






数据结构是什么
数据:现实生活中一切可以处理的信息
结构:逻辑结构、存储结构
研究的是数据的逻辑结构,存储结构及其操作。
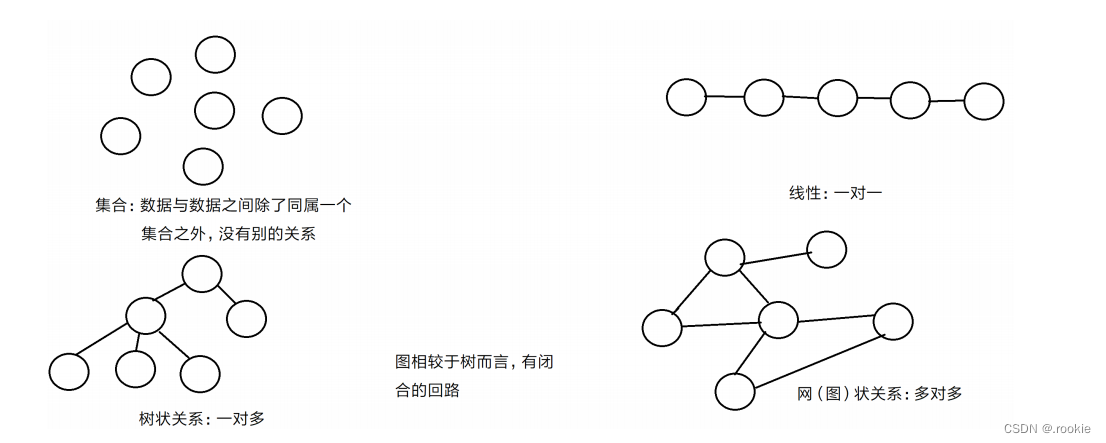
逻辑结构
事物与事物之间在现实生活中的抽象的一种逻辑关系
存储结构
顺序存储:在逻辑上相邻的元素,在物理空间上也相邻
优点:查找方便,
存储空间的利用率可以达到1
缺点:插入和删除不方便,
申请空间的时候,必须是一片连续的空间,对空间的要求比较高
会用空间碎片的产生
链式存储:在逻辑上相邻的元素,在物理空间上不一定相邻
优点:插入元素不需要移动大量的空间
对空间的要求没那么大,
缺点:查找不方便
存储空间的利用率不足1,没有顺序存储的大
索引存储:依据索引表查找数据大概位置,详细查找数据本身(冲突没有解决号的哈希存储)
优点:查找方便
缺点:有索引表的存在,要浪费空间
插入元素,删除元素之后,索引表要更新
哈希存储:根据关键字直接就能定位到记录本身,就能拿到数据
优点:查找方便,插入,删除也方便
缺点:如果哈希函数设计的不合理,查找的效率就会很低
操作
增、删、改、查、创、销
逻辑结构----确定研究对象,把对象的关系抽象出逻辑结构
|
| 把数据存到计算机里面
存储结构----顺序存储、链式存储、索引存储、哈辛存储
|
| 目的是为了程序能运算
操作 ----研究怎么运算,算法
|
| 用某一个语言实现该算法的功能
程序
线性结构
线性结构的顺序存储
顺序表:
学生管理系统:
typedef struct student
{
char name[20];
char id[20];
char add[20];
}data_type;
图书馆的书籍管理系统
typedef struct book
{
char name[20];
char id[20];
char add[20];
}data_type;
特点:
1.逻辑上相邻的元素,在物理空间上也相邻===》空间连续
2.大小固定
3.表满不能存,表空不能取
特点1和特点2
#define SIZE (10)
typedef struct list
{
data_type data[SIZE]; //struct student arr[];//存储空间
int count; //用来指示当前存储多少元素了
}List;
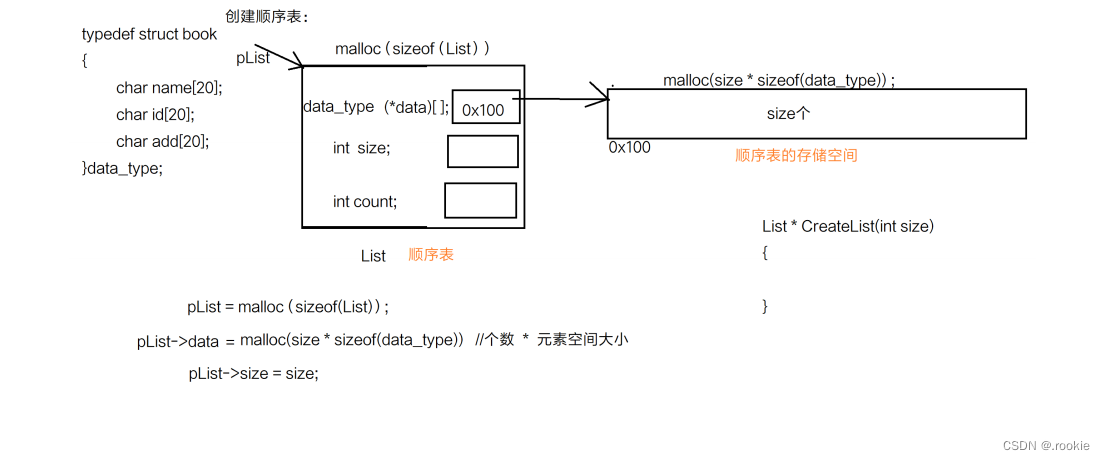
typedef struct list
{
data_type (*data)[]; //指向数组的指针 数组:顺序表的存储空间
int size; //当前顺序表有多大的空间
int count; //用来指示当前存储了多少元素 表满:count == size
}List;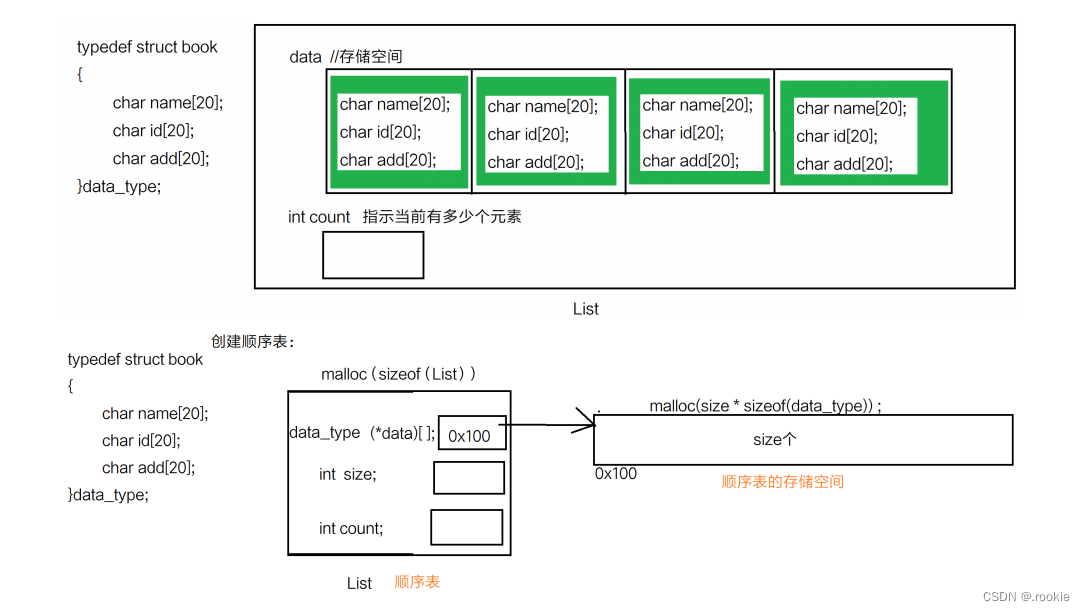
顺序表的创建
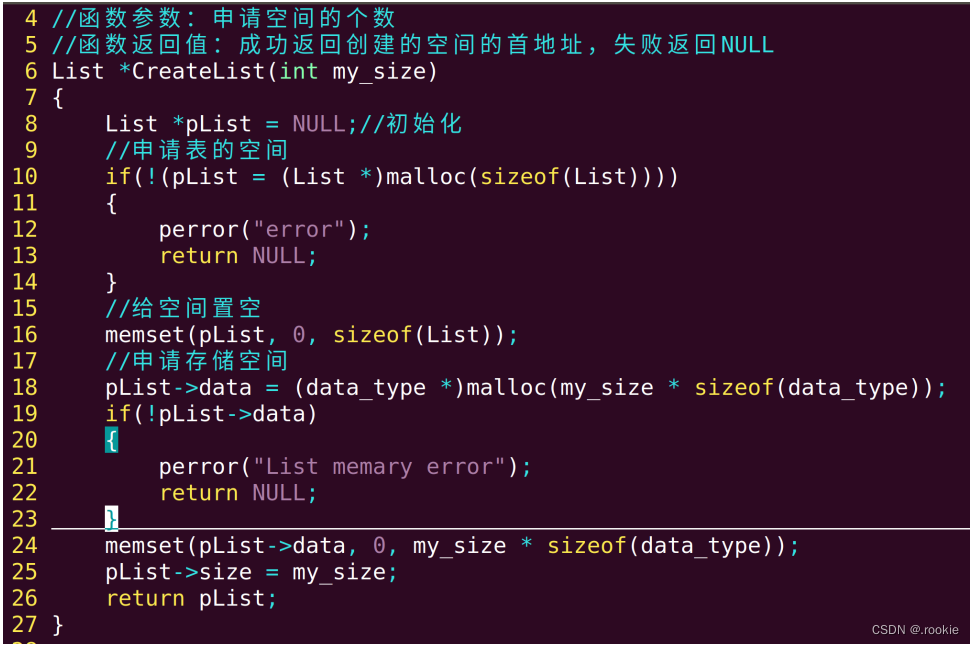
插入元素
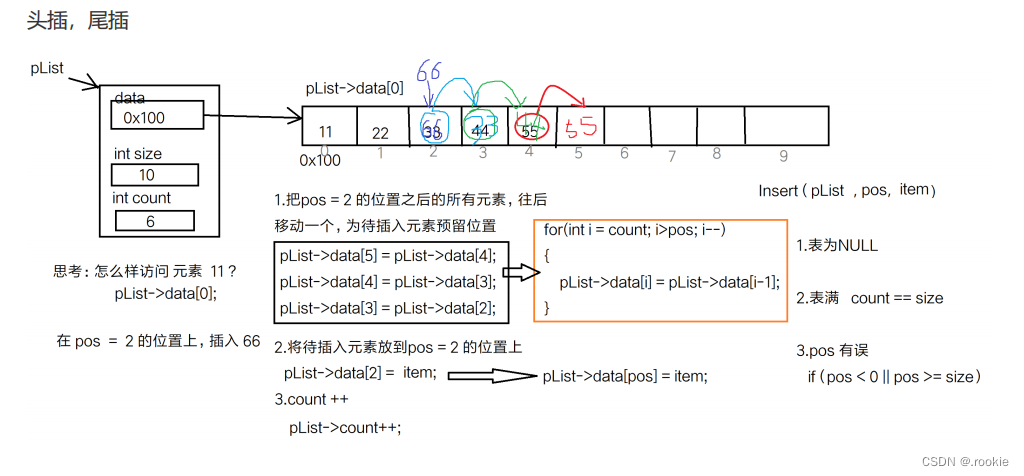
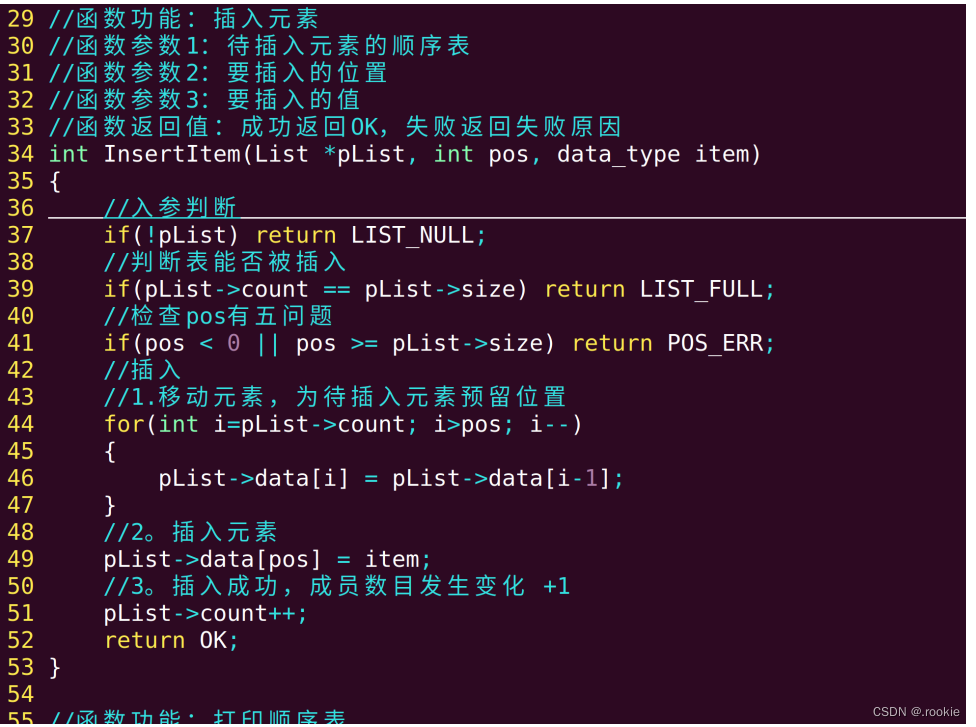
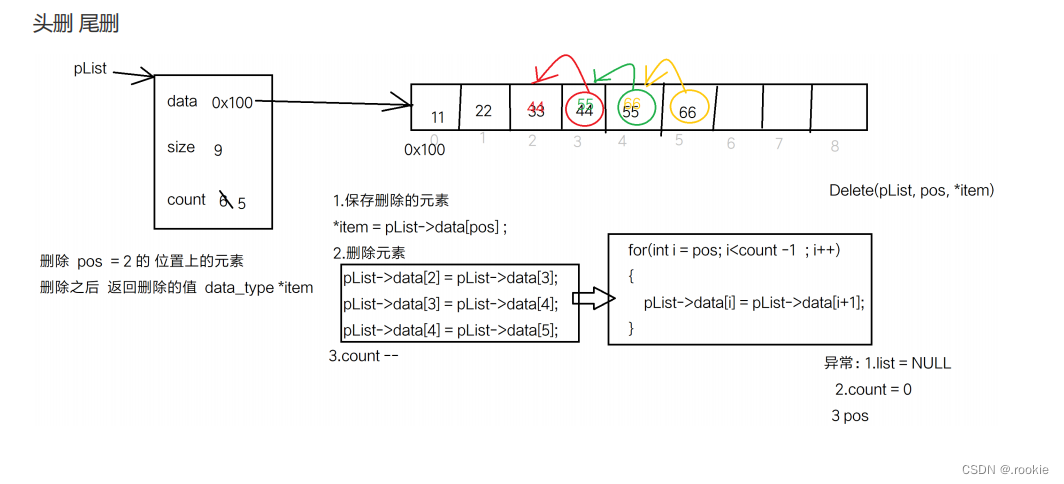
删除元素

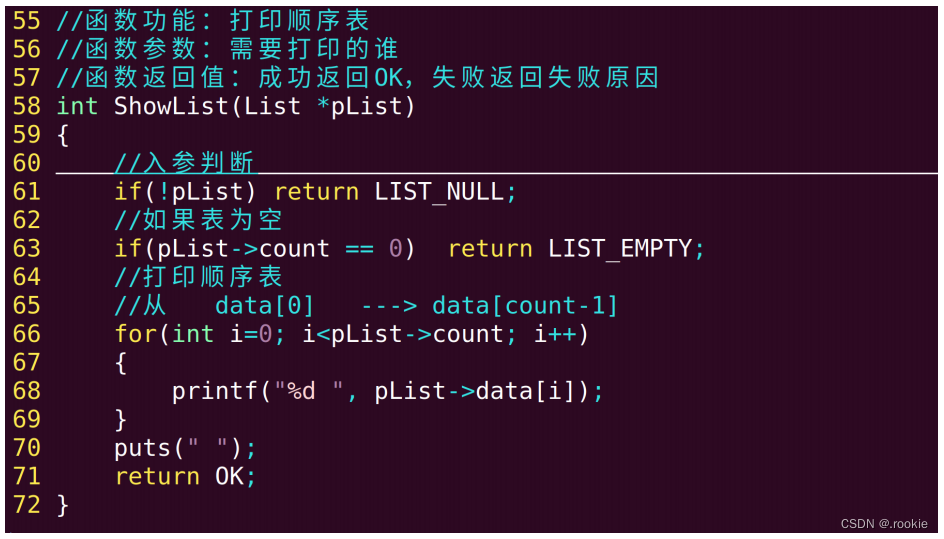
显示元素
销毁
释放空间

导入步骤
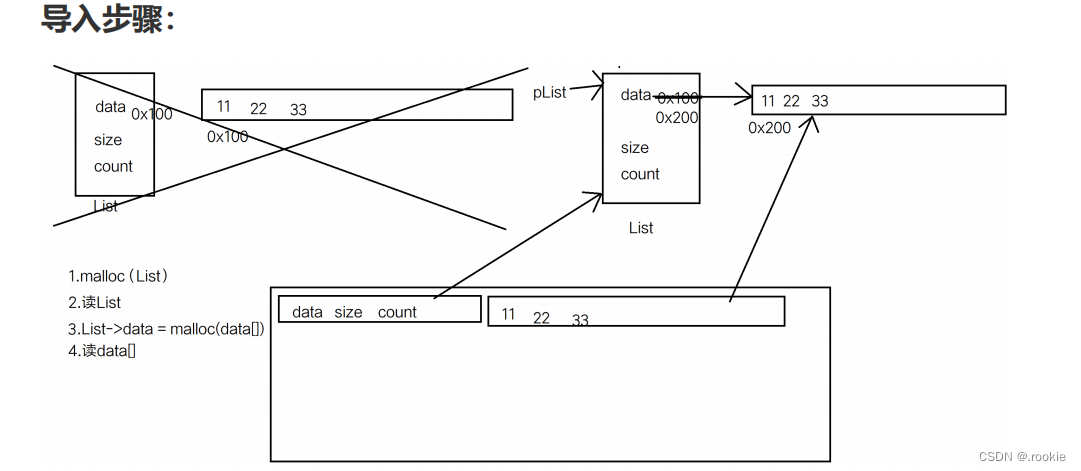
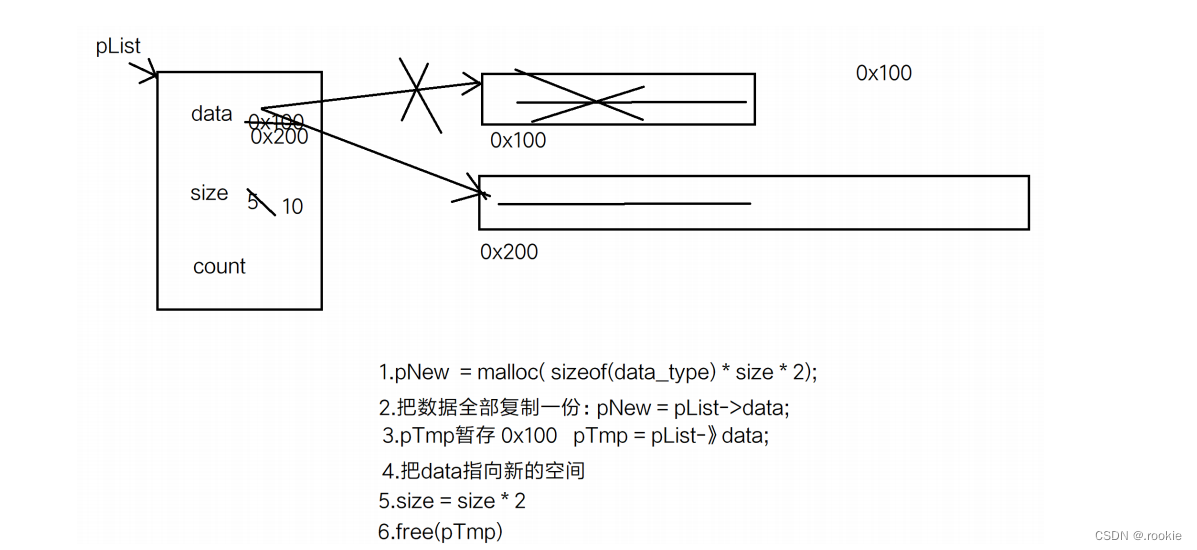
顺序表的扩容
线性结构的链式存储
链表的分类:
按方向分:单链表、双链表
按是否循环分:循环链表,不循环链表
按是否带头节点:带头结点的链表,不带头结点的链表
带头结点的不循环单链表
认识链表
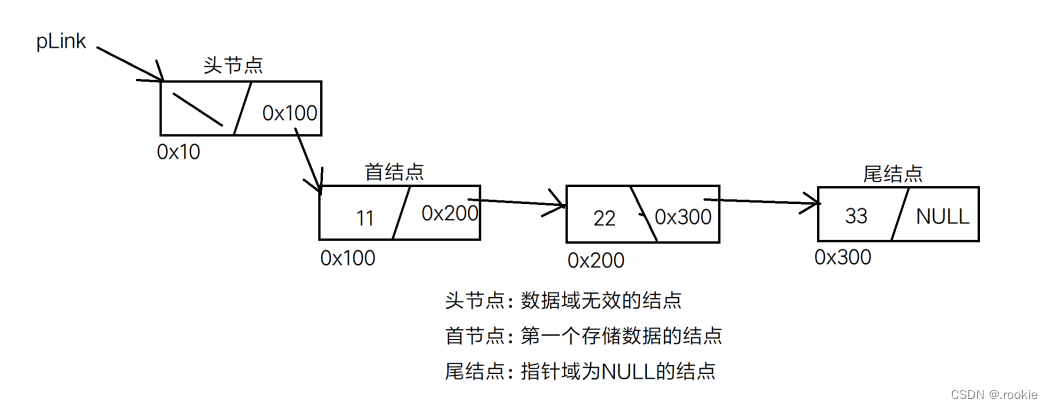
结点定义
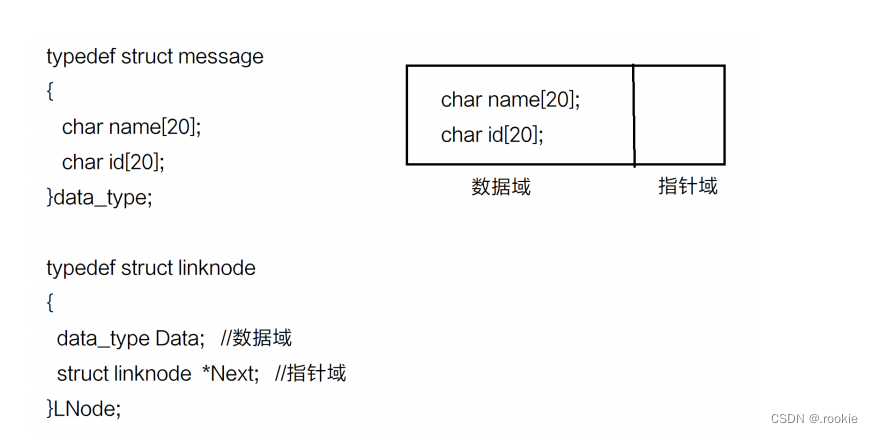
创建链表
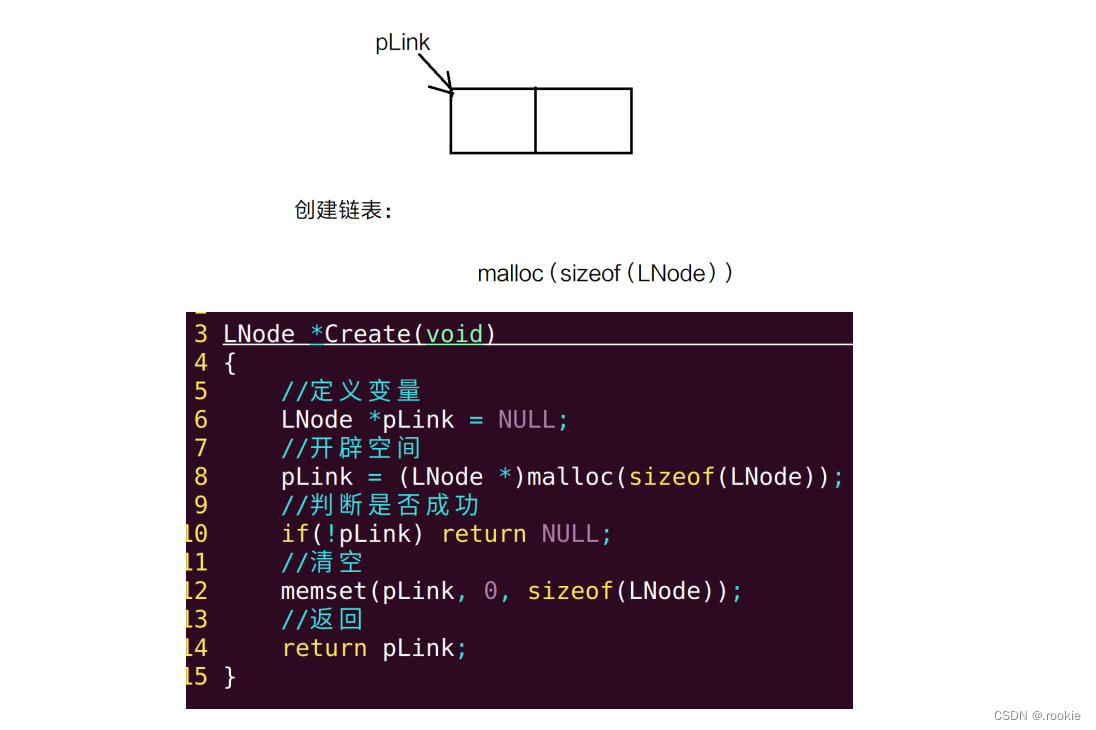
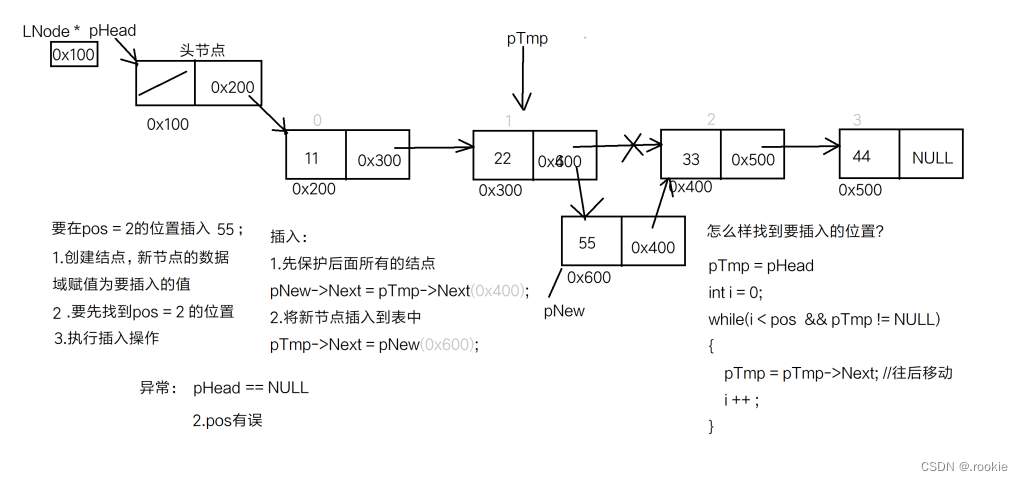
插入结点
显示链表
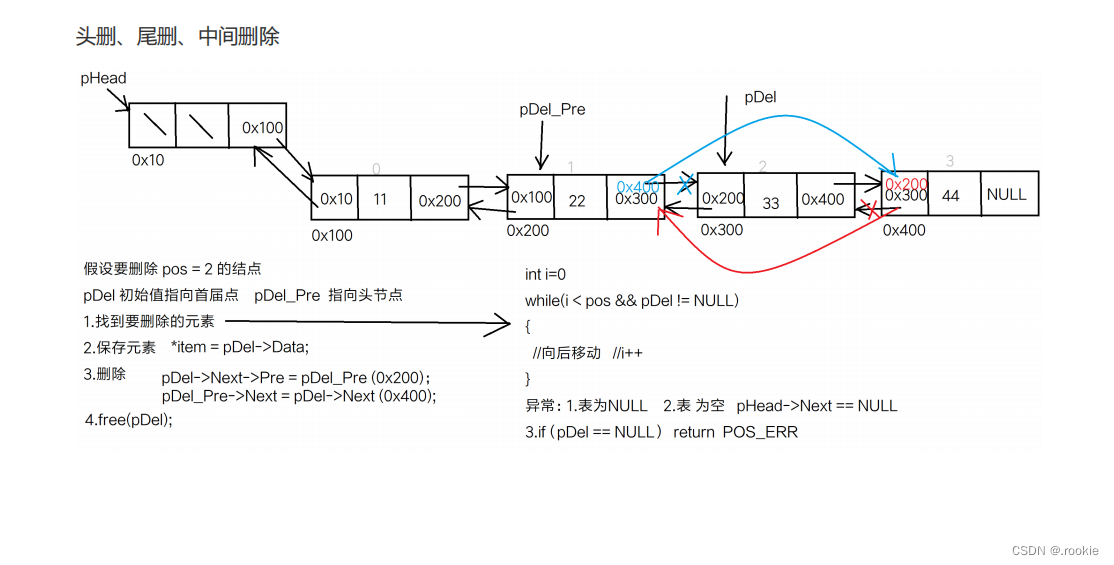
给链表删除元素
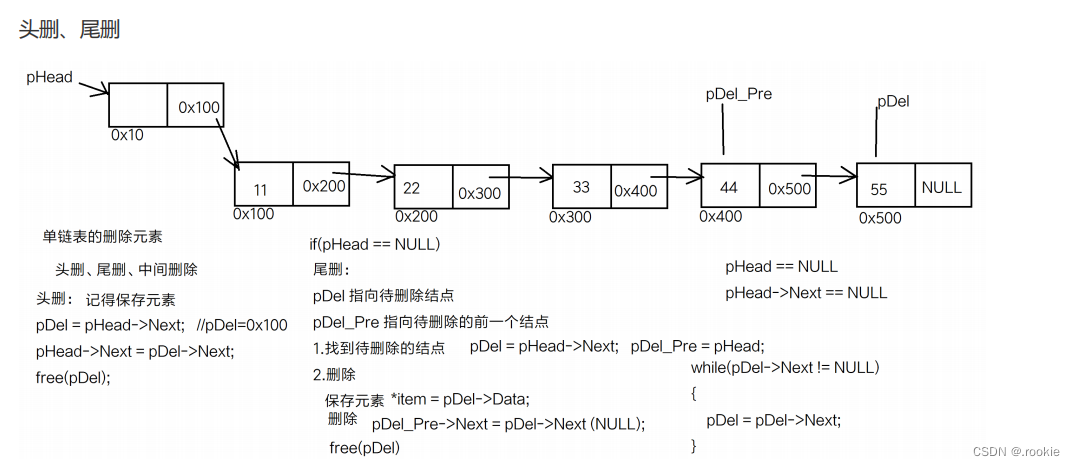
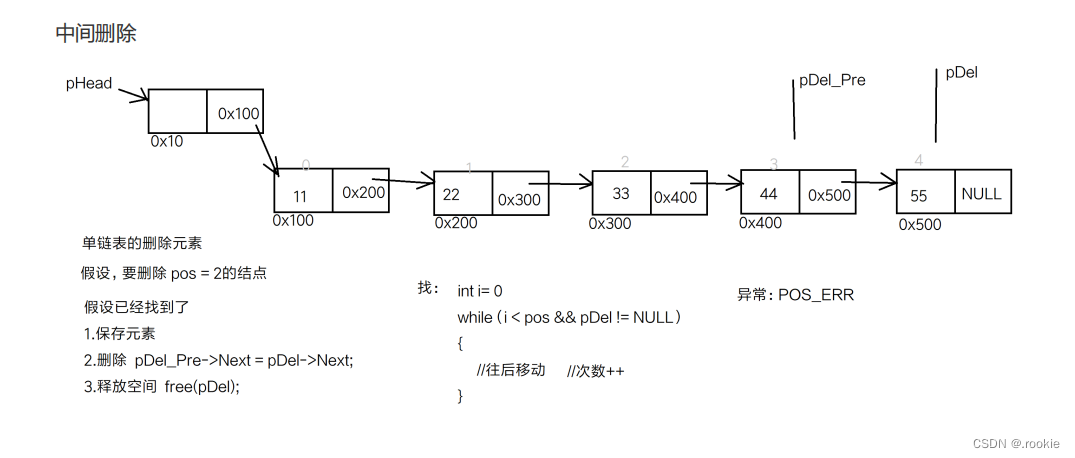
销毁单链表
按找头删、尾删的原则,把所有的数据节点全部删除(free)
当只剩下头节点的时候再释放头节点
逆置一个单链表
栈
对原来的单链表采用头删,对新链表采用头插
循环单链表
在循环链表下:尾结点的Next指向头节点

双链表
带头结点的不循环双链表
双链表表结点的定义

双链表的创建
双链表的插入元素
头插、尾插、中间插入
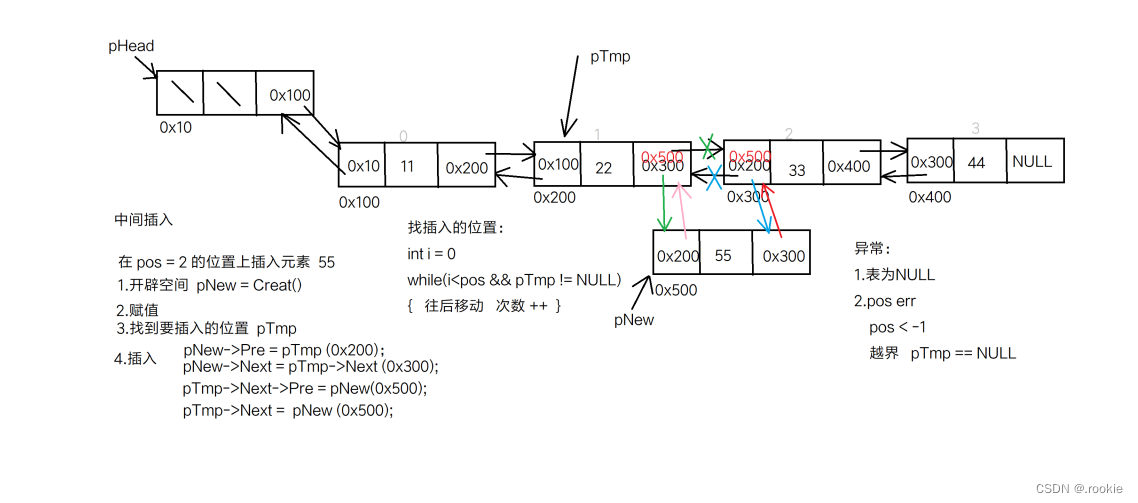
双链表的删除元素
双链表的显示
线性表,链表,顺序表之间的区别?
线性表是一种逻辑结构
顺序表和链表是线性表在顺序存储下和链式存储下的体现
链表和顺序表的区别:
1.链表是链式存储,顺序表是顺序存储
2.顺序表会有空间碎片产生,链表没有空间碎片产生
3.链表一般多用于插入、删除较多的场景
顺序表一般用于查找较多的场景
4.顺序表的存储空间利用率比链表的大
链表和顺序表怎么选择?
1.从空间来说
顺序表对空间的要求比链表大
顺序表的利用率比链表大
2.从操作来说
多用于查找,用顺序表
多用于插入、删除,用链表
3.从编译环境来说
不支持指针类型操作的编译器不能使用链表
编译器不支持使用指针类型操作,场景又是多插入、删除操作
使用静态链表,本质是二维数组
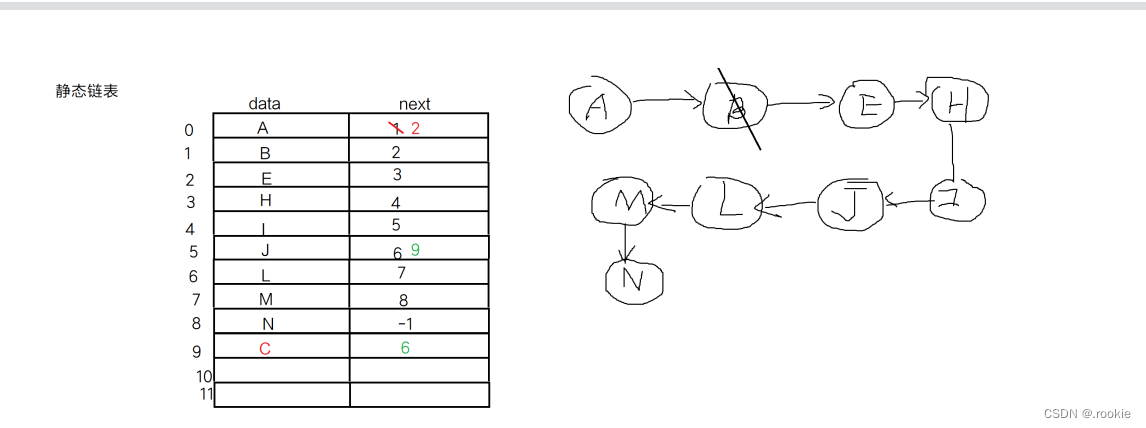
受限的线性表
栈:受限在了操作上
只允许数据在一段进行插入和删除操作,允许操作的一段叫做栈顶
特点:先进后出(FILO)
队列:受限在了操作上
只允许在一段执行插入操作,另一端执行删除操作,允许插入的一段叫做队尾,允许删除操作的一段叫做队头
特点:先进先出(FIFO)
串:受限在了存储上
只允许存储字符 * ' a — 1
栈
顺序存储
和顺序表相同
栈的定义:
//1.存储空间连续
//2.大小固定
//3.表满不能存,表空不能取
//4.只允许在一段(栈顶)进行插入删除操作
入栈和出栈

打印栈
//函数功能:显示栈
//函数参数:需要显示的栈
//函数返回值:成功返回OK,失败返回失败原因
int ShowItem(Stack *pStack)
{
//入参判断
//能否打印
//从i=0打印到i=top-1
return OK;
}链式存储
线性表的链式存储是一样的
头是栈顶:头插、头删
尾是栈顶:尾插、尾删
操作的时候一般选择头作为操作
共享栈:
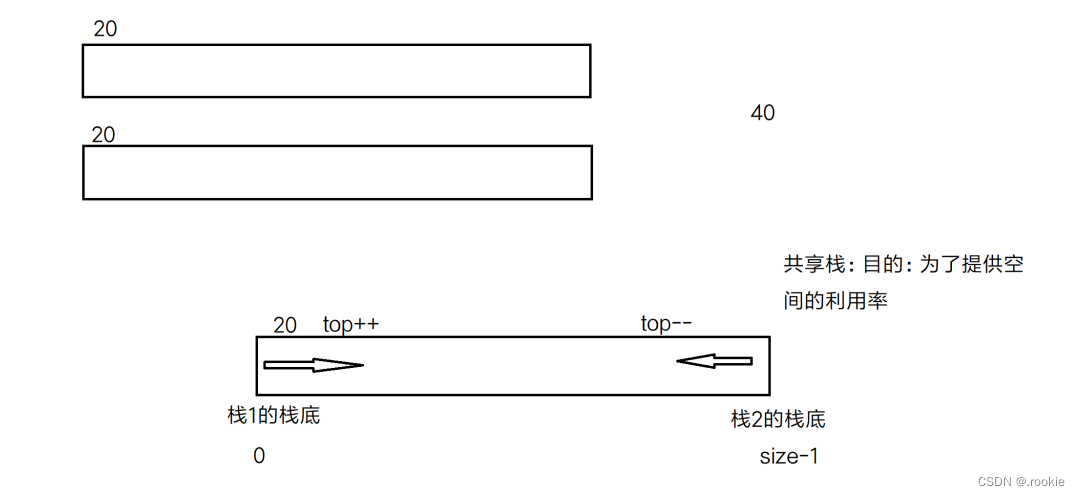
队列
顺序存储
队列的定义
//定义大小
#define SIZE (10)
//定义数据类型
typedef int data_type;
//栈的定义
typedef struct stack
{
data_type data[SIZE]; //存储空间
//只能在栈顶进行操作
int top; //指示栈顶
}Stack;
//队列的定义
typedef struct queue
{
data_type data[SIZE]; //存储空间
//在队尾插入、队头删除
int tail; //指示队尾
int head; //指示队头
}Queue;队列的创建

队列入队出队
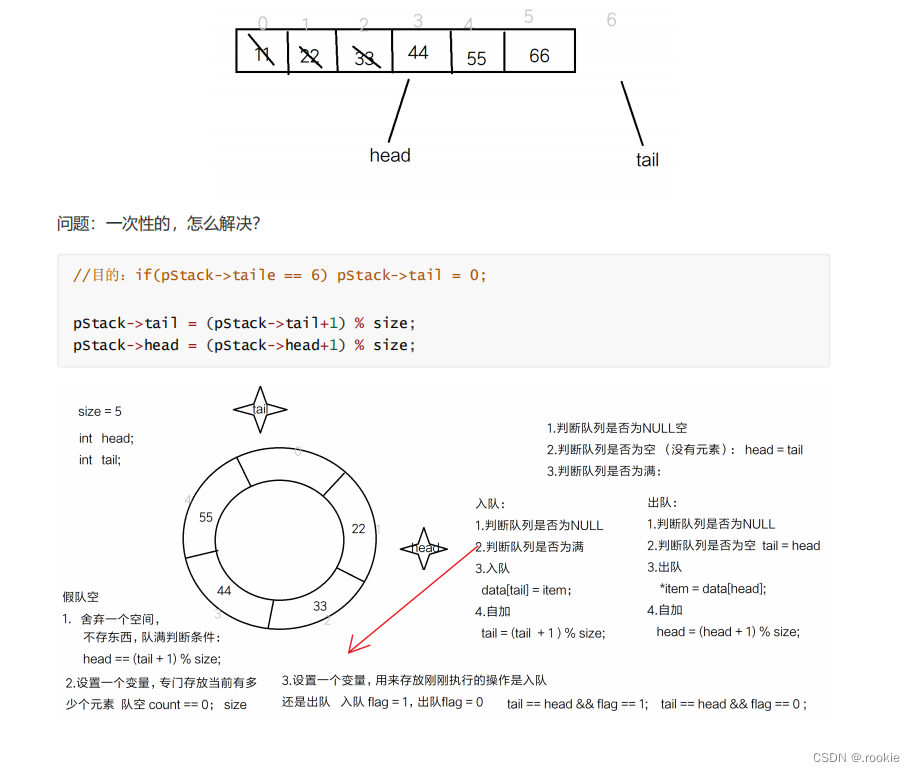
循环队列
避免假队空的方法:1. 舍弃一片空间 head = (tail+1)%SIZE2. 另外设置一个变量 count == SIZE;3. 设置标志位记录上次执行的操作是入队还是出队 head == tail && flag == 1
链式存储
对链表限制住了插入和删除的位置
双端队列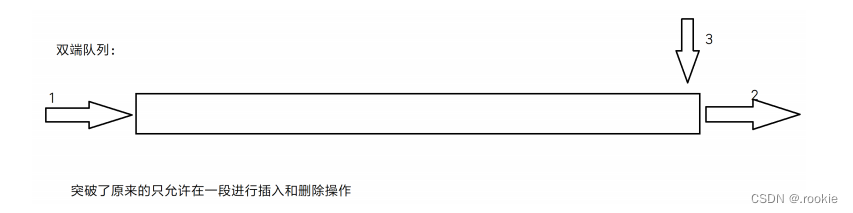
栈的应用
树形结构
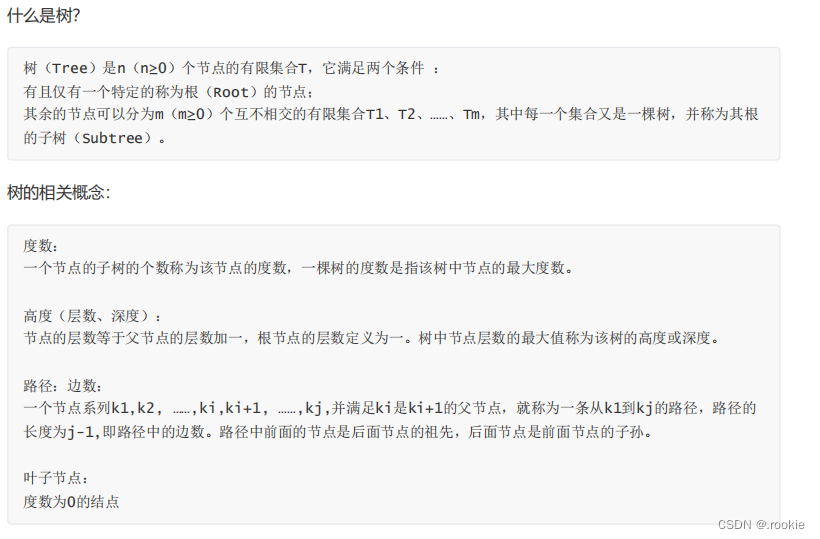
二叉树


满二叉树:有k层,恰好有2 k -1个结点
完全二叉树:在满二叉树的基础上,从右往左,从下往上依次去除结点
一颗普通的树转成二叉树:
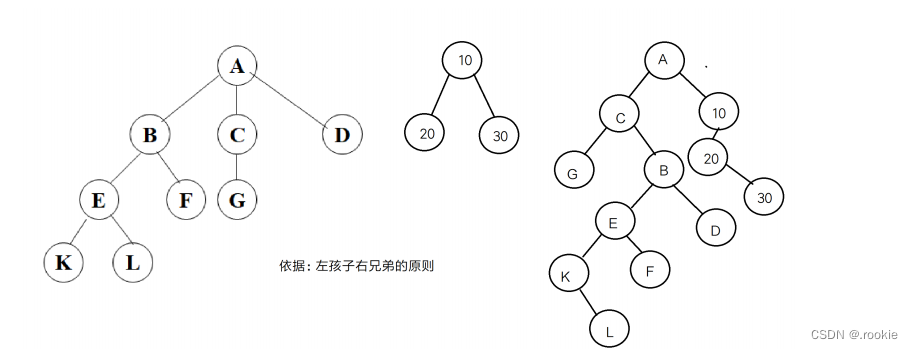
树形结构的顺序存储
树形结构的链式存储
树的结点的定义
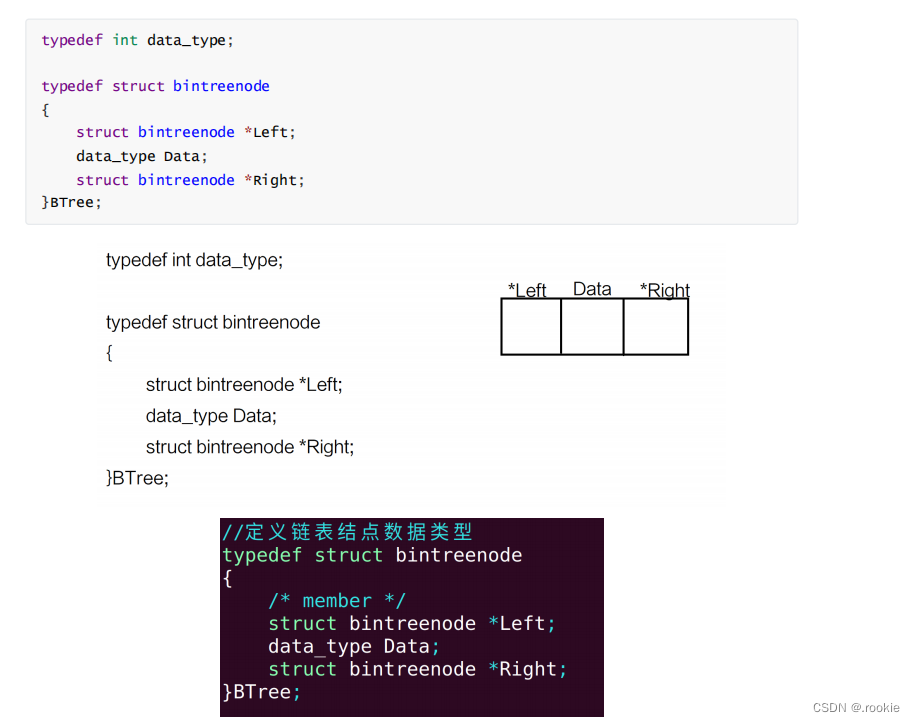
树的结点的创建

树的结点的插入
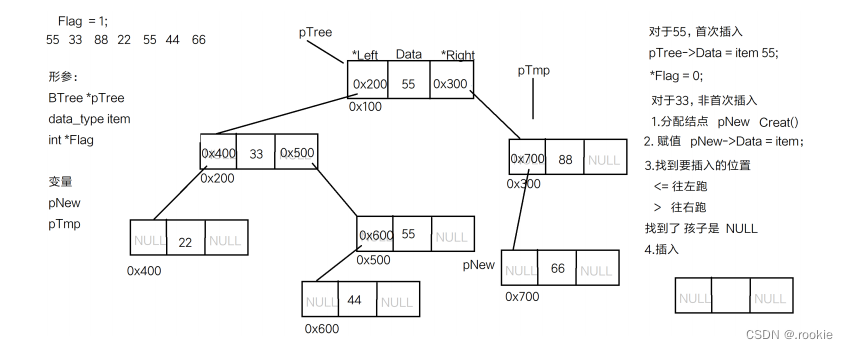
树的节点的遍历
先序遍历:
中序遍历:
后序遍历:
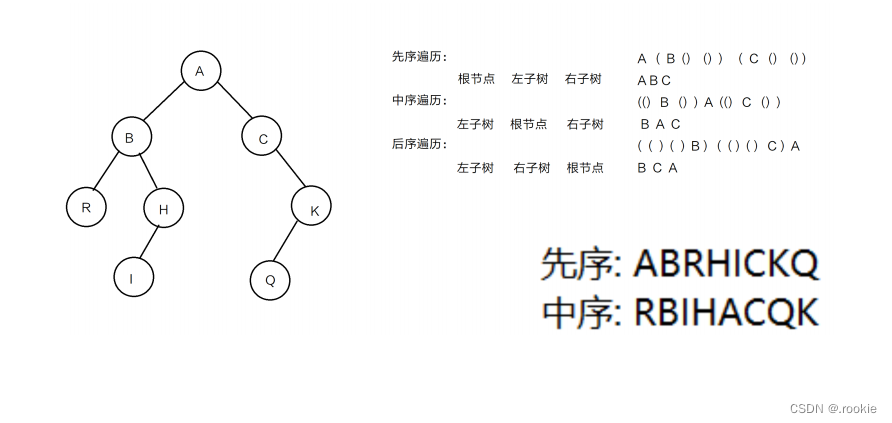
递归形式的遍历,非递归的写法
用栈
深度优先
广度优先
层次遍历
队列
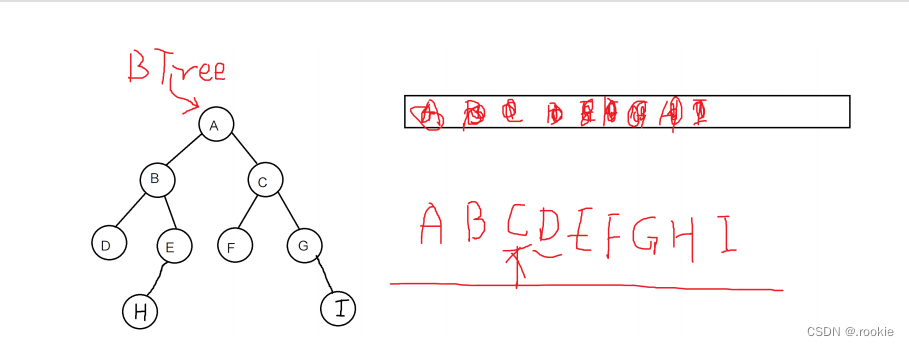
树的结点的删除
待删除结点没有孩子,直接删除
待删除结点有一个孩子,子承父位
待删除结点有两个孩子,找右子树中最小的值或者左子树中最大的值来继承
平衡二叉树
每一个结点的左子树的层数和右子树的层数不超过2
目的:解决树的降维问题(把树将成链表),提高效率
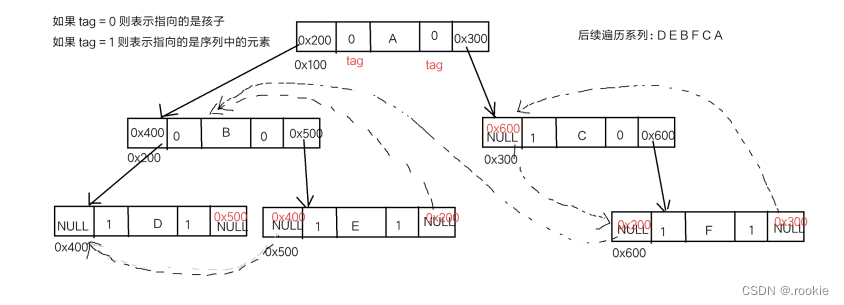
线索二叉树
网状结构
分类:
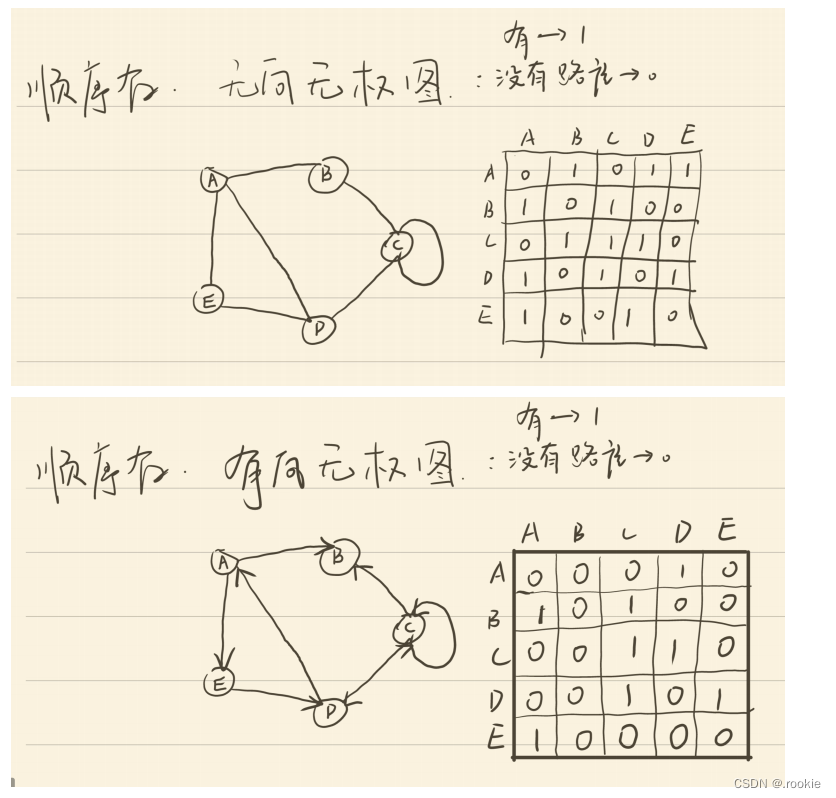
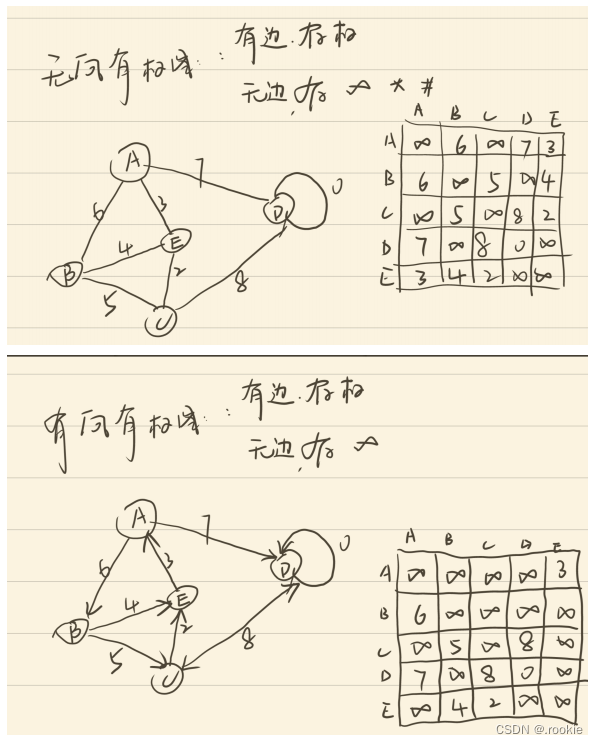
按有无方向可以分为:有向图、无向图
按是否带权值:带权图和不带权图
网状结构的顺序存储
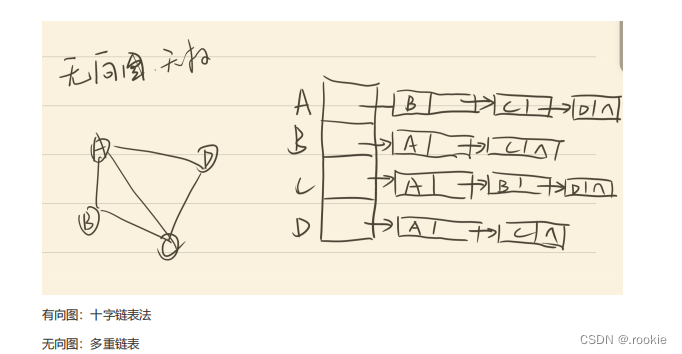
网状结构的链式存储
算法
算法是有限指令的有序集合。
算法是有穷的,程序是无穷的
程序 = 算法 + 数据结构
算法的特征
有穷性:算法必须在有限个语句能描述完
确定性(无二义性):每一条语句只能有一个解释
可行性:能运行的
输入:
输出:
怎么样评判算法的好坏:
效率与低存储量需求(时间复杂度,空间复杂度):时间复杂度:执行这个算法需要花费多少时间。eg:int sum = 0;for(int i = 0; i < n; i++){sum += i;}printf("%d\n", sum);T(n) = n + 2O(n) = n只需要记录量级 11. 顺序执行的代码,只会影响常数项,可以忽略 O(1) 。2. 只需要挑选循环中的一个基本操作来分析他的执行步骤的次数与 n (问题规模)的关系。3. 如果有多层循环嵌套,只需要关注最深层次循环的个数。优化时间复杂度:首先得保证算法的正确性,在这个基础上,思考怎么去减少循环的使用。空间复杂度:执行这个代码,需要花费多少空间。设算法对应问题的规模为 n, 执行算法所占存储空间的量级为 D(n) ,则 D(n) 为算法的空间复杂度。优化空间复杂度:1. 在定义的时候,更少的使用空间;1. 字节对齐:2. 位域:2. 在执行的时候,尽量避免开辟不必要的空间,并且功能结束之后,释放掉不用的空间。正确性:算法得无误运行。可读性、可维护性:对人的友好,是从编程规范入手优化。健壮性、鲁棒性:算法在输入有误的信息的时候,代码还能够按照预想的方式执行,不出现 BUG ,不会退出。
常见的查找算法
顺序查找:遍历
折半查找:二分查找
限制:必须有序、必须是一个顺序表
分块查找:块间有序,块内无序
内部排序
插入:
直接插入:重新构建一个链表
折半插入:和二分查找类似
希尔排序:增量,逐渐减少的,直到增量为1为止
交换:
冒泡:每一次运行总会将最小的或者最大的放到前面,如果需要交换,一直在交换
快速排序*:

选择:
简单选择:每一次运行总会将最小的或者最大的放到前面,最后只交换一次
堆(大根堆,小根堆):根>=左右孩子的,牵扯到树的变化,所以只有特定场景下才使用
多路归并:
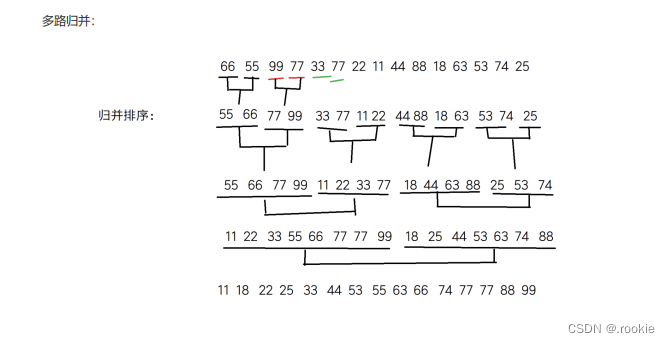
基数排序: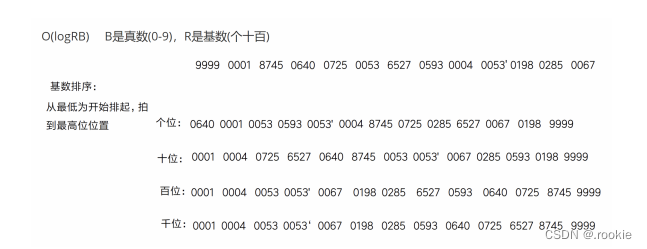
外部排序
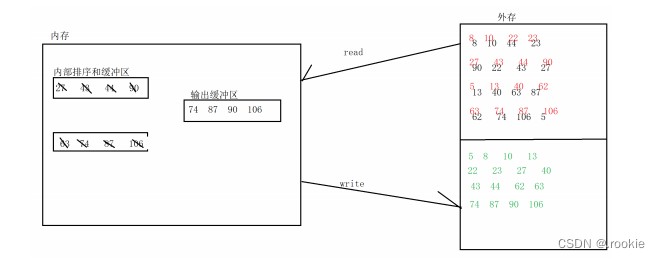
基于多路归并的外部排序:



















 2737
2737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









