






过拟合随记
看过很多关于过拟合方面资料,(自学习了4个月+)今天随记一篇自己对过拟合的观点。
机器学习是对偏好进行归纳的过程(来源于西瓜书)。这句话好像什么都没说,又好像什么都说完了。那么问题来了,何为偏好?我这里引入自己利用SSD算法做的一个目标检测DEMO(检测的内容就是卡卡西、鸣人、佐助)来聊聊个人观点。算了,归纳偏好还是引用图像分类算法来阐述更直接,分类的目的就是哪一张是卡卡西、鸣人还是佐助?
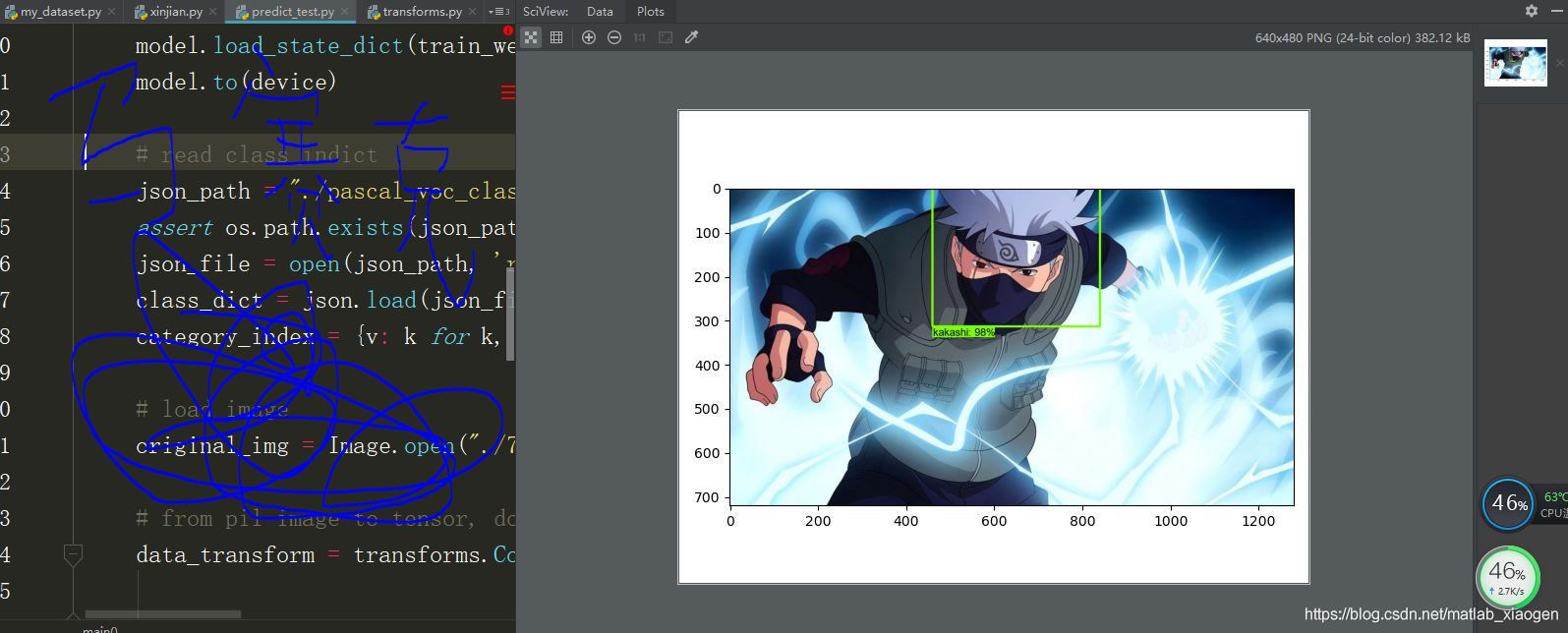
言归正传。刚才说到偏好,何为偏好?偏好是特征么?是但也不是,更具体的说偏好是指那些代表性的特征,而不是共有特征,更不是细化的个性特征(过拟合),何为代表性特征?卡卡西的发型(还有那个万年不脱口罩)、鸣人的黄色发型、佐助的发型。你完全可以根据他们局部特征判断是谁,不需要一个像素一个像素的看吧(卷积与全连接的区别)。共有特征这就解释了吧,都与头发,不能用有没有头发区分三者。细化的个性特征,这个就比较有意思也是关键,比如模型把写轮眼作为佐助的代表性特征,也就是说这一特征贡献的神经元输出很大,最终模型把写轮眼特征判定为佐助,那么问题来了,现在这张图片佐助没有开写轮眼,是不是要判定不是他啊?到这里就解释完了。
如何抑制过拟合?这个课题伴随了整个机器学习的发展历程,具体的方法分为两种:1)降低模型的复杂度。2)数据扩充(data augmentation)
1)降低模型的复杂度
具体的方法:L1、L2正则化、Dropout、batch normalization、集成学习。(今天不讨论约束模型方法)
2)数据扩充
具体的方法:1.水平翻转、剪裁、随机旋转、平移、缩放;2.增加图像噪声(高斯白噪声、椒盐噪声);3.图像锐化、清晰度和光照改变等。你以为我是来讲数据怎么扩充的?不,我是来讲扩充数据为什么能够抑制过拟合的。先谈谈1,其实也没有啥好说的,就是让代表性特征成为主流,啥是主流?就是成为强特征占到主导地位。再说2,网上都说噪音有利于迫使特征具有一般性,而一般性有利于模型的泛化能力,其实我的理解是一般性有利于模型的泛化能力这没错,但是更具体的是噪音有利于削弱细化的个性特征,而不是削弱具有代表性的特征,如果你削弱具有代表性的特征,模型岂不是欠拟合了?最后就是3了,我也不理解,可能锐化操作让特征的值更加凸显吧,光照和清晰度也没啥好说的,就是让环境因素更加一般性,总不能你的人脸识别只能在你白天或黑天解锁吧















 2060
2060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











