






5 文档数据库
在这一章中另一类NoSQL数据库将被讨论。文档数据库被许多人认为是从简单的键/值存储到稍复杂和有意义的数据结构的下一个逻辑步骤,因为它们至少允许在文档中封装键/值对。另一方面,文档不需要符合严格的模式,这省去了模式迁移工作的需要([ Ipp09 ])。在这一章中,Apache CouchDB和MongoDB作为这类文档数据库的代表将被研究。
5.1 Apache CouchDB
5.1.1 概览
CouchDB是一个由Erlang编写的文档数据库。CouchDB这个名字现在有时指“不可靠的商用硬件的集群”数据库,根据一位它的主要开发者所说,这实际上是一个缩写([ PLL09 ])。
CouchDB可以看作是Lotus Notes的一个后裔,因CouchDB的主要开发者Damien Karz在自己开始CouchDB项目前曾在IBM工作。很多来自Lotus Notes的概念可在CouchDB中找到:文档,视图,分布式,以及服务器和客户端间的复制。CouchDB的方法是从零建立这样一个文档数据库,使用web领域的技术如表述性状态转移(REST;参见[ Fie00 ]),JavaScript对象符号(JSON)作为一种数据交换格式,以及与基础设施组件相结合的能力如负载均衡器和缓存代理等([ PLL09 ])。
CouchDB可以被概括为一个文档数据库,其通过RESTful HTTP接口访问,在扁平地址空间中包含无模式的文档。对这些文档,JavaScript函数以MapReduce方式选择和聚合文档以及它们的表示,以建立也能被索引的数据库视图。CouchDB是分布式的,能够在服务器节点间或客户端和服务器间增量复制。在CouchDB中同一文档的多个并发版本(MVCC)是允许的,数据库能够检测冲突和管理他们的决议,其被授权给客户端应用程序([ Apa10c ]、[ Apa10a ])。
CouchDB生产环境最显著的应用是ubuntu one([ Can10a ]),Ubuntu Linux的云存储和f复制服务([ Can10b ])。CouchDB也是BBC的新web应用程序平台的一部分([ Far09 ])。此外一些(不太重要的)博客、维基、社交网络、Facebook apps和小网站使用CouchDB作为数据存储([ C+10 ])。
5.1.2 数据模型和键抽象
文档
在CouchDB中主要的抽象和数据结构是文档。文档由有一个键/名称和一个值的命名字段组成。在一个文档内字段名必须是唯一的,其分配的值可以是字符串(任意长度)、数字、布尔值、日期、一个有序list或一个关联map([ Apa10a ])。文档可以包含其他文件档的引用(URIs、URLs)但这些不被检查或由数据库保持一致性([ PLL09 ])。进一步的限制是CouchDB中的文档不能嵌套([ Ipp09 ])。
一篇维基文章作为这样的文档的示例:
" Title " : " CouchDB ",
" Last editor " : "172.5.123.91" ,
" Last modified ": "9/23/2010" ,
" Categories ": [" Database ", " NoSQL ", " Document Database "],
" Body ": " CouchDB is a ..." ,
" Last editor " : "172.5.123.91" ,
" Last modified ": "9/23/2010" ,
" Categories ": [" Database ", " NoSQL ", " Document Database "],
" Body ": " CouchDB is a ..." ,
" Reviewed ": false
除了字段外,文档也可以有附件,CouchDB为每个文档维护一些元数据(如唯一标识符和序列id)([ Apa10b ])。文档id是一个128位的值(所以CouchDB数据库可存储3.4e38个(注:原文有误)不同文档);修订号是一个32位的值,通过哈希函数确定。
CouchDB将自身看做一种半结构化数据库。关系数据库是专为结构化的且相互依存的数据设计,键/值存储操作未解释的、孤立的键/值对,而文档数据库如CouchDB追求第三种路径:文档中包含的数据不对应于一个固定的模式(无模式),但有一些内部结构被应用程序以及数据库本身所知。这种方法的优点是,首先没有必要进行模式迁移,而这在关系数据库世界中将导致大量的努力;其次,相比于键/值存储,数据可被更复杂地评价(例如视图的计算)。在网络应用领域有很多面向文档的应用,CouchDB声称其数据模型适合这类应用,且迭代地扩展或修改文档的可能性可以用更少的精力来完成,相比于关系数据库([ Apa10a ])。
每个CouchDB数据库包含唯一一个扁平/非分层的命名空间,其包含所有具有由CouchDB计算的唯一标识(由一个文档id和一个修订号称为序列id组成)的文件。CouchDB服务器可以承载多个数据库([ Apa10c ],[ Apa10b ])。早先文档被存储为XML文件,但今天他们以类JSON格式被序列化到磁盘([ PLL09 ])。
文档检索由B树实现,其索引文档的id和修订号(序列id;参见[ Apa10b ])。
视图
CouchDB的查询、展现、汇总和报告半结构化文档数据的方式是视图([ Apa10a ]、[ Apa10b ])。一个典型的视图例子是分离不同类型的文档(如博客文章、评论、博客系统中的作者),这些未被数据库本身区分,对它来说他们只是文件([ PLL09 ])。
视图由JavaScript函数定义,其既不改变也不保存或缓存底层的文档,仅将它们呈现给请求的用户或客户端应用程序。因此文档以及视图(事实上是特殊的文档,称为设计文档)可被复制,视图不会被副本干扰。视图按需被计算。一个数据库中视图的数量或通过视图表现的文档的数量没有限制。
定义视图的JavaScript函数被称为map和reduce,其和Google的MapReduce方法([ DG04 ])具有相同的责任。map函数得到一个文档作为参数,可以执行任何计算并释放任意数据,如果它符合该视图的条件;如果给定的文档不匹配这些条件,map函数什么都不释放。为一个文档释放的数据的例子是文档本身,从中提取、引用或包含其他文档的内容(例如,语义相关的文档如一个论坛、博客或维基中某用户的评论)。
由map函数释放的数据结构是一个三元组,由文档id、一个键和一个可由map函数选择的值组成。文档按键进行排序,其不必是唯一的而是可以出现一个以上的文档;作为排序条件的键可以用来如定义一个视图,为博客的首页对博客按日期降序排序。map函数释放的值是可选的,可以包含任意数据。文档id由CouchDB隐式设置,其代表传给map函数作为参数的文档。([ PLL09 ])。
在map函数被执行之后,它的结果被传递给一个可选的reduce函数,它是可选的但可以在视图上做一些聚集([ PLL09 ])。
由于数据库的所有文档都通过视图函数处理,这对大的库可能是耗时和资源密集的。因此,视图的创建和索引不是在写操作创建时发生而是按需的(在第一次请求定向到它时),以及被再次请求时增量更新。为提供视图增量更新,CouchDB为视图保存索引。正如前面提到的,视图被定义并存储在特定文档中。这些设计文档可以包含多个视图的函数,如果它们被命名为唯一。视图索引在这些设计文档的基础上维护,且设计文档中不包含单一视图。因此,如果用户请求一个视图,它的索引和相同设计文档中定义的所有的索引均被更新([ Apa10b ]、[ PLL09 ])。此外增量视图更新的前提是,map函数需要是指称透明的,意味着对同样的文档每次被调用时其必须释放相同的键和值([ Apa10e ])。
为更新视图,负责它的组件(称为视图生成器)比较整个数据库的序列id,并检查它自上次视图刷新后是否已经改变。如果不是,视图生成器确定文件更改、删除或创建是在那个时间之后;它传输新的和更新后的文档到视图的map和reduce函数,并从视图中移除已删除的文档。因为对数据库的更改都以只追加的方式写到磁盘(见第5.1.7节),视图的增量更新可以有效率地进行,因磁盘寻道数量是最小化的。只追加索引存储的进一步优势是,如果索引更新过程中系统崩溃,先前的状态仍保持一致,CouchDB在启动时忽略不完整的追加数据,当下次被请求时再更新索引。
当视图生成器正在更新视图,客户端可以读取视图的旧状态的数据。也有可能视图的旧状态被呈现给一个客户端,新状态被呈现给另一个客户端,因为视图索引也以只追加的方式被写入,当一个客户端仍在读时视图数据的压缩不会忽略旧的索引状态(更多的在第5.1.7节)。
5.1.3 版本化
文档被优化地更新,且更新操作并不意味着任何锁([ Apa10b ])。如果某个客户端发布一个更新,联络的服务器以修改时复制的方式创建一个新的文档修订(见3.3节),且最近的修订历史记录存储在CouchDB中,直到数据库下一次被压缩。因此,一个文档是由一个删除前一直附着其上的文档id/键来标识的,且修订号由CouchDB在文档创建时和每一次更新时创建([ Apa10b ])。如果一个文档被更新,不仅当前修订号被存储,而且会存储早于它的修订号的列表,以允许数据库(在复制另一个节点或处理读请求时)以及客户端应用程序在出现冲突版本时追朔修订历史([ PLL09 ])。
CouchDB不认为版本冲突是一种异常,而是一种正常情况。他们不仅能由不同的客户端操作同一CouchDB节点产生,也会由于客户端操作同一数据库的不同副本而产生。对并发版本有无限个版本号的情况并未被数据库禁止。CouchDB数据库可以确定地检测文档的哪些版本相互连续,以及哪些是冲突的,必须由客户端应用程序来解决。冲突解决可能会出现在数据库的任何副本节点上,因为接收已解析版本的节点会把它发送到所有必须接受这个版本为有效的副本上。可能会出现冲突解决并发地在不同的节点发起的问题;两个节点上的本地已解析版本随后被检测为冲突的,像其他所有版本冲突那样被解决([ Apa10b ])。
版本冲突在读时被检测到,冲突的版本被返回到客户端,由客户端负责解决冲突。([ Apa10b ])。
一个最新版本有冲突的文档被排除在视图之外([ Apa10b ])。
5.1.4 分布和复制
CouchDB为遵循单点方法的分布式设置而设计,其中每个服务器具有相同的职责设置且没有特殊的角色(如主/从设置,待机集群等)。根据设计,不同的数据库节点可以完全独立操作和处理读写请求。两个数据库节点可以双向复制数据(文档、文档附件、视图),如果双方通过网络互相接触。复制过程增量进行,且可用简单的方式检测版本冲突,因为每个文档的更新使CouchDB创建一个该文档的新的修订,且过时的修订号的列表被存储。通过修订号以及过时的修订号列表,CouchDB可以确定是否有冲突;如果有版本冲突,两个节点均有这一概念,可将冲突的版本升级到客户端以解决冲突;如果没有版本冲突,该节点没有该文档的最新版本,则更新它(参见[ Apa10a ]、[ Apa10b ]、[ PLL09 ])
CouchDB的分布式情景包括集群、笔记本上脱机使用(如员工访问客户时)或在分散于世界各地的公司所在地,其对公司或组织本地网络的访问是缓慢或不稳定的。在后两种情况下,可以在一个断开连接的CouchDB实例上工作,且没有使用限制。如果到副本节点的网络连接被建立了,数据库节点可以再次同步他们的状态([ Apa10b ])。
复制进程增量地且文档感知地进行操作。增量地意味着只有上次复制以来的数据变化被传输到另一个节点,即不是传输整个文档而是只传输改变的字段和附件blobs;文档感知意味着每个成功复制的文件不必再复制,如果复制进程崩溃([ Apa10b ])。
除了复制整个数据库,CouchDB还允许部分复制。为此JavaScript过滤函数可以被定义,其对副本数据放行但拒绝数据库的其它数据([ Apa10b ])。
部分复制机制可用于手动分片数据,通过为每个CouchDB节点定义不同的过滤器。如果这不被使用也没有像Lounge这类扩展([ FRLL10 ]),CouchDB复制所有数据到所有节点,且不自动分片,因此默认的行为像MySQL副本机制,如Ippolito评论的([ Ipp09 ])。
根据CouchDB文档,副本机制被设计为通过很小的代价分布和复制数据库。另一方面,他们也应该能够处理扩展的和更精致的分布式场景,如分区数据库或带全部修订历史的数据库。为此,“CouchDB副本模型可以修改为其他分布式更新模型”。例如,存储引擎可被“增强以允许多文档更新事务”,以使“在复制上游服务器时进行类似子版本的‘全部或无’原子操作,使得任何单个文件冲突或验证失败将导致整个更新操作失败”成为可能([ Apa10b ];验证的更多信息可在下面找到)。
5.1.5 接口
CouchDB数据库通过RESTful HTTP接口允许读取和更新文件([ Apa10b ])。CouchDB项目还提供库,方便通过一些编程语言以及Web管理界面进行存取([ Apa10c ])。
CouchDB文档通过其URL被请求,根据RESTful HTTP范式(读通过HTTP GET,创建和更新通过HTTP PUT,删除通过HTTP DELETE)。读操作必须在更新操作之前进行,因为对更新操作,已读取并需要更新的文档必须作为参数提供。为检索文档的URL——也许它们的数据依旧被一个应用程序需要——可通过客户端应用程序请求视图(通过HTTP GET)。通过请求它们的文档id和键,可以检索视图项的值([ PLL09 ])。文档以及视图通过JSON格式交换([ Ipp09 ])。
Lehnhardt和Lang指出,通过提供RESTful HTTP接口,许多标准网络基础设施组件如负载均衡、高速缓存、SSL代理和认证代理可以很容易地与CouchDB集成。一个例子是,在缓存服务器使用一个文档的修订号作为ETag头([ FGM+99,14.19节 ])。网络基础设施组件也可以为客户端应用程序隐藏分布式细节——如果这是必需的,或被选择以保持应用程序更简单,虽然其提供的性能和可能性是来自于分布式数据库的概念([ PLL09 ])。
5.1.6 ACID特性
根据技术文档,ACID特性被纳入CouchDB,由于它的提交系统和操作文件的方式([ Apa10b ])。
原子性被提供给单个更新操作,其可以被执行完成或失败回滚,因此数据库永远不包含部分保存或更新的文件([ Apa10b ])。
一致性可被质疑,因为在分布式CouchDB环境中没有强一致性,所有的副本一直都是可写的,并不会自主地相互复制。这导致了一个MVCC系统,在其中版本冲突需要在读时由客户端应用程序解决,如果无语法调和是可能的。
单节点CouchDB数据库的一致性以及持久性由CouchDB操作数据库文件的方式保证(见下文;参见[ Apa10b ])。
5.1.7 存储实现
考虑存储实现,CouchDB应用一些方法保证一致性和持久性以及优化性能([ Apa10b ]):
- CouchDB不会覆盖提交的数据或相关结构,因而一个数据库文件在每个时刻处于一致的状态中。因此,数据库也不需要关闭以正确地终止,而是可以简单地杀死进程。
- 文档更新通过两个阶段执行,以提供事务,同时保持一致性和数据库的持久性:
1、更新后的文档同步地序列化到磁盘。这个规则的一个例外是文档中的BLOB数据被并发地写入。
2、更新后的数据库头被写入到磁盘上2个相同且连续的块中。
现在,如果步骤1执行时系统崩溃,当CouchDB重启时未完全写入的数据将被忽略。如果步骤2中的系统崩溃,有一定几率两个相同的数据库头中的一个已被写入;如果不是这样的话,数据库头和数据库内容之间的不一致会被发现,因为CouchDB启动时为了一致性检查数据库头。除了这些数据库头的检查,没有进一步检查或清洗的需要。
- 读请求永远不会被block,永远不用等待一个读者或写者,也永远不会被CouchDB中断。它保证了一个读客户端在一个读操作的自始至终可以看到数据库的一致性快照。
- 如上所述,CouchDB数据库的文档使用B树索引。文档上的更新操作发生时,被更新文档的新的修订号(序列id)被生成、索引,且更新的索引以只追加的方式写入磁盘。
- 为有效率地存储文档,一个文档和它的元数据首先被组合在一个所谓的缓冲区中,然后按顺序写入磁盘。因此,文档可以被客户端和数据库(用于如索引目的、视图计算)有效率地一次性读取。
- 如前面提到的,视图索引以只追加的方式写,就像文档索引。
- CouchDB需要时不时地压缩数据库以收回不再需要的磁盘空间。这是因为只追加的数据库、索引文件以及文档修订历史。压缩可以被安排或是隐式执行当“浪费”的空间超过某个阈值。压缩过程克隆所有仍需要的数据库内容,并将它复制到一个新的数据库文件。在复制过程中,旧的数据库文件被保留,因此复制和更新操作仍然可以执行。如果在复制过程中系统崩溃,旧的数据库文件仍然是当前的和完整的。复制过程被认为成功,当所有的数据已被转移到新的数据库文件,以及所有的请求都被重定向到它;然后CouchDB删掉旧的数据库文件。
5.1.8 安全
访问控制
CouchDB实现了一个简单的访问控制模型:一个文档可能有一个允许读取它的授权角色的列表(被称为“读者”)。一个用户可以关联到零个、一个或多个角色,它确定他在访问数据库时的角色。如果文档有关联的读者列表,其只能当存取用户拥有一个读者的一个角色时才能被读取。当视图内容被返回给用户时,如视图返回带读者列表的文档,则会被动态地过滤([ Apa10b ])。
管理员权限
CouchDB中有一个特殊的管理员角色,允许创建和管理用户账户,以及操纵设计文档(如视图;参见[ Apa10b ])。
更新验证
文档可以在它们被写入磁盘之前动态地验证,以确保安全和数据的有效性。为此,JavaScript函数可以被定义为以文件和登入用户的凭据作为参数,并且可以返回一个负值如果他们不认为该文件应写到磁盘。这导致CouchDB中止更新请求,且错误消息会返回给发布更新的客户端。鉴于验证功能被认为是比较通用的,超越数据验证的自定义安全模型可以以这种方式实现。
更新验证功能被执行是为了线上使用的CouchDB实例的更新操作,以及为了由于复制另一个节点导致的更新操作。([ Apa10b ])。
5.1.9 实现
CouchDB最初是用C++实现的,但由于并发原因后来移植到Erlang OTP(开放电信平台;参见[ Eri10 ]),一个函数化的、并行的语言和平台,最初在电信部门(爱立信)以可用性和可靠性为重点被开发。Erlang语言的特点是轻量级的进程,一个异步和基于消息的并发方法,无共享状态的线程以及数据不变性。CouchDB的实现从这些特点获益,因为Erlang被选择以实现完全无锁的并发读写请求和复制,以减少瓶颈并保持在高负荷下数据库以可预见的方式工作([ Apa10a ]、[ Apa10b ])。
为进一步提供高可用性和允许大规模并发访问,CouchDB使用了一种无共享集群方法,它可以让所有的数据库副本节点独立工作,即使他们是断开的(见上节以及[ Apa10b ])。
虽然数据库本身是用Erlang实现的,CouchDB使用的两个库是用C写的,IBM Components for Unicode以及Mozilla的Spidermonkey JavaScript引擎([ Apa10a ])。
5.1.10 进一步的说明
CouchDB允许在数据库中创建整个应用程序,文档附件可能包括HTML、CSS和JavaScript([ Apa10b ],[ PLL09 ])。
CouchDB有一个机制来对服务器端事件反应。为了这个目的,可以为服务器事件注册并提供JavaScript代码来处理这些事件([ PLL09 ])。
CouchDB允许为文档和视图提供JavaScript转换函数,可被用于如创建它们的非JSON表示(如XML文档;参见[ PLL09 ])。
一些项目已经围绕CouchDB出现,它们扩展了它的附加功能,最值得注意的是与Apache Lucene整合的全文搜索和索引([ N+10 ],[ Apa09 ])和集群框架Lounge([ FRLL10 ])。
5.2 MongoDB
5.2.1 概览
MongoDB是C++编写的无模式文档数据库,以开源项目形式被开发,其主要由10gen公司推动,也提供围绕MongoDB的专业服务。据其开发商所说,MongoDB的主要目标是缩小快速且高度可扩展的键/值存储与功能丰富的传统RDBMS间的差异。MongoDB名字来源于形容词humongous([ 10g10 ])。MongoDB的突出的用户包括SourceForge.net、foursquare、纽约时报、网址缩短服务bit.ly和分布式社交网络DIASPORA([ Cop10 ]、[ Hey10 ]、[ Mah10 ]、[ Rid10 ]、[ Ric10 ])。
5.2.2 数据库和集合
MongoDB数据库驻留在一个MongoDB服务器中,其可以容纳多于一个这样的独立且由服务器分开存储的数据库。数据库包含一个或多个由文档组成的集合。为了控制数据库的访问,一组安全凭据可以为数据库定义([ CB10 ])。
根据MongoDB手册,数据库中的集合式指“文档的命名集合”([ CBH10a ])。因MongoDB是无模式的,一个集合内的文档可能是异构的,虽然MongoDB手册建议“为你的每个顶层对象创建一个数据库集合”([ MMM+10b ])。一旦第一个文档插入到数据库中,就自动产生了一个集合且插入的文档被添加到该集合中。这样一个隐式创建的集合通过MongoDB的默认参数被配置。如果单独的选项值如自动索引、预分配磁盘空间或大小限制(参见[ MDM+10 ]并查看下面的小节)被要求,集合也可以由createCollection命令创建:
db. createCollection (<name >, {< configuration parameters >})
例如,下面的命令创建了一个集合叫mycoll,带10000000字节预分配磁盘空间并没有自动生成的且索引的文档字段_id:
db. createCollection (" mycoll ", { size :10000000 , autoIndexId : false });
MongoDB允许在分层命名空间中使用点符号来组织集合,如集合wiki.articles,wiki.categories和wiki.authors位于命名空间wiki下。MongoDB手册指出,“这仅仅对用户来说是一种组织机制——从数据库的视角看集合命名空间是扁平的”([ CBH10a ])。
5.2.3 文档
MongoDB中数据存储的抽象和单元是文档,一种与XML文档、Python的字典、Ruby hash或JSON文档相当的数据结构。事实上,MongoDB使用一个称为BSON的格式来持久化文档,其与JSON很相似但用了二进制表示,原因是效率和与JSON相比额外的数据类型。尽管如此,“BSON和JSON可以容易地互相映射,也可以转为许多编程语言中的各种数据结构”([ CBH+10b ])。
作为一个例子,以JSON符号表示,代表一篇维基文章的文档看起来如下:
{
title : " MongoDB ",
last_editor : "172.5.123.91" ,
last_modified : new Date ("9/23/2010") ,
body : " MongoDB is a..." ,
categories : [" Database ", " NoSQL ", " Document Database "] ,
reviewed : false
title : " MongoDB ",
last_editor : "172.5.123.91" ,
last_modified : new Date ("9/23/2010") ,
body : " MongoDB is a..." ,
categories : [" Database ", " NoSQL ", " Document Database "] ,
reviewed : false
}
为添加这样一个文档到MongoDB集合,使用insert函数:
db.< collection >. insert ( { title : " MongoDB ", last_editor : ... } );
一旦文档插入,可以通过find操作发出匹配查询来检索,或通过save操作更新:
db.< collection >. find ( { categories : [ " NoSQL ", " Document Databases " ] } );
db.< collection >. save ( { ... } );
MongoDB中的文档被限制在4MB([ SM10 ])。
文档字段的数据类型
MongoDB为文档字段提供以下数据类型(
[
CHM10a
], [
MC09
], [
MMM
+
10a
]):
- 标量类型:boolean,integer,double
- 字符序列类型:string(以UTF-8编码的字符序列),正则表达式,代码(JavaScript)
- object(BSON对象)
- object id是一种为12字节长的二进制值提供的数据类型,被MongoDB和所有官方支持的编程语言驱动使用,一个名叫 _id 的字段唯一标识了集合中的文档。数据类型object id由以下几部分组成:
- 从纪元以来以秒为单位的时间戳(前4字节)
- 分配object id值的机器id(随后3字节)
- MongoDB进程的id(随后2字节)
- 计数器(最后3字节)
对 _id 字段有一个object id值的文档,它们创建时的时间戳可以通过所有官方支持的编程驱动提取。
- null
- array
- date
文档间的引用
MongoDB不提供外键机制,因此文档间的引用必须由客户端应用程序发出的附加查询解决。引用可手动设置,通过为一些引用字段分配被引用文档的 _id 字段的值。此外,MongoDB提供一个更正式的方法来指定引用,称为DBRef(“数据库引用”)。使用DBRef的优点是,其他集合中的文档可以通过它们被引用,且一些编程语言的驱动会自动解引用(参见[ MDC+10 ] [ MMM+10d,数据库引用 ])。DBRef的语法是:
{ $ref : <collectionname >, $id : <documentid >[, $db : <dbname >] }
MongoDB手册指出,字段$db是可选的,且当前很多编程语言的驱动不支持([ MDC+10 ])。
MongoDB指出尽管文档间的引用是可能的,有一种替代是在文档内嵌套文档。文档的嵌入是“更有效率的”,根据MongoDB手册,因为“[数据]位于同磁盘上,数据库的客户端-服务器周转被消除”。相反,当使用引用时,“每一个引用遍历都是一次数据库的查询”,导致至少在网络或应用服务器和数据库之间的延迟增加,但通常更多是因为引用数据不缓存在内存中,而是必须从磁盘加载。
MongoDB手册给出了一些指导,什么时候引用一个object,什么时候把它内嵌,见表5.1([ MMM+10b ])。
|
对象引用的条件
|
对象内嵌的条件
|
|
First-class domain objects (typically residing
in a separate collection) Many-to-many reference between objects Objects of this type are often queried in large numbers (request all / the first n objects of a certain type)
The object is large (multiple megabytes)
|
Objects with “line-item detail” characteristic
Aggregation relationship between object and host object Object is not referenced by another object (DBRefs for embedded objects are not possible as of MongoDB, version 1.7) Performance to request and operate on the
object and its host-object is crucial
|
表5.1:MongoDB——引用 vs. 对象内嵌(参见[ MMM+10b ])
5.2.4 数据库操作
查询
选择 在MongoDB查询被指定为查询对象,一个BSON文档包含选择条件,并作为一个参数传递给find操作,其在被查询的集合上执行([ CMH+10 ]):
db.< collection >. find ( { title : " MongoDB " );
给find操作的选择条件可以被看作相当于SQL语句中的WHERE子句([ Mer10f ])。如果查询对象为空,则返回集合的所有文档。
在选择条件传递到find操作时,允许多个操作符——除上面的例子中的相等比较。这些有以下的一般形式:
<fieldname >: {$< operator >: <value >}
<fieldname >: {$< operator >: <value >, $< operator >: value } // AND - junction
允许以下比较操作符([ MMM+10b ]):
- 不等于:$ne
- 数值关系:$gt, $gte, $lt, $lte(代表>, >=, <, <=)
- 取模运算,余数和模的值放在一个二元数组中,如:
{ age: { $mod : [2, 1]} } // to retrieve documents with an uneven age
- 与数组中(至少)一个元素的想等比较:$in 带一个数组作为比较的操作数,如:
{ categories : {$in: [" NoSQL ", " Document Databases "]} }
- 对数组所有元素的不等于比较:$nin 带一个数组作为比较的操作数
- 对数组所有元素的相等比较:$all,如
{ categories : { $all : [" NoSQL ", " Document Databases "]} }
- 数组大小比较:$size,如
{ categories : { $size : 2} }
- 一个字段的(不)存在:$exists 带一个true或false的参数,如:
{ categories : { $exists : false }, body : { $exists : true } }
- 字段类型:$type 带一个BSON数据类型的数值型(如MongoDB手册指定,参见[ MMM+10c,条件运算符–$type ])
逻辑连接可以在查询对象中指定如下:
- 用逗号分隔的比较表达式代表一个AND连接。
- OR连接可通过特殊的$or操作符,赋值给布尔值或表达式的数组,每一个都可以满足查询。作为一个例子,下面的查询对象匹配已审查或正好有两个分类的文档:
{ $or: [ { reviewed : { $exists : true } }, { categories : { $size : 2} } ] }
- 为表达NOR连接,MongoDB支持$nor操作符。如同$or,其被赋值给表达式或布尔值的数组。
- 通过$not操作符,一个条目可被取反,如:
{ $not : { categories : {$in: {" NoSQL "}}} } // category does not contain " NoSQL "
{ $not : { title : /^ Mongo /i} } // title does not start with " Mongo "
下面是MongoDB手册对于某些字段类型的补充([ MMM+10c ]):
- 除了上述比较运算符,也可以为字符串字段做(PCRE,Perl-compatible Regular Expressions)正则表达式匹配。如果正则表达式只包含一个前缀检查(/^prefix/ [modifiers] 相当于SQL的like ‘prefix%’ ),MongoDB使用定义在那个字段上的索引如果可能的话。
- 要搜索数组中的单个值,在查询对象中数组字段可以简单地分配给所需的值,例如:
{ categories : " NoSQL " }
也可以指定数组中一个元素的位置:
{<field>.<index>.<field>: <value>}
- 如果一个数组字段指定了多个选择条件,则必须区分文档是否必须满足所有或其中一个条件。如果条件是用逗号分隔的,每一个条件可以用不同的子句来匹配。相反,如果每个返回文档都必须满足所有条件,必须使用特殊的$elemMatch操作符(参见[ MMM+10c,数组中的值–$elemMatch ]):
{ x: { $elemMatch : {a: 1, b: {$gt: 2}} } } // documents with x.a==1 and x.b >2
{ "x.a": 1, "x.b": {$gt: 2} } // documents with x.a==1 or x.b >2
- 对象内的字段通过以点分隔的字段名并将整个项放在双引号内来引用:“field.subfield”。如果匹配文件的所有字段在其精确顺序下与选择条件相关,以下语法需要被使用: { <subfield_1>:<value>, <subfield_2>: <value>} } ([ CMH+10 ],[ Mer10f ]、[ MHC+10A ])。
选择条件可以独立于应用程序使用的编程语言绑定被指定,通过$where操作符,其分配给一个字符串包含JavaScript语法的选择条件([ MMM+10b ]),如:
db.< collection >. find ( { $where : " this .a ==1" } );
如代码段指出,比较发生的对象由this关键字引用。除其他操作符外$where操作符可被指定。MongoDB建议选择上面所提到的标准操作符,带JavaScript条件表达式。这是因为第一种语句可以直接被查询优化器使用,因此评价更快。为优化查询性能,MongoDB首先计算所有其他条件,然后才解释分配到$where的JavaScript表达式([ MMM+10b ])。
投影 第二个参数可以提供给find操作以限制应检索的字段——类似于SQL语句的投影子句(即在关键字SELECT和FROM间指定的字段)。这些字段又是由包含其名称并赋值为1的BSON对象指定的(参见[ MS10 ]、[ CMB+10,一个简单的优化例子]):
db.< collection >. find ( {< selection criteria >}, {< field_1 >:1 , ...} );
字段规范也适用于使用点符号嵌入对象的字段(field.subfield),以及arrays中的范围。
如果只有特定字段被排除在find操作返回的文档外,则指定其值为0:
db.< collection >. find ( {< selection criteria >}, {< field_1 >:0 , <field_2 >:0 , ...} );
在这两种情况下,只返回文档的一部分,不能用于更新他们的原始文档。MongoDB手册此外备注主键字段 _id 总是在结果文档中被返回,不能被排除在外。
结果处理 find操作的结果可以进一步处理,通过使用sort操作进行排列,通过limit操作限制结果的数目,或通过skip操作忽略前n个结果(参见[ CMH+10,排序、跳过和限制 ]、[ MMM+10c,游标方法 ]、[ CMB+10,一个简单的优化例子 ]):
db.< collection >. find ( ... ). sort ({< field >: <1| -1 >}). limit (<number >). skip (<number >);
sort操作——等价于SQL中的ORDER BY字句——接受一个包含字段名加所需顺序(1:升序,-1:降序)的pair的文档作为参数。推荐在经常作为排序条件或限定返回值个数的字段上加一个索引,以避免大结果集的内存排序。如果没有对选择查询指定sort操作,结果集的文档以自然顺序被返回,这“不是特别有用,因为虽然该顺序往往接近插入顺序,但不能保证是这样”对标准表而言,根据MongoDB手册。然而,对所谓的上限集合(见下文)中的表,结果集的自然顺序可以被用于有效地“以插入顺序存储和检索数据”。相对地,为非上限集合上的选择查询使用sort操作是非常可取的([ MMD + 10 ])。
如果不使用limit操作,MongoDB返回所有匹配的文档,其以被称为块(即不作为一个整体)的文档组的形式被返回给客户端;在这样一个块中文档的数量是不固定的,可能会因不同的查询而有所不同。为limit和skip操作设定的值也可以传给find操作作为第三和第四个参数:
db.< collection >. find ( {< selection - criteria >}, {<field - inclusion / exclusion >}, <limit -number >, <skip -number > );
要快速、高效地检索查询结果的个数,可以在结果集上调用count操作:
db.< collection >. find ( ... ). count ();
为通过预定义的或任意的自定义函数来聚合结果,group操作被提供,可被看作相当于SQL的GROUP BY。
为限制一条查询评估的文档数量,可以指定字段的最小和/或最大值([ MCB10a ]):
db.< collection >. find ( {...} ).min ( {<field >: <value >, <... >: <...>, ....} ).max( {<field >: <value >, <... >: <...>, ....} );
db.< collection >. find ( $min : {...} , $max : {...} , $query : {...} );
用于指定上限和下限的字段必须被索引。当MongoDB评估范围时,传递给min的值是包含的(注:闭区间),而传递给max的值是不包含的(注:开区间)。对于单一字段,这也可以通过$gte和$lt操作来表达,这被MongoDB手册强烈推荐。另一方面,对复合字段很难指定范围——这种情况下使用最小/最大描述为佳。
除了这些查询或结果集上的操作,查询执行和其结果可以通过特殊操作符配置,例如限制被扫描的文档数量,或解释该查询(对于进一步的详情参见[ MMM+10c,特殊操作符 ])。
游标 find操作的返回值是一个游标,通过它一条查询的返回文档可被处理。下面的JavaScript例子显示了查询的结果集可以迭代( [ MMM+10c,游标方法 ]):
var cursor = db.< collection >. find ( {...}) ;
cursor . forEach ( function ( result ) { ... } );
为请求单一文档——典型地根据其主键字段 _id 被识别——应使用findOne操作替代find([ MMM+10 ]):
db.< collection >. findOne ({ _id : 921394}) ;
查询优化器 如上所述,MongoDB——不同于很多NoSQL数据库——支持ad-hoc查询。为有效地回复这些查询,查询计划被MongoDB中称为查询优化器的组件所创建。与关系数据库中的相似组件相比,它不是基于统计的,也不为多个可能的查询计划的成本建模。相反,它只是并行地执行不同的查询计划,并在第一个返回后终止其它所有的执行,从而学习对某个特定查询哪个查询计划是最适合的。MongoDB手册指出,这种方法“假定系统是非关系型时工作得特别好,其使可能的查询计划空间变小(因为没有连接)”([ MC10b ])。
插入
文档通过执行insert操作被插入MongoDB集合,只需要将要插入的文档作为一个参数([ CBH+10b,文档定位 ]):
db.< collection >. insert ( <document > );
MongoDB为传给insert操作的文档添加主键字段 _id 。
另外,文档也可以被插入到集合通过save操作([ MMM+10 ]):
db.< collection >. save ( <document > );
save操作包括插入和更新:如果 _id 字段不出现在传给save操作的文档中,则插入;否则更新集合中的文档以及 _id 值。
更新
如在上一段中讨论,save操作可用于更新文档。然而,也有一个显式的update操作具有额外的参数及如下语法([ CHD+10 ]):
db.< collection >. update ( <criteria >, <new document >, <upsert >, <multi > );
第一个参数指定选择条件,通过它可选出要更新的文档;它需要以和find操作相同的语法被提供。匹配上的文档需要被替换成的文档作为第二个参数提供。如果第三个参数设置为真,则第二个参数中的文档被插入,即使集合中没有文档匹配第一个参数的条件(upsert是update或insert的缩写)。如果最后一个参数被设置为真,所有匹配条件的文档被替换;否则只有第一个匹配的文档被更新。update操作的最后两个参数是可选的,默认设置为假。
在为良好的更新性能的努力中,MongoDB收集统计信息并推断哪些文档可能变大。对于这些文档,一些填充被保留以允许他们变大。这个方法背后的依据是,更新操作可被最有效地处理,如果修改后的文件大小不增长([ CHD+10,笔记,对象填充])。
修改操作 如果文档只有某些字段将被修改,MongoDB提供所谓的modifier操作,可以用于替代传一个完整的文档作为update的第二个参数([ CHD+10,修改操作 ])。Modifier操作包括数值递增($inc),设置和删除字段($set,$unset),将值添加到数组($push,$pushall,$addToSet),从数组中删除值($pop,$pull,$pullAll),替换数组值($)和重命名字段($rename)。
作为一个例子,下面的命令将第一个标题为“MongoDB”的文档的修订号递增1:
db.< collection >. update ( { title : " MongoDB "}, { $inc : { revision : 1}} );
相比于整个文档的替换,modifier操作的优点在于可以有效率地执行,因为“查询和返回对象的延迟”被避免。此外,modifier操作具有“操作的原子性和非常小的网络数据传输”的特性,根据MongoDB手册([ CHD+10,修改操作 ])。
如果modifier操作以upsert设置为真来使用,包含在modifier操作表达式中定义的字段的新文档将被插入。
原子更新 默认情况下,从MongoDB版本1.5.2起update操作是非阻塞的。这需要特别注意,因为对于同一个命令发出的多个文档的更新可能会和其它读写操作交错,从而导致非预期的结果。因此,如果要求原子性,$atomic标志必须设置为真,并加入update和remove操作的选择条件中([ CHD+10,笔记,阻塞 ])。
尽管如此,以下操作和方法已经提供或实现原子性,不必显式使用$atomic标志:
- 采用modifier操作的更新默认情况下是原子的([ CHD+10,更新操作 ]、[ MCS+10,更新操作 ])。
- 另一种原子地执行更新的方式被MongoDB手册称为“更新如果是最近的”,可与操作系统中引入的“比较并交换”策略相提并论([ MCS+10,更新如果是最近的 ])。它意味着选择一个对象(这里指:文档),在本地修改它并请求更新它,仅当自从对象被选择以来未在数据存储中被更改。作为“更新如果是最近的”的一个例子,下面的操作增加了一篇维基文章的修订号:
wikiArticle = db. wiki . findOne ( { title : " MongoDB "} ); // select document
oldRevision = wikiArticle . revision ; // save old revision number
wikiArticle . revision ++; // increment revision number in document
db. wiki . update ( { title : " MongoDB “,
revision = oldRevision }, wikiArticle ); // Update if Current
最后一个语句将只在修订号与第一个语句发生的时间相同时更新该文档。如果它自前三条语句执行后已被更改,则第四行的第一个参数的选择标准将不再匹配任何文档。
- 单文档可通过特殊的操作findAndModify被原子地更新,其选择、更新并返回一个文档([ MSB+10 ])。它的语法如下:
db.< collection >. findAndModify ( query : {...} ,
sort : {...} ,
remove : <true |false >,
update : {...} ,
new : <true |false >,
fields : {...} ,
upsert : <true |false >);
查询参数用来选择第一个被操作修改的文档。为更改结果集的顺序,可以按sort参数中指定的字段进行排序。如果返回的文档应在返回前被删除,remove参数必须设定为真。在update参数中,将指定如何修改选定的文档——或者通过提供一个完整的文档来替换它,或者使用modifier表达式。如果修改后的文档将被返回而不是返回原始的,new参数必须设置为真。为限制结果文档中返回的字段数,fields参数必须使用,其包含被设为1或0的字段名称以示选择或不选择它们。最后一个参数upsert指定如果查询结果集为空时是否应创建文档。
findAndModify操作在分片设置中也适用。如果被操作影响的集合是分片的,查询必须包含分片的键。
删除
为从一个集合中删除文档,必须使用remove操作,其接受一个文档带选择条件作为参数([ CNM+10 ]):
db.< collection >. remove ( { <criteria > } );
选择条件必须以和find操作相同的方式指定。如果它是空的,集合中的所有文档被删除。remove操作不会消除对删除文件的引用。从一个集合中删除单个文档最好是传 _id 字段给remove操作,因为根据MongoDB手册使用整个文档是低效的。
从MongoDB 1.3版起,当remove操作执行时默认允许并行操作。这可能导致虽然匹配传给remove的条件但文档没有删除,如果一个并发的update操作使文档变大。如果不期望这样的行为,remove操作需要原子地执行,不允许任何的并发操作,通过下面的语法:
db.< collection >. remove ( { <criteria > , $atomic : true } );
事务属性
对于事务,MongoDB只为update和delete操作提供原子性,通过设置$atomic标志为真并将其添加到选择条件。事务锁定和复杂事务不被支持,因为MongoDB手册中讨论的如下原因([ MCS+10 ]):
- 性能如“在分片环境中,分布式锁可能是昂贵和缓慢的”。MongoDB倾向于“轻量级和快”。
- 避免死锁
- 保持数据库操作简单、可预测
- MongoDB必须“对实时问题工作得很好”。因此,锁定大量的数据“可能会在较长时间内停止一些小而轻的查询...将使它更难以实现这一目标”。
服务器端代码执行
MongoDB——如同关系数据库和它们的存储过程——允许在数据库节点本地执行代码。MongoDB中服务器端代码执行包括三种不同的方法:
1、在一个数据库节点执行任意代码,通过eval操作([ MMC+10b ])
2、通过count,group和distinct操作聚集([ MMM+10g ])
3、在多个数据库节点以MapReduce方式的代码执行([ HMC+10 ])
每一种方法都在下一段简要讨论。
eval操作 为在一个数据库节点本地执行任意代码,代码必须被一个匿名的JavaScript函数包裹,并传递到MongoDB的通用的eval操作([ MMC+10b ]):
db. eval ( function (< formal parameters >) { ... }, <actual parameters >);
如果递给eval的函数传有形参,它们必须绑定为实际参数通过将其作为实参传递给eval。虽然eval可能有助于在一个服务器本地处理大量的数据,它必须小心地使用因为执行期间会有写锁。另一个重要的缺点是,eval操作不支持分片设置,使得MapReduce方法不得不被使用在下面所描述的场景中。
包含任意代码的函数也需要在一个键(带字段名_id)下保存,位于数据库服务器上一个特殊的名为system.js的集合中,随后通过它们的键被调用,如:
system .js. save ( {_id : " myfunction ", value : function (...) {...}} );
db.< collection >. eval ( myfunction , ...) ; // invoke the formerly saved function
聚集 为了实现查询结果的聚集,MongoDB提供了count,distinct和group操作,其可以通过编程语言库调用并在数据库服务器上执行([ MMM+10g ])。
count操作返回在一个集合上调用的查询匹配的文档数,接受选择条件作为参数,以和find操作相同的方式指定:
db.< collection >. count ( <criteria > );
如果以空条件调用count,则返回集合中的文档的数量。如果选择条件被使用,它所使用的文档字段应该被索引以加快count的执行(和find类似)。
为检索特定的文档字段的不同值,distinct操作被提供。它被调用通过以如下语法传一个文档给通用的runCommand操作或——如果被编程语言驱动提供——直接使用distinct操作:
db. runCommand ( { distinct : <collection >, key : <field > [, query : <criteria > ]} );
db.< collection >. distinct ( <document field > [, { <criteria > } ]);
文档的query部分是可选的,但可能对仅考虑一个集合中相关文档的不同字段值是有用的。文档中指定为key的字段也可以是使用点符号的嵌套字段(field.subfield)。
与SQL中的GROUP BY子句等价,MongoDB提供聚合操作group。group操作返回一个分组项的数组,并通过一个包含如下字段的文档来参数化:
db.< collection >. group ( {
key: { <document field to group by > },
reduce : function (doc , aggrcounter ) { <aggregation logic > },
initial : { < initialization of aggregation variable (s)> },
keyf : { <for grouping by key - objects or nestes fields > }
cond : { <selection criteria > },
finalize : function ( value ){ <return value calculation > }
});
传递给group操作的文档字段在表5.2中解释:
|
字段
|
描述
|
强制?
|
|
key
|
The document fields by which the grouping shall happen.
|
Yes (if keyf is
not specified)
|
|
reduce
|
A function that “aggregates (reduces) the objects iterated. Typical operations
of a reduce function include summing and counting. reduce takes two arguments: the current document being iterated over and
the aggregation counter object.”
|
Yes
|
|
initial
|
Initial values for the aggregation variable(s).
|
No
|
|
keyf
|
If the grouping key is a calculated document/BSON object a function
returning the key object has to be specified here; in this case key has
to be omitted and keyf has to be used instead.
|
Yes (if key is
not specified)
|
|
cond
|
Selection criteria for documents that shall be considered by the group
operation. The criteria syntax is the same as for the find and count operation. If no criteria is specified, all documents of the collection are
processed by group.
|
No
|
|
finalize
|
“An optional function to be run on each item in the result set just before
the item is returned. Can either modify the item (e. g., add an average field given a count and a total) or return a replacement object
(returning a new object with just _id and average fields).”
|
No
|
表5.2:MongoDB——group操作的参数([ MMM+10g,Group])
MongoDB手册提供了如何使用group操作的一个例子([ MMM+10g,Group]):
db.< collection >. group (
{key: { a:true , b: true },
cond : { active :1 },
reduce : function (doc ,acc ) { acc . csum += obj .c; },
initial : { csum : 0 }
}
);
相应的SQL语句看起来像这样:
select a, b, sum (c) csum from <collection > where active =1 group by a, b;
SQL函数sum重建在group函数上,以传递给group的文档的initial和reduce参数为例。initial的值定义了变量sum并将其初始化为0;该代码块在文档的选择和处理前被执行一次。对每个匹配条件(通过cond定义)的文档,赋给reduce键的函数被执行。这个函数添加选定文档(doc)的属性值c到累加变量(acc)的字段csum上,acc是传给函数的第二个参数([ MMM+10g ])。
group操作的一个限制是,它不能用于分片设置。在这些情况下在下一段讨论的MapReduce方法需被使用。MapReduce也允许实现自定义聚合操作,除了上述讨论的预定义的count,distinct和group操作。
MapReduce 第三种服务器端代码执行方法,特别适合于分片设置下的批量操作和数据聚合,称为MapReduce([ HMC+10 ])。MongoDB的MapReduce实现类似于Google的MapReduce论文中描述的概念([ DG04 ])及其开源实现Hadoop:有两个阶段——map和reduce——其JavaScript代码在数据库服务器上执行,导致一个临时或永久的包含输出的集合。MongoDB shell——以及大多数的编程语言驱动——提供了一种启动这样的MapReduce式数据处理的语法:
db.< collection >. mapreduce ( map : <map - function >,
reduce : <reduce - function >,query : <selection criteria >,sort : <sorting specificiation >,limit : <number of objects to process >,out: <output - collection name >,outType : <" normal "|" merge "|" reduce ">,keeptemp : <true |false >,finalize : <finalize function >,scope : <object with variables to put in global namespace >,verbose : <true |false >
);
MongoDB手册对于MapReduce主题有以下评论:
- mapreduce操作的必填字段是map和reduce,其必须被分配给JavaScript函数并带以下讨论的签名。
- 如果out被指定或keeptemp设置为true,MapReduce数据处理的输出结果被保存在一个永久集合中;否则包含结果的集合是临时的,如果客户端断开连接或显式drop时它被删除。
- outType参数控制out指定的集合如何填充:如果设置为“normal” ,在新的结果写入前集合将被清空;如果设置为“merge”,旧的和新的结果合并,使得从最新的MapReduce作业的返回值覆盖先前作业的值,如果键同时出现在旧的和新的结果中(即最新结果中没有出现的键保持不变);如果设置为“reduce”,最新的MapReduce作业的reduce操作被在旧值和新值上执行。
- map和reduce函数已经执行后,finalize函数被应用到所有结果上。与reduce对比,对一个给定的键和值它只被调用一次,而reduce被迭代地调用所以对于一个给定的键可能多次调用(见以下对reduce函数的约束)。
- scope参数被分配给一个JavaScript对象放在全局命名空间。因此,其变量在map,reduce和finalize函数中可访问。
- 如果verbose被设置为true,MapReduce作业执行时间的统计被提供。
map,reduce和finalize函数以如下方式被指定:
- 在map函数中,考虑了一个单一文档通过this关键字访问其自身的引用。map需要在它的执行中至少调用emit(key, value)一次,以添加一个键和值到中间结果中,其会在MapReduce作业执行的第二阶段被reduce函数处理。map函数有以下签名:
function map( void ) --> void
- reduce负责计算一个给定键的单一值,从map函数发射出的值数组中。因此,其签名如下:
function reduce (key , value_array ) --> value
MongoDB手册指出“MapReduce引擎可以迭代调用reduce函数;因此,这些功能必须是幂等的”。这种reduce的约束可以用如下谓词来形式化:
∀k, vals : reduce( k, [reduce (k, vals)]) ≡ reduce(k, vals)
在MongoDB版本1.6中,reduce的返回值不允许是一个数组。MongoDB进一步提出,map和reduce发射的数据“应该是格式一致的,使reduce的迭代成为可能”,并避免“难以调试的奇怪的错误”。
- 可选的finalize函数在reduce阶段后执行,并处理一个键和一个值:
function finalize (key , value ) --> final_value
与reduce对比,finalize函数仅对每个键调用一次。
MongoDB手册指出——与CouchDB对比——在MongoDB中MapReduce既不用于基本查询也不用于索引;它只有通过mapreduce操作显式调用。如前面章节提到的,在分片设置下MapReduce方法特别有用,甚至不得不使用(如服务器端的聚合)。只有在这些情况下MapReduce任务可以并行执行,因为“一个mongod进程上的任务是单线程的,由于目前JavaScript引擎的设计限制”([ MMM+10g,Map/Reduce ],[ HMC+10 ])。
维护和管理命令
MongoDB提供了发送到数据库的命令,以获得其运行状态信息或执行维护和管理任务。命令通过特定的命名空间$cmd执行,并具有以下基本语法:
db. $cmd . findOne ( { <commandname >: <value > [, options ] } );
当这样的一条命令发送到MongoDB服务器,其将以包含命令结果的一个单一文档来回应([ MMM+10e ])。
MongoDB命令的例子包括克隆数据库、刷写或挂起对磁盘上数据文件的写入、锁定和解锁数据文件以阻塞或放行写操作(为备份目的)、创建和删除索引、获取关于最近错误的信息、查看和终止运行的操作、验证集合、检索统计数据以及数据库系统信息([ CHM+10b ])。
5.2.5 索引
如关系型数据库系统,MongoDB允许为集合的文档字段指定索引。收集到的关于这些字段的信息存储在B树中,并被查询优化组件利用以“在集合中快速排序和整理文档”,从而提高读性能。
如关系型数据库,索引加速了选择以及更新操作,因为通过索引比全集合扫描找到文档的速度更快;另一方面,索引增加了插入和删除操作的开销,因为除了集合自身外B树索引也必须被更新。因此MongoDB手册总结到“索引对读数量大于写数量的集合最好。对于写密集型的集合,在某些情况下,索引可能会适得其反”([ MMH+10 ])。作为一般规则,MongoDB手册建议索引“作为键被查找的字段”以及排序的字段;应该被索引的字段也可以使用MongoDB提供的分析工具或通过在查询上调用explain操作来决定(参见[ MMM+10b,索引选择]、[ CMB+10,一个简单的优化例子])。
索引通过名为ensureIndex的操作被创建:
db.< collection >. ensureIndex ({< field1 >:< sorting >, <field2 >:< sorting >, ...}) ;
索引可以定义在任何类型的字段上——甚至是嵌套文档。如果只是嵌套文档的某些特定字段需要被索引,也可以使用点符号指定(即fieldname.subfieldname)。如果为一个数组字段指定索引,数组的每个元素都被MongoDB索引。排序标志可以为升序设置为1,为降序设置为-1。排序顺序和排序操作以及复合索引(即多个字段上的索引) 上的范围查询有关,根据MongoDB手册(参见[ MMH+10,复合键索引 ],[ MMM+ 10f ])。为查询一个数组或多个值的对象字段,$all操作符必须被使用:
db.< collection >. find ( <field >: { $all : [ <value_1 >, <value_2 > ... ] } );
默认情况下,MongoDB在 _id 字段上创建一个索引,其唯一地标识了集合中的文档,并预计将被作为一个常用的选择条件;但是,当手动创建一个集合,这个字段上的自动索引可能被忽视。另一个关于索引的重要选项是需要显式选择的后台索引生成,因为默认情况下索引生成会阻塞其他数据库操作。当使用后台索引时,索引是逐步生成的,这会比作为前台任务的索引更慢。只有当后台索引任务完成,后台建立的索引才可以被查询所用。MongoDB手册中提到关于(后台)索引的两个局限:首先,一次只能为每个集合建立一个索引;其次,在建立索引时某些管理操作(如repairDatabase)被禁用([ MH10b ])。
MongoDB也支持唯一索引,指定没有两个集合中的文档具有相同的值。要指定唯一索引,另一个参数被传递给上述ensureIndex操作:
db.< collection >. ensureIndex ({< field1 >:< sorting >, <field2 >:< sorting >, ...} , { unique :
true });
MongoDB手册警告说,索引字段必须在集合中的所有文档中存在。因为MongoDB自动使用null值插入所有缺失的索引字段,没有两个缺失相同的唯一索引键的文档可被插入。
MongoDB可以强制使用一个特定的索引,通过hint操作,以赋值为1的索引字段名作为参数:
<db.< collection >. find ( ... ). hint ( {< indexfield_1 >:1 , <indexfield_2 >:1 , ...} );
MongoDB指出,MongoDB中的查询优化器组件通常利用索引,但如果一个查询涉及到索引和非索引字段,可能会失败。也可以强制查询优化器忽略所有索引,并进行全集合扫描,通过$natural:1作为参数传给hint操作([ CMB+10,Hint])。
为查看特定集合中指定的所有索引,调用getIndexes操作:
db.< collection >. getIndexes ();
为删除集合中所有的索引或一个特定索引,必须使用以下操作:
db.< collection >. dropIndexes (); // drops all indexes
db.< collection >. dropIndex ({< fieldname >:< sortorder >, <fieldname >:< sortorder >, ...}) ;
索引也可以被重建通过调用reIndex操作:
db.< collection >. reIndex ();
MongoDB手册认为,这一手动索引重建一般是“不必要的”,但当“你的集合的大小发生了巨大变化或索引使用的磁盘空间大得奇怪”时,它对管理员有用。
5.2.6 编程语言库
截至2010年10月MongoDB项目为以下编程语言提供了客户端库:C,C#,C++,Haskell,Java,JavaScript,Perl,PHP,Python,Ruby。除了这些官方交付的库,有很多额外的、社区的库为更多语言提供,如Clojure,F #,Groovy,Lua,Objective C,Scala,Schema,和Smalltalk。这些库——被MongoDB项目称为驱动——提供编程语言的数据类型和BSON格式之间的数据转换,以及一个与MongoDB服务器交互的API([ HCS+10 ])。
5.2.7 分布式方面
并发和锁
MongoDB的架构被描述为“并发友好的”虽然“粒度锁和闩锁的一些工作尚未完成。这意味着一些操作可能阻塞别的。”
MongoDB对很多操作使用读/写锁,“[任何]数量的并发读操作被允许,但通常只有一个写操作”。写锁的获取是贪婪的,且如果等待,会阻止后续的读锁请求([ MHH10 ])。
复制
为MongoDB集群出现不可用节点时的冗余和故障转移,MongoDB提供了异步复制。在这样的设置中,在任何给定的时间只有一个数据库节点负责写操作(称为主服务器/节点)。为强一致性语义读操作可以去这个服务器,或如果最终一致性是足够的则去其任何副本节点([ MMG+10 ])。
MongoDB文档讨论了复制的两种方法——主从复制和副本集——如图5.1中所描述。
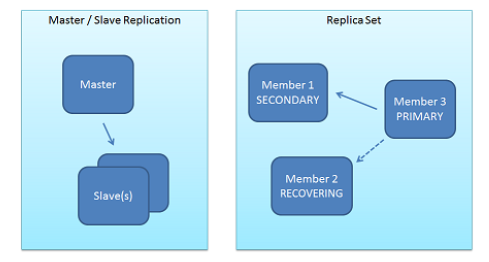
图5.1:MongoDB——复制方法(来自[ MMMG+10 ])
主-从 是一种由2台服务器组成的设置,其中包括一个主机处理写请求并复制这些操作到另一个服务器:从([ MJS+10 ])。(注:实际上可以有多个从机)
启动一个主从设置需要通过以主模式启动一个MongoDB进程,并以带指定其主节点的参数的从模式启动第二个进程:
mongod -- master <further parameters >
mongod --slave -- source <master hostname >[: < port >] <further parameters >
关于从服务器的一个重要说明是,如果他们与主机的写操作相比落后太多,或他们被重启但在停机时间内的更新操作无法再完整地从主机得到,则复制将停止。在这些情况下,“复制将终止,且如果需要重新启动复制则默认需要操作员干预”([ MJS+10 ],同时[ BMH10 ])。作为替代,从节点可以带–autoresync参数启动,使之在不同步时重新启动复制。
一次永久的故障转移,从主机到从机或角色反转,只可能以关闭并重新启动这两类服务器实现([ MJS+10,管理任务])。
副本集 是一组MongoDB节点“一起工作以提供自动故障转移”([ BCM+10 ])。他们被描述为“一个对现有主/从复制的加工,增加自动故障转移和成员节点的自动恢复”([ MCD+10 ])。为设置一个副本集,下面的步骤是必需的([ BCM+10 ]):
1、启动n个MongoDB节点,带–replSet参数:
mongod -- replSet <name > --port <port > -- dbpath <data directory >
2、初始化副本集,通过连接一个启动的mongod进程,并传输一个副本集的配置文档给rs.initiate操作,通过MongoDB shell:
mongo <host >:< port >
> config = {_id : ’<name >’,
members : [
{_id: 0: host : ’<host >:< port >’},
{_id: 1: host : ’<host >:< port >’},
{_id: 2: host : ’<host >:< port >’}
]}
> rs. initiate ( config );
接收rs.initiate命令的MongoDB节点传输配置对象到其他节点,并在集合成员中选出一个主节点。如果一个副本集节点以-rest参数启动副本集的状态可以通过rs.status操作或web管理界面获得,如([ Mer10c ])。
为添加更多的节点到副本集,他们带–replset启动参数及节点希望加入的副本集的名称([ DBC10 ]):
mongo -- replSet <name > <further parameters >
添加到副本集的节点必须或者有一个空数据目录,或者有另一个节点数据目录的最近的拷贝(以加速同步)。这是由于MongoDB不具有多版本存储或任何冲突解决支持的特性(见下面阐述限制的章节)。
如果一个副本集启动并正确运行,到主节点的写操作被复制到其他节点,通过传播操作并应用于本地存储的数据之上([ Mer10e ])。这种方法类似于在3.1.3节中描述的向量时钟下的状态传播的操作传输模型。在MongoDB中,副本集的节点收到的操作被写入到一个上限集合,其具有一个有限的大小,不应设置过低。不过,如果操作被省略没有数据被丢失,因为新的操作到达比本地节点应用它到本地数据存储的速度更快;仍可能完全同步这样的一个节点[ Mer10d ]。在副本集的节点间传播的写操作通过接收他们的服务器(那时为主服务器)的id和一个整体增加的序号来区分([ MHD+10 ])。MongoDB分指出,“初始复制对故障转移是必不可少的;系统不会故障转移到新主节点,直到节点之间的初始同步完成”。
副本集可以包含多达7个服务器,可以承担标准服务器(存储数据,能成为主服务器),被动服务器(存储数据,不能成为主服务器)或仲裁(不存储数据但参与选出新主服务器的协调过程;参见[ MHD+10 ])的角色。复本集考虑了数据中心配置——根据MongoDB文档——在版本1.6实现得不完全,但已经实现功能选项如主和灾难恢复站点以及本地读取([ Mer10b ])。副本集有以下的一致性和持久性语义([ MD10 ]):
- 写操作被提交仅当其被复制到法定个数(多数)的数据库节点中。
- 当写操作被传送到副本节点时它们已对主节点可见,因此一个未提交到所有节点的新版本已经可以从主节点读取。这种未提交读语义被引入——在理论上——可以这种方式实现更高的性能和可用性。
- 在主数据库节点故障导致故障转移的情况下,所有未被复制到其它节点的数据被删除。如果主节点再次可用,其数据作为备份但不会自动恢复,因为需要手动干预来合并其数据库内容与副本节点的内容。
- 故障转移期间,即其他节点声明主节点宕机并选出新主节点的时间窗口中,写和强一致性读操作是不可能的。然而,最终一致性的读操作可以被执行([ MH10a,故障转移需多长时间? ])。
- 为检测网络分区,每个节点通过心跳监测其它节点。如果一个主服务器接收不到至少一半的节点的心跳(包括自己),它将退出其主节点状态并不再处理写操作。“否则在网络分区中,服务器可能认为自己还是主节点但实际上已经不是了”([ MHD+10,设计,心跳监测 ])。
- 如果一个新的主服务器被选出,可能会导致有关一致性的一些严重影响:因为新主被假定为有最新的状态,次节点上所有较新的数据将被丢弃。这种情况被次节点通过他们的操作日志检测到。已经被执行的操作被回滚,直到它们的状态与新主的状态一致。在该回滚期间更改的数据被保存到一个文件中,且不能被副本集自动应用。次节点可能比新选出的主有一个较新的状态的情况,可能由在次节点已提交但新主节点尚未提交的操作导致(在操作发出时新主节点还是次节点;参见[ MHD+10,设计,主的假设;设计,同步(连接到新主)])。
在MongoDB 1.6版本中,副本集的认证机制不可用。进一步的限制是MapReduce任务只能在主节点运行因为他们创建新的集合([ MC10a ])。
从复制中排除数据 可通过把不应提交给复制的数据放入特殊的数据库local实现。除了用户数据,MongoDB还在这个库中存储管理数据如复制的配置文档([ Mer10a ])。
分片
从1.6版本起,MongoDB通过自动分片架构支持水平扩展,以分散数据到“数千个节点”,并实现负载和数据的自动均衡以及自动故障转移([ MHC+10b ]、[ MDH+10 ])。
分片被理解为“以一种保序方式在多台机器上的数据分区”,按MongoDB文档。MongoDB提到雅虎的PNUTS([ CRS+08 ])和谷歌的Bigtable([ CDG+06 ] )对MongoDB实施的分区方案有重要影响(参见[ MDH+10,MongoDB的自动分片,扩展模型 ])。MongoDB的分片“发生在每一个集合的基础上,而不是以数据库作为一个整体”。在一个分片的配置中,MongoDB自动检测哪个集合的增长速度超过平均水平,使得他们开始受分片约束,而其他集合仍驻留在单个节点。MongoDB也检测不同分片必须承担的负载的不平衡,并能自动平衡数据以减少不成比例的负载分配([ MDH+10,MongoDB的自动分片 ])。
MongoDB的分片建立在副本集之上,上面已讨论过。这意味着对每个分区的数据,由一些组成副本集的节点负责:在任何时刻,这些服务器之一是主节点并处理所有写请求,然后传播到次服务器以复制更改并保持该集的同步;如果主节点失败,剩余的节点通过协商选择一个新的主节点,使得副本集的操作被继续。这种方式,自动故障转移为每个分片提供(参见[ MDH+10,MongoDB的自动分片,平衡和故障转移])。
分片架构 MongoDB的分片集群由三个组件组成,如图5.2描述(参见[ MDH+10,架构概况]):
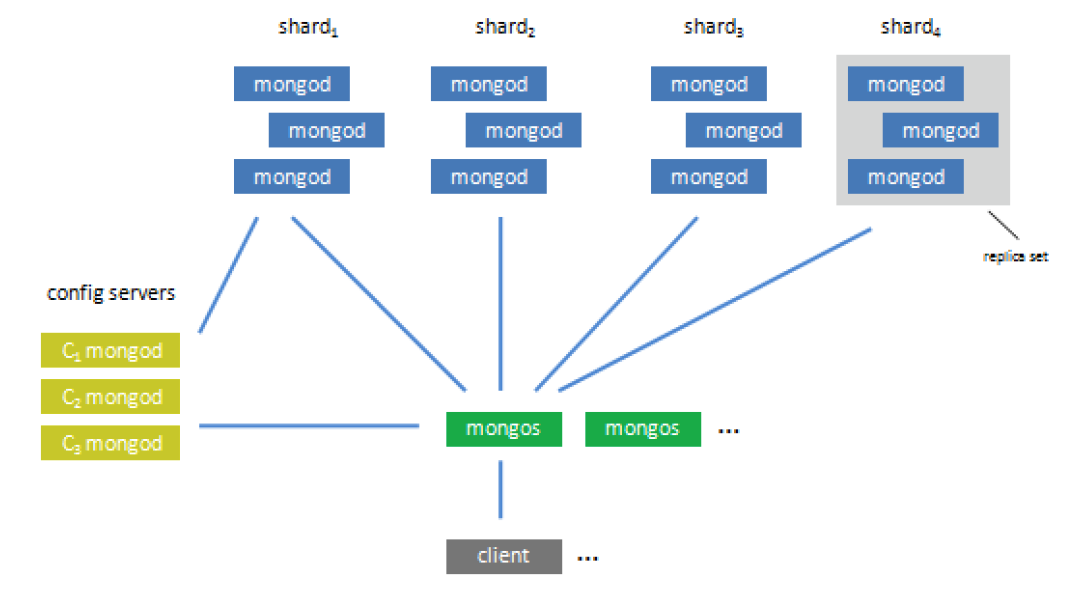
图5.2:MongoDB——分片组件(来自[ MDH+10,架构概况])
分片 由运行mongod进程和存储数据的服务器组成。为在生产系统确保可用性和自动故障转移,每个分片通常包含组成一个副本集的多台服务器。
配置服务器 “存储集群的元数据,包括每一个分片服务器的基本信息和其中包含的块”。块是来自集合的数据的连续范围,其根据分片的键来排序并存储在分片上(分片键和块在下面更详细地讨论)。每个配置服务器存储完整的块元数据,并能够推断特定文件驻留在哪个分片上。配置服务器上的数据保持一致通过两阶段提交协议和一种特殊的复制方案(即主从复制或副本集不用于此目的)。存储在配置服务器上的元数据成为只读的,如果这些服务器中的任何一台不可达;在这种状态下,数据库仍然是可写的,但它变得不可能在分片间重新分布数据([ MHB+10b ])。
路由服务 是服务器端mongos进程,其代表客户端应用执行读写请求。他们负责通过配置服务器寻找被读取或写入的分片,连接到这些分片,执行所请求的操作并返回结果给客户端应用程序,也负责合并在不同分片上请求执行的结果。这使得分布式MongoDB配置像为客户端应用程序提供服务的单一服务器,对分片无感知;甚至编程语言的库不需要考虑分片。mongos进程不保存任何状态,也不需要协调分片设置下的各个节点。此外,他们被MongoDB文档描述为轻量级的,使得它不限制运行任何数量的mongos进程。mongos进程可以在任何类型的服务器上执行——碎片、配置服务器以及应用程序服务器。
分片、配置和路由服务器可以在物理或虚拟服务器上以不同的方式组织,按MongoDB文档描述的([ MDH+10,服务器布局 ])。一个最小的分片设置需要至少两个分片,一个配置和一个路由服务器([ MHB+10A,介绍])。
分片方案 如上所述,MongoDB中的分区基于集合产生。对每个集合,可以配置通过一定数量的字段来对文档分区。如果MongoDB随后检测到负载和集合数据大小上的不平衡,它根据配置的键将其文档分区,同时保持键的顺序。如文档字段name被配置为集合users的分区键,配置服务器上这个集合的元数据可能如图5.3所示。

图5.3:MongoDB——分片元数据例子(来自[ MDH+10,架构概况,分片,分片键 ])
分片持久化 集合的文件被存储在所谓的块,连续范围的数据。他们以三元组(collection,minkey,maxkey)被标识,其中minkey和maxkey是作为分片键的文档字段的最小值和最大值。如果块成长到一个配置的大小,他们分裂成两个新的块([ MDH+10,架构概述 ])。如版本1.6,对客户端应用程序来说,块的“分裂作为插入的副作用发生(且透明的)”。块可以在后台分片服务器间迁移,直到数据和负载均匀分布;这是通过“称为平衡器的子系统实现的,其不断监控分片负载和移动块,如果它发现一个失衡”([ MSL10 ])。
MongoDB手册指出,选择分片键使得“粒度足够确保数据的均匀分布”是重要的。这意味着,应该将一个有大量不同值的文档字段选为分片键,使得它总是可以分裂块。一个反例可能是上述提到的name字段:如果一个块仅包含带有流行的名字像“史密斯”的文档,其不能分裂成更小的块。这是由于这一事实,一个块通过上述三元组区分(collection,minkey,maxkey):如果minkey和maxkey已经有相同的值且分片要保持文档的顺序,这样的块不能再分裂了。为了避免这样的问题,也可以指定复合的分片键(如lastname,firstname;参见[ MDH+10,架构概况 ])。
建立一个分片的MongoDB集群 通过以下步骤执行([ MHB+10a,分片集群的配置 ]):
1、通过mongod命令加-shardsvr标志启动一批分片:
./ mongod -- shardsrv <further parameters >
2、通过mongod命令加-configsvr标志启动一批配置服务器:
./ mongod -- configsvr <further parameters >
3、通过mongos命令加-configdb标志以指定配置服务器来启动一批路由服务器:
./ mongos -- configdb <config server host >:< port > <further parameters >
4、连接到一个路由服务器,切换到admin数据库并增加分片:
./ mongo <routig server host >:< routing server port >/ admin
> db. runCommand ( { addshard : "< shard hostname >:< port >" } )
5、为数据库启用分片,其中包含了集合:
./ mongo <routig server host >:< routing server port >/ admin
> db. runCommand ( { enablesharding : "<db >" } )
> db. runCommand ( { shardcollection : "<db >.< collection >",
key : {< sharding key(s) >} } )
失败 在一个分片环境有以下的影响,取决于失败的类型([ MHB+10b ]):
- 一个mongos路由进程的失败不是关键的因为可能——在生产环境应该——有多个路由进程。在这些进程中的一个失败的情况下,它可以简单地被重新启动,来自客户端应用程序的请求被重定向到另一个路由进程。
- 一个分片内的单一mongod进程失效不影响这个分片的可用性,如果它被分布在不同的组成副本集的服务器上。上述副本集节点故障的说明再次应用于此。
- 所有组成分片的mongodb进程的失败使分片无法执行读和写操作。然而,在这个失败场景中,对其他分片的操作不会被影响。
- 一个配置服务器的失败不影响分片的读写操作,但使得其分裂和块的重新分布变得不可能。
分片的影响 它“必须跑在可信安全模式,没有显式的安全”,1.6版本下分片键不能被改变,写操作(update、insert、upsert)必须包括分片键([ MDN+10 ])。
对于分布式的限制和放弃的特性
MongoDB不提供多版本存储,多主复制设置或任何版本冲突调解的支持。采用与许多其他NoSQL存储不同的实现和不提供这些功能的理论依据,被MongoDB文档说明如下:
“合并旧操作,在另一个节点已接受写入操作后,是一个很难的问题。一个数据有多个主副本,有写入冲突的潜在可能。通常情况下,在其他产品中由用户代码手动解决版本调解的问题。我们认为那有太多的工作:我们希望MongoDB的使用只需更少的开发者工作,而不是更多。多主也可以使原子操作有语义问题。或许可以(如上所述)手动恢复这些事件,通过手动的DBA工作,但我们相信在有许多节点的大型系统,这样的努力变得不切实际。”([ MD10,理论依据 ])
5.2.8 安全和认证
根据文档,在1.6版中“MongoDB只支持最基本的安全”。它可以创建数据库的用户帐户,要求他们通过用户名和密码进行身份验证。然而,认证用户的访问控制只区分读写访问权限。MongoDB数据库服务器进程(即一个mongod进程)的一个特殊用户是admin,其有该进程提供的完全的读和写访问权限,包括包含管理数据的admin数据库。一个admin用户也被授权执行管理操作([ MMC+10A,Mongo安全 ])。
为获取对数据库服务器进程的认证,mongod进程被带–auth参数启动。在此之前,管理员必须在admin数据库中创建。一个登录的管理员可以为system.users集合创建读和写权限的帐户,通过addUser操作([ MMC+10a,配置身份认证和安全 ]):
./ mongo <parameters > // log on as administrator
> use <database >
> db. addUser (< username >, <password > [, <true |false >])
addUser操作第三个可选的参数表明是否用户只能拥有读的权限;如果其被省略,被创建的用户将有数据库的读取和写入访问权限。
身份认证和访问控制在分片和共享设置下不能使用。它们只能在确保“只有受信任的机器可以访问数据库的TCP端口”的环境下安全运行([ MMC+10a,不带安全运行(可信环境)])。
5.2.9 特殊特性
上限集合
MongoDB允许指定固定大小的集合,被称为上限集合,根据手册可被MongoDB高效地处理。一个这种上限集合的大小被预先分配,并通过FIFO方式(根据插入时间)删除文档来保持恒定。如果在上限集合上执行选择查询,则结果集的文档以其插入顺序被返回,如果没有被显式地排序,即文档字段没有使用sort操作来排序结果。
上限集合有一些关于操作文件的限制:因文档的插入总是可能的,更新操作只有在修改后的文件大小不增长的情况下才能成功,删除操作对单文档不可用,但能删除上限集合的所有文档。上限集合的大小在32位机器上限制为10的9次(注:存疑)个字节,在64位机没有这样的限制。上限集合的一个进一步限制是,他们不能被分片。如果在选择文档时没有指定顺序,它们以插入的顺序被返回。除了限定上限集合的大小,也可以指定其存储对象的最大数目([ MDM+10 ])。
MongoDB提到以下上限集合的用例([ MDM+10,应用]):
日志 是上限集合的一个应用,因为文档的插入以相当于文件系统写入的速度被处理,而日志所需的空间保持不变。
缓存 小的或数量有限的预计算对象的缓存,以LRU方式通过上限集合方便地实现。
自动存档 MongoDB手册认为是这样一种情景,老的数据需要从数据库中删除。对于其他数据库和普通MongoDB集合,脚本需要被编写和调度以根据年龄删除数据,上限集合已经提供了这样的行为,不需要进一步的操作。
GridFS
允许在MongoDB中存储二进制数据的BSON对象有4MB大小限制。因此,MongoDB实现了一个规范名为GridFS以存储大型二进制数据并提供大数据对象——如视频或音频——上的操作,像检索这样一个对象的有限数目个字节。GridFS规范被MongoDB实现为对客户端应用程序透明,通过分割一个集合的多个文档中的大数据对象,并在这些文档上维护一个包含元数据的集合。大多数编程语言驱动也支持GridFS规范([ CDM+10 ])。
MongoDB手册认为GridFS也可作为一种文件系统存储的替代,当大量文件必须被维护、复制和备份,以及如果文件被预计经常改变的话。相反,如果大量的小型静态文件需要被存储和处理,通过GridFS存储在MongoDB中被视为不合理的([ Hor10 ])。
地理空间索引
为了支持基于位置的查询,如“找到离一个特定的位置最近的N个项目”,MongoDB提供二维地理空间索引([ HMS+10 ])。纬度和经度值必须保存在文档字段中,其是一个对象或一个数组,前两个元素表示坐标,例如
{ loc : { 50, 30 } } // coordinates in an array field
{ loc : { x : 50, y : 30} } // coordinates in an object field
如果使用了一个对象字段,则该对象的字段不必具有特定名称,也不必以一定的顺序出现(虽然所有文件中的顺序必须是一致的)。
地理空间坐标的一个索引使用特殊的值2d创建,而不是通过一个命令:
db.< collection >. createIndex ( { <field > : "2d" } );
因创建索引没有额外的参数,MongoDB认为纬度和经度值应当被索引,因此索引范围被限定在区间[−180...180]。如果其他值被索引,索引范围应在索引创建时按如下方法给出:
db.< collection >. createIndex ( { <field > : "2d" } , { min : <min -value ,
max : <max - value });
范围的界限是不包含的,这意味着索引值不能采用这些值。
为基于地理空间索引查询,查询文档可以包含特殊的条件如$near和$maxDistance:
db.< collection >. find ( { <field > : [< coordinate >, <coordinate >]} ); // exact match
db.< collection >. find ( { <field > : { $near : [< coordinate >, <coordinate >] } } );
db.< collection >. find ( { <field > : { $near : [< coordinate >, <coordinate >],
$maxDistance : <value >} } );
除了限制会用于匹配的距离,也可能要定义一个覆盖一个地理空间区域的形状(方或圆)作为选择条件。
除了通用find操作,MongoDB还提供了专门的方式以查询地理信息,使用geoNear操作。这种操作的优点是它为每一个匹配的文件返回一个距离值,并允许诊断和故障处理。geoNear操作必须使用db.runCommand语法调用:
db. runCommand ({ geoNear : <collection >, near = [< coordinate >, <coordinate >], ...}) ;
如语法例子所示,没有字段名被提供给geoNear操作,因为它会自动确定查询集合的地理空间索引。
当使用上述$near条件,MongoDB的计算基于一个理想化的扁平地球模型,其纬度和经度的弧度值在每个位置的间隔是相等的。自MongoDB 1.7球状模型的地球被提供,因此查询可以使用正确的球面距离通过使用$sphereNear条件(替代$near),$centerSphere条件(匹配圆形)或添加选项spherical:true到geoNear操作的参数。当使用球面距离时,坐标值必须以十进制值和按经度、纬度的顺序提供,并使用弧度测量。
地理空间索引具有一些局限在MongoDB版本1.6.5(稳定)和1.7(不稳定于2010年12月)。首先,它被限制索引没有外边界包围的正方形。其次,每个集合只允许一个地理空间索引。第三,MongoDB未实现极点的包围或-180°至180°的边界。最后,地理信息索引不能被分片。















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









