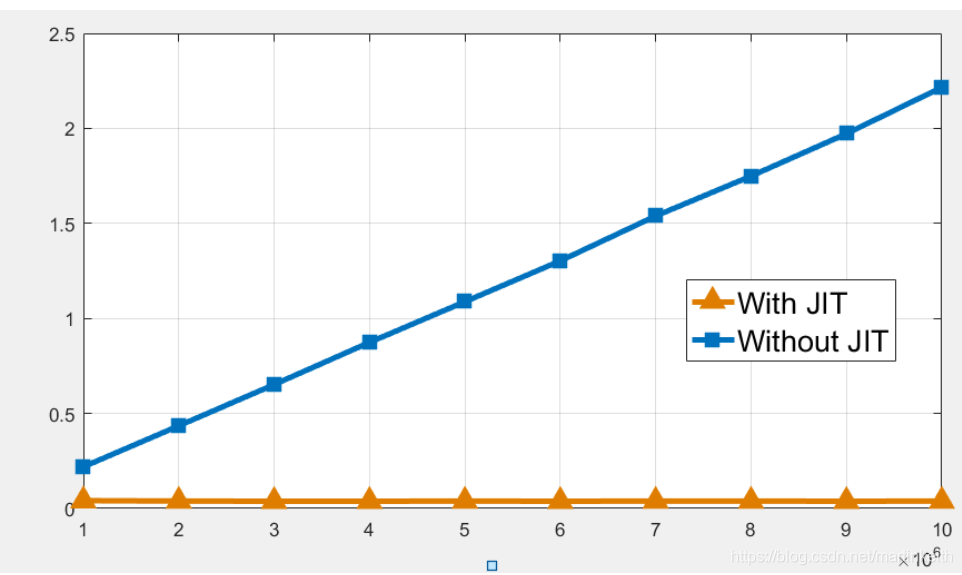
可以看到随着运算量的线性增加,sum()的运行时间几乎也是线性增加的,而sum_jit()的运行时间基本上保持不变,运算量的增加并没有带来影响。
更多numba的加速选项 https://zhuanlan.zhihu.com/p/60994299
除了上面提到的jit和vectorize,其实numba还支持很多加速类型。常见的比如
@nb.jit(nopython=True,fastmath=True) 牺牲一丢丢数学精度来提高速度
@nb.jit(nopython=True,parallel=True) 自动进行并行计算
切记一定要用nopython。默认都是True的,但有时候如果定义的函数中遇到numba支持不良好的部分,它就会自动关闭nopython模式。没有nopython的numba就好像没有武器的士兵,虽然好过没兵,但确实没什么战斗力。因此,在使用jit时候要明确写出nopython=True。如果遇到问题,就找到这些支持不良好的部分,然后改写。毕竟numba对loop非常友好,改写这些部分应当是非常容易的。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









