







在写代码时,一味地堆叠循环,设备性能发挥不出来,从而导致运行时间过长,但是,改写代码又比较痛苦,这时候,使用numba加速代码,一比较方便,性能也能得到质的提升。
对于CPU和GPU的加速方法,可参考
numba的GPU加速注意细节
- 在与numpy配合使用时,只能支持numpy极少数功能;参考
- 不支持复数,可通过向量运算定义复数运算;
- 与数学运算相关的,比如正弦,余弦,exp等函数,都用math包代替,不用numpy。
通过3090Ti加速,速度提升明显,示例
import numpy as np
import numba as nb
from numba import cuda,jit
import math
import time
x = np.linspace(0,1,1000)
y = np.linspace(0,1,1000)
z = 0.15 #传播轴
p = np.zeros([len(x),len(y)])
@cuda.jit
def nb_func(out,data):
# for ii in range(M):
# for jj in range(M):
# j定义为这个thread在所在的block块中的位置(0 <= j <= 999)
jj = cuda.threadIdx.x
# i定义为这个block块在gird中的位置(0 <= i <= 999)
ii = cuda.blockIdx.x
a = x[ii]
b = y[jj]
s = 0
for ri in range(100):
rr = ri/1000.0
for v in range(1000):
v = v/100.0
out[ii,jj]=1
t1 = time.time()
data_device=cuda.to_device(p)
#在GPU里开辟一块空间存放图像数组
out_device=cuda.device_array([1000,1000])
#运行nb_func()函数
nb_func[1000,1000](out_device,data_device)
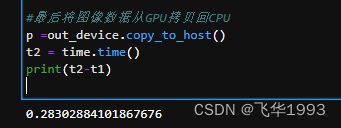
#最后将图像数据从GPU拷贝回CPU
p =out_device.copy_to_host()
t2 = time.time()
print(t2-t1)
可以看到,以上代码相当于4层循环,一共循环1000*1000*1000*100=100亿次,运行时间3秒不到
















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











