






Web基础和HTTP协议
文章目录
一、DNS解析
网络是基于TCP/IP协议进行通信和连接的,每一台主机都有一个唯一的标识,
为了保证网络上每台计算机的IP地址的唯一性,用户必须向特定机构申请注册,分配IP地址网络中的地址方案分为两套,IP地址系统和域名地址系统
/etc/hosts
在没有DNS服务器的情况下,使用本地/etc/hosts完成解析/映射,实现快速访问
/etc/resolv.conf
DNS客户端配置文件,主要用于设置DNS服务器的IP和域名,还包含了主机域名的搜索顺序等等,这个我呢见是由域名解析器使用的配置文件
/etc/sysconfig/network-scripts/ifcfg-ens33
在网卡配置文件中定义DNS1= DNS2=
生效顺序: hosts文件 >> 网卡配置文件 >> /etc/resolv.conf
二、域名的概念
1.定义:标识一组主机并提供它们有关信息的树形结构
2.域名空间结构
- 根域
基础单位,除了根域其他都只有一个上级域
- 顶级域
一般代表一种类型的组织机构或国家地区
- 二级域
用来标明顶级域内的一个特定的组织,国家顶级域下面的二级域名由国家网络部门统一管理
- 子域
子域即为主域下的一个子域名,当一个子域的流量过大时,主域的DNS服务器可以把一个子域的查询授权给一台专门的子域服务器,称为子域授权或子域委派
- 主机
位于域名空间最下层,就是一台具体的计算机,如www、mail、都是具体的计算机名字,可用www.sina.com.cn.来表示
- 域名注册
是Internet中用于解决地址对应问题的一种方法,遵循先申请先注册原则
三、网页
1.网页基本概念
- 网页
纯文件格式文件,编写语言为html
- 网站
有一个一个页面构成的,是多个网页的结合体
- 主页
打开网站后出现的第一个网页称为网站主页
- HTTP/HTTPS
用来传输网页的通信协议,是一种通讯/交互的标准/规范
- URL
是一种万维网寻址系统
- 超链接
是将网站中不同网页链接起来的功能
2.HTML文档结构
| 超文本标记语言 |
|---|
| 浏览器解释和执行HTML源码的工具 |
| HTML文档的结构 |
| HTML网页 |
| 头部部分 |
| 标题部分 |
| 主体部分 |
| 网页内容,包括文本、图像等 |
<html>
<head>
<title>我的第一个网页</title>
</head>
<body>
Hello World!
</body>
</html>
3.Web1.0与Web2.0区别
- web1.0
以编辑为特征,网站提供给用户的内容是编辑处理后的,然后用户阅读网站提供内容,这个过程是网站到用户单向行为
- web2.0
更注重用户的交互作用,用户即是网站消费者,也是网站内容的制造者,加强了网站与用户之间的互动,网站内容基于用户提供网站的诸多功能也由用户参与建设,实现了网站与用户双向的交流与参与,用户分享以兴趣为聚合点的社群开放平台,活跃的用户
4.静态页面和动态页面的区别
- 静态网页特点
每个静态网页都有一个固定的URL,不含有“ ?”,每个静态页面都是保存在服务器上的,静态网页的内容相对稳定,页面浏览速度迅速,无需数据库,但是没有数据库的支持,交互性较差,在功能方面有较大的限制
- 动态页面特点
网页URL不固定,能通过后台与用户交互,在动态网页网址中有一个标志性的符号“ ?”,常用语言有PHP、JSP、Python、Ruby等
四、HTTP协议
http协议是互联网上应用最为广泛的一种网络协议,它是基于TCP协议的应用层传输协议,简单来说就是客户端和服务端进行数据传输的一种规则,设计这个协议的目的是为了发布和接收web服务器上的HTML页面
1.HTTP协议版本
| HTTP0.9 | 已经过时 |
|---|---|
| HTTP1.0 | 目前用的较多* |
| HTTP1.1 | 目前用的较多* |
| HTTP2.0 | 最新 |
2.HTTP1.0和HTTP1.1之间的区别
- 缓存处理
在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略Entitytag,If-Unmodified-Since,If-Match,If-None-Match等更多可供选择的缓存头来控制缓存策略
- 带宽优化及网络连接的使用
HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求引入range头域,它允许只请求资源的某个部分,即返回码是206,这样就方便了开发者自由的选择以便于充分利用带宽和连接
- 错误通知管理
在HTTP1.1中新增了24个错误状态响应码如409表示请求的资源与资源的当前状态发生冲突,410表示服务器上的某个资源被永久性的删除
- Host头处理
在HTTP1.0中认为每台服务器都绑定一个唯一的TP地址,因此请求消息中的RZ并没有传递主机名,但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟机,并且他们共享一个IP地址,HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有inost头域会报告一个错误
长连接
HTTP1.1支持长连接和请求的流水线处理,在一个TCP链接上可以传送多个HTT请求和响应,减少建立关闭连接的消耗和延迟,在HTTP1.1中默认开启connection:keep-alive,一定程度上弥补了HTTP1.0,每次请求都要创建连接的缺点
3.HTTP请求格式
- GET方式
请求行:请求方式——请求资源路径——请求的版本协议号
请求头:
| Accept | 客户端可以接受的数据类型 |
|---|---|
| Accept-Language | 客户端可以接受的语言类型 |
| User-Agent | 浏览器的信息 |
| Accpect-Encoding | 客户端可以接受的编码格式 |
| Host | 表示请求的IP和端口号 |
| Connection | 告诉服务器请求连接如何处理 |
| Keep-Alive | 通知服务器回传数据不要马上关闭, |
| Closed | 马上关闭 |
- POST请求方式
请求行:请求方式——请求资源路径——请求的版本协议号
请求头:
| Accept | 客户端可以接受的数据类型 |
|---|---|
| Accept-Language | 客户端可以接受的语言类型 |
| User-Agent | 浏览器的信息 |
| Content-Type | 发送数据类型 |
| CPntent-Length | 发送数据长度 |
请求体:客户端可以接受的数据类型
简单理解
- GET方法
从指定的服务器上获得数据
GET请求能被缓存
GET请求会保存在浏览器的浏览记录里
GET请求长度的限制
主要用于获取数据
查询的字符串会显示在URL中,不安全
- POST方法
提交数据给指定服务器处理
POST请求不能被缓存
POST请求不会保存在浏览器的浏览记录里
POST请求没有长度限制
查询字符串不会显示在URL中,比较安全
4.HTTP状态码
当使用浏览器访问一个URL,会根据处理情况返回相应的处理状态
| 状态码 | 已定义范围 | 分类 |
|---|---|---|
| 1xx | 100-101 | 信息提示 |
| 2xx | 200-206 | 成功 |
| 3xx | 300-305 | 重定向 |
| 4xx | 400-415 | 客户端错误 |
| 5xx | 500-505 | 服务器错误 |

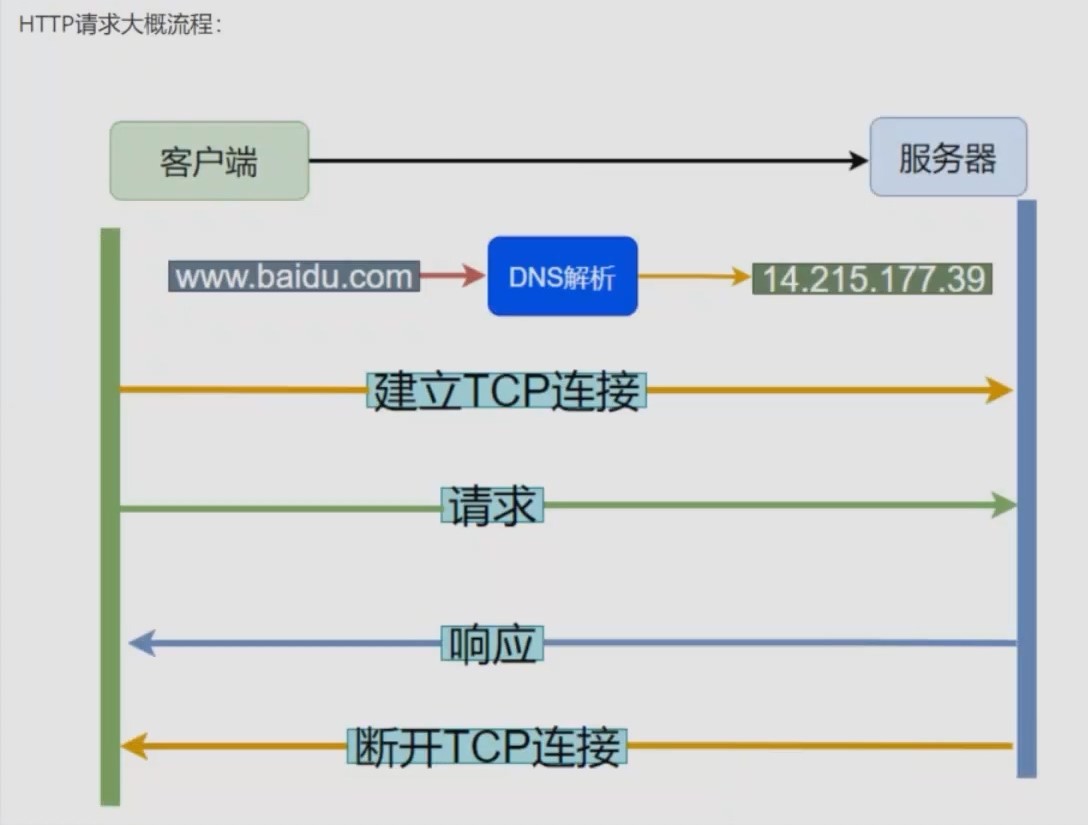
HTTP协议请求流程图


















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











