







概述
论文地址:https://arxiv.org/abs/2404.12926
人工智能的发展正在改变我们的学习方式。特别是使用大规模语言模型(LLM)的聊天机器人,通过提供个性化指导和即时反馈,极大地拓展了教育的可能性。
然而,在将 LLM 应用于教育领域方面仍存在许多挑战。例如,在物理解题中,计算数学公式和理解概念至关重要,但 LLM 在这些方面表现不佳。此外,当问题陈述包含图像时,也很难适当地处理这些信息。
因此,在本研究中,我们开发了一个 LLM 聊天机器人,专门用于印度高中物理选择题。通过使用强化学习和图像字幕,我们成功地大幅提高了 LLM 的解题和推理能力。这项研究为开启人工智能时代的教育革命之门迈出了一步。
相关研究
相关研究包括视觉语言模型(VLMs)的开发:Flamingo、GPT4、LLaVA 系列和 MiniGPT4 等模型能够处理视觉和语言综合信息,在视觉问题解答任务中表现出色。它们显示了此外,VisionLLM、Kosmos-2 和 Qwen-VL 等模型的视觉接地能力也有所提高。
对于从人类反馈中强化学习(RLHF)来说,最初的重点是文本总结和问题解答等任务,但后来逐渐被应用于改进通用语言模型。从人类反馈中强化学习(RLHF)最初的重点是文本摘要和问题解答等任务,后来逐渐应用于改进通用语言模型。
就图像说明而言,它们已被证明能有效减少 LLM 流形处理的局限性和模糊性。使用图像说明可为 LLM 提供更多上下文信息,并有望提高准确性。
LLM 在教育领域的应用包括提供个性化学习材料、提高生产率和普及性。此外,还在研究开发基于 LLM 的学生助理和编程作业自动反馈。
然而,对数学教育中的 ChatGPT 进行的评估表明,在领域适应性和语境理解方面仍有改进的余地。基于这些相关研究,我们正在开发一款专门用于物理教育的 LLM 聊天机器人。
建议方法
1. 使用 MM-PhyQA 数据集
- 印度高中物理选择题数据集 - 包括问题文本、选项、正确答案和解释 - 3,700 个研究样本和 676 个测试样本
2. 添加图片说明
- 对每幅问题图像进行详细描述 - 利用 Infi-MM 模型生成图像说明 - 尽量减少幻觉和图像处理错误
3. 联合联络小组的应用
将人类反馈纳入模型学习过程 - 从 MM-PhyQA 数据集中选择 2,000 个样本并使用 5 个模型进行推理- 使用 Gemini Pro 对推理结果进行排序- 将排序最高的回应与其他回应配对以创建 8,000 个优先级数据集- 使用优先级数据集训练奖励模型(RM)- 使用 PPO 算法用 RM 更新 LLM
使用优先级数据集训练奖励模型 (RM) - 使用 PPO 算法用 RM 更新 LLM
4. 微调
- 使用 7B、13B 和 13B LoRA 大型版本的 LLaVA 1.5 模型 - 使用 MM-PhyQA 数据集进行微调 - 使用 PEFT 进行高效参数学习
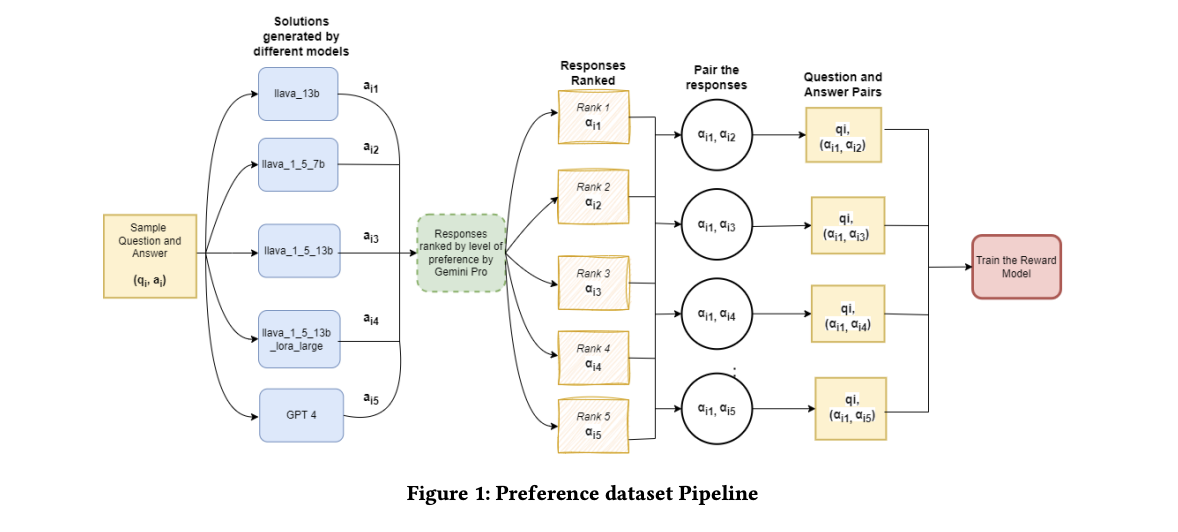
图 1 是拟议方法的概览:RLHF 流程通过创建优先数据集和学习奖励模型来提高 LLM 的推断能力。
通过实验,可以比较拟议方法在以下六种情况下的性能,从而对其进行评估
- 使用(问题文本/答案、图像、标题)进行微调
2.使用(问题文本/答案、标题)进行微调
3.使用(问题文本/答案、图像)进行微调
- 将 RLHF 应用于 1
5.将 RLHF 应用于 2
6.将 RLHF 应用于3
试验
表 1 至表 3 显示了在上一节所述的六种实验设置中,在不使用 RLHF 的设置 1 至设置 3 的情况下,每个模型与测试数据的对比精度。

表 1 显示了仅使用问题文本、答案和图像进行微调的结果,LLaVA 1.5 的 7B、13B 和 13B LoRA 大型模型的准确率分别为 53.3%、52.7% 和 53.1%,没有显著差异。
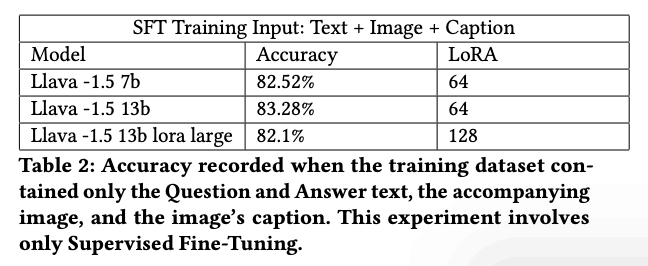 表 2 显示了使用问题文本和答案、图像和标题进行微调的结果。添加图片说明后,准确率明显提高,LLaVA 1.5 7B、13B 和 13B LoRA 大型模型的准确率分别达到 82.52%、83.28% 和 82.1%,这表明图片说明有助于提高 LLM 性能。
表 2 显示了使用问题文本和答案、图像和标题进行微调的结果。添加图片说明后,准确率明显提高,LLaVA 1.5 7B、13B 和 13B LoRA 大型模型的准确率分别达到 82.52%、83.28% 和 82.1%,这表明图片说明有助于提高 LLM 性能。
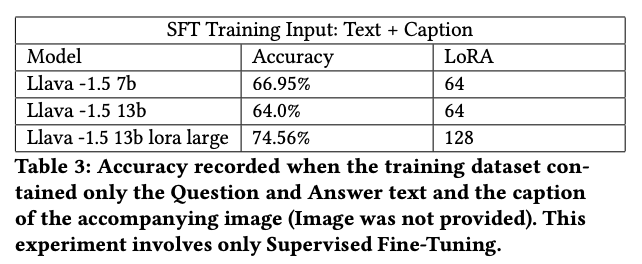 表 3 显示了仅使用问题文本、答案和标题进行微调的结果。即使没有图像,使用说明也能提高准确率:LLaVA 1.5 中 7B、13B 和 13B LoRA 大型模型的准确率分别为 66.95%、64.0% 和 74.56%。
表 3 显示了仅使用问题文本、答案和标题进行微调的结果。即使没有图像,使用说明也能提高准确率:LLaVA 1.5 中 7B、13B 和 13B LoRA 大型模型的准确率分别为 66.95%、64.0% 和 74.56%。
这些结果表明,图像说明在提高 LLM 成绩方面发挥了重要作用。增加图片说明可能会提高解决问题的成绩,因为它们为 LLM 提供了更多的上下文信息。
不过,本文没有介绍应用 RLHF 的设置 4 至设置 6 的结果,因此无法讨论 RLHF 的效果;预计 RLHF 的应用将进一步提高 LLM 的推理能力,但验证这一点是未来的任务。
此外,由于本研究中使用的 MM-PhyQA 数据集专门针对印度高中物理问题,因此需要进一步研究拟议方法对其他学科和难度水平问题的有效性。
结论
本研究在 MM-PhyQA 数据集上引入了图像标题和 RLHF 这两种方法,目的是开发一款专门针对印度高中物理选择题的 LLM 聊天机器人。实验结果表明,添加图片说明能显著提高 LLM 的准确性。另一方面,RLHF 的有效性还需要进一步验证。
今后,还需要解决各种问题,包括验证 RLHF 的有效性、将其应用于其他领域、在实际教育环境中使用以及伦理方面的考虑。本研究为 LLHF 在教育领域的应用提供了重要见解,有望为人工智能教育研究的发展做出贡献。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











