






SQL 三条主线
1.DDL ( 数据定义语言 )
CREAT / ALTER / DROP / RENAME / TRUNCATE
2.DML ( 数据操作语言 )
INSERT / DELETE / UPDATE / SELECT
3.DCL ( 数据控制语言 )
COMMIT / ROLLBACK / SAVEPOINT / GRANT / REVOKE
SQL 语句的规则和规范
规则 :
-
SQL 可以写在一行或多行 , 但为了提高句子的可读性 , 各子句分行写 , 必要时使用缩进
-
每条命令以 ’ ; ’ or ’ \g ’ or ’ \G ’ 结束
-
关键字不能被缩写 , 也不能分行
-
必须使用英文状态下的半角输入方式
-
字符串 & 日期 => ’ '
-
列的别名 => " "
规范 :
- MySQL 在 Win 下是大小写不敏感的
- MySQL 在 Linux 下是大小写敏感的 :
- 数据库名 ,表名 ,表的别名 , 变量名 ,是严格区分大小写的
- 关键字 , 函数名 , 列名 ( 字段名 ) , 列 ( 字段名 ) 的别名 是忽略大小写的
- 推荐使用的统一书写规范 :
- 数据库名 ,表名 ,表的别名 ,字段名 , 字段别名 等都小写
- SQL 关键字 ,函数名 ,绑定变量 等都大写
注释 :
# 单行注释 ( MySQL 特有的方式 )
-- 单行注释 ( 通用 ,-- 后必须含一个空格 )
/*
多行注释
*/
导入现有表的数据 :
- 方式一 :source + 文件的全路径名 ( 使用命令行操作 )
- 方式二 :基于具体的图形化界面的工具导入数据
eg.SQLyog 中 ,"工具" => "执行 sql 脚本" => 选择 xxx.sql 即可
命令行登陆和退出账户 :
- 登陆 => mysql [ -h主机名(localhost / 127.0.0.1) -P端口号(3306) ] -u用户名 (root) -p密码(xiaonuo123…)
- 退出:exit或ctrl+C
基本的 SELSCT 语句
1.基本的查询语句
/*
基本的查询语句
'*' => 表中所有的字段
'DUAL' => 伪表
*/
SELECT ...(字段)
FROM ...(表名) ;
2.列的别名 :
/*
列的别名 :
AS => alias(别名)
*/
SELECT ...(字段) ...(别名)
FROM ... ;
SELECT ...(字段)AS...(别名)
FROM ... ;
专业防出现带空格的别名 ,此处区别第一种方式 PS :使用"" 不用 '' (MySQL未报错是因为不严谨)
SELECT ...(字段) "..."(别名)
FROM ... ;
3.去除重复行(不显示一列中的重复数据) :
/*
去除重复行(不显示一列中的重复数据) :
DISTINCT
*/
SELECT DISTINCT ...(字段)
FROM ... ; #正确的
SELECT DISTINCT ...(字段) ,...(字段)
FROM ... ; #仅仅是没报错 ,但没实际意义
SELECT ...(字段) , DISTINCT...(字段)
FROM ... ; #错误的
4.空值(NULL)参与运算
/*
空值(NULL)参与运算 => 结果一定也为空 ( NULL )
NULL 不等同于 0 or '' or 'NULL'
eg.某一行数据的某个字段的值为 NULL
解决方案 => 引入 IFNULL(字段 ,值)=> 详情参考后续的单行函数
*/
5.着重号
/*
着重号 => ``
当字段名或表名与系统的保留字关键词重名时使用(用于区分)
*/
6.查询常数
/*
表中不存在的字段,以常量的方式出现 ''
*/
SELECT '常量',...(字段)
FROM ...(表);
7.显示表的结构
/*
使用 DESCRIBE or DESC 命令
显示表字段的详细信息
*/
DESCRIBE ...(表名);
DESC ...(表名);
8.过滤数据
SELECT ...(字段)
FROM ...(表)
WHERE ...(条件);
运算符
1.算术运算符
# 算术运算符 : + - * / (div) % (mod)
# 在 SELECT 语句中,'+' 没有连接作用 ,就单纯表示加法运算 eg.
SELECT 100 + '1'
FROM DUAL; # => 101 而非 1001 ,(区别Java)
# 在 SELECT 语句中 , '字符 or 字符串' => 默认取值为 0 ,而非 ASCII 码
SELECT 100 + 'a'
FROM DUAL; # => 100 ,而非 197
# 在 SELECT 语句中 , NULL 参与运算 ,结果为 NULL
SELECT 100 + NULL
FROM DUAL; # => NULL
# '/' => 分母如果为 0 ,则对应的结果为 NULL
# '/' => MySQL 中默认将除法运算得到的结果转化为了浮点型
SELECT 100 / 0
FROM DUAL; # => NULL
SELECT 100 / 2
FROM DUAL; # => 50.0000
# '%' => 结果与被模数的符号一致
SELECT 12 % 3
FROM DUAL; # => 0
SELECT 12 % 5
FROM DUAL; # => 2
SELECT 12 % -5
FROM DUAL; # => 2
SELECT -12 % 5
FROM DUAL; # => -2
SELECT -12 % -5
FROM DUAL; # => -2
2.比较运算符
# 真 => '1' 假 => '0' 其余 => NULL
# = <=> <> != < <= > >=
# = :
SELECT 1 = 2,1 != 2,1 = '1',1 = 'a',0 = 'a'
# 0 1 1 0 1 => 字符串存在隐式转换,如果转换不成功,则看作是 0
FROM DUAL;
SELECT 'a' = 'a','a' = 'b'
# 1 0 => 两边都是字符串的话,则按照 ANSI 进行比较
FROM DUAL;
SELECT 1 = NULL
FROM DUAL; # NULL
SELECT NULL = NULL
FROM DUAL; # NULL
/*
<=> "安全等于" ( 为 NULL 而生 )与 '=' 的作用类似 ,唯一的区别 '<=>' 可以对 NULL 进行比较 :
NULL & NULL => 1
NULL & other => 0
*/
# IS NULL / IS NOT NULL / ISNULL
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) IS NULL;
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) <=> NULL;
SELECT ... (字段)
FROM ... (表)
WHERE ISNULL(... (字段)) ;
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) IS NOT NULL;
SELECT ... (字段)
FROM ... (表)
WHERE NOT ... (字段) <=> NULL;
# LEAST () => min / GREATEST () => max
SELECT LEAST('a','b','c')
FROM DUAL; # => a
SELECT GREATEST('a','b','c')
FROM DUAL; # => c
# BETWEEN ... (a) AND...(b) => 查询满足区间范围 [a,b] 的 字段值
# NOT BETWEEN ... (a) AND...(b)
# OR => 或者 条件必须写全
# IN (set) / NOT IN (set) => 满足对应的结果集 set
# LIKE 模糊查询
# '%' => 代表不确定个数的字符
# '_' => 代表一个不确定字符
# '\'OR '$' => 转义字符
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) LIKE '%a%';
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) LIKE '_a%';
# 区别以下两种表述
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) LIKE '__a%';
SELECT ... (字段)
FROM ... (表)
WHERE ... (字段) LIKE '_\_a%';
/*
REGEXP / RLIKE => 正则表达式:
'^' => 开头
'$' => 结尾
'.' => 匹配任何一个单字符
"[...]" => 匹配方括号内的任意字符 '-' => 表范围 eg.
[a-z] => 任意字母
[0-9] => 任意数字
*/
3.逻辑运算符
/*
参考 C / Java
and(&&):两个条件如果同时成立,结果为true,否则为false
or(||):两个条件只要有一个成立,结果为true,否则为false
not(!):如果条件成立,则not后为false,否则为true
PS :
AND 的 优先级 高于 OR
XOR => 异或 => 两个中只能满足一个
*/
4.位运算符

5.运算符的优先级

排序与分页
1.排序
/*
使用 ORDER BY 对查询到的数据进行排序操作
升序 => ASC (ascend)
降序 => DESC (descend)
*/
SELECT ...(field)
FROM ...(table)
ORDER BY ...(field); # => 默认为升序排序
SELECT ...(field)
FROM ...(table)
ORDER BY ...(field) ASC;
SELECT ...(field)
FROM ...(table)
ORDER BY ...(field) DESC;
# WHERE 不可使用字段的别名 ;but ORDER BY 可以使用
# => 执行顺序 :
SELECT ... (3)
FROM ... (1)
WHERE ... (2)
ORDER BY ...; (4)
2. LIMIT 实现分页
/*
关键词 => LIMIT ...(偏移量),...(条目数)
每页显示 pageSize 条记录,此时显示第 pageNo 页
*/
SELECT ...
FROM ...
LIMIT (pageNo - 1) * pageSize ,pageSize;
# 语句的声明顺序
SELECT ...
FROM ...
WHERE ...
ORDER BY ...
LIMIT ... , ... ;
# MySQL 8.0 新特性 :
# LIMIT ...(条目数) OFFSET...(偏移量)
SELECT ...
FROM ...
LIMIT pageSize OFFSET (pageNo - 1) * pageSize ;
3.拓展
LIMIT 可以使用在 MySQL ,PGSQL , MariaDB SQLite 等数据库中使用 ,表示分页
不能使用在 SQL Server , DB2 , Oracle 中!
eg. Oracle 中使用默认 rownum 去限制行数
多表查询
1.思考:
为何引入多表查询?
- 减少数据的冗余 ,内存的消耗
- 减少了 IO 的次数 ,时间的消耗

2.笛卡尔积的错误与正确的多表查询
1.笛卡尔积的错误 => 原因 :缺少了多表的链接 (错误的匹配了不该匹配的字段)

2.多表查询 (关联查询)的正确方式 => 需要有连接条件
eg.
SELECT employee_id , department_name
FROM employees ,departments
# 两表的连接条件 (PS : 无法查询 id 为NULL 的员工 ,详情参考后续)
WHERE employees.department_id = departments.department_id;
3.案例分析 & 问题解决
1)笛卡儿积的错误会在下面条件下产生 :
- 省略多个表的连接条件(关联条件)
- 连接条件(关联条件)无效
- 所有表中的所有行互相连接
2)为了避免笛卡儿积 , 可以在 WHERE 中加入有效的连接条件
3)插入连接条件后的查询语法
SELECT table1.column , table2.column
FROM table1 , table2
WHERE table1.column1 = table2.column2;
如果查询字段中出现了多个表中都存在的字段 , 则必须指明此字段所在的表
建议:从 SQL 优化的角度 ,建议多表查询时,每个字段前都指明其所在的表
可以给表起别名 ,在 SELECT 和 WHERE 中使用 ,but ,如果给表起了别名 ,一旦在 SELECT 和 WHERE 中使用表名的话 ,则必须使用表的别名 ,不可使用原名
如果有 n 个表实现多表查询 ,则至少有 n-1 个连接条件
3.等值连接 VS 非等值连接 & 自连接 VS 非自连接
/*
多表查询的分类:
角度 一 :等值连接 VS 非等值连接
角度 二 :自连接 VS 非自连接
角度 三 :内连接 VS 外连接
*/
1.等值连接 VS 非等值连接
WHERE 的条件不是用 “=” 连接
2.自连接 VS 非自连接
自己连接自己 eg.
# 查询员工 id ,员工姓名 及其管理者的 id ,管理者的姓名
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name
FROM employees emp,employees mgr
WHERE emp.`manager_id` = mgr.`employee_id`;
3.内连接 VS 外连接
- 内连接 :合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表中不匹配的行
- 外连接 :合并具有同一列的两个以上的表的行,结果集中除了包含一个表与另一个表中不匹配的行之外,还查询到了 左表 或 右表 中不匹配的行
外连接的分类:
- 左外连接
- 右外连接
- 满外连接(左中右都有)
SQL 92 语法:
实现内连接 见上
实现外连接 ,使用 " + " => MySQL 不支持SQL 92 语法中外连接的书写
# 查询员工 id ,员工姓名 及其管理者的 id ,管理者的姓名 (左外连接)
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name
FROM employees emp,employees mgr
WHERE emp.`manager_id` = mgr.`employee_id`(+); # => 107 条记录
SQL 99 语法:
SQL 99 中使用 JOIN … ON 的方式实现多表的查询 ,这种方式也能解决外连接的问题 ,MySQL 是支持此种方式的
SQL 99 语法实现内连接
()表示可省略
SELECT employee_id , department_name
FROM employees (INNER) JOIN departments
ON employees.department_id = departments.department_id;
SELECT employee_id , department_name , city
FROM employees JOIN departments
ON employees.department_id = departments.department_id
JOIN location
ON departments.location_id = location.location_id ;
SQL 99 语法实现外连接
# 左外连接
SELECT employee_id , department_name
FROM employees LEFT (OUTER) JOIN departments
ON employees.department_id = departments.department_id;
# 右外连接
SELECT employee_id , department_name
FROM employees RIGHT (OUTER) JOIN departments
ON employees.department_id = departments.department_id;
# 满外连接 => MySQL 不支持 FULL OUTER JOIN
SELECT employee_id , department_name
FROM employees FULL (OUTER) JOIN departments
ON employees.department_id = departments.department_id;
联合查询
引入:
union 联合、合并
UNION => 会执行去重操作
UNION ALL => 不会执行去重操作
结论 :
如果明确知道合并数据后的结果数据不存在重复数据 ,或不需要去除重复数据 ,则尽量使用 UNION ALL 语句,以提高查询的效率
语法:
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
.....
select 字段|常量|表达式|函数 【from 表】 【where 条件】
特点:
1、多条查询语句的查询的列数必须是一致的
2、多条查询语句的查询的列的类型几乎相同
3、union代表去重,union all代表不去重
七种 JOIN 的实现

# 中图 => 内连接
SELECT employee_id,department_name
FROM employees JOIN departments
ON employees.department_id = departments.department_id;
# 左上图 => 左外连接
SELECT employee_id,department_name
FROM employees LEFT JOIN departments
ON employees.department_id = departments.department_id;
# 右上图 => 右外连接
SELECT employee_id,department_name
FROM employees RIGHT JOIN departments
ON employees.department_id = departments.department_id;
# 左中图
SELECT employee_id,department_name
FROM employees LEFT JOIN departments
ON employees.department_id = departments.department_id
WHERE departments.department_id IS NULL;
# 右中图
SELECT employee_id,department_name
FROM employees RIGHT JOIN departments
ON employees.department_id = departments.department_id
WHERE employees.department_id IS NULL;
# 左下图
# 方式 一 : 左上图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees LEFT JOIN departments
ON employees.department_id = departments.department_id
UNION ALL
SELECT employee_id,department_name
FROM employees RIGHT JOIN departments
ON employees.department_id = departments.department_id
WHERE employees.department_id IS NULL;
# 方式 二 : 左中图 UNION ALL 右上图
SELECT employee_id,department_name
FROM employees LEFT JOIN departments
ON employees.department_id = departments.department_id
WHERE departments.department_id IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees RIGHT JOIN departments
ON employees.department_id = departments.department_id;
# 右下图 :左中图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees LEFT JOIN departments
ON employees.department_id = departments.department_id
WHERE departments.department_id IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees RIGHT JOIN departments
ON employees.department_id = departments.department_id
WHERE employees.department_id IS NULL;
SQL 99 语法新特性1 => 自然连接
# NATURAL JOIN => 它会帮你自动查询两张连接表中`所有相同的字段` ,然后进行等值连接
SQL 99 语法新特性2 => USING 的使用
SELECT employee_id,department_name
FROM employees JOIN departments
ON employees.department_id = departments.department_id;
SELECT employee_id,department_name
FROM employees JOIN departments
USING (department_id);
单行函数
- 内置函数
- 自定义函数
我们在使用 SQL 语言的时候 ,不是直接和这门语言打交道 ,而是通过它使用不同的数据库软件 ,即 DBMS 。不同的 DBMS 之间的差异很大 ,远大于同一个语言不同版本之间的差异。实际上只有很少的函数是被 DBMS 同时支持的 。大部分 DBMS 会有自己特定的函数 ,这就意味着 采用 SQL 函数的代码可移植性是很差的 ,因此在使用函数的时候需要特别注意
1.MySQL 的内置函数 及其 分类
从实现功能的角度可分为 :
- 数值函数
- 字符串函数
- 日期和时间函数
- 流程控制函数
- 加密与解密函数
- 获取 SQL 信息函数
- 聚合函数等
可大致分为 => 单行函数 & 聚合函数 (分组函数)
单行函数:
- 操作数据对象
- 接受参数返回函数结果
- 只对一行进行变换
- 每行返回一个结果
- 可以嵌套
- 参数可以是一列或一个值
2.数值函数
2.1基本函数
- ABS(x) => 返回 x 函数的绝对值
- SIGN (x)=> 返回 x 的符合 ,正数 => “1” 负数 => “-1” 0 => "0"
- PI() => 返回圆周率的值
- CEIL(x) , CEILING(x) => 返回大于或等于某个值的最小整数 (天花板)
- FLOOR(x) => 返回小于或等于某个值的最大整数 (地板)
- LEAST(e1,e2,e3…) => 返回列表中的最小值
- GREATEST(e1,e2,e3…) => 返回列表中的最大值
- MOD(x,y) => 返回 x 除以 y 后的余数
- RAND() => 返回 0 ~ 1 的随机值
- RAND(x) => 返回 0 ~ 1 的随机值 ,其中 x 作为种子值 ,相同的 x 值会产生相同的随机数
- ROUND(x) => 返回一个对 x 的值进行四舍五入之后 ,最接近于 x 的整数
- ROUND(x) => 返回一个对 x 的值进行四舍五入之后 ,最接近于 x 的值 ,并保留到小数点后的 y 位
- TRUNCATE(x,y) => 返回数字截断为 y 位小数的结果
- SQRT(x) => 返回 x 的平方根 ,if x < 0 ,返回 NULL
2.2角度制与弧度制的转换
- RADIANS(x) => 角度 => 弧度
- DEGREES(x) => 弧度 => 角度
2.3三角函数
- SIN (x)
- ASIN (x) => 反函数
- COS (x)
- ACOS (x)
- TAN (x)
- ATAN (x)
- ATAN2 (m,n) => 返回两个参数的反正切值
- COT (x)
x 默认为弧度制
2.4指数和对数
- POW(x,y) , POWER(x,y) => 返回 x 的 y 次方
- EXP(x) => 返回 e 的 x 次方
- LN (x) ,LOG (x) => 返回以 e 为底 x 的对数 ,if x <= 0 ,返回 "NULL"
- LOG10(x) => 返回以 10 为底 x 的对数 ,if x <= 0 ,返回 "NULL"
- LOG2(x) => 返回以 2 为底 x 的对数 ,if x <= 0 ,返回 "NULL"
2.5进制间的转换
- BIN(x) => 返回 x 的二进制编码
- HEX(x) => 返回 x 的十六进制编码
- OCT(x) => 返回 x 的八进制编码
- CONV(x,f1,f2) => 返回 f1 进制数 变成 f2 进制数
3.字符串函数
-
ASCII(s) => 返回字符串 s 中的第一个字符的 ASCII 码的值
-
CHAR_LENGTH(s) => 返回字符串 s 的字符数 ,作用与 CHARACTER_LENGTH(s) 相同
-
LENGTH(s) => 返回字符串 s 的字节数 ,和字符集有关
-
CONCAT(s1,s2,s3…) => 连接 s1,s2,s3 … sn 为一个字符串
-
CONCAT_WS(x,s1,s2,s3…) => 同 CONCAT(s1,s2,…) 函数,不过每个字符串之间要加上 x
-
INSERT(str,idx,len,replacestr) => 将字符串从 idx 位置开始 ,len 个字符串的字串替换为字符串replacestr 【PS: MySQL 中字符串的索引从 1 开始】
-
REPLACE(str,a,b) => 用字符串 b 替换字符串 str 中所有出现的字符串 a
-
UPPER(s) 或 UCASE(s) => 将字符串中所有字母转为大写
-
LOWER(s) 或 LCASE(s) => 将字符串中所有字母转为小写
-
LEFT(str,n) => 返回 str 最左边的 n 个字符
-
LRIGHT(str,n) => 返回 str 最右边的 n 个字符
-
LPAD(str,len,pad) => 用字符串 pad 对 str 左边进行填充,直到 str 的长度为 len 个字符,可实现右对齐
-
RPAD(str,len,pad) => 用字符串 pad 对 str 右边进行填充,直到 str 的长度为 len 个字符,可实现左对齐
-

-
FIELD(s,s1,s2,…) => 返回字符串 s 在列表中第一次出现的位置
-
FIND_IN_SET(s1,s2) => 返回字符串 s1 在字符串 s2 出现的位置 ,其中 字符串 s2 是一个以逗号分割的字符串
-
REVERS(s) => 返回 s 反转后的字符串
-
NULLIF(value1,value2) => 比较两个字符串 ,如果 value1 与 value2 相等 ,则返回 NULL ,否则返回 value1
4.日期和时间函数
4.1获取日期、时间

4.2日期和时间戳的转换

4.3获取月份、星期、星期数、天数等

4.4日期的操作函数



4.5时间和秒钟数转换

4.6计算日期和时间的函数
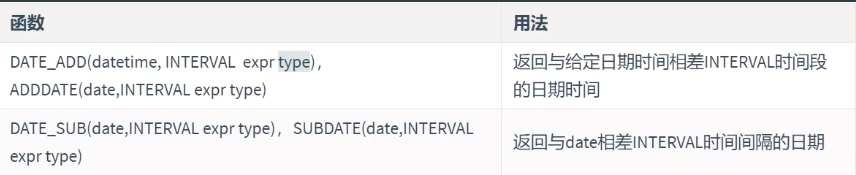


4.7日期的格式化与解析




5.流程控制函数

6.加密与解密函数

PASSWORD(str) / ENCODE(value,password_seed) / DECODE(value,password_seed) 在 MySQL 8.0 中已经被弃用了
7.MySQL 的信息函数

8.其他函数

聚合函数
对一组数据进行汇总的函数输入的是一组数据的集合,输出的是单个值
1.常见的几个聚合函数
1.1AVG() /SUM()
=> 只适用于数值类型的字段或变量
1.2MAX() / MIN()
=> 适用于数值类型,字符串类型,日期时间类型的字段 (变量)
1.3COUNT()
/*
如果计算表中有多少条数据,如何实现?
方式 1 => COUNT(*)
方式 2 => COUNT(1)
方式 3 => COUNT(field) => 不一定对 !!
*/
- 作用:计算指定字段在查询结构中出现的个数
- 注意 :计算指定字段出现的个数时,是不计算 NULL 值的
- AVG = SUM / COUNT

2.GROUP BY 的使用
# 使用 GROUP BY 子句将表中的数据分成若干组
SELECT culumn ,group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];




3.HAVING 的使用 => 过滤数据
# 练习 :查询各个部门中最高工资比 10000 高的部门信息
# 错误的写法
SELECT department_id,MAX(salary)
FROM employees
WHERE MAX(salary) > 10000
GROUP BY department_id;
# 要求 1 :如果过滤条件中使用了聚合函数,则必须使用 HAVING 来代替 WHERE 。否则 ,报错
# 要求 2 :HAVING 必须声明在 GROUP BY 的后面。
# 正确的写法 :
SELECT department_id ,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
# 要求 3 :开发中 ,使用 HAVING 的前提是 SQL 中使用了 GROUP BY .
# 练习 :查询部门 id 为 10,20,30,40 部门中最高工资比 10000 高的部门信息
# 方式 1 ( 推荐 ):
SELECT department_id ,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
# 方式 2 :
SELECT department_id ,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
/*
结论 :
当过滤条件中有聚合函数时 ,此过滤条件必须声明在 HAVING 中
当过滤条件中没有聚合函数时 ,此过滤条件声明在 WHERE 中或声明在 HAVING 中都可以,但建议声明在 WHERE 中( 提高效率 )
*/
/*
WHERE 与 HAVING 的对比
1.从适用范围上来讲 ,HAVING 的适用范围更广
2.如果过滤条件中没有聚合函数:这种情况下,WHERE 的执行效率要高于 HAVING
*/
4.SQL 的底层原理
4.1SELECT 语句的完整结构
# SQL 92 语法 :
SELECT ... , ... , ... (存在聚合函数)
FROM ... , ... , ...
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ... , ...
HAVING 包含聚合函数的过滤条件
ORDER BY ... , ... (ASC / DESC)
LIMIT ... , ... ;
# SQL 99 语法 :
SELECT ... , ... , ... (存在聚合函数)
FROM ... (LEFT / RIGHT) JOIN ... ON ...多表的连接条件
(LEFT / RIGHT) JOIN ... ON ...
WHERE 不包含聚合函数的过滤条件
GROUP BY ... , ...
HAVING 包含聚合函数的过滤条件
ORDER BY ... , ... (ASC / DESC)
LIMIT ... , ... ;
4.2SQL 语句的执行顺序

FROM ... , ... => ON => (LEFT / RIGHT JOIN) => WHERE => GROUP BY => HAVING => SELECT => DISTINCT => ORDER BY => LIMIT
子查询
1.需求分析 & 问题解决
子查询的基本使用
# 需求 :谁的工资比 Abel 的高
# 方式 1 :
SELECT salary
FROM employees
WHERE last_name = 'Abel'; # => 11000;
SELECT last_name , salary
FROM employees
WHERE salary > 11000;
# 方式 2 (自连接):
SELECT e2.last_name , e2.salary
FROM employees e1 ,employees e2
WHERE e2.salary > e1.salary
AND e1.last_name = 'Abel';
# 方式 3 (子查询):
SELECT last_name , salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'Abel';
);
# 称谓的规范 :外查询 (或 主查询),内查询 (或 子查询)
/*
子查询(内查询)在主查询之前一次执行完成
子查询的结果被主查询(外查询)使用
注意事项:
子查询要放在括号内
将子查询放在比较条件的右侧 (增强可读性)
单行操作符对应单行子查询 ,多行操作符对应多行子查询
*/
子查询的分类
角度 1 :
从内查询返回结果的条目数 => 单行子查询 VS 多行子查询
角度 2 :
从内查询是否被执行多次 (内外查询是否有关) => 相关子查询 VS 不相关子查询
eg. 相关子查询 => 查询工资大于本部门平均工资的员工信息
不相关子查询 => 查询工资大于本公司平均工资的员工信息
2.单行子查询
单行比较操作符
'=' '>' '>=' '<' '<=' '<>'
3.多行子查询
- 也称为集合比较子查询
- 内查询返回多行
- 使用多行比较操作符
多行比较操作符
/*
IN => 等于列表中任意一个
ANY => 需要和单行比较操作符一起使用,和子查询返回的某一个值比较
ALL => 需要和单行比较操作符一起使用,和子查询返回的所有值比较
SOME => 实际上是 ANY 的别名,作用相同,一般使用 ANY
*/
# 区别下面两个练习
# 练习 :返回其他 job_id 中比 job_id 为 'IT PROG' 部门任一工资低的员工的员工号,姓名,job_id,salary => 存在
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT PROG'
AND salary < ANY(
SELECT salary
FROM employees
WHERE job_id = 'IT PROG'
);
# 练习 :返回其他 job_id 中比 job_id 为 'IT PROG' 部门所有工资低的员工的员工号,姓名,job_id,salary => 任意
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE job_id <> 'IT PROG'
AND salary < ALL(
SELECT salary
FROM employees
WHERE job_id = 'IT PROG'
);
小拓展
# 查询平均工资最低的部门 id
SELECT MIN(AVG(salary))
FROM employees
GROUP BY department_id; # => 错误的 ,MySQL 中聚合函数不可嵌套 ,单行函数可
# => 方式 1 :
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_sal)
FROM (
SELECT AVG(salary) "avg_sal"
FROM employees
GROUP BY department_id
)t_dept_avg_sal # => 等价于将查询到的 AVG 新建了一张表去存放,避开了聚合函数的嵌套使用
);
# => 方式 2 :
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL(
SELECT AVG(salary) "avg_sal"
FROM employees
GROUP BY department_id
);
4.相关子查询
SELECT column1,column2,...
FROM table1 outer
WHERE column1 operator(
SELECT column1,column2
FROM table2
WHERE expr1 =
outer.expr2);
相关子查询执行流程

# 查询员工中工资大于本部门平均工资的员工的 last_name , salary , department_id
# 方式 1 :相关子查询
SELECT e1.last_name , e1.salary , e1.department_id
FROM employees e1
WHERE e1.salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e2.department_id = e1.department_id
);
# 方式 2 :在 FROM 中声明子查询
SELECT e.last_name , e.salary , e.department_id
FROM employees e , (
SELECT department_id , AVG(salary) "avg_sal"
FROM employees
GROUP BY department_id)t_dept_avg_sal
WHERE e.department_id = t_dept_avg_sal.department_id
AND e.salary > t_dept_avg_sal.salary
在 SELECT 中除了 GROUP BY 和 LIMIT 之外 ,其它位置都可以声明子查询
EXISTS 与 NOT EXISTS 关键字
# 查询公司管理者的 employee_id ,last_name ,job_id ,department_id 信息
# 方式 1 : 自连接
SELECT DISTINCT e1.employee_id ,e1.last_name ,e1.job_id ,e1.department_id # => 去重
FROM employees e1 JOIN employees e2
ON e1.employee_id = e2.manager_id;
# 方式 2 :子查询
SELECT DISTINCT employee_id ,last_name ,job_id ,department_id # => 去重
FROM employees
WHERE employee_id IN (
SELECT manager_id
FROM employees
);
# 方式 3 : 使用 EXISTS
SELECT employee_id ,last_name ,job_id ,department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.employee_id = e2.manager_id
);
如果同时既可以使用子查询又可以使用自连接,推荐自连接(效率高)=> 具体可参照未来的 MySQL 高级篇















 2993
2993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









