






ACPL: Anti-curriculum Pseudo-labelling for Semi-supervised Medical Image Classification(CVPR 2022)
Code is available at https://github.com/FBLADL/ACPL
Abstract
一个有效的应用于医学图像分析的SSL方法必须解决两个挑战:
(1)有效地处理 multi-class(如病变分类)和 multi-label(如多种疾病诊断)问题;
(2)处理 imbalanced learning(因为疾病流行率的高度差异【multi-class 和 multi-label都可能存在类不平衡问题,如下图】)
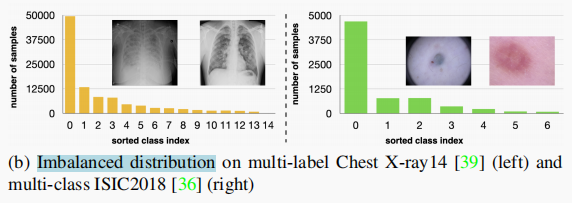
一种应用于半监督医学图像分析的策略是 pseudo labelling ,但是它有一些缺点。pseudo labelling 的准确性一般比 consistency learning 低,它不是专门针对 multi-class 和 multi-label 问题设计的,它可能受到 imbalanced learning 的挑战。在本文中,不像传统的方法根据一个阈值来选择自信的伪标签,我们提出了一个新的半监督学习方法,叫做 anti-curriculum pseudo-labelling (ACPL),它引入了新的技术来选择 informative unlabelled samples,提高了训练的平衡度,使模型可以同时使用于 multi-class 和 multi-label 问题,并通过一个精确的 ensemble of classifiers 来预测伪标签(提高伪标签精度)。
- 数据集:Chest X-Ray14(胸部疾病multi-label分类数据集)、ISIC2018(皮肤病变的multi-class分类)
1. Introduction
State-of-the-art (SOTA) SSL 方法通常是基于 无标签数据的consistency learning、 self-supervised pre-training。尽管基于一致性的方法在 multi-class SSL 问题上达到了SOTA结果,但是 pseudo-labelling 在 multi-label SSL problems 上展现了更好的结果。
Pseudo labelling SSL methods存在的问题:
(1)要进行伪标签标注无标签样本属于 least informative 样本,在 imbalanced 问题中,这些样本很可能是属于 majority classes(样本数较大的类别) 。因此,这将使分类偏向于样本数多的类别,并很有可能恶化 minority classes(样本数少的类别)的分类精度。此外,选择可信的伪标注的样本在多类别问题中具有挑战性,在多标签问题中更具有挑战性。以前的论文对所有类都使用固定的阈值,如果能有一个 class-wise threshold – 可以解决 imbalanced learning 以及多标签问题中类之间的相关性,那么就能实现更准确的伪标签预测。然而,如果不知道类分布,或者我们正在处理多类别或多标签问题,这样的 class-wise threshold 很难估计出来。
(2)使用模型输出进行伪标记过程也会导致确认偏差,分配错误的伪标签将增加模型对这些错误预测的可信度,从而降低了模型的精度。(将错就错?)
在本文中,提出了 anti-curriculum pseudolabelling (ACPL) ,解决了 multi-class 和 multi-label imbalanced learning SSL 医学图像分析问题。
- 首先,我们引入了一种新的方法来选择 the most informative unlabelled images 来进行伪标记。这是受我们 argument(论点?) 的启发,即对于SSL,在 unlabelled and labelled samples 之间存在一个 distribution shift(也就是说在训练过程中,distribution shift会导致学习的策略离想要得到的行为策略越来越远) 。一个有效的 learning curriculum 必须关注于尽可能远离 labelled samples 分布的 informative unlabelled samples 。因此,这些 informative samples 很可能属于医学图形分析中不平衡学习问题中的 minority classes。我们消除了估计 class-wise classification threshold 的需要,并促进我们的模型在多类和多标签问题上更好工作。unlabeled samples 的信息内容度量是用我们提出的 cross-distribution sample informativeness(交叉分布样本信息量) 来计算的,该信息量输出unlabeled samples 与 set of labelled anchor samples(有标签锚定样本集)的接近程度(anchor samples 是highly informative labelled samples)。
- 其次,我们引入了一种新的伪标记机制,称为 informative mixup(信息混合),它将模型分类与在样本信息量指导下的最近邻(KNN)分类相结合,以提高预测精度和减少确认偏差。
- 第三,我们提出了锚定集纯化方法,选择 most informative pseudo-labelled 样本,来包含在 labelled anchor set 中,以提高KNN分类器在后续训练时的伪标记精度。
综上所述,我们的ACPL方法选择了信息量高的样本进行伪标记(解决了MIA不平衡分类问题,允许多标签多类建模),并使用 an ensemble of classifiers 来产生准确的伪标签(解决了确认偏差以提高分类精度)。主要的技术贡献包括:
- 一种新的信息内容度量方法来选择 informative unlabelled samples,即 cross-distribution sample informativeness(CDSI)
- 一个新的叫做 informative mixup(IM) 伪标注机制,它从深度学习和KNN分类器的集合中生成伪标签
- 一种新的方法,称为锚集纯化(anchor set purification,ASP),选择 informative pseudo-labelled 样本,并将它们包含在 labelled anchor set,以提高KNN分类器的伪标记精度
2. Related Work
Pseudo-labelling SSL
pseudo-labelling SSL methods are more accurate for multi-label problems,但是基于之前讨论的它的缺点,本文对此主要解决两个问题:(1)更好地选择 informative unlabeled samples,以解决伪标签倾向于是大多数类标签问题、多类别多标签问题;(2)设计一个精确的伪标注机制,来处理确认偏差
训练样本的选择是根据它们的信息量来的,这已经在全监督 curriculum and anti-curriculum learning 方法中进行了研究。 Curriculum learning:在训练早期关注easy samples,在后期训练中逐步包含hard samples,其中easy samples通常被定义为在训练过程中损失值小的样本, hard samples通常是损失值大的样本; anti-curriculum:首先关注hard samples,在后面的训练中逐渐转移到easy samples。有研究使用Curriculum learning来研究pseudo-labelling SSL 方法,但是还没有人使用anti-curriculum learning来研究SSL方法。因为我们旨在解决不平衡的多标签多类别的SSL问题,我们遵循anti-curriculum learning,即对the most informative samples 进行伪标注,而这些样本很可能就是属于 minority classes(因此,帮助平衡了训练)。另外,使用反课程学习还使得样本的选择不需要评估出一个class-wise classification threshold。【也就是说题目中的 “anti-curriculum” 体现在这里了!!】
3. Methods
3.1. ACPL Optimisation
D
L
D_L
DL : small labelled training set;
D
U
D_U
DU : large unlabelled training set;
D
S
D_S
DS : pseudo-labelled set(对 informative unlabeled samples标注得到的伪标签集合);
D
A
D_A
DA : anchor set(informative labelled sample – 用来跟unlabeled samples计算close程度来度量无标签样本的信息量大小)
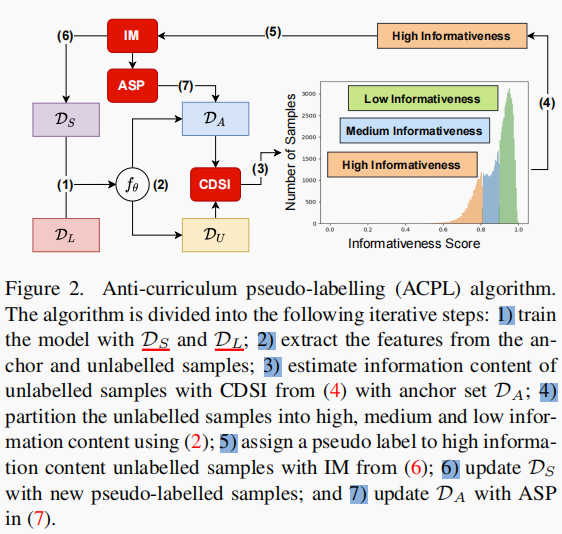
ACPL 算法:

ACPL 框架图:
代价函数cost function:

3.2. Cross Distribution Sample Informativeness (CDSI)
评估一个无标签样本是否具有高信息量根据下式计算:
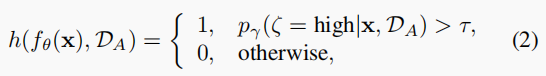
p
γ
p_\gamma
pγ(·) :Gaussian Mixture Model (GMM)
3.3. Informative Mixup (IM)
根据(2)式得到 informative unlabelled samples 后,我们开始为它们产生可靠的伪标签,对于每个无标签样本,我们给它产生两个伪标签:一个是模型预测得到的,另一个是使用 anchor set 的 KNN 的预测。
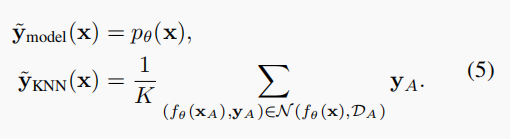
y
A
y_A
yA 是 anchor set 中的样本标签。
单独使用上面的每一个作为伪标签都是有问题的,受MixUp的启发,提出 informative mixup 方法。
3.4. Anchor Set Purification (ASP)
在对informative unlabelled samples估计完伪标签后,我们接下来的目标是用 informative pseudo-labelled samples 更新 anchor set,以在随后的训练阶段保持(4)的准确性。然而,添加所有 pseudo-labelled samples 将导致 anchor set 过大,并增加超参数的sensitivity灵敏度。因此,我们提出 Anchor Set Purification (ASP) 模型来选择连接最少的 pseudo-labeled samples ,并将其插入到 anchor set 中。(如图3所述)
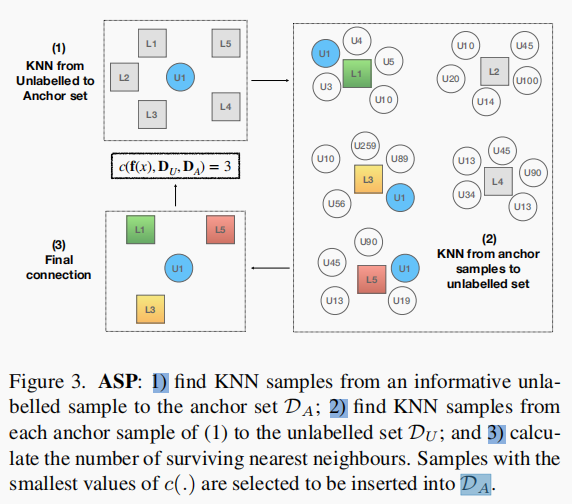
描述:(1)根据anchor set,找到一个 informative unlabeled sample 的k个最邻近样本(这里就是L1、L2、L3、L4、L5);(2)根据unlabeled set 找到1)中来自anchor set 里的 k 个样本的最邻近样本;(3)计算
U
1
U_1
U1 在这5个样本的最近邻样本中出现的次数,这个次数就作为该informative unlabeled sample
U
1
U_1
U1 的信息量大小
c
(
⋅
)
c(·)
c(⋅)。















 1336
1336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









