







1. 概述
人脸识别研究通常使用从网上收集的人脸图像数据集,但这些数据集可能包含重复的人脸图像。为了解决这个问题,我们需要一种方法来检测人脸图像数据集中的重复图像,并提高其质量。本文介绍了一种检测人脸图像数据集中重复图像的方法。该方法适用于从网络上收集的五个人脸图像数据集(LFW、TinyFace、Adience(已对齐)、CASIA-WebFace 和 C-MS-Celeb(已对齐))。这些去重数据集均可公开获取。还对人脸识别模型进行了实验,以研究去重复数据集的影响。
论文地址:https://arxiv.org/pdf/2401.14088.pdf
源码地址:https://github.com/dasec/dataset-duplicates
2. 重复检测方法
本文研究了精确重复(完全匹配的重复图像)和近似重复(不完全匹配但应视为重复图像)的检测方法。
所谓 “完全重复”,是指通过比较数据,两份数据完全匹配,即可识别出重复数据。为了提高计算效率,我们使用 BLAKE3 哈希算法收集一组初始数据来检测重复数据。由于相同的数据总是产生相同的哈希值,因此不会出现因哈希值而导致的假阴性,但会出现假阳性(哈希碰撞)。因此,我们引入了一个额外的步骤来检查文件数据是否与哈希值发现的重复数据集完全匹配。虽然这只是一个非常简单的检查步骤,但我们却能在所有数据集中检测到 “完全重复”(请注意,结果显示,这里应用的五个数据集在创建时并未执行此类检查)。
其次是 “近似重复”,指的是略有不同但应视为重复的相似图像,例如在人脸识别研究中。下图就是一个例子。

这种 "近乎重复 "的定义各不相同。本文根据 Python 软件包 "ImageHash "的默认设置,使用了两种图像散列方法 "pHash(感知散列)"和 “抗裁剪散列”。
与 "抗裁剪散列 "相比,"pHash "检测到的重复图像更多,这表明 "抗裁剪散列 "在某些情况下可能无法成功应用。图像散列功能检测到的重复图像集可能会重叠,因此纠正误报和合并(删除)重复图像集是去重过程的重要组成部分。
人脸识别和人脸图像质量评估模型依赖于人脸图像预处理。这些模型根据检测到的面部地标对原始人脸图像进行裁剪和对齐。本文介绍的重复检测方法对这种预处理后的人脸图像效果很好。
这是因为预处理所需的面部地标检测可能会在某些图像上失效,而且预处理/原始图像的变化可能会产生一组没有自己的重复图像。因此,应该在对未改动的原始图像进行重复检测后,再进行额外的步骤。
本文使用 ArcFace 中使用的相似性变换对人脸图像进行预处理。在检测到多张人脸的图像中,根据检测边界框的宽度和高度、与图像中心的距离以及检测器的置信度分数来选择主要人脸。所有预处理图像的宽度和高度均为 112 x 112。下图显示了一个预处理样本。
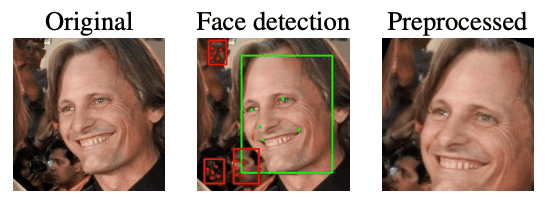
地标检测失败的人脸图像数量分别为:LFW 为 0,TinyFace 为 859(根据原始图像的检测结果,只有 4 幅重复),Adience 为 79(9 幅重复),CASIA-WebFace 为 129(2 幅重复),C-MS-Celeb 为 6。179 幅图像(351 幅重复)。这些图像在额外的重复检测步骤中不予考虑,建议在验证原始图像后作为额外步骤进行。
下表概述了所研究的数据集,显示了图像和重复图像的总数。Intra "表示主体内重复(重复集中的所有图像只属于一个主体),"Subjects-w.-intra "表示至少有一个主体内重复的主体,"Inter "表示主体间重复(重复集中的所有图像属于多个主体),"Subjects-w.-inter "表示至少有一个主体间重复的主体。Subjects-w.-inter "代表至少有一个主体间重叠的主体。

LFW、TinyFace 和 Adience 各包含不到 20,000 张人脸图像;CASIA-WebFace 和 C-MS-Celeb 分别包含 494,414 和 6,464,016 张人脸图像;只有 LFW 有极少量的重复;CASIA-WebFace 和 C-MS-Celeb 包含超过 20,000 张人脸图像。TinyFace 还包含 153428 张非人脸图像,本文不考虑这些图像。CASIA-WebFace 中重复图像的绝对数量高于较小的数据集,但重复图像占人脸图像总数的比例相对较低。(不包括 LFW)。
C-MS-Celeb 是 MS-Celeb1M 的子集,带有干净的主题标签。本文使用的是 ALIGNED 版本。在所研究的所有数据集中,该数据集的重复绝对数最高,相对于人脸图像总数的重复比例也最高。在该数据集中,有 33918 张主体间重复图像同时也是主体内重复图像。因此,属于某些重复集的图像总数为 885 476 张。这种主体内/主体间重复的重叠现象在其他数据集中并不存在,因此每个数据集的总数量只是主体内和主体间数量的总和
重复检测方法可用于识别单个数据集内部以及多个数据集之间的重复数据。这种方法可以消除从不同来源收集的数据集之间的无意重复。在使用预处理图像时,数据集之间发现了新的重复数据,这些重复数据被人工识别为真阳性数据(主要是 CASIA-WebFace 和 C-MS-Celeb 之间的重复数据,在其他地方也有发现)。
3. 删除重复数据的方法
本节介绍如何从数据集中有效识别和删除重复图像。第一种方法是从重复图像集中选择并存储具有代表性的图像。这样既能消除不必要的重复,又能保留数据集中的重要信息。从包含完全相同图像的集合中选择第一张图像,按词典顺序而不是随机排序,可确保可重复性。
如果在不同类别之间发现重复图像,则通过更复杂的程序将图像重新分配到相应类别。重复的图像会与所有相关类别中不重叠的图像进行比较,然后分配到相似度最高的类别中。但是,如果平均相似度得分较低或候选类别之间的得分差距较小,则会将图像从数据集中排除,以避免错误分配。
它还能纠正误报。用于检测近似图像的图像散列技术可能会错误地将不同图像视为重复图像。为了纠正这种误报,需要使用人脸识别技术来识别实际不同的图像,并将其排除在外。这一步骤可过滤掉相似度得分低于一定阈值的图像对,从而减少误报。
纠正误报后,再次根据质量得分对图像进行排序。在此,质量得分最高的图像被选为重复图像集的代表。无法计算质量分数的图像会自动排在列表的底部,优先处理已计算分数的图像。
4. 试验
在此,我们将研究去重复如何改变人脸识别模型。人脸识别需要选择匹配和不匹配的人脸图像对。
对于配对,一种方法是为每个受试者选择所有可能的配对。然而,对于数据集中图像数量相对较多的目标,这种方法会大大增加配对的数量(一个有 N 幅图像的目标会产生 (N-(N-1))/2 对配对,每幅图像会产生 N-1 对配对)。对)。
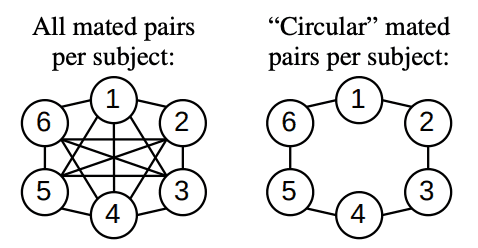
不过,由于这些实验的目的是比较有无重叠数据集的结果,因此每幅图像的匹配对数量最好保持平衡。因此,本文为数据集中的每个对象 "循环 "选择匹配对。简单地说,就是索引 i 处的图像与下一个索引 i+1 处的图像形成匹配对。如果目标有多幅图像,最后一幅图像也会与第一幅图像配对。
因此,有两幅或两幅以上图像的目标将有与图像数量相等的匹配对,而正好有两幅图像的目标将有一幅匹配对。至于图像的顺序,则按图像路径的词典顺序升序排列。这种 "循环 "选择匹配对的方法可以用相对较少的计算资源来实现。
以下是每个数据集的配对数量,以及由于只包含单幅图像而被排除在外的目标数量。
- TinyFace:11 881 人(153 人被排除在外)。
- 人数:18 093 人(815 人不包括在内)
- CASIA-WebFace:494 284(不包括目标 0)
- C-MS-Celeb:6 457 562 人(123 人被排除在外)
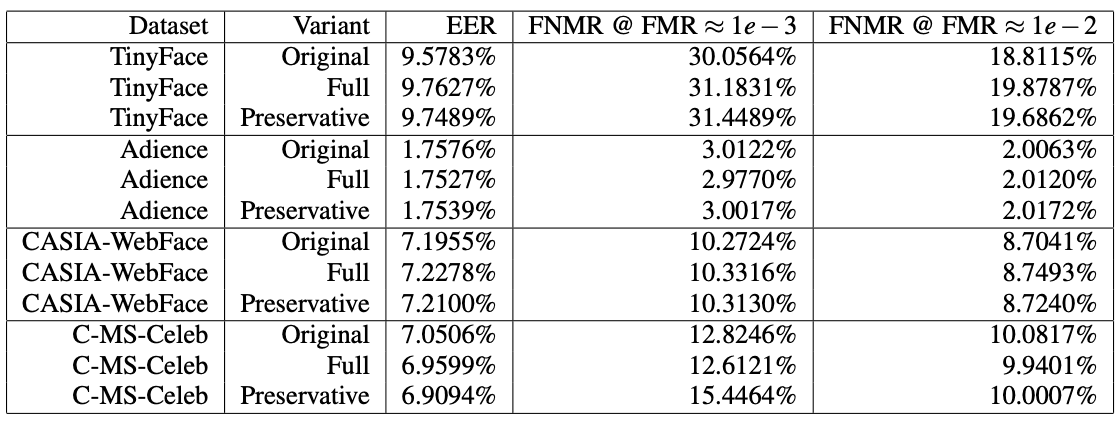
对于每个数据集,随机抽取与匹配数据对数量相等的非匹配数据对。MagFace 模型用于人脸识别。然后使用相似性分数来评估人脸识别的错误非匹配率 (FNMR)、错误匹配率 (FMR) 和相等错误率 (EER) 的性能。
下表显示了结果。可以看出,有重复和无重复的变体之间主要存在微小差异,在不同情况下,去除重复的变体会增加或减少错误率。
5.总结
本文介绍了一种基于哈希函数的重复人脸图像检测方法。它还提出了如何在预处理过的人脸图像和原始图像上使用这一方法。利用这些方法,我们检测了通过网络搜刮收集的五个具有代表性的人脸图像数据集的重复图像。
除 LFW 数据集外,每个数据集中都有超过 1%的图像被认为是重复图像,从数百到数十万不等。大多数重复图像属于一个数据集目标(目标内重复),但也有一些,尤其是在 C-MS-Celeb 数据集中,属于多个目标(目标间重复)。
它还展示了如何从数据集中有效识别和删除重复图像。本研究提出了减少假阳性重复图像、为每个重复图像集选择最高质量的人脸图像以及将去重复人脸图像分配给目标间重复图像集中最适合的目标(如果不确定,则不分配)等建议。它还显示了去重在人脸识别模型中的影响。
如本文所示,典型的人脸识别人脸图像数据集包含大量重复图像,这一事实表明,网络抓取的人脸图像数据集出现重复图像的风险很高,今后在构建数据集时应考虑实施重复图像过滤器。
请注意,本文所涉及的五个数据集的重复数据集可在 GitHub 上获取。
https://github.com/dasec/dataset-duplicates




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











