







简介
由于深度学习方法的快速发展,近年来,用于执行图像边缘检测的卷积神经网络(CNN)模型爆炸性地传播。但边缘检测的大多数工作都致力于通过设计非常深入的网络来实现更高的度量(即ODS、OIS、AP),这导致了计算操作数量的增加。然而,这些边缘检测方法对于低容量设备和现实世界的应用并不实用。考虑到上述缺点,提出了一种新的轻量级结构LDC——用于边缘检测的轻量级密集CNN模型。它旨在成为现实世界应用程序的实用网络,可以自适应地学习关注高频信息的最有价值的特征。所提出的体系结构基于DexiNed,但为了在性能和适用性之间寻求更好的折衷,考虑了较小的滤波器尺寸和紧凑的模块。作为所提出的修改的结果,获得了一个参数少于1M的模型,并且比大多数最先进的方法轻。LDC 是一种基于 CNN 的边缘检测模型,与参数小于100万的轻量级模型相比,LDC生成了薄边缘图并取得了最高分数(即ODS),与参数约为3500万的重型体系结构相比,性能相似。LDC提供了使用不同边缘检测数据集的定量和定性结果,并与现有技术模型进行了比较。所提出的LDC不使用预训练的权重,需要直接的超参数设置。
详细内容可参考代码:https://github.com/xavysp/LDC。
• 提出了一种轻量级CNN架构,参数仅为674K个,而DexiNed中有35M个参数。
• 与最先进的边缘检测器(参数少于1M)进行了广泛的比较研究。本文完全致力于边缘检测,即所有进行定量比较的模型都使用BIPED、MDBD和新的BRIND数据集进行训练和验证。此外,每个模型都使用其他数据集进行交叉验证。
• 进行了深入的消融研究,以确保LDC的稳健性。

边缘检测
基于深度学习的边缘检测器
深度学习方法在图像边缘检测领域取得了显著进展。其中,HED是一种基于VGG16架构的深度监督模型,使用交叉熵损失函数实现了端到端的边缘训练。基于HED架构,还提出了几种模型,如CED、RCF、BDCN等,大多数使用VGG16或ResNet作为主干架构,并进行了中间边缘融合和损失函数修改。然而,这些模型通常需要大量的参数和计算资源。为了解决这一问题,DexiNed提出了部分基于Xception的CNN架构,使用新的训练数据集。尽管DexiNed参数多达35M,但它在边缘检测数据集上取得了最佳结果。另一种边缘检测算法CATS使用了新型损失函数,通过交叉熵实现了更干净、更薄的边缘图。除此之外,还有一些使用GAN模型和Transformers的方法,虽然取得了一定的改进,但往往需要更多的计算资源。鉴于此,轻量级模型(通常参数少于1M)的发展变得越来越重要,例如TIN和PiDiNet架构,它们通过减小内核大小和手动内核设置来减少参数。
边缘检测数据集
边缘检测数据集对于训练和评估边缘检测算法至关重要。CID是一个用于轮廓检测的数据集,由40个灰度图像组成。BSDS300和BSDS500是广泛使用的数据集,虽然注释主要用于边界检测,但有些图像也进行了边缘级别的注释。此外,纽约大学室内数据集和其他语义分割数据集也被考虑用于边缘检测。Multicue数据集包含边界和边缘级别的多个注释,适用于边界检测。近年来,BIPED和BRIND数据集专门用于感知边缘检测,并为LDC等模型的训练提供了有价值的数据。
模型方法
卷积神经网络架构
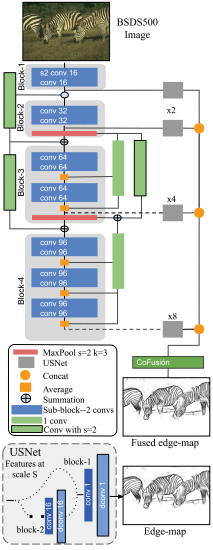
DexiNed体系结构由密集极端初始网络Dexi和上采样块USNet两个子网组成。Dexi由6个受xception网络启发的输出区块组成;每个区块都连接有两种类型的跳过连接。USNet是一个条件CNN,用于升级和转换边缘图中的特征图,其大小与Dexi子网的输入图像相同。这种架构产生了一个具有35M参数的模型。
为了生成LDC架构,对DexiNed进行了以下修改:
-
LDC仅使用了DexiNed的四个区块。
-
LDC减小了Dexi的滤波器大小,以轻微增加参数数量。
-
LDC生成四个中间边缘图预测,最终结果来自这些预测的融合。融合策略受到CATS的启发,称为上下文感知融合块或CoFusion。为减少参数数量,CoFusion操作稍作修改,LDC使用了较少的卷积层和归一化组。
-
对于LDC中的中间边缘图形成,USNet与DexiNed中的配置相同。
-
最后,为了训练LDC,对CATS的损失函数进行了轻微修改。
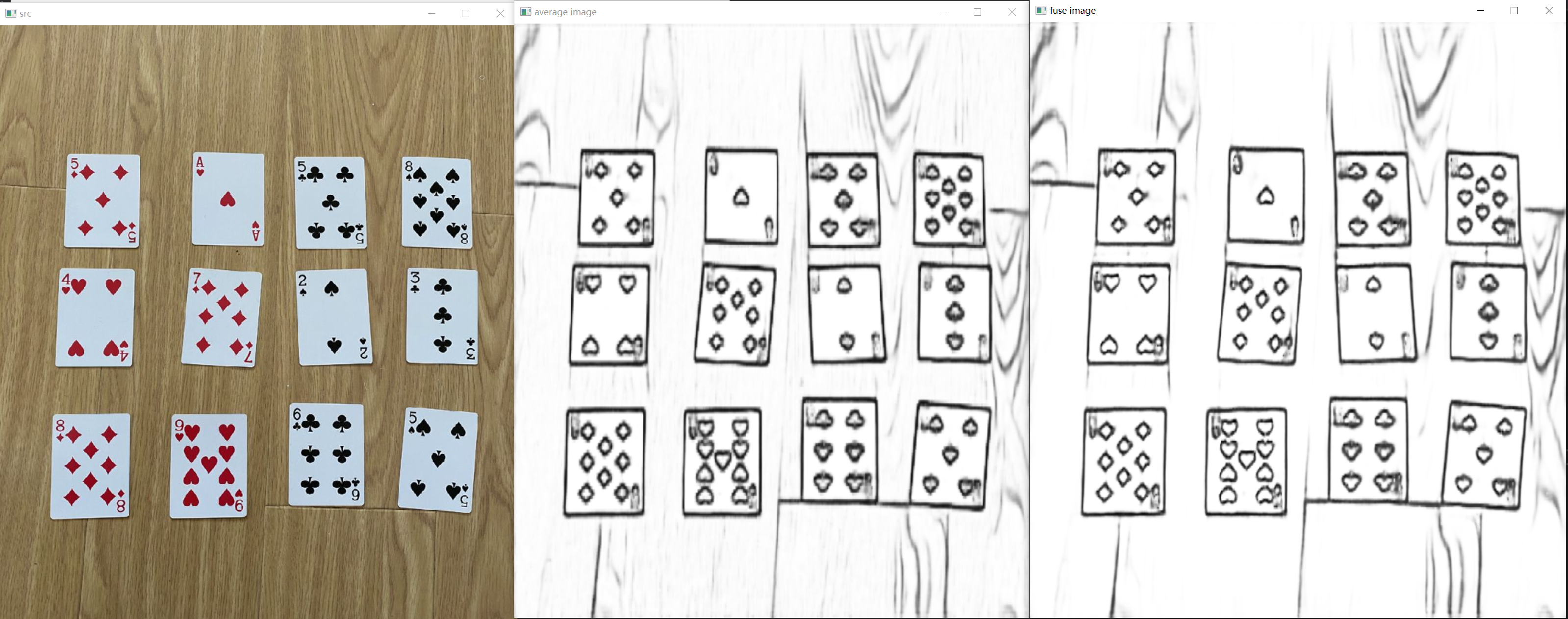
C++代码实现推理
ONNX Runtime 是一个开源的跨平台推理引擎,由微软开发并维护。它支持在各种硬件和操作系统上进行模型推理,包括 CPU、GPU 和专用加速器。ONNX Runtime 支持使用 ONNX(Open Neural Network Exchange)格式的模型,这是一种用于表示深度学习模型的开放标准。使用 ONNX Runtime,您可以轻松地在不同的部署环境中运行深度学习模型,并获得高性能和低延迟的推理结果。
#include <string>
#include <math.h>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
//#include <cuda_provider_factory.h>
#include <onnxruntime_cxx_api.h>
using namespace cv;
using namespace std;
using namespace Ort;
class LDC
{
public:
LDC(string modelpath);
void detect(Mat srcimg, Mat& average_image, Mat& fuse_image);
private:
vector<float> input_image_;
int inpWidth;
int inpHeight;
int outWidth;
int outHeight;
int num_outs;
Env env = Env(ORT_LOGGING_LEVEL_ERROR, "LDC");
Ort::Session* ort_session = nullptr;
SessionOptions sessionOptions = SessionOptions();
vector<char*> input_names;
vector<char*> output_names;
vector<vector<int64_t>> input_node_dims; // >=1 outputs
vector<vector<int64_t>> output_node_dims; // >=1 outputs
};
LDC::LDC(string model_path)
{
std::wstring widestr = std::wstring(model_path.begin(), model_path.end());
//OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0);
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
ort_session = new Session(env, widestr.c_str(), sessionOptions);
size_t numInputNodes = ort_session->GetInputCount();
size_t numOutputNodes = ort_session->GetOutputCount();
AllocatorWithDefaultOptions allocator;
for (int i = 0; i < numInputNodes; i++)
{
input_names.push_back(ort_session->GetInputName(i, allocator));
Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_node_dims.push_back(input_dims);
}
for (int i = 0; i < numOutputNodes; i++)
{
output_names.push_back(ort_session->GetOutputName(i, allocator));
Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_node_dims.push_back(output_dims);
}
this->inpHeight = input_node_dims[0][2];
this->inpWidth = input_node_dims[0][3];
this->outHeight = output_node_dims[0][2];
this->outWidth = output_node_dims[0][3];
this->num_outs = output_node_dims.size();
}
void LDC::detect(Mat srcimg, Mat& average_image, Mat& fuse_image)
{
Mat dstimg;
resize(srcimg, dstimg, Size(this->inpWidth, this->inpHeight));
this->input_image_.resize(this->inpWidth * this->inpHeight * dstimg.channels());
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < this->inpHeight; i++)
{
for (int j = 0; j < this->inpWidth; j++)
{
float pix = dstimg.ptr<uchar>(i)[j * 3 + 2 - c];
this->input_image_[c * this->inpHeight * this->inpWidth + i * this->inpWidth + j] = pix;
}
}
}
array<int64_t, 4> input_shape_{ 1, 3, this->inpHeight, this->inpWidth };
auto allocator_info = MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
Value input_tensor_ = Value::CreateTensor<float>(allocator_info, input_image_.data(), input_image_.size(), input_shape_.data(), input_shape_.size());
// 开始推理
vector<Value> ort_outputs = ort_session->Run(RunOptions{ nullptr }, &input_names[0], &input_tensor_, 1, output_names.data(), output_names.size()); // 开始推理
for (int n = 0; n < num_outs; n++)
{
float* pred = ort_outputs[n].GetTensorMutableData<float>();
Mat result(outHeight, outWidth, CV_32FC1, pred);
Mat TmpExp;
cv::exp(-result, TmpExp); ///不用for循环
Mat mask = 1.0 / (1.0 + TmpExp);
double min_value, max_value;
minMaxLoc(mask, &min_value, &max_value, 0, 0);
mask = (mask - min_value) * 255.0 / (max_value - min_value + 1e-12);
mask.convertTo(mask, CV_8UC1);
bitwise_not(mask, mask);
resize(mask, mask, Size(srcimg.cols, srcimg.rows));
accumulate(mask, average_image); //将所有图像叠加
fuse_image = mask;
}
average_image = average_image / (float)num_outs; //求出平均图像
average_image.convertTo(average_image, CV_8UC1);
}
int main()
{
LDC net("models/LDC_640x360.onnx");
std::string path = "images";
std::vector<std::string> filenames;
cv::glob(path, filenames, false);
for (auto img_name : filenames)
{
cv::Mat cv_src = cv::imread(img_name, 1);
Mat average_image = Mat::zeros(cv_src.rows, cv_src.cols, CV_32FC1);
Mat fuse_image(cv_src.rows, cv_src.cols, CV_8UC1);
net.detect(cv_src, average_image, fuse_image);
namedWindow("src", WINDOW_NORMAL);
imshow("src", cv_src);
namedWindow("average image", WINDOW_NORMAL);
imshow("average image", average_image);
namedWindow("fuse image", WINDOW_NORMAL);
imshow("fuse image", fuse_image);
waitKey(0);
}
}

















 3090
3090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











