







前言:
在内存中存储数据有两种形式:连续的内存、不连续的内存,这就对应了两种数据结构 数组(线性表) 和 链表。
那么我们常说的 队列、栈 都是使用上面两种形式实现的。
Collection(单元素)
├List(有序、可重复)
│ ├LinkedList
│ ├ArrayList
│ └Vector
│ └Stack
└Set(无序、不可重复)
├List(有序、可重复)
│ ├LinkedList
│ ├ArrayList
│ └Vector
│ └Stack
└Set(无序、不可重复)
Map(双元素)
├Hashtable
├HashMap
└WeakHashMap
一、LinkedList
1、
LinkedList基于链表的数据结构。
2、
LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)
3、LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
List list = Collections.synchronizedList(new LinkedList(...));
4、
允许null元素
二、ArrayList
1.ArrayList是实现了基于动态数组的数据结构
2、ArrayList实现了可变大小的数组。
3、ArrayList没有同步。
4、
允许null元素
ArrayList 和 LinkedList 的区别
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
三、Vector
Vector非常类似ArrayList,但是Vector是同步的
四、Stack
Stack
继承自Vector,实现一个后进先出的堆栈
五、HashSet
HashSet
是
无序、不可重复元素 的 collection
HashSet不能添加重复的元素,当调用add(Object)方法时
候,
首先会调用Object的hashCode方法判hashCode是否已经存在,如不存在则直接插入元素 ;
如果已存在则调用Object对象的equals方法判断是否返回true , 如果为true则说明元素已经存 在,如为false则插入元素。
首先会调用Object的hashCode方法判hashCode是否已经存在,如不存在则直接插入元素 ;
如果已存在则调用Object对象的equals方法判断是否返回true , 如果为true则说明元素已经存 在,如为false则插入元素。
六. HashMap的数据结构:
既然数组查询效率高,链表插入删除效率高,于是hashmap就将两者结合在了一块
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
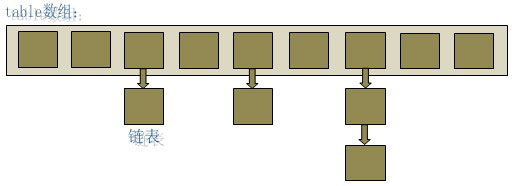
从上图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。
从上图也可以看出 hashcode 和 地址的关系,hashmap添加数据时,先判断hashcode值落在table数组的哪个位置,
如果没有,table数组就加一个空间。如果有相同的hashcode了,就加到该位置下边的链表中。
所以 不同的对象可能会有相同的hash值。
HashMap 中的数据不能排序,原因是 当我们遍历hashmap,他会按照上图先把hashcode排个序,然后依次读出。
hashmap 排序问题请看:
七、Hashtable
HashMap类
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









