







简介
音频驱动的说话头生成是一种将人物头像与语音音频相结合,通过生成技术将静态头像转化为动态头像的过程。这种技术在视频游戏、电影配音以及虚拟化身等都有应用,它能够增强人物形象的真实感和表现力。
目前,生成对抗网络(GANs)是在表达性说话头生成方面表现最为突出的技术。然而,GANs 存在模式崩溃和训练不稳定等问题,这限制了其在不同说话风格上的高性能表现。另一方面,扩散模型是一种新兴的生成技术,近年来在图像生成、视频生成和人体动作合成等领域取得了显著的成果。然而,当前的扩散模型在表达性说话头生成方面仍存在一些问题,例如帧抖动问题,即生成的头像在连续的帧之间可能出现不稳定的抖动。
因此,如何充分发挥扩散模型在表达性说话头生成方面的潜力,是一个有前景但尚未充分开发的研究方向。未来的工作可以集中在解决扩散模型中存在的问题,提高其在生成逼真的、稳定的表达性说话头方面的性能。这可能涉及到改进模型的架构、优化训练算法、设计更有效的损失函数等方面的工作。通过不断地改进和完善,扩散模型有望成为表达性说话头生成领域的领先技术之一。
DreamTalk单张图像生成逼真人物说话头像动画
DreamTalk网络结构
在人工智能生成人物头像的方法中,主要有两种方法:音频驱动和表情驱动。
-
音频驱动方法:
- 人物特定:在训练时需要指定演讲者的音频,以生成与该演讲者相匹配的头像。
- 人物不确定:可以为未知演讲者生成视频,不需要事先指定演讲者的身份信息。
-
表情驱动方法:
- 离散情感类别模型:早期采用离散情感类别模型来生成特定表情的头像。
- 表情参考视频:后来采用表情参考视频进行表情转移,从参考视频中学习表情,并将其应用于生成的头像中。然而,这些基于GAN的模型存在模式崩溃问题,导致生成的头像缺乏多样性和真实感。
针对以上问题,DreamTalk提出了一种新方法,即使用扩散模型来生成具有个性化和情感表达的头像。扩散模型在多个视觉任务中表现出色,但之前的尝试在生成表情时只能产生中性情感的头像。本文提出的方法通过从输入音频和肖像中推断出演讲风格,并生成更具表现力的头像。这种方法能够从输入音频中推断出演讲风格,从而生成更具表现力的头像,克服了以往模式崩溃问题,为生成人物头像提供了新的解决方案。
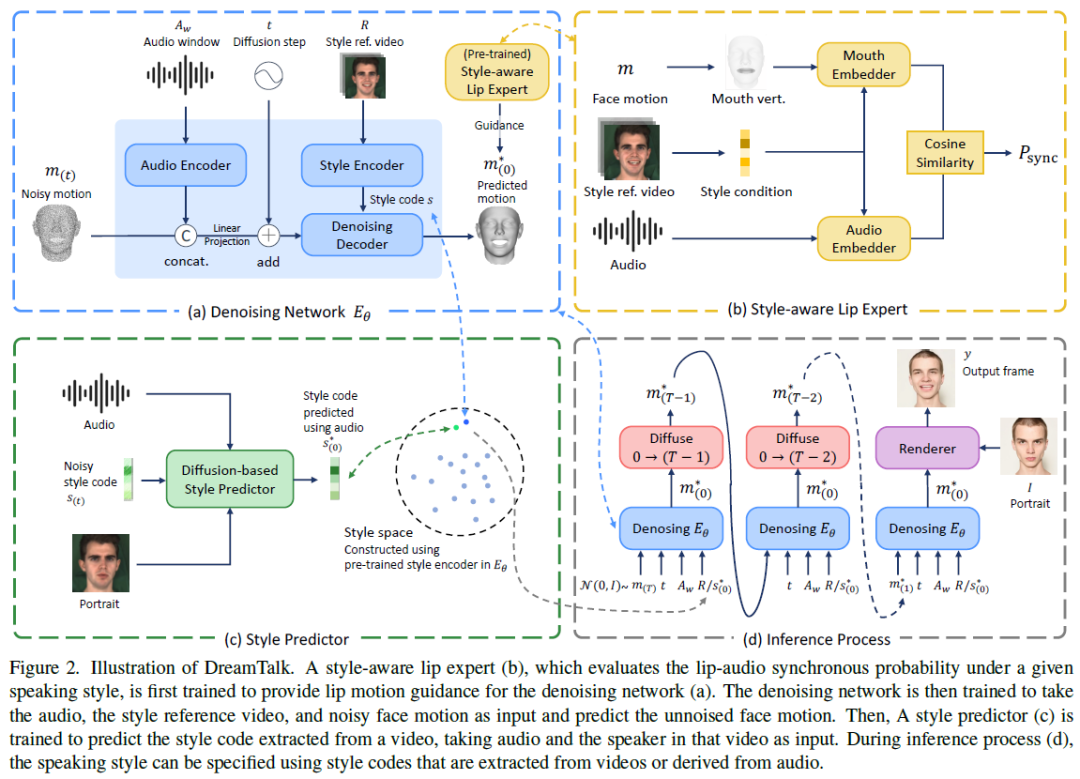
DreamTalk框架由三个关键组件组成:去噪网络、风格感知唇形专家和风格预测器:
-
去噪网络:
- 去噪网络负责根据输入的语音和风格参考视频计算人脸运动,并将其参数化为3D形变模型的表情参数序列。
- 它以滑动窗口的方式逐帧合成人脸运动序列,并利用音频窗口预测运动帧。
- 音频窗口首先被馈送到基于transformer的音频编码器中,输出噪声运动级联。然后将这些运动线性投影到相同维度,与时间步长t相加,作为transformer解码器的键和值。
- 为了提取说话风格,风格编码器从风格参考视频中提取3DMM表情参数序列,并将其输入到transformer编码器中。使用自注意力池化层聚合输出标记,以获得风格代码。
- 这些风格代码被重复多次并添加位置编码,然后作为transformer解码器的查询。解码器的中间输出令牌经过前馈网络以预测信号。
-
风格感知唇形专家:
- 风格感知唇形专家旨在解决去噪网络中存在的唇动不准确的问题。
- 它经过训练,能够评估不同说话风格下的口型同步,并在不同的说话风格下提供唇动指导,以在风格表现力和口型同步之间取得平衡。
- 该专家根据风格参考视频计算音频和嘴唇运动同步的概率,将唇动和音频编码为以风格参考为条件的嵌入,并计算余弦相似度以表示同步概率。
- 为了获取唇动信息,首先将人脸运动转换为人脸网格,并选择嘴巴区域的顶点作为唇动表示。然后,使用风格编码器从风格参考视频中提取风格特征,并将其与嵌入网络的中间特征图连接,以将风格条件融合到嵌入网络中。
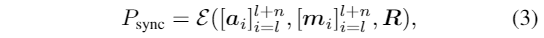
-
风格预测器:
- 风格预测器用于预测由训练的去噪网络中的风格编码器提取的风格代码,并观察说话人身份和风格代码之间的相关性。
- 它被实例化为序列上的transformer编码器,其序列包括音频嵌入、扩散时间步的嵌入、说话人信息嵌入、噪声风格代码嵌入和一个称为learned query的最终嵌入,输出用于预测无噪声风格代码。
- 音频嵌入是使用自监督预训练语音模型提取的音频特征。为获取说话人信息嵌入,首先提取了3DMM身份参数,然后使用MLP将其嵌入到token中。

模型训练
首先,通过确定随机采样的音频和唇动剪辑是否像中那样同步,对风格感知的唇动专家进行预训练,然后在训练去噪网络期间进行冻结。去噪网络是通过从数据集中抽样随机元组来训练的,优化损失:
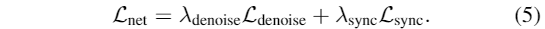 具体来说,从同一时刻的训练视频中提取地面真实运动和语音音频窗口。样式引用是从同一个视频中随机抽取的视频片段。
具体来说,从同一时刻的训练视频中提取地面真实运动和语音音频窗口。样式引用是从同一个视频中随机抽取的视频片段。
首先计算扩散模型的去噪损失定义为:

然后,去噪网络通过对生成的片段进行同步损失来最大化同步概率:
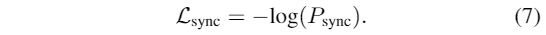
使用无分类器指导的进行模型训练。对于推理,预测信号由一下公式计算:
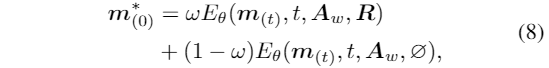
该方法通过调节比例因子ω来控制风格参考R的效果。
当训练风格预测器时,我们抽取一个随机视频,然后从中提取音频和风格代码。由于3DMM身份参数可能会泄露表情信息,因此从具有相同说话人身份的另一个视频中采样肖像。样式预测器通过优化损失值来训练:
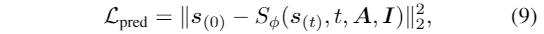
利用PIRenderer作为渲染器,并对其进行精心微调,使渲染器具有情感表达生成能力。
模型推理
在DreamTalk方法中,可以根据不同的需求选择使用参考视频或仅通过输入音频和肖像来指定说话风格。
-
使用参考视频:
- 当使用参考视频来指定说话风格时,可以利用去噪网络中的风格编码器来导出风格代码。这个过程包括从参考视频中提取风格信息,并将其编码成风格代码,用于指导生成的头像面部动作。
-
仅使用输入音频和肖像:
- 当仅依赖输入的音频和人像时,这些输入由风格预测器处理。风格预测器负责从输入的音频中推断出说话风格,并生成相应的风格代码。这个过程不依赖于参考视频,而是根据输入的音频和肖像直接预测出说话风格。
无论是使用参考视频还是仅依赖输入音频和肖像,得到了风格代码后,去噪网络可以利用 DDPM(Diffusion Probabilistic Models)的采样算法来产生人脸运动。该算法首先对随机运动进行采样,然后计算去噪序列,并最终生成人脸运动序列。利用 DDIM(Diffusion Implicit Models)可以加速采样过程。最后,渲染器将生成的人脸运动渲染为视频,产生逼真的说话头像。
实验
在实验设置中,研究者使用了以下数据集、基线方法和指标进行评估:
-
数据集:
- 训练和评估去噪网络:MEAD、HDTF 和 Voxceleb2。
- 训练风格感知唇形专家:MEAD 和 HDTF。
- 训练风格预测器:MEAD,并在 MEAD 和 RAVEDESS 上进行评估。
-
基线方法(与以下方法进行对比):
- MakeitTalk
- Wav2Lip
- PCAVS
- AVCT
- GC-AVT
- EAMM
- StyleTalk
- DiffTalk
- SadTalker
- PDFGC
- EAT
-
指标:
- 结构相似性指标(SSIM)
- 模糊检测的累积概率(CPBD)
- SyncNet 置信度分数(Sync conf)
- 嘴巴区域周围的地标距离(M-LMD)
- 全脸地标距离(F-LMD)
-
结果:
- 定量比较显示,该方法在大多数指标上优于先前的方法。
- 尤其在精确的嘴唇同步和生成与参考说话风格一致的面部表情方面表现出色。
这些结果表明,该方法在生成表情丰富的说话头像方面具有显著的优势,尤其在嘴唇同步和面部表情一致性方面表现出色,相比于先前的方法取得了更好的结果。
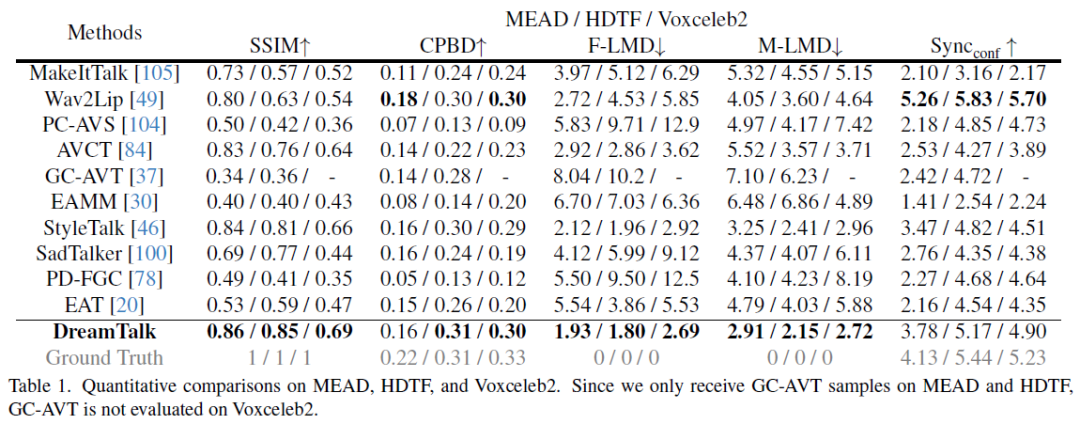
在定性比较中,与其他方法相比,各个方法存在不同程度的问题和局限性:
-
MakeItTalk 和 AVCT:
- 存在准确的嘴唇同步方面的困难。
-
Wav2Lip 和 PC-AVS:
- 输出模糊不清。
-
SadTalker:
- 在嘴唇运动方面有时显示出不自然的抖动。
-
EAT:
- 能力仅限于生成离散的情绪,缺乏细腻的表达。
-
EAMM、GC-AVT、StyleTalk 和 PD-FGC:
- 能够产生细致的表情,但存在以下问题:
- EAMM 在嘴唇同步方面表现不佳。
- GC-AVT 和 PDFGC 在保持说话者身份方面有困难。
- 三者都存在渲染合理背景的问题。
- StyleTalk 有时会减弱强度并且无法准确地生成某些单词的嘴唇运动。
- 能够产生细致的表情,但存在以下问题:
-
DiffTalk:
- 在嘴唇同步方面存在困难,并且在嘴部区域引入抖动和伪影。
相比之下,DreamTalk在生成逼真的说话人脸方面表现出色,具有以下优势:
- 能够模仿参考说话风格。
- 实现精确的嘴唇同步。
- 提供优质的视频质量。
因此,DreamTalk在生成表情丰富的说话头像方面具有显著的优势,是一种值得关注的高性能方法。


泛化能力:本方法还展示了在不同领域的肖像、各种语言的语音、嘈杂的音频输入和歌曲中生成逼真的说话头视频的能力。

说话风格预测结果:本方法能够准确识别细微的表情差异,并根据原始视频中观察到的个性化说话风格进行预测。

消融分析
本文通过消融实验分析了设计的贡献,包括去除口型专家和使用无条件口型专家的变体。结果表明,去除口型专家会导致情感数据集MEAD的唇同步精度下降,而使用无条件口型专家则会牺牲表达风格的精度。全模型通过引导扩散模型的表达潜力,实现了精确的唇同步和生动的表情,达到了平衡。

风格代码可视化
使用tSNE将MEAD数据集中15个说话者的风格代码映射到2D空间中,这些说话者展示了22种不同的说话风格,包括三个强度级别的七种情绪和一种中性风格。每种风格从10个随机选择的视频中提取风格代码。结果显示,相同说话者的风格代码倾向于聚集在一起,这表明个体说话者的独特性对说话风格的差异产生了更大的影响,这也是使用肖像信息推断说话风格的合理性的基础。此外,每个说话者的风格代码分布都展示了共同的模式和个性化的特征。

风格编辑
调整分类器自由指导方案中的比例因子ω可以调节输入风格的影响,当ω超过2时,唇同步准确度会下降。利用风格空间进行风格代码插值可以实现无缝过渡和生成新的说话风格。

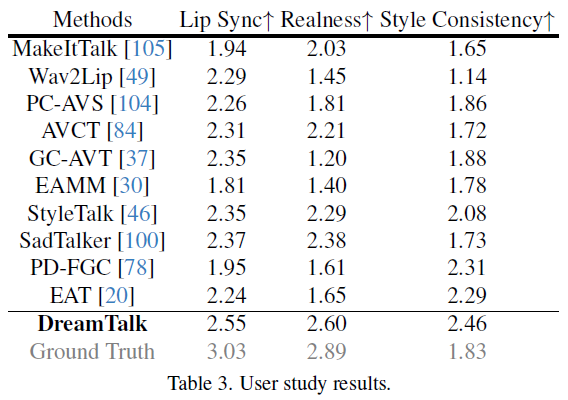
用户研究
用户研究共有20名参与者,测试样本涵盖多种说话风格和说话人。每种方法都需要参与者对10个视频进行评分,评分包括三个方面:唇同步质量、结果真实性和生成视频与风格参考之间的一致性。结果表明,该方法在所有方面均优于现有方法,尤其是在风格一致性方面表现出色。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











