







1.Paimon是什么?
Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。Flink 社区内部孵化了 Flink Table Store (简称 FTS )子项目,一个真正面向 Streaming 以及 Realtime的数据湖存储项目。2023年3月12日,FTS进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。

Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
Apache Paimon的官方网站是:Apache Paimon
整体架构:
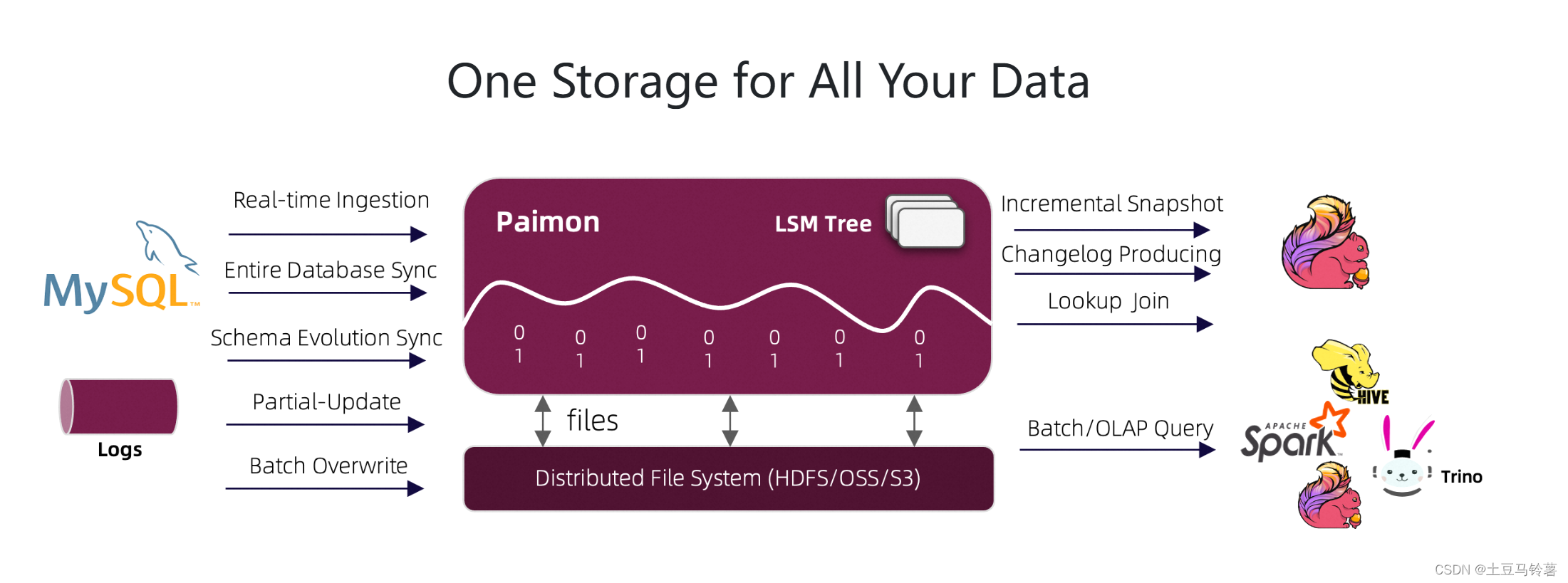
读/写:Paimon 支持多种读/写数据和执行 OLAP 查询的方式。
(1)对于读取,它支持以下方式消费数据
从历史快照(批处理模式)、从最新的偏移量(在流模式下),或以混合方式读取增量快照。
(2)对于写入,它支持来自数据库变更日志(CDC)的流式同步或来自离线数据的批量插入/覆盖。
生态:除了Apache Flink之外,Paimon还支持Apache Hive、Apache Spark、Trino等其他计算引擎的读取。
底层:Paimon 将列式文件存储在文件系统/对象存储上,并使用 LSM 树结构来支持大量数据更新和高性能查询。
统一存储:
对于 Apache Flink 这样的流引擎,通常有三种类型的连接器:
- 消息队列:例如 Apache Kafka,在源阶段和中间阶段都使用它,以保证延迟保持在秒级
- OLAP系统:例如Clickhouse,它以流方式接收处理后的数据并为用户的即席查询提供服务
- 批量存储:例如Apache Hive,它支持传统批处理的各种操作,包括INSERT OVERWRITE
Paimon 提供表抽象。它的使用方式与传统数据库没有什么区别:
- 在批处理执行模式下,它就像一个Hive表,支持Batch SQL的各种操作。查询它以查看最新的快照。
- 在流执行模式下,它的作用就像一个消息队列。查询它的行为就像从历史数据永不过期的消息队列中查询流更改日志。
核心特性
- 统一批处理和流处理:批量写入和读取、流式更新、变更日志生成,全部支持。
- 数据湖能力:低成本、高可靠性、可扩展的元数据。Apache Paimon 具有作为数据湖存储的所有优势。
- 各种合并引擎:按照您喜欢的方式更新记录。保留最后一条记录、进行部分更新或将记录聚合在一起。
- 变更日志生成:Apache Paimon 可以从任何数据源生成正确且完整的变更日志,从而简化流分析。
- 丰富的表类型:除了主键表之外,Apache Paimon还支持append-only表,提供有序的流式读取来替代消息队列。
- 模式演化:Apache Paimon 支持完整的模式演化。可以重命名列并重新排序。
2.Paimon实现原理
基本概念:
Snapshot:
快照捕获表在某个时间点的状态。用户可以通过最新的快照来访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
Partition:
Paimon 采用与 Apache Hive 相同的分区概念来分离数据。分区是一种可选方法,可根据日期、城市和部门等特定列的值将表划分为相关部分。每个表可以有一个或多个分区键来标识特定分区。通过分区,用户可以高效地操作表中的一片记录。如果定义了主键,则分区键必须是主键的子集。
Bucket:
未分区表或分区表中的分区被细分为存储桶,以便为可用于更有效查询的数据提供额外的结构。桶的范围由记录中的一列或多列的哈希值确定。用户可以通过提供bucket-key选项来指定分桶列。如果未指定bucket-key选项,则主键(如果已定义)或完整记录将用作存储桶键。桶是读写的最小存储单元,因此桶的数量限制了最大处理并行度。不过这个数字不应该太大,因为它会导致大量小文件和低读取性能。一般来说,建议每个桶的数据大小为1GB左右。
Consistency Guarantees一致性保证
Paimon writer使用两阶段提交协议以原子方式将一批记录提交到表中。每次提交在提交时最多生成两个快照。对于任意
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









