







概述
在人工智能领域,注意力机制(Attention Mechanism)作为一种关键的技术,正在逐渐改变我们对模型处理数据方式的理解。本文将深入探讨注意力机制的原理、起源、发展以及其实现方式,旨在为读者提供一个全面且易于理解的视角。
注意力机制的概念源于人类的认知过程。当人们面对复杂的信息时,往往会选择性地关注与当前任务最相关的部分,而忽略其他不重要的内容。这种能力使得人类能够在有限的认知资源下高效地处理信息。在人工智能模型中,注意力机制的引入正是为了模拟这种能力,让模型能够动态地分配计算资源,从而更有效地捕捉数据中的关键信息和上下文关系。
2、注意力机制的基本原理
注意力机制的核心目标是使人工智能模型在生成输出时能够有选择性地关注输入数据的不同部分。具体而言,它通过生成分数(通常是输入的某种函数)来确定对每个数据部分的关注程度,这些分数用于创建输入的加权和,进而输入到下一层网络。这种机制使得模型能够捕捉到数据中的上下文和关系,而这些在传统的、固定处理序列的方法中可能会被遗漏。
3、注意力机制的起源
注意力机制的起源可以追溯到机器翻译任务。早期的神经网络模型在处理长句子时面临着一个主要问题:无论输入句子有多长,编码器都必须将其编码为固定长度的向量,这可能无法捕捉到输入的所有细微之处,导致性能下降。为了解决这一问题,研究人员受到人类翻译过程的启发,提出了一种新的机制,即注意力机制。在这种机制下,模型不再使用固定长度的向量来表示整个句子,而是为句子中的每个单词创建一个向量序列,并在翻译过程中动态地关注与当前翻译任务最相关的部分。
4、早期编码器 - 解码器网络与注意力机制的初步探索
2014 年,Cho 等人提出了使用循环神经网络(RNN)作为编码器和解码器的架构,但这种基于 RNN 的网络在处理非常长的句子时存在问题。与此同时,Ilya Sutskever 及其团队在谷歌提出了使用长短期记忆网络(LSTM,一种 RNN 的变体)作为编码器和解码器进行序列到序列学习。这两种模型都被应用于将英语文本翻译成法语的任务,尽管 LSTM 在处理较长序列时表现更好,但固定长度向量的瓶颈问题依然存在。
为了解决这一瓶颈问题,Bahdanau 等人在其神经机器翻译论文中提出了一种机制,使模型能够专注于句子中与预测目标单词在上下文中更相关的部分。这一机制的核心思想是:当解码器进行翻译时,它会查看原始句子,以找到与它接下来要表达的内容最匹配的部分,并为每个单词创建一个上下文向量。这个上下文向量就像一个摘要,有助于根据原始句子决定如何翻译该单词。解码器不会一次性使用整个摘要,而是会计算权重,以确定摘要中哪些部分对当前正在翻译的单词最重要。决定这些权重的过程涉及一种称为对齐模型的工具,它帮助解码器在翻译单词时关注原始句子的正确部分。
5、缩放点积注意力:注意力机制的重要发展
随着研究的深入,人们开始寻找更有效的注意力实现方式。在一篇题为《Effective Approaches to Attention-based Neural Machine Translation》的论文中,研究人员提出了点积注意力,其中对齐函数是一个点积。几年后,具有开创性的“《Attention is all you need》”论文引入了缩放点积注意力,这一方法成为了现代注意力机制的重要基础。
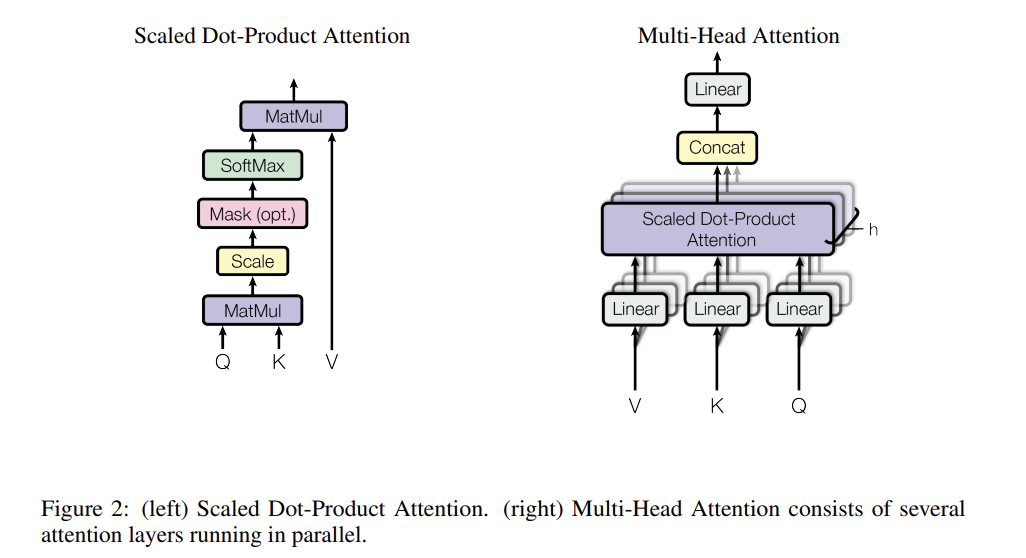
5.1 缩放点积注意力的实现过程
缩放点积注意力的实现过程如下:
5.1.1 输入的准备
缩放点积注意力需要三个输入,即查询(Query,Q)、键(Key,K)和值(Value,V)。它们通常都从输入嵌入中派生而来。查询代表你想要关注的项目集合,键与值配对,用于检索信息。模型通过查询和键之间的相似性来确定要对相应的值给予多少关注。
5.1.2 获取 Q、K 和 V
从输入嵌入开始,模型学习单独的线性变换(权重矩阵),将输入嵌入投影到查询、键和值空间。这些变换是模型的参数的一部分,并在训练过程中进行优化。通过这种方式,模型可以独立地操纵用于计算注意力权重(通过 Q 和 K)的输入方面以及用于计算注意力机制输出(通过 V)的输入方面。
以下是代码示例:
import numpy as np
# 示例输入嵌入
X = np.random.rand(10, 16) # 10 个元素,每个是一个 16 维向量
# 初始化查询、键和值的权重矩阵
W_Q = np.random.rand(16, 16) # 维度是出于示例目的选择的
W_K = np.random.rand(16, 16)
W_V = np.random.rand(16, 16)
# 计算查询、键和值
Q = np.dot(X, W_Q)
K = np.dot(X, W_K)
V = np.dot(X, W_V)
5.1.3 计算 Q 和 K 转置的点积
一旦有了 Q 和 K,计算它们的点积,得到一个表示查询和键之间相似性的矩阵。
dot_product = np.dot(Q, K.T) # 使用 numpy 的内置函数
5.1.4 获取缩放点积
将点积除以键的维度的平方根,以防止点积值过大。这一缩放操作有助于稳定梯度,避免在训练过程中出现数值不稳定的问题。
d_k = K.shape[-1] # 在这种情况下将是 16
# 基本上除以 16 的平方根,即在这种情况下是 4
scaled_dot_product = dot_product / np.sqrt(d_k)
5.1.5 对缩放点积应用 Softmax
Softmax 函数将向量中的数字转换为概率,使得输出的注意力权重在 0 到 1 之间,并且所有权重之和为 1。这一步的输出是注意力权重,它们决定了给定输入单词的重要性。
def softmax(z):
exp_scores = np.exp(z - np.max(z, axis=-1, keepdims=True)) # 提高稳定性
return exp_scores / np.sum(exp_scores, axis=-1, keepdims=True)
# 示例用法
vector_array = [2.0, 1.0, 0.1]
print("Softmax 概率:", softmax(vector_array))
输出结果为:
Softmax 概率:[0.65900114 0.24243297 0.09856589]
因此,这一步的目标是将你在前一步计算出的向量数组转换为 0 到 1 范围内的概率。这一步的输出是注意力权重,它们本质上决定了给定输入单词的重要性。
attention_weights = softmax(scaled_dot_product)
对于其对应的输入来源,这个概率数字越高,其重要性就越高。
5.1.6 乘以 V
将注意力权重与值矩阵 V 相乘,根据权重聚合值,选择要关注的值。这一步本质上是通过 V 将概率重新连接回输入矩阵,得到最终的输出。
output = np.dot(attention_weights, V)
将所有内容整合到一个数学方程中,我们得到:
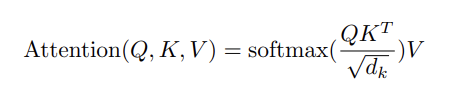
作为一个 Python 函数,它看起来像这样:
def scaled_dot_product_attention(X, W_Q, W_K, W_V):
# 计算查询、键和值
Q = np.dot(X, W_Q)
K = np.dot(X, W_K)
V = np.dot(X, W_V)
# 计算 Q 和 K^T 的点积
dot_product = np.dot(Q, K.T)
# 获取缩放点积
d_k = K.shape[-1]
scaled_dot_product = dot_product / np.sqrt(d_k)
# 应用 softmax 获取注意力权重
attention_weights = softmax(scaled_dot_product)
# 乘以 V 获取输出
output = np.dot(attention_weights, V)
return output, attention_weights
# 示例用法
# 定义输入嵌入和权重矩阵
X = np.random.rand(10, 16) # 10 个元素,每个是一个 16 维向量
W_Q = np.random.rand(16, 16)
W_K = np.random.rand(16, 16)
W_V = np.random.rand(16, 16)
output, attention_weights = scaled_dot_product_attention(X, W_Q, W_K, W_V)
print("输出(聚合嵌入):")
print(output)
print("\n注意力权重(相关性分数):")
print(attention_weights)
输出结果为:
输出(聚合嵌入):
[[5.09599132 4.4742368 4.48008769 4.10447843 5.73438516 5.20663291
3.53378133 5.82415923 3.72478851 4.77225668 5.27221298 3.62251028
4.68724943 3.93792586 4.3472472 5.12591473]
[5.09621662 4.47427655 4.48007838 4.10450512 5.73436916 5.20667063
3.53370481 5.82419706 3.72482501 4.77241048 5.27219455 3.6225587
4.68727098 3.93783536 4.34720002 5.12597141]
[5.09563269 4.47417458 4.48010325 4.10443597 5.734411 5.20657353
3.53390455 5.82409992 3.72473137 4.77201189 5.2722428 3.6224335
4.68721553 3.9380711 4.34732342 5.12582479]
[5.09632807 4.47429524 4.48007309 4.10451827 5.7343609 5.2066886
3.5336657 5.82421494 3.72484219 4.77248653 5.27218496 3.62258243
4.6872813 3.93778954 4.34717566 5.12599916]
[5.09628431 4.47428739 4.4800748 4.10451308 5.73436398 5.20668119
3.5336804 5.8242075 3.72483498 4.77245663 5.2721885 3.62257301
4.68727707 3.93780698 4.3471847 5.12598815]
[5.0962137 4.47427585 4.48007837 4.10450476 5.7343693 5.20667001
3.53370556 5.82419641 3.72482437 4.77240847 5.2721947 3.62255803
4.68727063 3.93783633 4.34720044 5.12597062]
[5.09590612 4.47422339 4.48009238 4.10446839 5.73439171 5.20661976
3.53381233 5.82414622 3.72477619 4.77219864 5.27222067 3.62249228
4.68724184 3.93796181 4.34726669 5.12589365]
[5.0963771 4.47430327 4.48007062 4.10452404 5.73435721 5.20669637
3.53364826 5.82422266 3.72484957 4.77251996 5.27218067 3.62259284
4.68728578 3.93776918 4.34716475 5.12601133]
[5.09427791 4.47393653 4.48016038 4.10427489 5.7345063 5.2063466
3.53436561 5.8238718 3.72451289 4.77108808 5.27235308 3.6221418
4.68708645 3.93861577 4.34760721 5.12548251]
[5.09598424 4.47423751 4.48008936 4.1044777 5.73438636 5.20663313
3.53378627 5.82415973 3.72478915 4.77225191 5.27221451 3.62250919
4.68724941 3.93793083 4.34725075 5.12591352]]
注意力权重(相关性分数):
[[1.39610340e-09 2.65875422e-07 1.06720407e-09 2.46473541e-04
3.30566624e-06 7.59082039e-07 9.47371303e-09 9.99749155e-01
6.23506419e-13 2.87692454e-08]
[9.62249688e-11 3.85672864e-08 6.13600771e-11 1.16144738e-04
6.40885383e-07 1.06810081e-07 7.39585064e-10 9.99883065e-01
1.63713108e-14 2.75331274e-09]
[3.69381681e-09 6.13144136e-07 2.80803461e-09 4.55134876e-04
6.64814118e-06 1.49670062e-06 2.41414264e-08 9.99536010e-01
2.48323405e-12 6.63936853e-08]
[9.79218477e-12 6.92919207e-09 7.68894361e-12 5.05418004e-05
1.23007726e-07 2.34823978e-08 1.24176332e-10 9.99949304e-01
9.59727501e-16 4.83111885e-10]
[1.24670936e-10 4.27972941e-08 1.21790065e-10 7.57169471e-05
7.82443047e-07 1.57462636e-07 1.16640444e-09 9.99923294e-01
2.35191256e-14 5.02281725e-09]
[1.35436961e-10 5.32213794e-08 1.10051728e-10 1.17621865e-04
8.32222943e-07 1.59229009e-07 1.31918356e-09 9.99881326e-01
3.69075253e-14 5.44039607e-09]
[1.24666668e-09 2.83110486e-07 8.25483229e-10 2.97601672e-04
2.85247687e-06 7.16442470e-07 8.11115147e-09 9.99698510e-01
4.61471570e-13 2.58350362e-08]
[2.94232175e-12 2.82720887e-09 2.06606788e-12 2.14674234e-05
7.58050062e-08 1.04137540e-08 3.39606998e-11 9.99978443e-01
1.00563466e-16 1.36133761e-10]
[3.29813507e-08 2.92401719e-06 2.06839303e-08 1.23927899e-03
2.00026214e-05 6.59439395e-06 1.48264494e-07 9.98730623e-01
4.90583470e-11 3.74539859e-07]
[3.26708157e-10 9.74857808e-08 2.53245979e-10 2.52864875e-04
1.76701970e-06 3.06926908e-07 2.62423409e-09 9.99744949e-01
1.07566811e-13 1.10075243e-08]]
从视觉上看,输出只是一个巨大的数字矩阵,但这些数字现在与用于创建它们的输入嵌入有了更多的细微差别和上下文联系。
6、注意力机制的拓展与优化
随着深度学习技术的不断发展,注意力机制也在不断地拓展和优化。例如,Longformer 论文提出了滑动窗口注意力,将注意力限制在局部邻域内,从而减少了计算量,使其更适合处理长序列。此外,Flash Attention 方法则专注于通过硬件优化和先进算法来提高注意力计算的效率,进一步推动了注意力机制在大规模语言模型中的应用。
七、结论
注意力机制作为人工智能领域的一项重要技术,已经在众多任务中取得了显著的成果。它通过模拟人类的选择性注意力,使模型能够更有效地处理复杂的数据,并捕捉到数据中的关键信息和上下文关系。从早期的编码器 - 解码器架构到现代的 Transformer 模型,注意力机制不断演变和发展,为人工智能的进步提供了强大的动力。未来,随着研究的深入和技术的创新,注意力机制有望在更多领域发挥更大的作用,推动人工智能技术迈向新的高度。



















 2979
2979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











