







1. 介绍
扩散模型作为一类生成模型,已经因其在生成高质量图像和视频方面的显著成就而受到广泛关注。它们以卓越的图像质量和丰富的多样性脱颖而出。不过,扩散模型在图像生成过程中需要执行大量的采样步骤,这使得整个估计过程变得相对缓慢。
与此同时,生成对抗网络(GANs)以其简洁的单步生成和快速采样能力而闻名。尽管已有尝试将GANs应用于更广泛的数据集,但在样本质量方面,它们往往无法与扩散模型相媲美。此外,GANs在生成图像多样性方面也存在局限。
本文旨在结合扩散模型的高样本质量和GANs的快速采样优势。为此,提出了一种融合两种训练目标的新方法:
- 对抗性损失(Adversarial Loss)
- 与分馏采样(Seeded Distillation Sampling, SDS)相匹配的蒸馏损失(Distillation Loss)
通过引入鉴别器,对抗性损失能够比较真实图像与生成图像,有效避免了其他蒸馏技术中常见的模糊和伪影问题。而蒸馏损失则利用了一个预先训练好的(静态的)扩散模型作为“教师”,借助其丰富的知识库,以一种高效的方式进行知识传递。
这里提出的方法在性能上超越了现有的最先进扩散模型SOTA SDXL,能够在仅需一到四个采样步骤的情况下生成高保真的实时图像。这标志着生成模型领域的一个重大进步,为未来生成任务的效率和质量提供了新的可能性。
论文地址:https://arxiv.org/pdf/2311.17042.pdf
源码地址:https://github.com/cumulo-autumn/streamdiffusion
2.模型架构
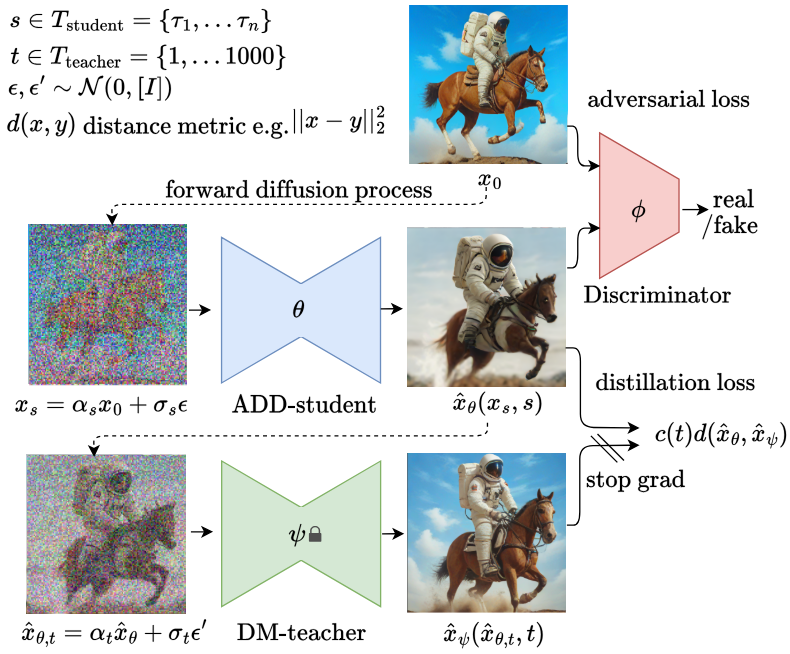
2.1 训练程序
训练过程如上图所示,其中主模型 ADD-student由三个预先训练过的权重为 θ 的扩散模型(UNet-DM)、一个可训练权重为 j 的判别器和一个权重为 ψ 的 DM-Teacher (扩散模型)组成。使用的模型
对于对抗损失,生成的样本 x ^ θ \hat{x}_\theta x^θ 和实际图像 x 0 x_0 x0 被传递给一个判别器来区分它们。 下一节将详细介绍判别器和对抗损失的设计。 为了从 DM-Teacher 中提炼知识,ADD-学生样本 x ^ θ \hat{x}_\theta x^θ 被扩散到教师(DM-Teacher)的前瞻过程 x ^ θ , t \hat{x}_{\theta,t} x^θ,t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











