







摘要
大规模语言模型的出现是提高病人护理质量和临床操作效率的一个重大突破。大规模语言模型拥有数百亿个参数,通过海量文本数据训练而成,能够生成类似人类的反应并执行复杂的任务。这在改进临床文档、提高诊断准确性和管理病人护理方面显示出巨大的潜力。然而,像 ChatGPT 和 GPT-4 这样的大规模语言模型是封闭的,很难针对医疗保健领域所需的特定情况进行定制。
为解决这一问题,近年来开发了开源大规模语言模型。开源大规模语言模型是一种很有前景的解决方案,它提供了无限的访问权限,并可根据医疗保健领域的特定需求灵活定制。例如,LLaMA 模型是通用领域开源大规模语言模型的佼佼者,具有最先进的功能。但是,由于这些模型主要是在通用领域数据的基础上进行训练的,因此缺乏准确可靠的医疗应用所需的专业知识。
为了弥补这些不足,目前正在开发专门用于医疗保健的开源大规模语言模型,通过生物医学数据对其进行增强。然而,现有的研究,如 PMC-LaMA 和 Meditron,主要集中在生物医学领域,而且只评估问题解答(QA)任务。只有 GatorTronGPT 和 Clinical-LaMA 是例外。然而,由于缺乏教学协调以及模型和数据规模的限制,GatorTronGPT并未在各种临床环境中充分利用大规模语言模型,而 Clinical-LaMA 对临床文本的先验学习也很有限。此外,它还存在 "灾难性遗忘 "问题,即在整合新的医疗数据时,先前的知识会受到影响。
为了应对这些挑战,本文开发了一种新的大规模医学语言模型Me-LaMA,该模型可持续预训练 LLaMA2 模型、调整指令并纳入丰富的生物医学和临床数据。
这为研究医疗保健领域的大规模语言模型提供了一个全面的数据集,其中还包括一个大型预训练数据集、一个教学协调数据集和一个新的医疗评估基准 (MIBE)。
在使用 MIBE 进行的评估中,Me-LaMA 模型在零射、四射和监督学习方面的表现优于现有的开源大规模医学语言模型。通过针对特定任务的指令调整,Me-LaMA 模型在许多数据集上的表现优于 ChatGPT 和 GPT-4。
技术
Me-LaMA 是通过对 LLaMA2 的持续预研究和教学调整开发出来的。该过程包括 129B 标记样本和 214K 指示性研究,其中包括一般、生物医学和临床数据。
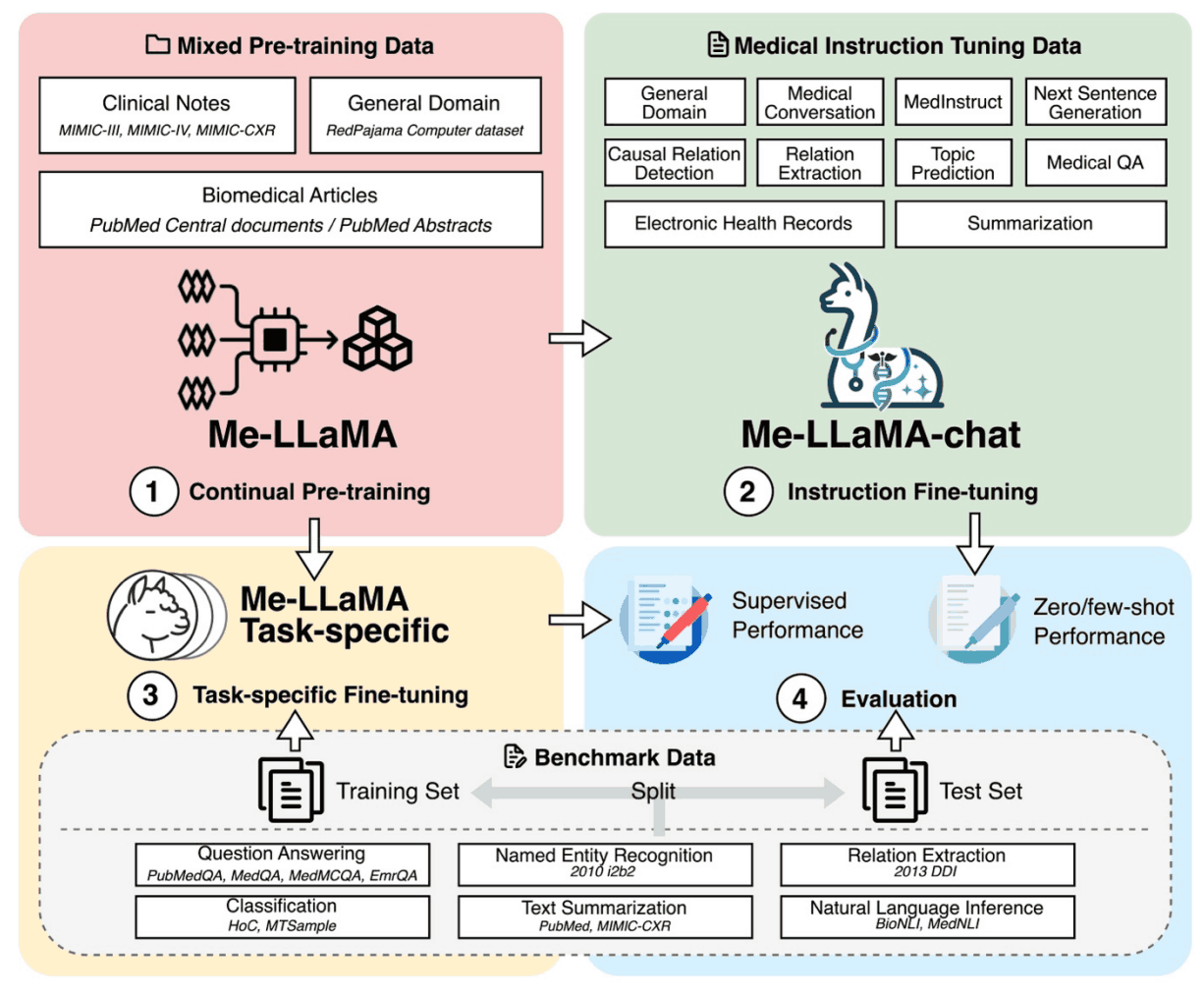
为使 LLaMA2 模型适用于医疗领域,我们创建了一个混合连续预训练数据集。该数据集包含 129B 标记,由生物医学文献、临床笔记和一般领域数据组成。这平衡了特定领域知识与广泛的上下文理解,减少了灾难性遗忘。
- 生物医学文献
- 它包含大量从 PubMed Central 和 PubMed Abstracts 收集的生物医学文献。
- 临床说明
- 使用 MIMIC-III、MIMIC-IV 和 MIMIC-CXR 中的匿名自由文本临床笔记来反映真实的临床场景和推理。
- 一般部门数据
- 为防止灾难性遗忘,我们重现了 LLaMA 研究前的数据,包括 RedPaja
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











