







本文章所有截图来自于斯坦福深度学习课程,是个人看完视频后正则化小结。
正则化的宏观概念就是你对你模型做的任何事情,也就是种种所谓的惩罚,主要目的
是为了减轻模型的复杂度,而不是去试图拟合数据
1.L1正则化(鼓励稀疏)
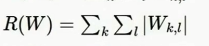
L1更喜欢稀疏解,它倾向于让你的W大部分元素值接近0,少数元素除外,偏离0
2.L2正则化(权值衰减)
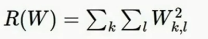
L2正则化就是欧式范数的权重向量W。L2正则化理念上就是对这个权重向量的欧式范数进行惩罚
L1、L2例子:
有一些训练的样本x,有两个不同的W进行考虑,X是一个包含四个1作为元素的四维向量
1.首元素是1,其他三个元素是0
2.四个元素都是0.25
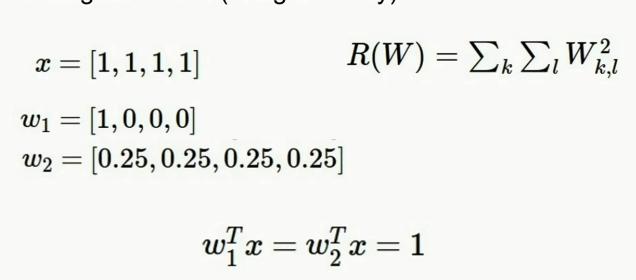
第二种情况下L2回归性好一些,具有较小的范数,L2范数可以用一种相对粗糙的方式度量分类器的复杂性。在线性分类器上,W的值反应的是x向量的值在多大程度上对输出有影响。L2的作用就是更加能够传递出x中不同元素值的影响,它的鲁棒性会更好一些,取决于x向量的整体情况
使用L1更倾向于第一种情况,因为L1正则化对复杂性具有不同的概念,即模型具有更小的复杂度,用数字0描述模型的复杂度在该例子中L1下结果都是1,但可以构建一个类似的例子,在那种情况下L1更有效)
L1考虑的是有可能是非0元素的个数,L2考虑的是整体分布
3.弹性网络正则化(L1+L2)
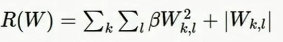
4.最大规则正则化
惩罚最高准则而不是L1或L2准则
5.脱网(Dropout)(一般在全连接层使用,有时也在卷积层,但在卷积层中,要把某几条通道整个置0)
在正向传递时,使一些神经元(激活函数)设为0,如下图所示
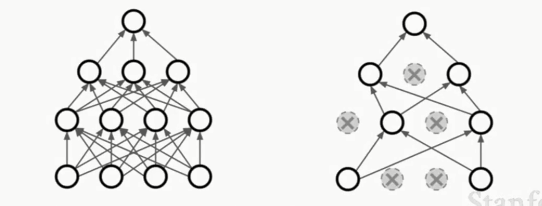
可以牵强的解释为避免了特征间的相互适应,避免了过拟合
对梯度的影响:训练需要更长的时间,梯度只在非dropout的节点上传递,更新时,只会更新网络的一小部分子结构,所以需要更长的时间进行训练,但是收敛后,模型的鲁棒性会很好
比批量归一化某种程度要好,有控制机制
一种常用的方式:训练时添加随机噪声、测试时边缘化噪声
Examples:
1.Dropout
2.Batch Normalization
3.Data Augmentation(数据增强)
4.DropConnect(将权重矩阵中某些值置0)
5.Fractional Max Pooling(部分最大池方法)
6.Stochastic Depth(训练时随机丢弃一些层,测试时用所有的层)















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









