






Mysql
什么是 SQL?
SQL 是一种结构化查询语言(Structured Query Language),专门用来与数据库打交道,目的是提供一种从数据库中读写数据的简单有效的方法。
Mysql的基本架构与SQL语句的执行过程?
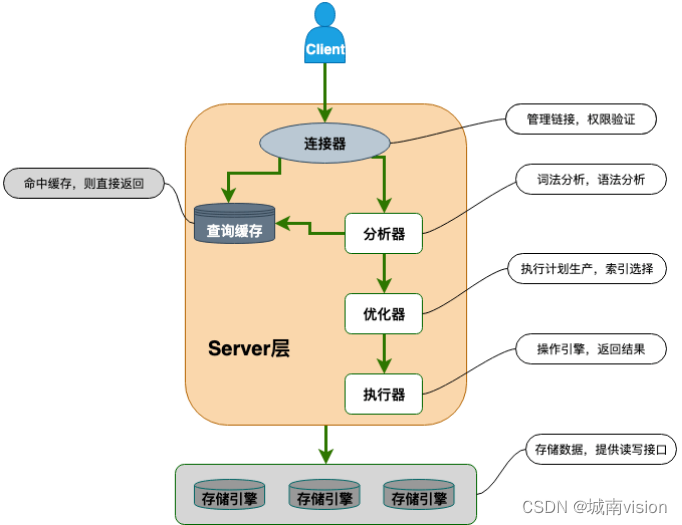
MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。存储引擎:主要负责数据的存储和读取。
查询语句的执行流程如下:权限校验(如果命中缓存)—>查询缓存—>分析器—>优化器—>权限校验—>执行器—>引擎
-
先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
-
通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id=‘1’。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
-
接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
-
进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
更新语句执行流程如下:分析器---->权限校验---->执行器—>引擎—redo log(prepare 状态)—>binlog—>redo log(commit 状态)
Mysql字段类型
MySQL 常用字段类型
数值类型:整型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)、浮点型(FLOAT 和 DOUBLE)、定点型(DECIMAL)
字符串类型:CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB 等,最常用的是 CHAR 和 VARCHAR。
日期时间类型:YEAR、TIME、DATE、DATETIME 和 TIMESTAMP 等。
CHAR 和 VARCHAR 的区别是什么?
两者的主要区别在于:CHAR 是定长字符串,VARCHAR 是变长字符串。
CHAR 在存储时会在右边填充空格以达到指定的长度,检索时会去掉空格;VARCHAR 在存储时需要使用 1 或 2 个额外字节记录字符串的长度,检索时不需要处理。
VARCHAR(100)和 VARCHAR(10)的区别是什么?
1、VARCHAR(100)和 VARCHAR(10)都是变长类型,VARCHAR (100) 可以满足更大范围的字符存储需求。
2、虽说 VARCHAR(100)和 VARCHAR(10)能存储的字符范围不同,但二者存储相同的字符串,所占用磁盘的存储空间其实是一样的。
3、但是VARCHAR(100) 会消耗更多的内存。这是因为 VARCHAR 类型在内存中操作时,通常会使用字符类型中定义的长度来保存值。
DECIMAL 和 FLOAT/DOUBLE 的区别是什么?
DECIMAL 和 FLOAT 的区别是:DECIMAL 是定点数,FLOAT/DOUBLE 是浮点数。DECIMAL 可以存储精确的小数值,FLOAT/DOUBLE 只能存储近似的小数值。
DECIMAL 用于存储具有精度要求的小数,例如与货币相关的数据,可以避免浮点数带来的精度损失。
为什么不推荐使用 TEXT 和 BLOB?
这两种类型具有一些缺点和限制:
- 不能有默认值。
- 在使用临时表时无法使用内存临时表,只能在磁盘上创建临时表。
- 检索效率较低。
DATETIME 和 TIMESTAMP 的区别是什么?
DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
- DATETIME:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
为什么 MySQL 不建议使用 NULL 作为列默认值?
1、Null代表了一个不确定的值,比较的时候比较复杂。
2、Null 列需要更多的存储空间:需要一个额外字节作为判断是否为 NULL 的标志位。
3、对含有NULL值的列进行统计计算,eg. **count()**,**max()**,**min()**,结果比较复杂,并不符合我们的期望值。
4、NULL值到非NULL的更新无法做到原地更新,更容易发生索引分裂,从而影响性能。
Mysql缓存
Mysql查询缓存的优缺点
优点:
1、由于查询缓存是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘 I/O 和 CPU 计算,导致效率非常高。
缺点:
1、缓存查询需要Hash计算,高并发的时候比较耗时
2、查询缓存的失效问题。如果表的变更比较频繁,则会造成查询缓存的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
3、查询语句不同,但查询结果相同的查询都会被缓存,自愿消耗过大。
简单总结一下查询缓存的适用场景
1、表数据修改不频繁、数据较静态,比如博客系统。
2、查询(Select)重复度高。
3、查询结果集小于 1 MB
Mysql事务
Mysql事务的隔离级别
从SQL 标准定义了四个隔离级别的介绍可以看出,标准的 SQL 隔离级别定义里,REPEATABLE-READ(可重复读)是不可以防止幻读的。
但是!InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的,主要有下面两种情况:
快照读:由 MVCC 机制来保证不出现幻读。
当前读:使用 Next-Key Lock 进行加锁来保证不出现幻读,Next-Key Lock 是行锁(Record Lock)和间隙锁(Gap Lock)的结合,行锁只能锁住已经存在的行,为了避免插入新行,需要依赖间隙锁。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 READ-COMMITTED ,但是你要知道的是 InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失。















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









