






DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
引言:探索乌克兰语的机器翻译挑战
在当今全球化迅速发展的背景下,机器翻译技术已成为沟通世界各地文化和语言的重要桥梁。尽管如此,对于一些使用人数较少的语言,如乌克兰语,机器翻译仍面临着重大挑战。这些挑战主要来源于资源的匮乏、技术的局限性以及语言本身的复杂性。
1. 数据资源的稀缺性
对于英语等广泛使用的语言,获取大量平衡且高质量的数据集相对容易。然而,对于乌克兰语这样的资源较少的语言,获取同等质量的数据集却是一项艰巨的任务。乌克兰语的语料库、字典和标注资源相对匮乏,这直接影响了机器翻译模型的训练效果和翻译质量。
2. 技术转移的复杂性
虽然可以通过将已有的英语翻译模型直接应用于乌克兰语来尝试解决资源不足的问题,但这种方法往往不能达到理想的效果。乌克兰语与英语在语法、句法结构以及表达习惯上有着显著差异,这些差异使得直接转移技术时难以处理这两种语言之间的细微差别。
3. 乌克兰语的语言特性
乌克兰语是一种属于印欧语系的斯拉夫语言,它具有丰富的屈折变化和复杂的语法结构。例如,乌克兰语中的名词有七个格,动词则有多种时态和语气变化。这些语言特性增加了机器翻译的难度,尤其是在保持语句流畅性和准确性方面。
4. 翻译质量的评估难题
评估机器翻译的质量是一个全球性的难题,但对于乌克兰语来说尤为复杂。由于缺乏足够的双语评估人员和标准化的评估体系,很难准确衡量翻译的质量。此外,现有的自动评估工具如BLEU等,往往不能很好地反映乌克兰语翻译的实际效果。
综上所述,尽管面临种种挑战,但随着技术的不断进步和对乌克兰语资源的逐渐积累,我们有理由相信,乌克兰语的机器翻译将会得到显著改善。通过细致的语料库构建、算法优化以及跨语言技术的智能转移,未来乌克兰语的机器翻译有望达到更高的准确性和流畅性。
论文标题、机构、论文链接和项目地址
论文标题: Setting up the Data Printer with Improved English to Ukrainian Machine Translation
机构: Ukrainian Catholic University, lang-uk initiative, Igor Sikorsky Kyiv Polytechnic Institute, Università della Svizzera italiana
论文链接: https://arxiv.org/pdf/2404.15196.pdf
项目地址: https://github.com/lang-uk/dragoman
数据准备与筛选过程
在构建高效的语言模型时,数据的准备与筛选是至关重要的步骤。本章节将详细介绍我们如何从大规模的数据集中筛选出高质量的数据,以及这一过程对模型性能的影响。
1. 数据来源与初步筛选
我们的数据来源于公开的Paracrawl数据集,该数据集包含超过1300万条英语-乌克兰语的句子对。这些数据是通过自动匹配互联网文本中的相似句子收集而来。初步检查发现,数据集中存在大量重复、错误翻译或质量低下的句子。例如,大量重复的天气预报,以及从成人网站抓取的低质量机器翻译文本。
2. 语言过滤
为确保数据的纯净性,我们使用gcld3库进行语言检测,移除所有未能确认为乌克兰语或英语的句子。这一步骤是为了排除那些语言标记错误的数据,确保后续处理的准确性。
3. 翻译对齐筛选
利用LaBSE模型,我们对句子进行嵌入,然后筛选出那些在嵌入空间中对齐较差的句子对。这一步骤帮助我们去除了翻译质量差的数据,这些数据可能会误导模型学习错误的语言规律。
4. 长度过滤
我们还根据原文和译文的长度进行了筛选,移除了那些原文与译文长度差异过大的句子对。这通常意味着翻译可能存在遗漏或冗余信息,不适合用于训练高质量的翻译模型。
5. 多阶段筛选结果
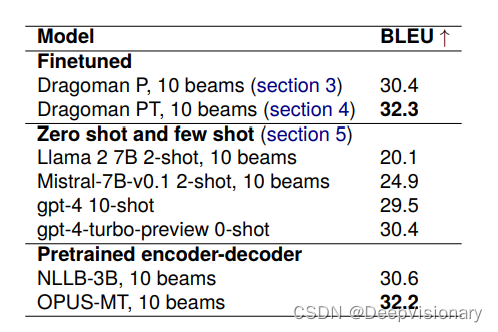
通过上述多个筛选阶段,我们设定了不同的阈值,以获得大约100万、300万和800万的样本量。我们对这些不同的子集进行了多次实验,以寻找最优的超参数。每个子集的筛选阈值和实验结果都记录在Table 2中。
6. 数据筛选对模型性能的影响
经过筛选的数据对模型的性能有显著影响。我们发现,尽管训练在800万筛选过的样本上的模型覆盖了更多的数据,但其性能并不如训练在300万筛选样本上的模型。这可能是因为较大数据集中仍存在一定比例的低质量数据,影响了模型的整体表现。
通过这一系列严格的数据准备与筛选过程,我们有效地提高了数据质量,为后续的模型训练打下了坚实的基础。这不仅提升了模型的翻译质量,也为我们深入理解数据与模型性能之间的关系提供了宝贵的经验。
无监督数据选择与模型微调
在机器翻译和自然语言处理领域,数据的选择和模型的微调是提高系统性能的关键步骤。本章节将探讨如何通过无监督的数据选择方法和模型微调技术,有效提升语言模型的翻译质量。
1. 无监督数据选择
在无监督数据选择阶段,我们主要关注如何从大规模的未标记数据集中筛选出高质量的数据用于训练。这一过程通常涉及多个过滤步骤,以确保数据的准确性和多样性。
- 语言过滤:使用语言检测工具(如gcld3库)来确保句子确实是目标语言(如乌克兰语)。
- 复杂度阈值:通过计算句子的困惑度(perplexity),排除那些过于复杂或不符合语言习惯的句子。
- 翻译质量检查:利用句子嵌入技术(如LaBSE模型)来评估源语言和目标语言句子之间的语义相似性,过滤掉对齐质量差的翻译对。
- 长度过滤:检查源句子和目标句子的长度,去除那些长度差异过大的数据对。
通过这些方法,我们可以从大量的原始数据中筛选出一部分高质量的数据,为模型训练提供更为精准的输入。
2. 模型微调
在选择了高质量的训练数据后,下一步是对预训练的语言模型进行微调,以适应特定的翻译任务。模型微调是一个精细的过程,需要调整的参数包括学习率、训练周期、批处理大小等。
- 微调策略:通常采用小批量梯度下降法对模型进行微调,以逐步优化模型的权重。
- 正则化技术:为了防止模型过拟合,可以采用如dropout等正则化技术,增强模型的泛化能力。
- 性能评估:在微调过程中,需要持续监控模型的性能,如使用BLEU分数等指标来评估翻译质量。
通过细致的微调,模型将更好地适应特定的语言对和翻译风格,从而在实际应用中达到更高的翻译准确率和流畅度。
总之,无监督数据选择和模型微调是提升机器翻译系统性能的关键步骤。通过精心设计的数据过滤策略和系统的模型微调过程,可以显著提高翻译模型的效果,尤其是在资源较少的语言如乌克兰语的场景中。

少样本学习与模型性能
在机器学习和特别是在自然语言处理领域,少样本学习(Few-Shot Learning)已成为一个重要的研究方向。这种学习方式允许模型仅通过极少量的样本进行有效学习,这对于数据稀缺的语言或特定任务尤为重要。
1. 少样本学习的定义与应用
少样本学习通常指的是在只有很少训练样本的情况下训练模型的能力。这种方法在数据稀缺的语言或领域中特别有用,例如在处理乌克兰语这样的资源较少的语言时。通过少样本学习,模型能够快速适应新任务,无需大量数据即可进行有效的预测。
2. 模型性能与少样本学习
在实际应用中,少样本学习能够显著减少对大规模标注数据集的依赖,这对于快速部署新模型或适应新领域具有重要意义。例如,在机器翻译任务中,通过少量的示例翻译,模型可以学习如何将一种语言翻译成另一种语言,即使对于那些它之前未曾见过的语言也能做到这一点。
3. 少样本学习的挑战
尽管少样本学习提供了许多优势,但它也面临着一些挑战。首先,少样本学习模型的泛化能力可能不如那些在大规模数据集上训练的模型。此外,如何设计有效的少样本学习算法,以及如何选择合适的样本来训练模型,也是当前研究中的热点问题。
4. 实际案例
在研究中,使用了基于Transformer的模型在少样本设置下进行乌克兰语的机器翻译任务。尽管模型在没有微调的情况下表现不佳,但通过使用少量的示例进行上下文提示,模型能够显著提高其翻译质量。这证明了即使在资源受限的情况下,少样本学习也能够有效地提升模型性能。
5. 结论
少样本学习为处理数据稀缺问题提供了一种有效的解决方案。通过优化模型架构和学习算法,少样本学习不仅能够提高模型的适应性,还能在资源受限的情况下保持较高的性能。未来的研究可以进一步探索如何通过改进学习策略和算法来增强模型的少样本学习能力。

讨论与局限性
1. 训练数据的质量和数量问题
尽管我们的模型在使用过滤后的数据进行训练时表现出了一定的性能提升,但在实验中发现,使用8百万过滤后的样本进行训练的模型性能不如使用3百万样本的模型(见表2)。这可能表明数据过滤虽然能够移除低质量数据,但过度过滤可能会导致有用信息的丢失,从而影响模型的泛化能力。
2. 语言模型的局限性
在使用基于Transformer的模型进行机器翻译任务时,我们发现即使是经过微调的模型也存在一定的局限性。例如,模型在处理长上下文时的稳定性尚未得到充分验证,这一点需要在未来的工作中进一步探讨(Olsson et al., 2022)。此外,我们的模型在未经微调的情况下,使用beam search进行翻译时的表现仍然不如专门的翻译模型(Tillmann and Ney, 2003)。
3. 评估指标的选择
尽管我们选择BLEU-4作为主要的评估指标,但BLEU指标本身与人类对翻译质量的判断相关性较低(Papineni et al., 2002; Freitag et al., 2022)。这提示我们在未来的研究中可能需要考虑更多与人类评价更为一致的学习型评估指标,以更准确地反映翻译质量。
4. 语言特异性问题
我们的研究主要关注于英语到乌克兰语的翻译,这可能限制了模型在其他语言对上的应用。此外,乌克兰语作为一种资源较少的语言,可用于训练的高质量数据相对较少,这可能进一步限制了模型性能的提升。
5. WMT22基准测试的表现
尽管我们的模型在FLORES测试集上取得了不错的成绩,但在WMT22的基准测试中,我们的模型表现仍然落后于最佳结果(Roussis and Papavassiliou, 2022)。这表明尽管我们的模型在某些测试集上表现良好,但在更广泛的应用场景中可能仍存在局限性。
总体而言,尽管我们的研究取得了一定的成果,但在数据处理、模型选择、评估指标以及语言特异性等方面仍存在一系列挑战和局限性。未来的工作需要在这些方面进行更深入的探索和改进,以提升机器翻译系统的整体性能和适用性。
结论与未来方向
在本研究中,我们通过一个两阶段的数据清洗流程构建了一个翻译系统,并展示了与最先进的编码器-解码器模型相匹配的英语至乌克兰语翻译任务性能。值得注意的是,我们的系统表现出比NLLB模型更优越的性能,后者在生成Aya数据集并显著推动多语言模型的进步方面起到了重要作用。改进的机器翻译能力可能为下一代针对乌克兰语训练的大型语言模型带来新的能力。最近对解码器单独骨干网络的改进以及这一过程的一般动态让我们感到鼓舞:我们坚信,本文提出的方法可以通过简单升级骨干模型来提高翻译质量。
1. 总结
我们的研究成功地应用了基于公开数据的机器翻译系统,特别是在处理英语到乌克兰语的任务中,展示了与当前最先进技术相匹配的性能。通过精心设计的数据清洗和选择流程,我们能够有效地提高翻译质量,这一点在多语言基准测试中得到了验证。此外,我们的系统在没有进行任何后处理的情况下,在WMT22测试集上达到了24.72的BLEU分数,这一成绩虽然略低于最佳结果,但与FLORES测试集上的表现相当,显示了我们方法的有效性。
2. 未来研究方向
尽管我们的研究取得了一定的成果,但在未来的工作中还有几个方向值得探索:
- 模型和数据的进一步优化:虽然我们使用的过滤和微调策略已经取得了不错的效果,但我们相信通过进一步优化模型架构和扩展数据处理方法,可以实现更精确和自然的翻译输出。
- 多样化的语言支持:目前的研究集中在乌克兰语的翻译上,未来可以将这种方法扩展到其他低资源语言,以支持更广泛的语言多样性。
- 自动化和智能化的数据清洗技术:自动化的数据清洗和质量评估工具将大大减少手动处理的需要,提高翻译系统的可扩展性和效率。
- 深入探索少量样本学习和零样本学习:这些学习策略为快速适应新任务提供了可能,未来的研究可以探索如何有效地利用这些策略来进一步提高翻译质量。
通过持续的技术创新和方法优化,我们期待未来能够开发出更加强大和灵活的多语言翻译工具,以更好地服务全球用户。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!

















 2992
2992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









