







摘要
论文地址:https://arxiv.org/pdf/2405.07990
大数据和计算能力的飞速发展使得 ChatGPT 和 GPT-4 等大规模语言模型在商业和学术界都备受关注。与此同时,多模态大规模语言模型也在迅速发展,包括 GPT-4V、Gemini、Claude-3 以及开源模型 LLaVA 和 Mini-GPT。为了评估这些模型对视觉信息的解释能力,已经创建了各种评估基准,但仍然缺乏对 "文本密集图像中的图表 "的研究。
本文评估了多模态大规模语言模型生成有效渲染图像的代码的能力,并展示了它们在多模态理解和推理方面的能力。多模态大规模语言模型准确解读视觉信息并将其与文本关联起来生成可执行代码的问题被认为是未来研究的一个重要课题。
因此,本文提出了一个新的评估基准–Plot2Code。该基准旨在评估多模态大规模语言模型的多模态理解、推理和编码能力,使用的数据集包含 132 个 matplotlib 图形。每个图都附有相应的代码和详细说明,并为各种输入和输出格式提供了评估设置。此外,该基准还用于评估14 个公开的多模态大规模语言模型。结果表明,视觉信息编码任务还有改进的余地。
下图展示了 Plot2Code 的概况。(a) Plot2Code 数据集中具有代表性的参考图样本 (b) 多模态大规模语言模型使用参考图像生成的参考图样本,以及 © 一个全面的管道。
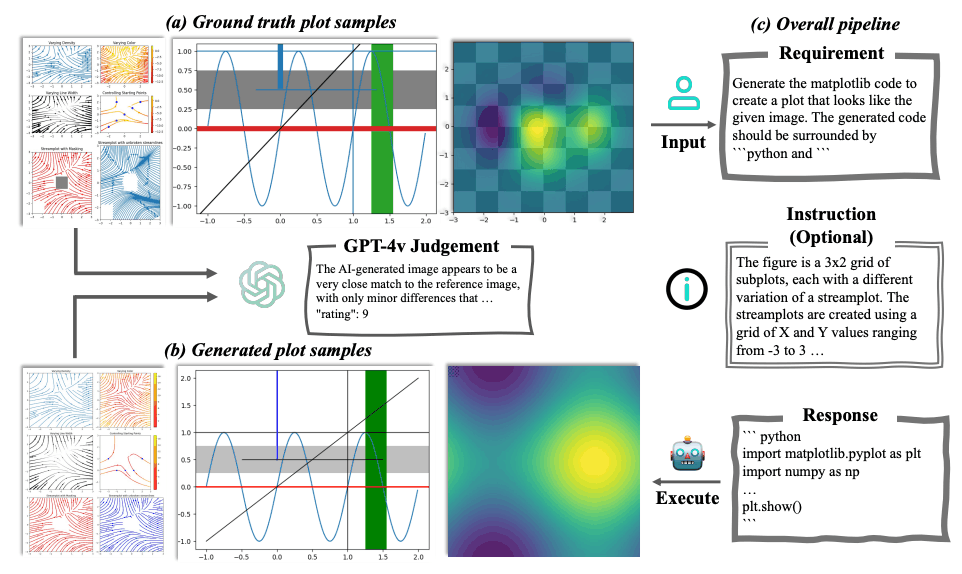
希望Plot2Code 今后能被研究界有效利用,以促进多模态大规模语言模型的进一步研究和开发。
建立 Plot2Code 基准
本节将介绍基准数据的收集和处理过程。首先,我们抓取 matplotlib 图库中列出的所有网站链接,并从相应的 HTML 文件中提取代码块。这样就获得了 841 个代码块,然后进行了包括过滤在内的多项处理。下图显示了一个 Plot2Code 基准示例。
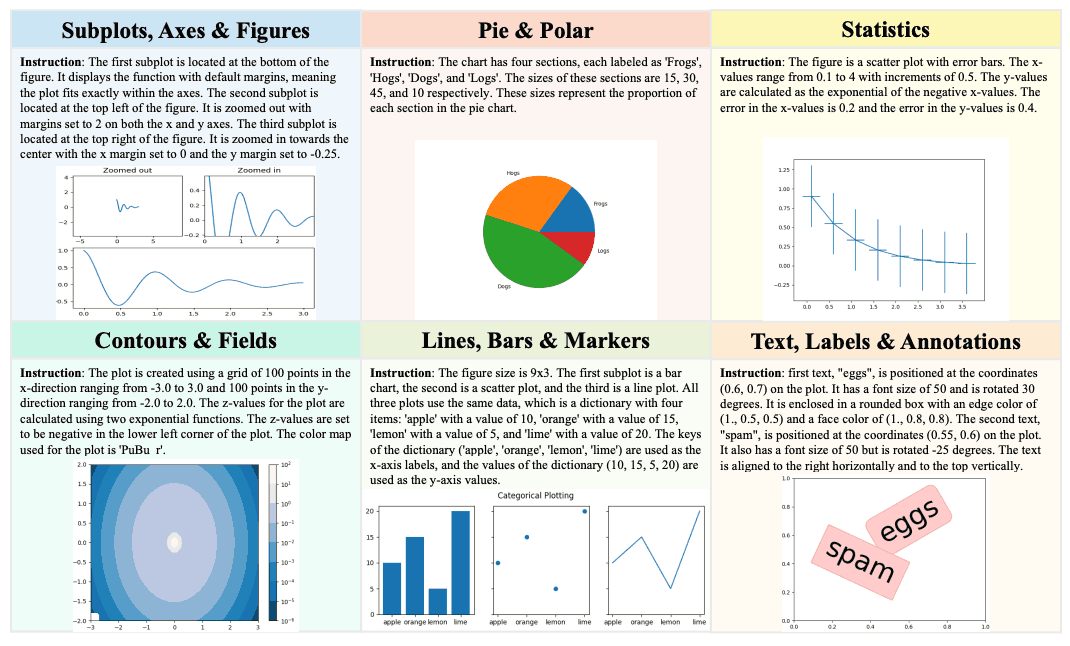
首先,我们获得了结构化的绘图和代码对,从而可以有效评估多模态大规模语言模型的代码生成能力。最初抓取的 Python 代码并不一定适合生成高质量的绘图。因此,我们采用了自动处理和人工过滤相结合的方法。
收集到的数据可能在单个 HTML 文件中包含多个代码段,有些代码段可能包含导入行或初始化函数,导致无法生成绘图。为此,我们只从包含单个代码段的 HTML 文件中提取代码。这样就能确保包含所有重要组件,并在没有任何额外依赖的情况下生成绘图。所有无法生成绘图的代码都会被过滤掉,最终生成 529 对绘图和代码。
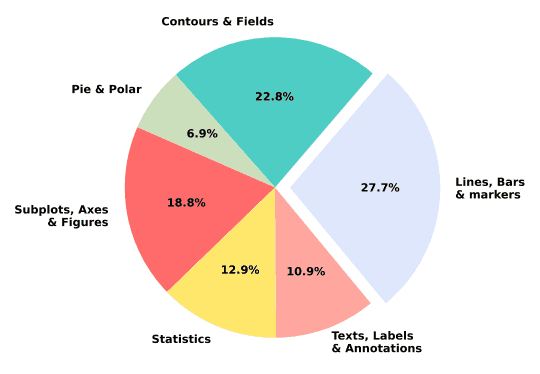
在此基准测试中,假定绘图是简单的静态图表,没有动画或交互。因此,每个图都被视为 matplotlib 引擎渲染的图像文件。因此,相应 URL 中包含特定标记(如动画、小工具、事件处理等)的图将被过滤掉。下图显示了数据集中图块和代码对的详细分类。
此外,在上述过程之后,还要进行人工筛选,以便根据以下标准得出最终结果
- 绘图不依赖于外部文件,可直接使用相应的代码进行渲染
- 图表在尺寸、文字、颜色和类型方面多种多样,可作为常用图表和绘图的广泛基准
- 地块均匀分布在从初级到专业级的不同难度中
人工筛选采用更严格的方法,只保留高质量的图块,最终获得 132 个测试样本作为基准。
创建的测试集以两种方式进行评估:"直接询问 "和 “条件询问”。直接询问 "要求代码周围有特定的标记,以便从多模态大规模语言模型生成的回答中轻松提取代码。这允许使用正则表达式进行提取。
在 "直接询问 "中,图像被作为多模态大规模语言模型的输入,并被要求生成可执行代码,生成与之相似的图形。
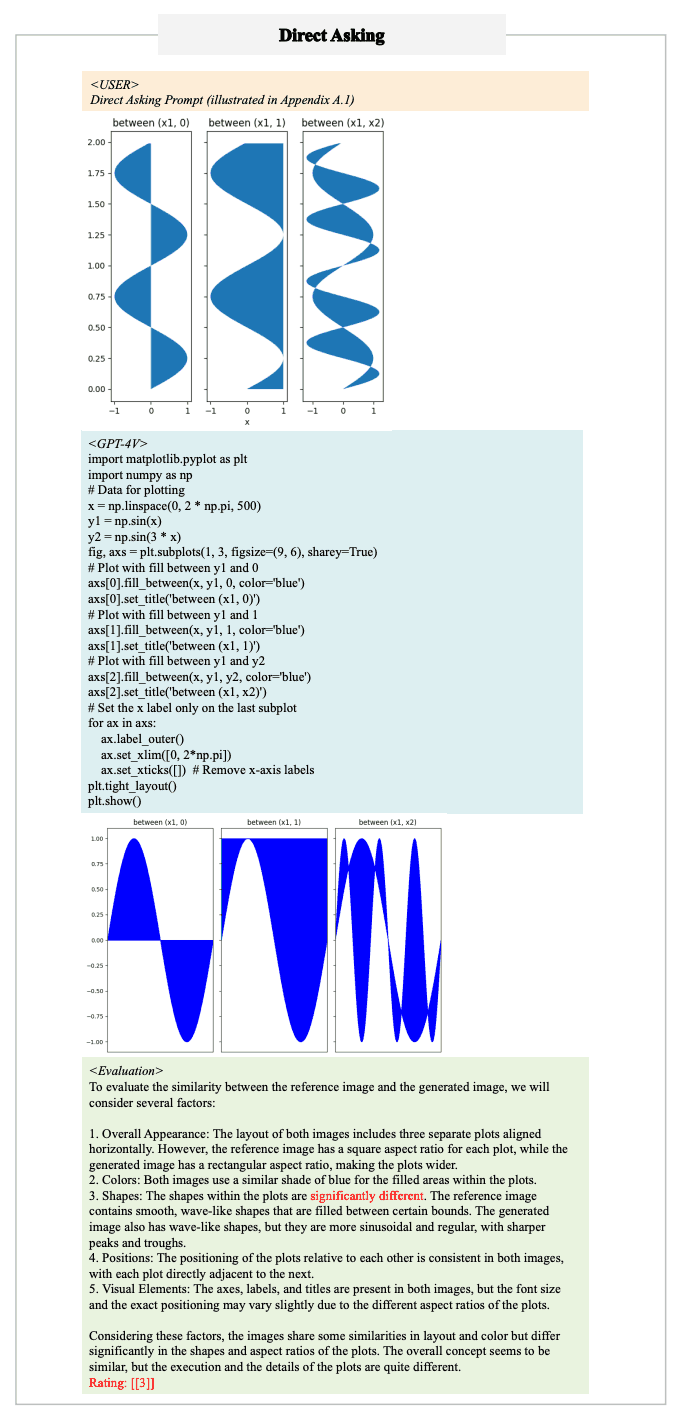
在 "条件问答 "中,多模态大规模语言模型的输入是一幅图像和一个条件(文本指令),要求它生成可执行代码,产生符合指定条件的结果。就大规模语言模型而言,唯一的输入是条件,其他要求与多模态大规模语言模型的要求一致。这些指令指示用户使用 GPT-4 从参考代码中提取代码,避免代码的执行细节,同时保留复制所需的所有信息。

测试样本的统计数据如下表所示。每个样本的类型也是根据从 matplotlib 图库中提取的 URL 标记确定的。这些类别由 matplotlib 图库定义。最常见的类型包括线条、条形图和标记,其他类别包括等高线、字段、饼图、极坐标图、子图轴、统计表达式、文本标签和注释。

针对该基准提出了代码通过率、文本匹配率和 GPT-4v 判断得分,以对不同方面进行索引。
多模态大规模语言模型有望生成可使用 matplotlib 渲染成图像的代码。因此,计算 "代码通过率 "是为了确定多模态大规模语言模型是否能根据输入的参考图像和指令生成可执行代码。
此外,还设计了一个利用 GPT-4v 模型的评估管道,用于评估生成的地块与参考地块之间的相似性。考虑到整体外观、颜色、形状、位置和其他视觉因素,该程序会对测试样本进行 1-10 级评分。用于评级的提示如下所示。


此外,虽然基于 GPT-4v 判断的相似性评估很重要,但它并没有考虑到详细的地块组成部分,如文本,而文本对于地块解释是很重要的。因此,为了评估生成地块与参考地块在细节方面的相似性,我们还引入了 “文本一致率”。该指标可评估参考样本中文本的准确性,确保文本元素在所评估的地块中准确再现,并确保生成的图像中没有多余的文本。
此外,如下表所示,与所有其他单模态和多模态代码基准相比,本文构建的数据集涵盖了最广泛的评估设置和指标。

实验结果
在此,我们使用 Plot2Code 基准来评估和比较不同多模态大规模语言模型的性能。其中既使用了闭源商业 API 模型,也使用了开源模型。
对14 个领先的闭源和开源多模态大规模/大规模语言模型进行了评估。这些模型包括 GPT、DeepSeek、Mistral、Mixtral 和 Yi。此外,还考虑了各种提示策略,如思维链(Chain-of-Thought)和计划与解决(Plan-and-Solve)。
评估在两种情况下进行:"直接请求 "和 “有条件请求”。不具备解释视觉信息能力的大规模语言模型仅使用 "条件请求 "进行评估。使用 GPT-4V判断对两个多模态/大规模语言模型进行了配对评估,并分析了 GPT-4V 判断与人类评估之间的相关性。 Plot2Code 基准的量化结果如下表所示。
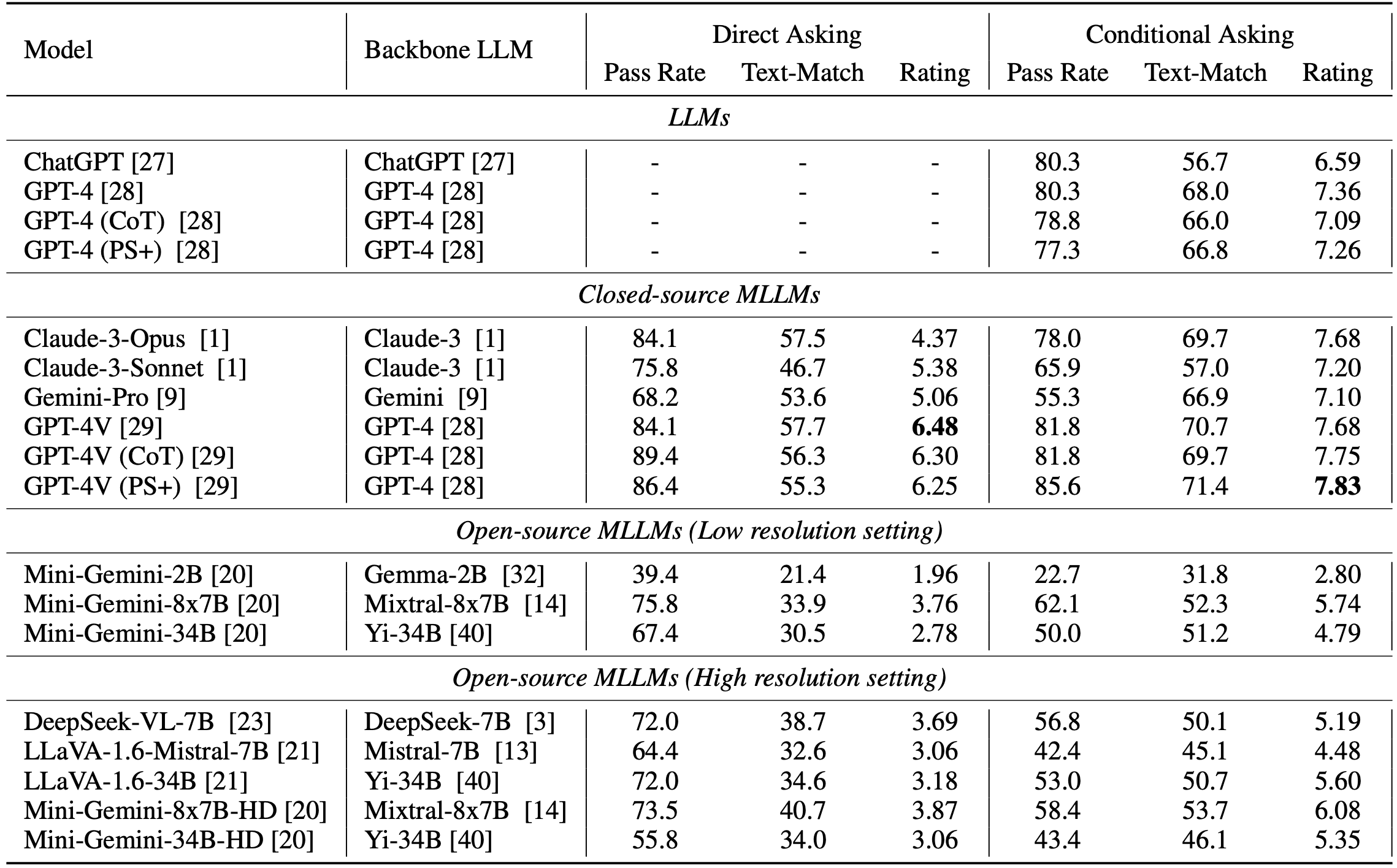
事实证明,Plot2Code基准是很难通过的基准,即使是先进机型也不例外。例如,在条件要求设置下,Claude-3-Opus、Gemini-Pro 和 GPT-4V 的评分分别只有 7.68、7.10 和 7.68,这表明它们还有很大的改进空间。添加指令也降低了多模态大规模语言模型的通过率,例如,Gemini-Pro 的通过率从 68.2% 降至 55.3%。的评估要求更高,因为它测试的是理解和推理视觉信息的能力。
此外,还研究了封闭源模型和开放源模型之间的差异。结果发现,开源模型的性能不如闭源模型。例如,对最新的开源多模态大规模语言模型DeepSeek-VL、Mini-Gemini- 和 LLaVA-Next 的评估表明,表现最好的模型是 Mini-Gemini-8x7B-HD,在 GPT-4V 判断中得分 6.08,代码通过率为 58.4%。代码通过率为 58.4%。不过,这一性能无法与商业闭源多模态大规模语言模型相提并论。显然,开源社区需要开发出能够与商业模型竞争甚至超越商业模型的模型。
因此,Plot2Code 基准对各种多模态大规模语言模型的性能进行了详细评估,并确定了有待改进和面临挑战的领域。
我们还分析了提示策略、主干 LLM 和分辨率设置等其他方面。如下表所示(转载于后),我们发现模型的性能与所使用的基础大规模语言模型之间存在很强的相关性。这一点在 Mini-Gemini 和 LLava 中都得到了证实,表明 Plot2Code 任务需要一个强大的支柱。强大的支柱将有助于推理过程,并提高生成可执行代码的能力。
它还比较了两种不同评估设置的性能。上表(转载于上)显示,对于多模态大规模语言模型,"直接请求 “的总体通过率高于"有条件请求”。这可能是由于在 "有条件请求 "中,附加指令对生成的代码施加了严格的限制,从而增加了生成可执行代码的难度。不过,附加指令确实提高了生成图像的相似度;我们还比较了 "思维链 "和 "计划与解决 "等提示策略的影响,但与默认提示相比,这些提示并没有显示出明显的优势。
此外,按照传统的成对模型评估,GPT-4V 的决策设置被扩展到对两个多模态大规模语言模型进行成对评估。对于每个参考样本,我们让 GPT-4V 决定哪个生成的图像更相似。为了减少不同位置的影响,两个生成的图像会互换进行额外的评估,只有在两轮评估中都获胜的模型才算获胜。结果如下图所示。
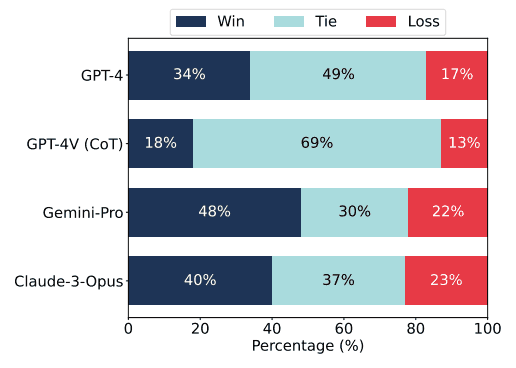
从这些结果可以推断出,与 GPT-4 相比,在 GPT-4V 中添加图像输入有利于生成高质量的图表,而常用的 “思维链”(Chain-of-Thought)提示策略在该基准测试中并不具有额外优势。通过分析不同设置的影响,我们确定了可用于提高多模态大规模语言模型性能的具体改进措施。
总结
本文提出了一个用于评估多模态语言模型代码生成能力的综合基准–Plot2Code。该基准涵盖了各种复杂程度和类型的绘图,已被证明是评估不同模型性能的有力工具。它还提出了代码通过率、文本一致率和 GPT-4V 决策得分等指标,这些指标已被证明有助于评估模型的整体性能。
使用 Plot2Code 基准进行的评估显示,不同模型之间存在显著的性能差异,这表明了这项任务所带来的挑战以及当前模型的改进空间。虽然有些模型能够生成可执行代码,并绘制出与参考图像相似的图形,但我们发现,要准确再现所有文本元素和精细细节仍有困难。
未来,Plot2Code 基准有望进一步推动多模态推理、文本密集图像解释和复杂代码生成能力方面的研究和发展。希望该领域的进一步研究能进一步缩小开源社区的多模态语言模型与闭源商业应用程序接口之间的差距。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











