






虚拟头结点
链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点了。
每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决这个问题。
常用方法:
1、虚拟头结点
2、双指针
#206、反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
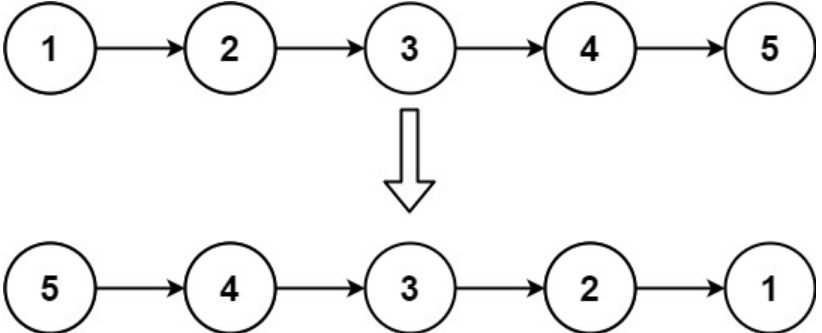
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
采用双指针 头插法
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre =null;
ListNode cur=head;
ListNode tmp=null;//存储下一个结点
while(cur!=null)
{
tmp=cur.next;
cur.next=pre;
pre=cur;
cur=tmp;
}
return pre;
}
}
#24、两两交换链表中的结点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
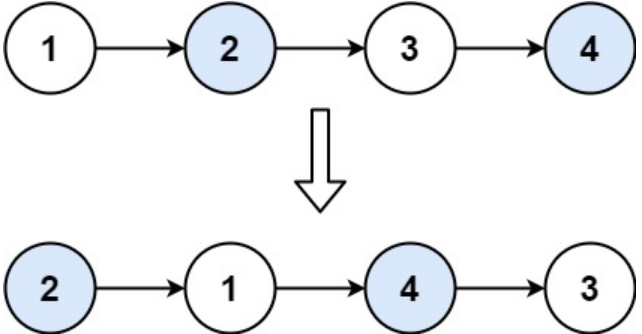
输入:head = [1,2,3,4]
输出:[2,1,4,3]
要使用一个虚拟头结点
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode vhead = new ListNode(-1);
vhead.next=head;
ListNode cur=vhead;
ListNode temp=null; //记录后面的链,防止断链
ListNode firstNode=null;
ListNode secondNode=null;
while(cur.next!=null && cur.next.next!=null)
{
firstNode=cur.next;
secondNode=cur.next.next;
temp=cur.next.next.next;
//交换
cur.next=secondNode;
firstNode.next=temp;
secondNode.next=firstNode;
cur=firstNode;
}
return vhead.next;
}
}
#19、删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
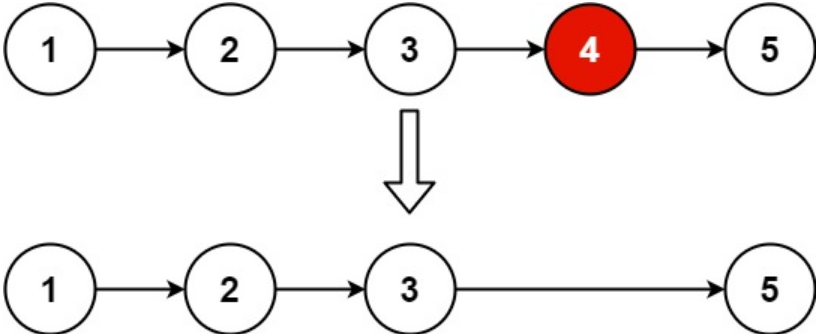
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
当fastIndex指向最后一个结点时,和倒数第n个结点之间有n-1个间隔,所以fastIndex比slowIndex相比,多走了n-1步,由于让slowIndex指向被删除结点的前一个方便删除,因此fastIndex比slowIndex多走n步。
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
//设置一个虚拟结点,方便删除头结点的情况
ListNode vhead =new ListNode(-1);
vhead.next=head;
ListNode slowIndex=vhead;
ListNode fastIndex=vhead;
//fastIndex比slowIndex多走n步
for(int i=0;i<n;i++)
{
fastIndex=fastIndex.next;
}
//让fastIndex指向最后一个结点
while(fastIndex.next!=null)
{
fastIndex=fastIndex.next;
slowIndex=slowIndex.next;
}
//slowIndex指向被删除结点的前一个
slowIndex.next=slowIndex.next.next;
return vhead.next;
}
}
#07、链表相交
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:
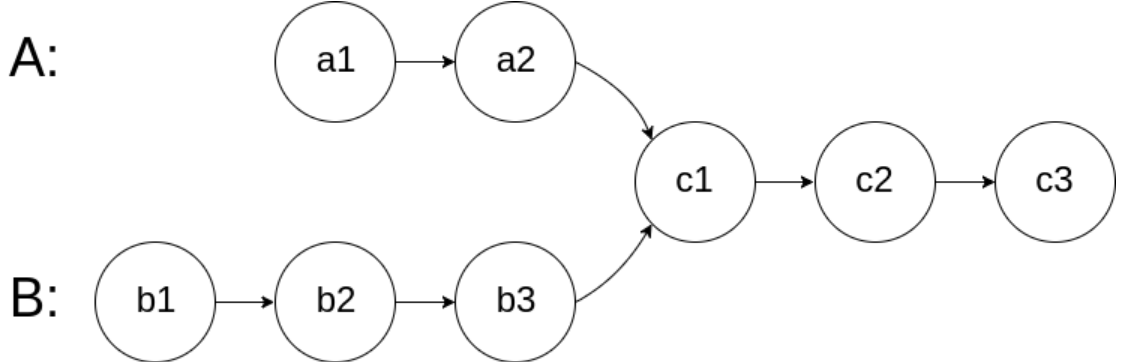
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
先找到长度差,然后移动到距离末尾同一位置处,再一起同时移动
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode curA =headA;
ListNode curB =headB;
int lenA=0;
int lenB=0;
while(curA!=null)
{
lenA++;
curA=curA.next;
}
while(curB!=null)
{
lenB++;
curB=curB.next;
}
curA=headA;
curB=headB;
if(lenA>lenB)
{
int num=lenA-lenB;
for(int i=0;i<num;i++)
{
curA=curA.next;
}
}
else{
int num=lenB-lenA;
for(int i=0;i<num;i++)
{
curB=curB.next;
}
}
while(curA!=curB)
{
curA=curA.next;
curB=curB.next;
}
return curA;
}
}
#142、环形链表二
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
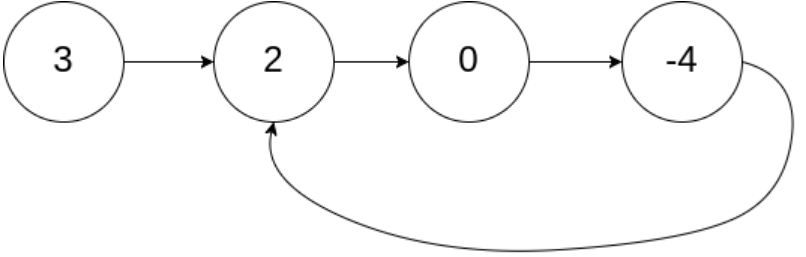
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
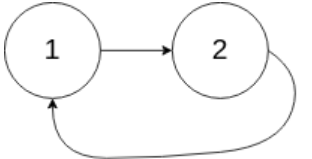
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
1、判断链表是否有环:
可以使用快慢指针法,分别定义 fast 和 slow 指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。因为如果有环,相对slow来说,fast是一步一步靠近slow的,所以一定会相遇,而且是在环中相遇!
2、有环的情况下,如何找到这个环的入口:
此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。 如图所示:
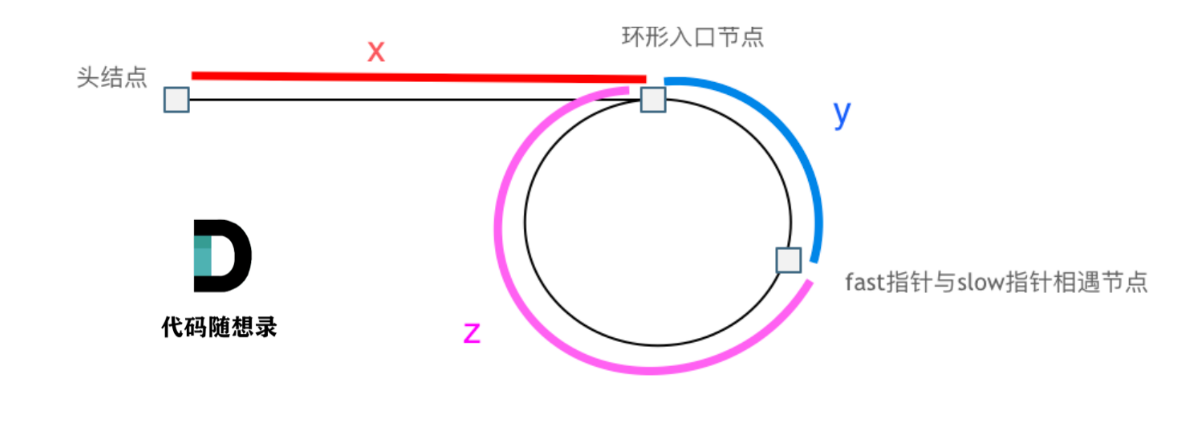
那么相遇时: slow指针走过的节点数为: x + y, fast指针走过的节点数:x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
(x + y) * 2 = x + y + n (y + z)
两边消掉一个(x+y): x + y = n (y + z)
因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:x = n (y + z) - y ,
再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:x = (n - 1) (y + z) + z 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 x = z,
这就意味着,从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
让index1和index2同时移动,每次移动一个节点, 那么他们相遇的地方就是 环形入口的节点。
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast=head;
ListNode slow=head;
while(fast!=null && fast.next!=null) //因为下面会fast.next.next,所以这里要判断fast.next fast跑的快,只需要判断fast就可以
{
slow=slow.next;
fast=fast.next.next; //每次快指针是慢指针的两倍
if(slow==fast) //相遇说明有环
{
ListNode index1 =fast;
ListNode index2 =head;
//从头结点出发一个指针,从相遇节点 也出发一个指针,
//这两个指针每次只走一个节点,
//那么当这两个指针相遇的时候就是 环形入口的节点。
while(index1!=index2)
{
index1=index1.next;
index2=index2.next;
}
return index1;
}
}
return null;
}
}
#25、K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
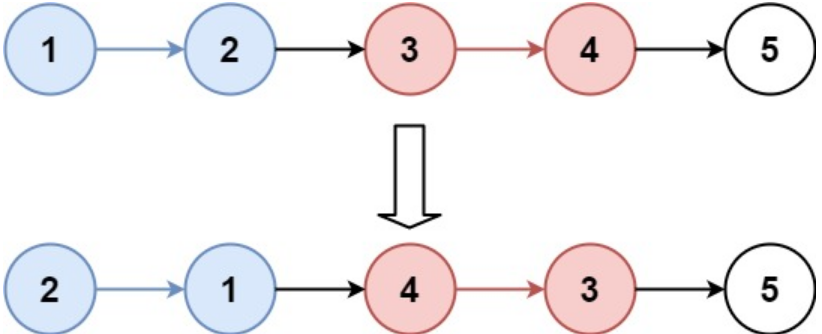
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:
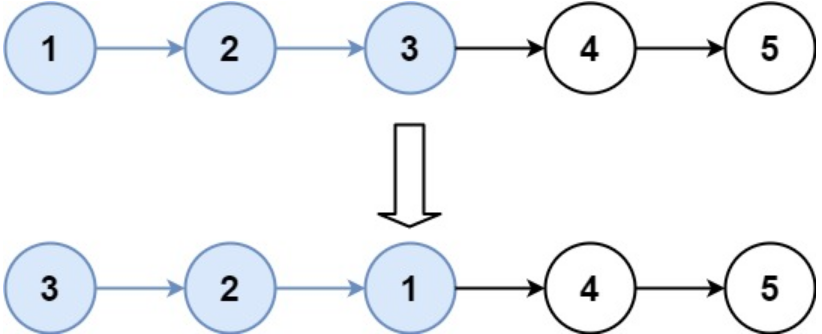
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为 n
- 1 <= k <= n <= 5000
- 0 <= Node.val <= 1000
进阶:你可以设计一个只用 O(1) 额外内存空间的算法解决此问题吗?
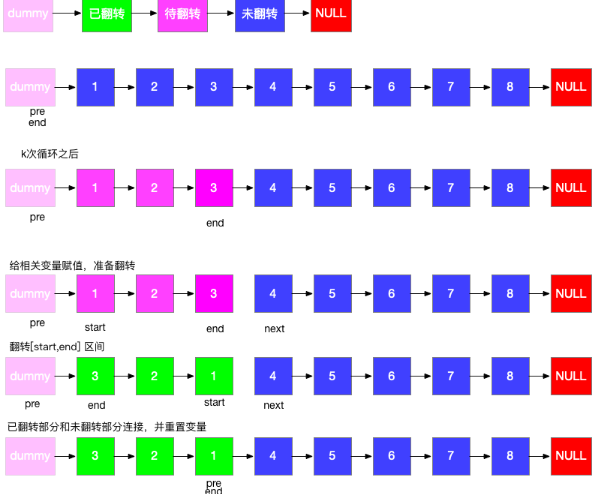
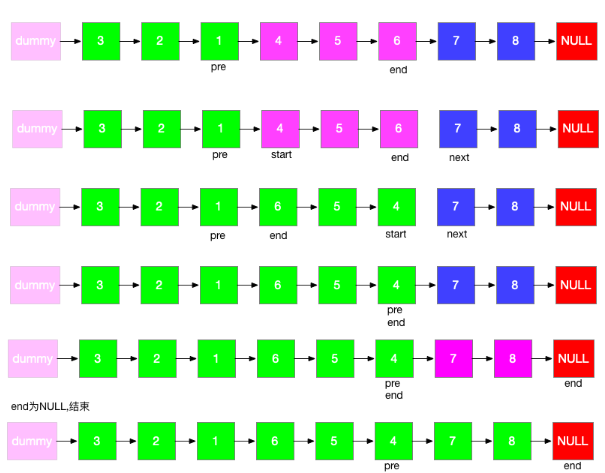
步骤分解:
1、链表分区为已翻转部分+待翻转部分+未翻转部分
2、每次翻转前,要确定翻转链表的范围,这个必须通过 k 此循环来确定。
3、需记录翻转链表前驱和后继,方便翻转完成后把已翻转部分和未翻转部分连接起来
4、初始需要两个变量 pre 和 end,pre 代表待翻转链表的前驱,end 代表待翻转链表的末尾
5、经过k此循环,end 到达末尾,记录待翻转链表的后继 next = end.next
6、翻转链表,然后将三部分链表连接起来,然后重置 pre 和 end 指针,然后进入下一次循环
7、特殊情况,当翻转部分长度不足 k 时,在定位 end 完成后,end==null,已经到达末尾,说明题目已完成,直接返回即可
8、时间复杂度为 O(n∗K),最好的情况为 O(n),最差的情况未 O(n2)
9、空间复杂度为 O(1)O(1)O(1) 除了几个必须的节点指针外,我们并没有占用其他空间
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dummy=new ListNode(0);//头结点
dummy.next=head;
ListNode pre=dummy; //用来记录每组的前一个结点
ListNode end=dummy; //用来找每组的末尾
while(end.next!=null) //当不是末尾元素时
{
for(int i=0;i<k && end!=null;i++) //找到每组的最后一个元素
end=end.next;
if(end==null) //已到达末尾,说明已经结束
break;
ListNode start=pre.next; //每组的第一个
ListNode next=end.next; //下一组的第一个,用来相连接
end.next=null; //让每一组的末尾断开
pre.next=reverse(start); //每一组进行翻转
start.next=next;
pre=start;
end=pre; //pre,end都让其指向下一组的前一个结点
}
return dummy.next;
}
//翻转一个链表,翻转完之后 head是指向尾节点的
public ListNode reverse(ListNode head)
{
ListNode pre=null;
ListNode cur=head;
ListNode temp=null; //用来记录链
while(cur!=null)
{
temp=cur.next;
cur.next=pre;
pre=cur;
cur=temp;
}
return pre;
}
}
#138、随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
- val:一个表示 Node.val 的整数。
- random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
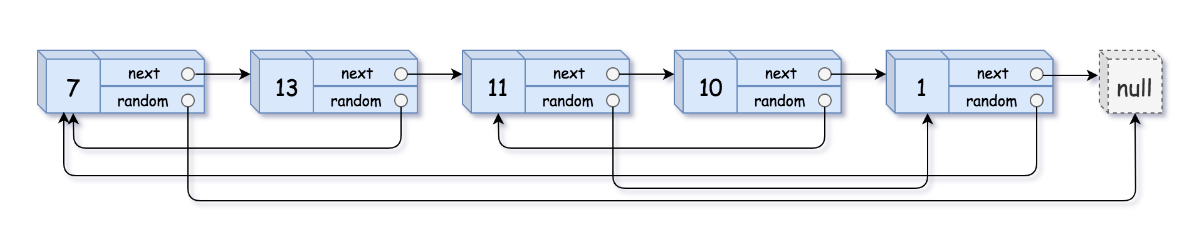
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
思路:
本题要求我们对一个特殊的链表进行深拷贝。如果是普通链表,我们可以直接按照遍历的顺序创建链表节点。而本题中因为随机指针的存在,当我们拷贝节点时,「当前节点的随机指针指向的节点」可能还没创建,因此我们需要变换思路。一个可行方案是,我们利用回溯的方式,让每个节点的拷贝操作相互独立。对于当前节点,我们首先要进行拷贝,然后我们进行「当前节点的后继节点」和「当前节点的随机指针指向的节点」拷贝,拷贝完成后将创建的新节点的指针返回,即可完成当前节点的两指针的赋值。
具体地,我们用哈希表记录每一个节点对应新节点的创建情况。遍历该链表的过程中,我们检查「当前节点的后继节点」和「当前节点的随机指针指向的节点」的创建情况。如果这两个节点中的任何一个节点的新节点没有被创建,我们都立刻递归地进行创建。当我们拷贝完成,回溯到当前层时,我们即可完成当前节点的指针赋值。注意一个节点可能被多个其他节点指向,因此我们可能递归地多次尝试拷贝某个节点,为了防止重复拷贝,我们需要首先检查当前节点是否被拷贝过,如果已经拷贝过,我们可以直接从哈希表中取出拷贝后的节点的指针并返回即可。
在实际代码中,我们需要特别判断给定节点为空节点的情况。
class Solution {
//记录已经复制的结点
Map<Node,Node> cacheNode =new HashMap<>();
public Node copyRandomList(Node head) {
if(head==null)
return null;
//如果此结点没有复制
if(!cacheNode.containsKey(head))
{
Node newhead =new Node(head.val);
cacheNode.put(head,newhead);
newhead.next=copyRandomList(head.next);
newhead.random=copyRandomList(head.random);
}
//已经复制了就返回复制的结点
return cacheNode.get(head);
}
}
#148、排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
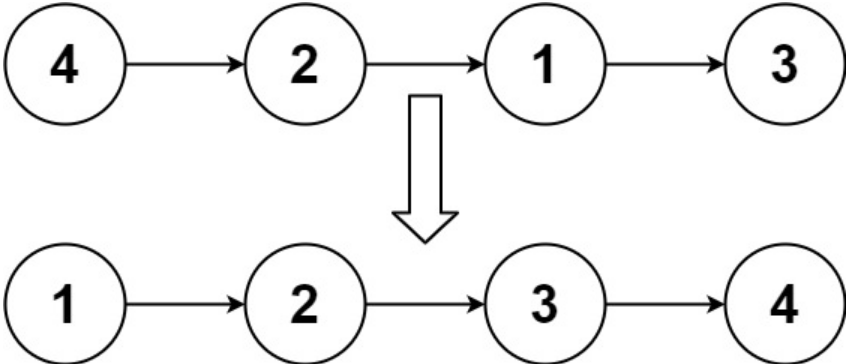
输入:head = [4,2,1,3]
输出:[1,2,3,4]
你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
归并排序的时间复杂度是O(nlogn)

class Solution {
public ListNode sortList(ListNode head) {
if(head==null)
return null;
int length=0;
//得到链表的长度
ListNode cur=head;
while(cur!=null)
{
length++;
cur=cur.next;
}
//建立头结点
ListNode dummy = new ListNode(0);
dummy.next=head;
//控制每次排序的步长,每两组进行合并
for(int subLength=1;subLength<length;subLength*=2)
{
ListNode prev=dummy; //用来连接
ListNode curr=dummy.next; //用来遍历
while(curr!=null)
{
ListNode head1=curr; //第一组的第一个结点
//寻找第一组的末尾,要么是第k个,要么不足k,是最后一个
for(int i=1;i<subLength && curr.next!=null;i++)
{
curr=curr.next;
}
ListNode head2=curr.next; //第二组的第一个结点
curr.next=null; //把第一组的末尾指向空
curr=head2; //第二组的第一个结点可能为null,所以下面要判断
//寻找第二组的末尾,要么是第k个,要么不足k,是最后一个
for(int i=1;i<subLength &&curr!=null &&curr.next!=null;i++) //这里要判断一下curr!=null ,因为curr是有可能等于0的
{
curr=curr.next;
}
ListNode next =null; //记录后面的链
if(curr!=null) //排除curr为null的情况
{
next=curr.next; //记录后面的链
curr.next=null;//第二组的末尾指向空
}
prev.next=merge(head1,head2); //把每两个组合并并和前面的连接起来
while(prev.next!=null)
{
prev=prev.next;
}
curr=next;
}
}
return dummy.next;
}
public ListNode merge(ListNode head1,ListNode head2)
{
ListNode dummy=new ListNode(0);
ListNode temp=dummy,temp1=head1,temp2=head2;
while(temp1!=null && temp2!=null)
{
if(temp1.val<=temp2.val)
{
temp.next=temp1;
temp1=temp1.next;
}
else
{
temp.next=temp2;
temp2=temp2.next;
}
temp=temp.next;
}
if(temp1!=null)
temp.next=temp1;
if(temp2!=null)
temp.next=temp2;
return dummy.next;
}
}
25和148题都是每次取出一定大小的链,进行断链。
#23、合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
顺序合并
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
ListNode ans=null;
for(int i=0;i<lists.length;i++)
{
ans=merge(ans,lists[i]);
}
return ans;
}
public ListNode merge(ListNode head1,ListNode head2)
{
ListNode dummy=new ListNode(0);
ListNode temp=dummy;
ListNode temp1=head1,temp2=head2;
while(temp1!=null && temp2!=null)
{
if(temp1.val<=temp2.val)
{
temp.next=temp1;
temp1=temp1.next;
}
else
{
temp.next=temp2;
temp2=temp2.next;
}
temp=temp.next;
}
if(temp1!=null)
temp.next=temp1;
else if(temp2!=null)
temp.next=temp2;
return dummy.next;
}
}
#146、LRU缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
- LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
思路
使用哈希表+双向链表实现
访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1)时间内完成。
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样可以很方便的对头尾结点进行操作。
class LRUCache {
//定义一个双向链表的结点
class DlinkedNode{
int key;
int value;
DlinkedNode prev;
DlinkedNode next; //前驱和后继
public DlinkedNode(){}
public DlinkedNode(int _key,int _value)
{
key=_key;
value=_value;
}
}
private Map<Integer,DlinkedNode> cache =new HashMap<Integer,DlinkedNode>();
private int size;
private int capacity;
private DlinkedNode head,tail; //虚拟头结点和尾节点
//构造函数
public LRUCache(int capacity) {
this.size=0;
this.capacity=capacity;
head=new DlinkedNode();
tail=new DlinkedNode();
head.next=tail;
tail.prev=head;
}
public int get(int key) {
DlinkedNode node =cache.get(key);
if(node==null)
return -1;
moveToHead(node); //先通过哈希定位,在移动到头部
return node.value;
}
public void put(int key, int value) {
DlinkedNode node=cache.get(key);
if(node==null) //如果不存在,新建一个结点
{
DlinkedNode newNode =new DlinkedNode(key,value);
cache.put(key,newNode);
addTohead(newNode);
size++;
if(size>capacity) //超出容量
{
//删除尾节点
DlinkedNode tail =removeTail();
cache.remove(tail.key); //哈希表中删除对应的项
size--;
}
}
else
{ //如果node存在,修改value后移动到头部
node.value=value;
moveToHead(node);
}
}
//头部添加一个结点
private void addTohead(DlinkedNode node)
{
node.prev=head;
node.next=head.next;
head.next.prev=node;
head.next=node;
}
//移除一个结点
private void removeNode(DlinkedNode node)
{
node.next.prev=node.prev;
node.prev.next=node.next;
}
//把一个结点移动到头部
private void moveToHead(DlinkedNode node)
{
removeNode(node);
addTohead(node);
}
//删除尾部结点
private DlinkedNode removeTail()
{
DlinkedNode res=tail.prev;
removeNode(res);
return res;
}
#234、回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

输入:head = [1,2,2,1]
输出:true
示例 2:
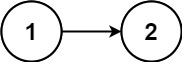
输入:head = [1,2]
输出:false
提示:
- 链表中节点数目在范围[1, 105] 内
- 0 <= Node.val <= 9
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
即用O(n) 时间复杂度和 O(1) 空间复杂度判断链表是否回文。
先找到中间结点,把后半部分翻转,然后逐一判断。
class Solution {
public boolean isPalindrome(ListNode head) {
int len=0;
ListNode cur=head;
while(cur!=null) //统计结点的个数
{
len++;
cur=cur.next;
}
cur=head;
if(len%2==0) //如果结点数为偶数
{
for(int i=1;i<len/2;i++)
{
cur=cur.next;
}
}
else //如果结点数为偶数
{
for(int i=1;i<len/2+1;i++)
{
cur=cur.next;
}
}
//把后半部分翻转
ListNode index1=head;
ListNode index2=reverse(cur.next);
while(index2!=null)
{
if(index1.val!=index2.val)
{
return false;
}
index1=index1.next;
index2=index2.next;
}
return true;
}
public ListNode reverse(ListNode head)
{
ListNode cur=head;
ListNode pre=null;
ListNode tmp=null;
while(cur!=null)
{
tmp=cur.next;
cur.next=pre;
pre=cur;
cur=tmp;
}
return pre;
}
}
#2、两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
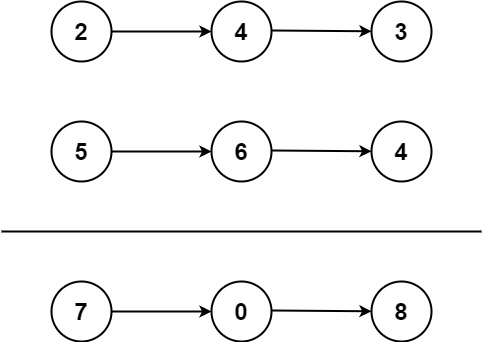
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode pre=new ListNode(0); //头结点
ListNode cur=pre; //可移动的指针,往后遍历,形成链表
int carry=0;
while(l1!=null || l2!=null) //只要有一个不为空就行
{
int x=l1==null?0:l1.val;
int y=l2==null?0:l2.val;
int sum=x+y+carry;
carry=sum/10;
sum=sum%10;
cur.next=new ListNode(sum);
cur=cur.next;
if(l1!=null)
l1=l1.next;
if(l2!=null)
l2=l2.next;
}
if(carry==1) //最后还有一个进位
cur.next=new ListNode(1);
return pre.next;
}
}
双指针法总结
双指针法(快慢指针法): 通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
定义快慢指针
- 快指针:寻找新数组的元素 ,新数组就是不含有目标元素的数组
- 慢指针:指向更新 新数组下标的位置
双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。
数组中的双指针:

链表双指针:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









