







查看gc.log
为什么会有promotion fail呢,是因为垃圾回收时,新生代的对象晋升到老年代,但是老年代放不下了,因此会触发这个报错。可以看出来,上一次GC完新生代已使用空间为345M,老年代已使用空间大约3540M,难怪晋升失败。最后一次GC结束,新生代居然还有4.5G的存活对象。
promotion-failed 产生原因:当进行young gc时,由于新生代空间不足,有部分对象无法存放在新生代,需要晋升到old代,但此时old代空间无法容纳此部分promotion对象。看这张图你就明白了,新生代存活对象还4.5G,显然老年代剩余的1.5G也是容不下的。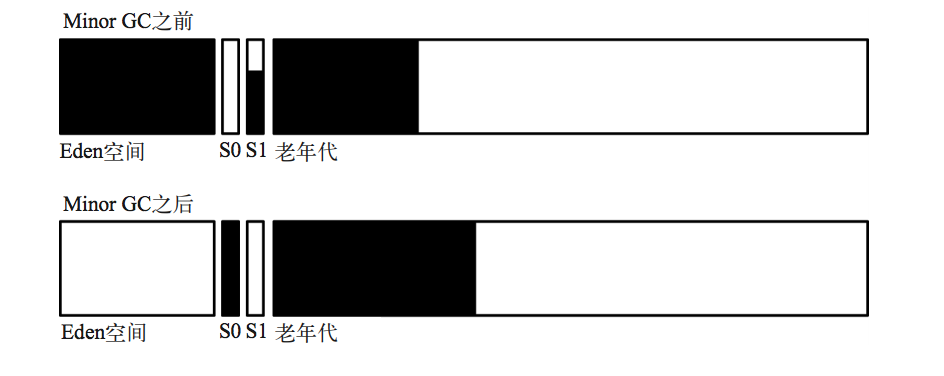
解决办法:
【1】确认下老生代空间是否设置太小
【2】如果老生代空间足够大,有可能是碎片导致,查看碎片参数:-XX:+CMSDumpAtPromotionFailure,如果是碎片导致,可以添加压缩参数,或者定时启动fullGC
【3】如果首次出现,有可能是对象太大,导致新生代和老生代都无法存放。
2019-03-27T01:25:55.597+0800: 639081.684: [GC (Allocation Failure) 2019-03-27T01:25:55.598+0800: 639081.684: [ParNew: 4521549K->340616K(4806016K), 0.1946791 secs] 7864864K->3811697K(10048896K), 0.1955043 secs] [Times: user=0.97 sys=0.28, real=0.19 secs]
2019-03-27T01:26:35.157+0800: 639121.244: [GC (Allocation Failure) 2019-03-27T01:26:35.158+0800: 639121.244: [ParNew: 4709768K->345288K(4806016K), 0.1163715 secs] 8180849K->3892545K(10048896K), 0.1171744 secs] [Times: user=0.75 sys=0.00, real=0.12 secs]
2019-03-27T01:27:27.636+0800: 639173.722: [GC (Allocation Failure) 2019-03-27T01:27:27.636+0800: 639173.723: [ParNew (promotion failed): 4714440K->4558997K(4806016K), 1.6425039 secs]2019-03-27T01:27:29.279+0800: 639175.365: [CMS
^C
查看jvm进程是否还在
ps aux |grep java
查看jvm进程消失的原因
dmesg命令没有找到原因,发现tomcat.log里面还有日志
#
# A fatal error has been detected by the Java Runtime Environment:
#
# SIGSEGV (0xb) at pc=0x00007f1dcf473110, pid=2396, tid=0x00007f1d9d42e700
#
# JRE version: OpenJDK Runtime Environment (8.0_172-b245) (build 1.8.0_172-b245)
# Java VM: OpenJDK 64-Bit Server VM (25.172-b245 mixed mode linux-amd64 compressed oops)
# Problematic frame:
# V [libjvm.so+0x862110] MarkSweep::IsAliveClosure::do_object_b(oopDesc*)+0x10
#
# Core dump written. Default location: /home/admin/rsp-server/target/core or core.2396
#
# An error report file with more information is saved as:
# /home/admin/rsp-server/target/hs_err_pid2396.log
Loaded disassembler from /opt/taobao/install/ajdk-8.5.9_b245/jre/lib/amd64/hsdis-amd64.so
#
# If you would like to submit a bug report, please visit:
# mailto:jvm@list.alibaba-inc.com
#
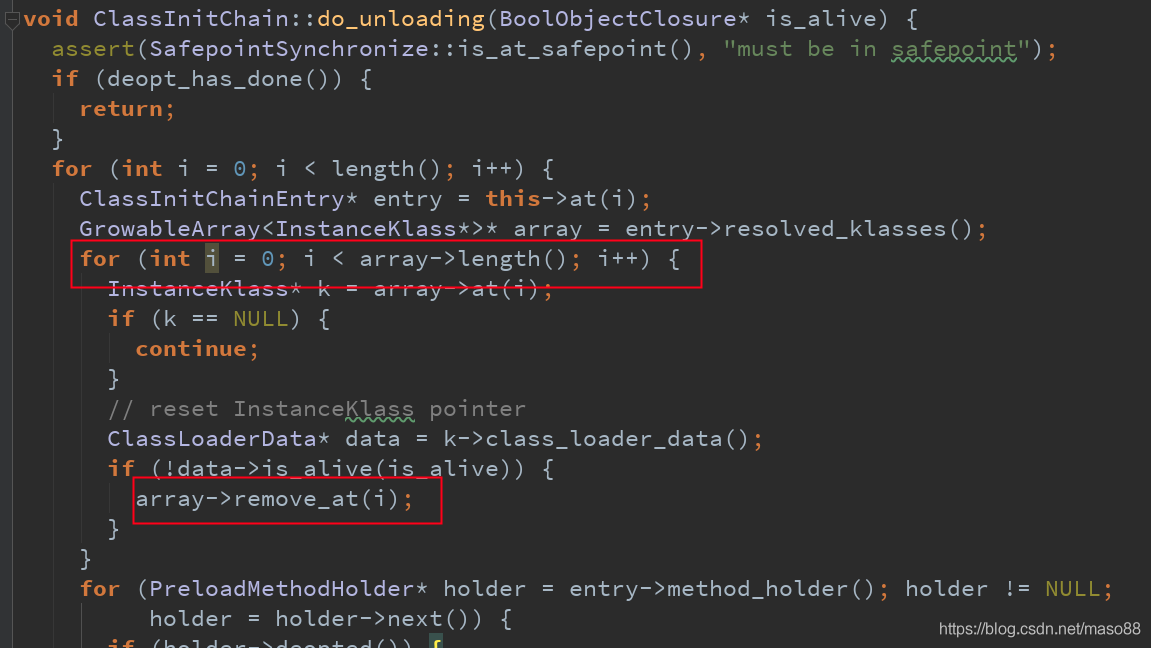
进去这个目录,发现果然有一个文件hs_err_pid2396.log,是当时打印出来的线程堆栈。再看这个stack,最终也是MarkSweep出了问题,第二行的ClassInitChain是warmup中的数据结构,gc在做unloading的时候需要清除warmup数据结构里记录的class信息
Stack: [0x00007f1d9d32f000,0x00007f1d9d42f000], sp=0x00007f1d9d42ce50, free space=1015k
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
V [libjvm.so+0x862110] MarkSweep::IsAliveClosure::do_object_b(oopDesc*)+0x10
V [libjvm.so+0x6b0838] ClassInitChain::do_unloading(BoolObjectClosure*)+0x88
V [libjvm.so+0x45dfa4] ClassLoaderDataGraph::do_unloading(BoolObjectClosure*, bool)+0x1b4
V [libjvm.so+0xa3981c] SystemDictionary::do_unloading(BoolObjectClosure*, bool)+0x1c
V [libjvm.so+0x5efec4] GenMarkSweep::mark_sweep_phase1(int, bool)+0x3a4
V [libjvm.so+0x5f1806] GenMarkSweep::invoke_at_safepoint(int, ReferenceProcessor*, bool)+0x176
V [libjvm.so+0x4de39c] CMSCollector::do_compaction_work(bool)+0x21c
V [libjvm.so+0x4de7c6] CMSCollector::acquire_control_and_collect(bool, bool)+0x156
V [libjvm.so+0x4dec0f] ConcurrentMarkSweepGeneration::collect(bool, bool, unsigned long, bool)+0x8f
V [libjvm.so+0x5eeb38] GenCollectedHeap::do_collection(bool, bool, unsigned long, bool, int)+0x568
V [libjvm.so+0x47ce97] GenCollectorPolicy::satisfy_failed_allocation(unsigned long, bool)+0xf7
V [libjvm.so+0xad6b88] VM_GenCollectForAllocation::doit()+0x98
V [libjvm.so+0xadea32] VM_Operation::evaluate()+0x52
V [libjvm.so+0xadc9f9] VMThread::evaluate_operation(VM_Operation*)+0xa9
V [libjvm.so+0xadd113] VMThread::loop()+0x1c3
V [libjvm.so+0xadd562] VMThread::run()+0x72
V [libjvm.so+0x915b22] java_start(Thread*)+0x122
再看看warmu是怎么卸载类的,里面有个bug,一边遍历一边删除元素。会报错。修改方法,现在不删除,直接设置为NULL。














 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









