







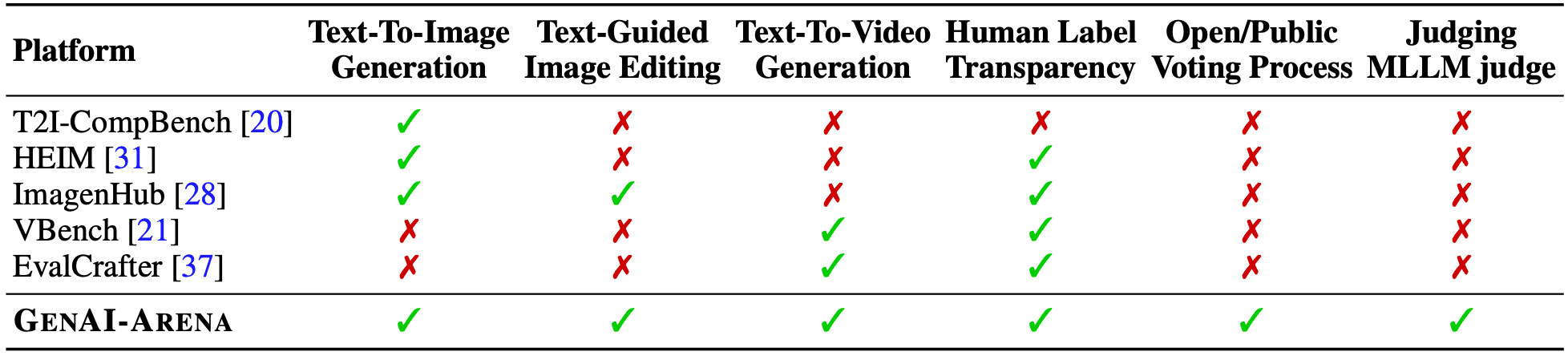
概述
论文地址:https://arxiv.org/abs/2406.04485
源码地址:https://github.com/TIGER-AI-Lab/ImagenHub
图像生成和图像编辑技术发展迅速,被广泛应用于艺术品创作和医疗成像支持等多个领域。尽管如此,掌握模型并评估其性能仍然是一项具有挑战性的任务。传统的评估指标,如 PSNR、SSIM、LPIPS 和 FID 等,对于评估特定的视角非常有用,但对于综合评估却存在挑战。特别是在评估美学和用户满意度等主观方面存在挑战。
为了应对这些挑战,本文提出了一个名为 GenAI-Arena 的新平台。GenAI-Arena 简化了比较不同模型的过程,并根据用户的偏好对它们进行排名,从而对模型的能力进行更全面的评估。该平台旨在帮助用户更全面地评估模型的能力。该平台支持多种任务,包括文本到图像生成、文本引导图像编辑和文本到视频生成。它支持多种任务。它还提供公开投票程序,以确保透明度。
自 2024 年 2 月 11 日以来,该论文已为三个多模态生成任务收集了 6000 多张选票。这些投票被用来为每个任务创建排行榜。对投票数据的分析还表明,虽然 Elo 评级通常是有效的,但 "简单 "和 "困难 "游戏之间的不平衡也会造成偏差。此外,还进行了一项定量分析案例研究,结果表明用户可以从多个评级角度进行投票,以识别输出中的细微差别,并为 Elo Rating 计算提供准确的投票。
此外,自动评估生成的视频图像内容的质量被认为是一个具有挑战性的问题。图像和视频有许多敏感的评估方面,如视觉质量、一致性、完整性和人工痕迹,这些多面性给评估带来了困难。此外,网络上缺乏教师数据。因此,在本文中,我们旨在通过发布用户投票数据作为 GenAI-Bench 来促进该领域的进一步发展。
我们计算了各种自动视频评估模型(如 GPT-4o 和 Gemini 等多模态大规模语言模型)与人类偏好之间的相关性,以评估它们的评估性能。结果表明,即使是最好的多模态大规模语言模型 GPT-4o,与人类偏好的最大皮尔逊相关系数也只有 0.22 左右。
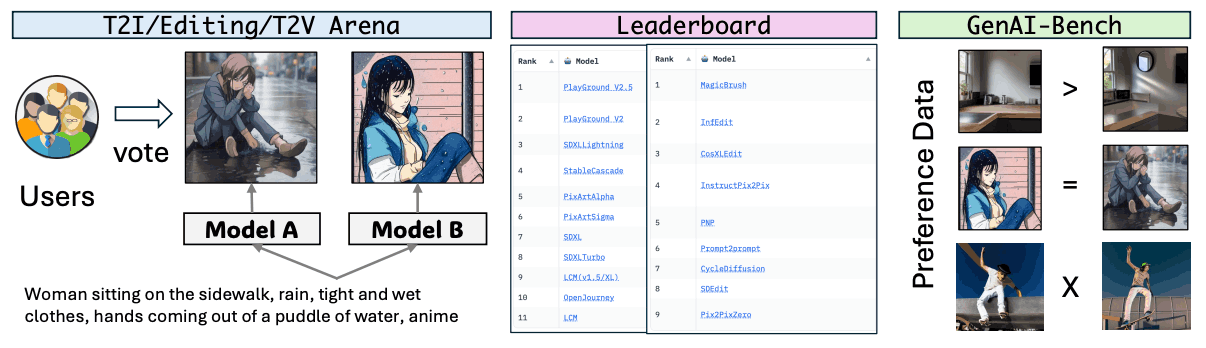
GenAI 竞技场由三部分组成:第一部分是基于文本的图像生成竞技场(T2I)、图像编辑竞技场(Editing)和基于文本的视频生成竞技场(T2V),社区通过投票获得他们最喜欢的配对。 第二个是排行榜,利用这些偏好对来计算所有评估模型的得分;第三个是 GenAI 工作台,用于评估各种多模态大规模语言模型(评估模型)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











