







DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
Parts2Whole革新:多参照图定制人像,创新自定义肖像生成框架!
引言:探索多条件人像生成的新篇章
在数字内容创作领域,可控的人像生成技术正逐渐成为一个重要的研究方向。这项技术能够根据特定的文本描述、结构信号或更精确的外观条件来合成人像,为用户提供了一种定制化的肖像解决方案。然而,由于控制条件的复杂性,尤其是在多种类型的条件输入和控制人体外观的各个方面时,这项任务呈现出显著的挑战性。
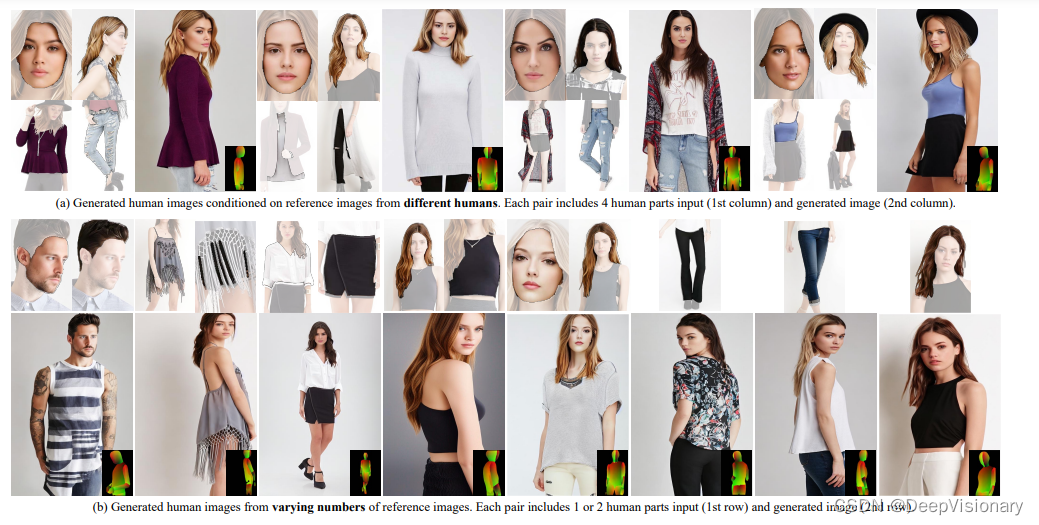
最近,我们介绍了一个名为Parts2Whole的新框架,它旨在从多个参考图像生成定制化的人像,包括姿势图像和人体外观的各个方面。我们的框架通过开发一个语义感知的外观编码器来保留不同人体部位的细节,该编码器基于文本标签处理每个图像,生成一系列多尺度特征图而不是单一图像令牌,以此来保留图像维度。此外,我们的框架通过在扩散过程中操作参考和目标特征的共享自注意机制,支持多图像条件生成。我们通过结合参考人像中的遮罩信息来增强原始注意力机制,允许精确选择任何部分。广泛的实验表明,我们的方法在多部分可控人像定制化方面优于现有替代方案。
论文概览与链接
本文的核心贡献包括构建了一个名为Parts2Whole的新框架,支持基于文本、姿势信号和人体外观多个方面的人像可控生成。我们提出了一个先进的多参考机制,包括一个语义感知图像编码器和共享注意操作,这些机制不仅保留了特定关键元素的细节,而且通过我们提出的遮罩引导方法实现了精确的主体选择。实验表明,我们的Parts2Whole能够从多种条件生成高质量的人像,并与给定条件保持高度一致。
论文链接:From Parts to Whole: A Unified Reference Framework for Controllable Human Image
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









