






1. Solr 官网
搜索引擎是指一个庞大的互联网资源数据库,如网页,新闻组,程序,图像等。它有助于在万维网上定位信息。用户可以通过以关键字或短语的形式将查询传递到搜索引擎中来搜索信息。 搜索引擎然后搜索其数据库并向用户返回相关链接。
1). 搜索引擎基本组件
- Web爬虫 - Web爬虫也称为蜘蛛或机器人。 它是一个收集网络信息的软件组件。
- 数据库 - Web上的所有信息都存储在数据库中。它们包含大量的Web资源。
- 搜索接口 - 此组件是用户和数据库之间的接口。它帮助用户搜索数据库。
2). 搜索引擎工作过程
| 步骤 | 标题或名称 | 描述 |
|---|---|---|
| 1 | 获取原始内容 | 任何搜索应用程序的第一步是收集要进行搜索的目标内容。 |
| 2 | 构建文档 | 从原始内容构建文档,让搜索应用程序可以很容易地理解和解释。 |
| 3 | 分析文档 | 在索引开始之前,将对文档进行分析。 |
| 4 | 索引文档 | 当文档被构建和分析后,下一步是对它们建立索引,以便可以基于特定键而不是文档的全部内容来检索该文档。索引类似于在书开始页或末尾处的目录索引,其中常见单词以其页码显示,使得这些单词可以快速跟踪,而不是搜索整本书。 |
| 5 | 用于搜索的用户接口 | 当索引数据库就绪,应用程序可以执行搜索操作。 为了帮助用户进行搜索,应用必须提供用户接口,用户可以在其中输入文本并启动搜索过程 |
| 6 | 构建查询 | 当用户做出搜索文本的请求,应用程序应该使用该文本来准备查询对象,然后可以使用该查询对象来查询索引数据库以获得相关的细节。 |
| 7 | 搜索查询 | 使用查询对象,检查索引数据库以获取相关详细信息和内容文档。 |
| 8 | 渲染结果 | 当收到所需的结果,应用程序应决定如何使用其用户界面向用户显示结果。 |
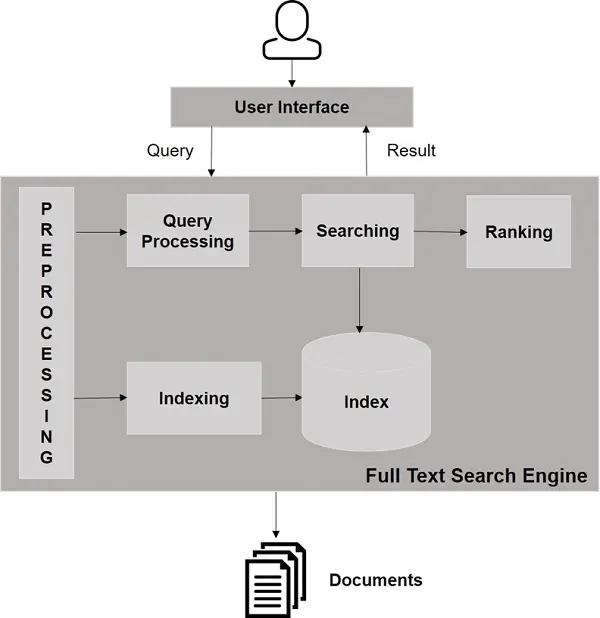
3). 安装
I. Solr 下载并解压
II. 启动
solr start
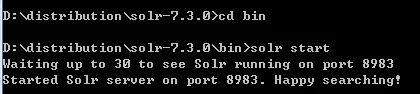
III. 验证
浏览器输入http://localhost:8983/
4). Solr 体系结构
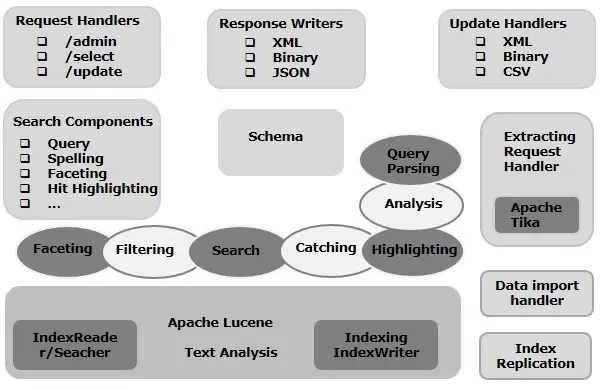
Solr的主要构建块(组件)
- 请求处理程序 - 发送到Apache Solr的请求由这些请求处理程序处理。请求可以是查询请求或索引更新请求。根据这些请示的要求来选择请求处理程序。为了将请求传递给Solr,通常将处理器映射到某个URI端点,并且它将为指定的请求提供服务。
- 搜索组件 - 搜索组件是Apache Solr中提供的搜索类型(功能)。它可能是拼写检查,查询,构面,命中突出显示等。这些搜索组件被注册为搜索处理程序。多个组件可以注册到搜索处理程序。
- 查询解析器 − Apache Solr查询解析器解析传递给Solr的查询,并验证查询的语法是否有错误。解析查询后,将它们转换为Lucene理解的格式。
- 响应写入器 - Apache Solr中的响应写入器是为用户查询生成格式化输出的组件。 Solr支持XML,JSON,CSV等响应格式。对每种类型的响应都有不同的响应写入。
- 分析器/分词器 - Lucene以令牌的形式识别数据。 Apache Solr分析内容,将其分成令牌,并将这些令牌传递给Lucene。 Apache Solr中的分析器检查字段的文本并生成令牌流。分词器将分析器准备的令牌流分解成令牌。
- 更新请求处理器 - 每当向Apache Solr发送更新请求时,请求都通过一组称为更新请求处理器的插件(签名,日志记录,索引)运行。这个处理器负责修改,例如删除字段,添加字段等。
5). Solr 术语
- 实例 - 就像一个tomcat实例或一个jetty实例,这个术语指的是在JVM中运行的应用程序服务器。Solr主目录提供对每个这些Solr实例的引用,一个或多个核心可以配置在每个实例中运行。
- 核心(core) - 在应用程序中运行多个索引时,可以在每个实例中拥有多个核心,而不是每个核心的多个实例。
- 主目录(home) - 术语$SOLR_HOME是指主目录,其中包含有关内核及其索引,配置和依赖关系的所有信息。
- 碎片(Shard) - 在分布式环境中,数据在多个Solr实例之间进行分区,其中每个数据块可以称为碎片(Shard)。它包含整个索引的子集。
6). Solr Cloud 术语
- 节点(Node) - 在Solr云中,Solr的每个单个实例都被视为一个节点。
- 集群 - Solr云环境中的所有节点组合在一起构成集群。
- 集合 - 集群具有称为集合的逻辑索引。
- 碎片 - 碎片是集合的一部分,它具有一个或多个索引副本。
- 副本 - 在Solr Core中,在节点中运行的分片副本称为副本。
- 领导者(Leader) - 它也是碎片的副本,它将Solr Cloud的请求分发给剩余的副本。
- Zookeeper - 这是一个Apache项目,Solr Cloud用于集中配置和协调,管理集群和选择领导者。
7). Solr中的主要配置文件如下 -
- Solr.xml - 它是包含Solr Cloud相关信息,此文件是在$SOLR_HOME目录中。 为了加载核心,Solr引用这个文件,这有助于识别它们。
- Solrconfig.xml − 此文件包含与请求处理和响应格式化相关的定义,核心特定配置,以及索引,配置,管理内存和提交。
- Schema.xml − 此文件包含整个模式以及字段和字段类型。
- Core.properties - 此文件包含特定于核心的配置。它被引用为核心发现,因为它包含核心的名称和数据目录的路径。它可以在任何目录中使用,会将此目录它视为核心目录。
8). 基本命令
I. 后台启动
solr start
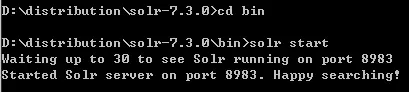
II. 停止
solr stop -all
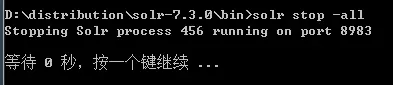
III. 前台启动
solr start -f
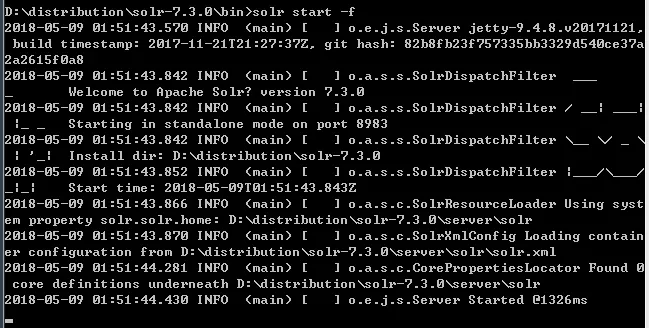
IV. 另一个端口上启动Solr
solr start -p 8081
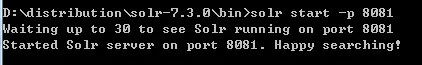
V. 重新启动Solr
solr start -p 8081
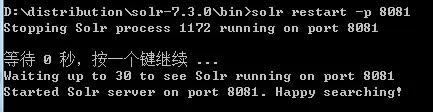
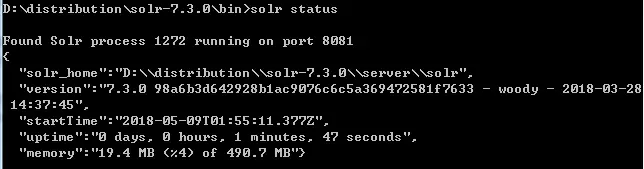
VI. Solr 状态
solr status
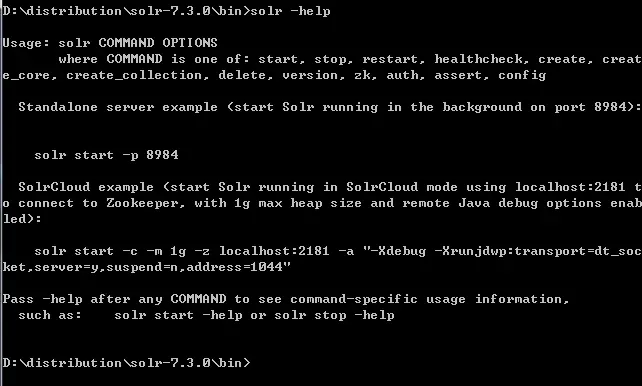
VII. Solr 帮助
solr -help
VIII. 指定端口停止
solr stop -p 8081

2. Solr 使用
1). Solr核心(Core)
核心是Lucene索引的运行实例,包含使用它所需的所有Solr配置文件。我们需要创建一个Solr Core来执行索引和分析等操作。Solr应用程序可以包含一个或多个核心。 如果需要,Solr应用程序中的两个核心可以相互通信。
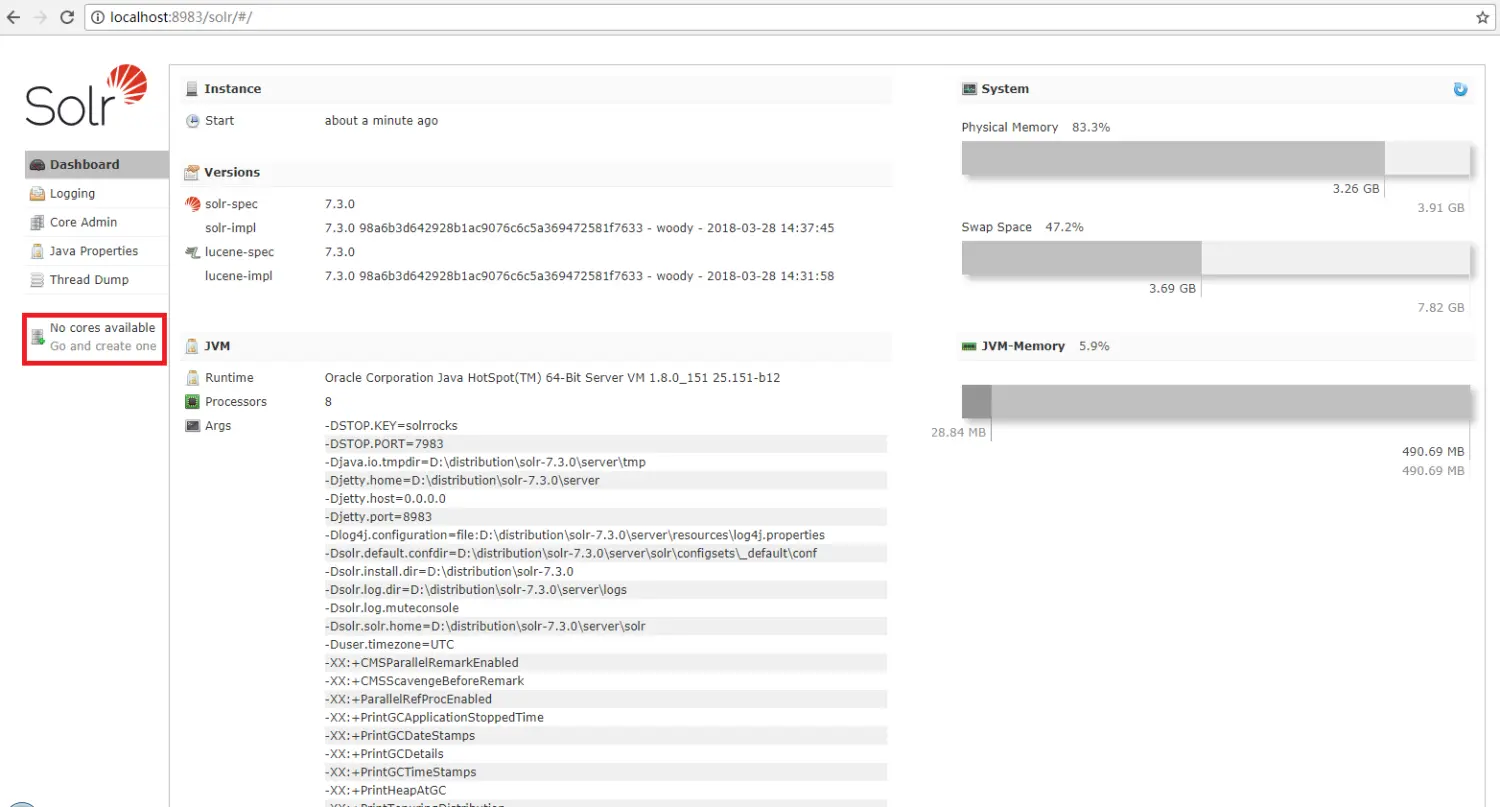
I. create 命令创建
solr create -c solr_sample

II. create_core创建
solr create_core -c my_core
参数:
- -c core_name 要创建的核心的名称
- -p port_name 要创建的核心的端口
- -d conf_dir 端口的配置目录

这时刷新
http://localhost:8983/solr/#/后可看到存在两个核心了
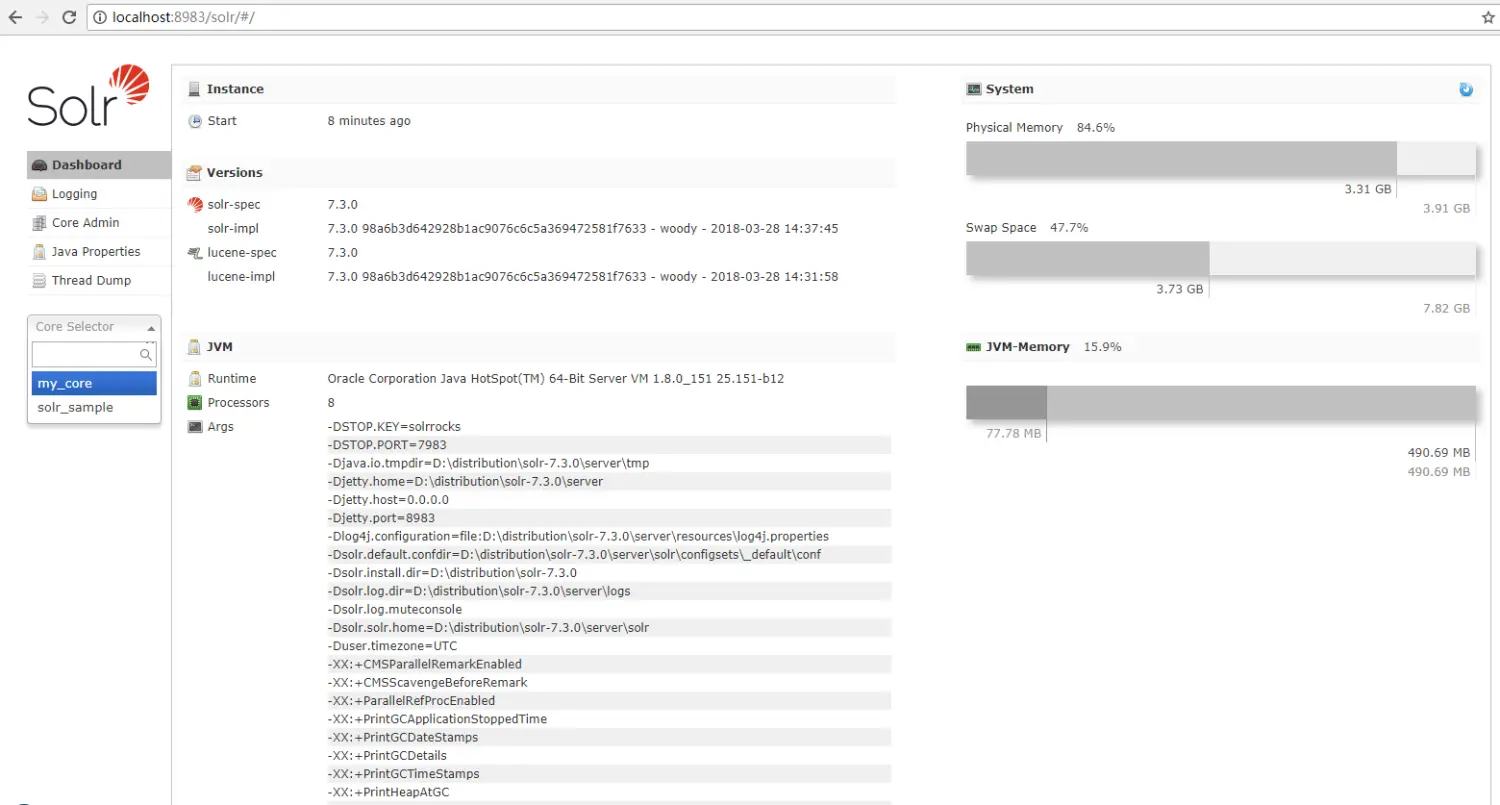
III. 删除核心
solr delete -c my_core

IV. 控制台创建
Core Admin -> Add Core
2). 索引
索引是系统地排列文档或(其他实体)。索引使用户能够在文档中快速地查找信息。
- 索引集合,解析和存储文档。
- 索引是为了在查找所需文档时提高搜索查询的速度和性能。
在Apache Solr中,我们可以索引(添加,删除,修改)各种文档格式,如xml,csv,pdf等。可以通过几种方式向Solr索引添加数据。
I. Post命令添加文档
Solr在其bin/目录中有一个post命令(Windows中无法使用)。使用这个命令,可以在Apache Solr中索引各种格式的文件。
- 将
\solr-7.3.0\example\exampledocs\目录下的post.jar拷贝到\solr-7.3.0\bin中, 使用命令执行添加文档
java -Dtype=text/csv -Dc=solr_sample -jar post.jar C:\Users\Administrator\Desktop\sample.csv
成功提示:
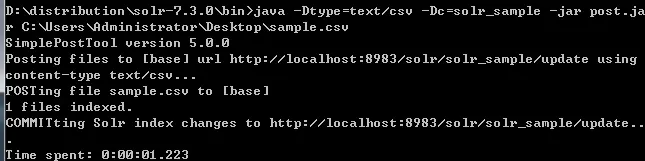
sample.csv即
solr-7.3.0\example\exampledocs下的book.csv
II. 查询
进入控制台
http://localhost:8983/solr/#/, 选择solr_sample核心,点击Query->Execute Query 在右侧会显示出数据
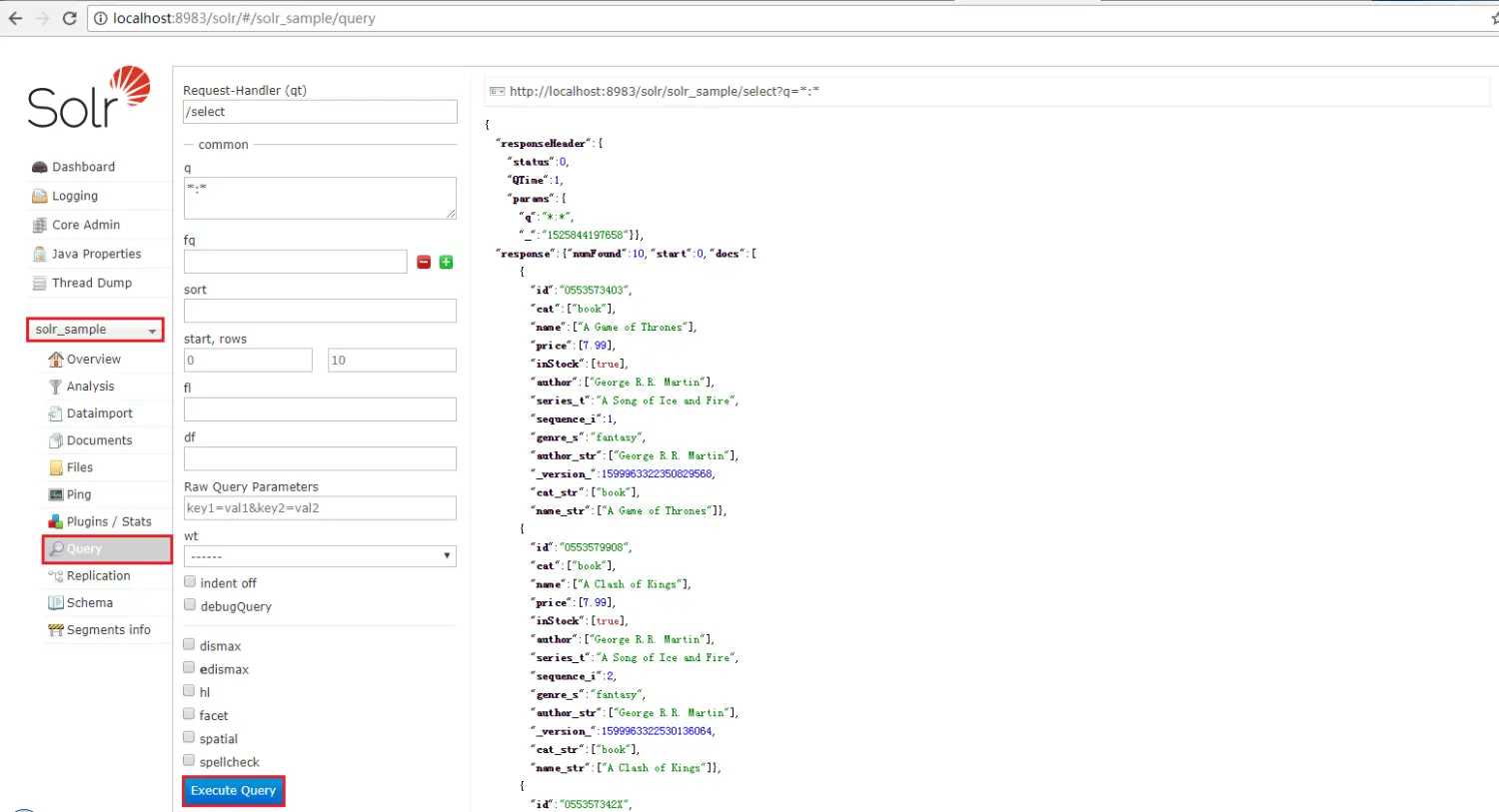
数据显示格式可以自已选择,在中间栏
wt选项可选择

III. Web界面添加文档
- 数据
{
"id": "001",
"name": "Ram",
"age": 53,
"Designation": "Manager",
"Location": "Hyderabad"
},
{
"id": "002",
"name": "Robert",
"age": 43,
"Designation": "SR.Programmer",
"Location": "Chennai"
},
{
"id": "003",
"name": "Rahim",
"age": 25,
"Designation": "JR.Programmer",
"Location": "Delhi"
}
- Documents->Document(s)->Submit Document.
注:在添加文档内容时,如果json数据根节点是数组,请只填写数组中的内容即可,默认提交时系统会设置为JSON数组
 图23.png
图23.png
IV. Java Api 添加文档
-
导包: 将
\solr-7.3.0\dist\solrj-lib\路径下的jar包全部引入工程,\solr-7.3.0\dist\目录下的solr-solrj-7.3.0.jar引入工程,将\solr-7.3.0\example\resources\路径下的log4j.properties复制到工程src目录下 图24.png
图24.png 代码
/**
* Solr Java Api 测试
* @author mazaiting
*/
public class SolrTest {
// Solr链接
public static final String url = "http://localhost:8983/solr/solr_sample";
/**
* 添加Document
* @throws IOException
* @throws SolrServerException
*/
@Test
public void addDocTest() throws SolrServerException, IOException {
// 创建Solr客户端
SolrClient solrClient = new HttpSolrClient.Builder(url).build();
// 准备Solr文档
SolrInputDocument document = new SolrInputDocument();
// 添加字段
document.addField("id", "022");
document.addField("name", "mazaiting");
document.addField("age", "24");
document.addField("addr", "中国科学院理化研究所");
// 添加文档到Solr
solrClient.add(document);
// 保存修改
solrClient.commit();
System.out.println("Documents added.");
}
}
-
测试结果
 图25.png
图25.png
3). 添加XML文档
I. 数据
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>
- add − 这是用于将文档添加到索引的根标记。它包含一个或多个要添加的文档。
- doc − 添加的文档应该包含在<doc> </ doc>标记中。文档包含字段形式的数据。
- field − 字段标记包含文档的字段的名称和值。
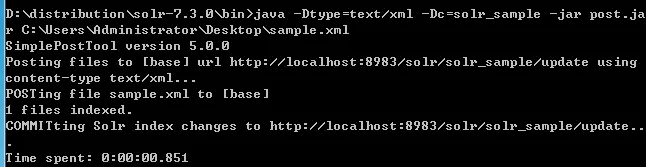
II. Post命令添加
java -Dtype=text/xml -Dc=solr_sample -jar post.jar C:\Users\Administrator\Desktop\sample.xml
4). 更新文档
I. 数据
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>
唯一的区别是这里使用字段的一个update属性。
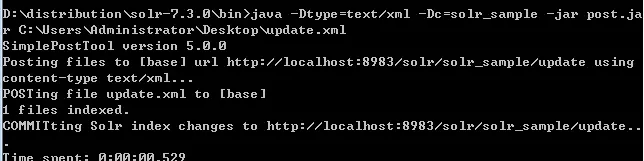
II. 命令
java -Dtype=text/xml -Dc=solr_sample -jar post.jar C:\Users\Administrator\Desktop\update.xml
5). 删除文档
I. 数据
<delete>
<id>003</id>
<id>005</id>
</delete>
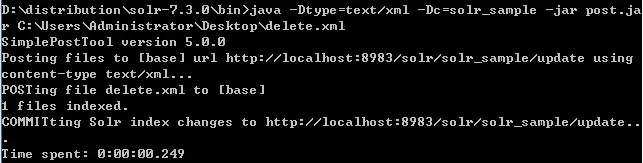
II. Post命令
java -Dtype=text/xml -Dc=solr_sample -jar post.jar C:\Users\Administrator\Desktop\delete.xml
III. 删除字段
<delete>
<query>city:Chennai</query>
</delete>
IV. 删除所有文档
<delete>
<query>*:*</query>
</delete>
V. Java Api
/**
* Solr Java Api 测试
* @author mazaiting
*/
public class SolrTest {
// Solr链接
public static final String url = "http://localhost:8983/solr/solr_sample";
/**
* 删除所有文档
* @throws IOException
* @throws SolrServerException
*/
@Test
public void delAllDocTest() throws SolrServerException, IOException {
// 创建客户端
SolrClient solrClient = new HttpSolrClient.Builder(url).build();
// 从Solr中删除文档
solrClient.deleteByQuery("*");
// 提交
solrClient.commit();
System.out.println("Documents deteled");
}
}
6). 检索数据
I. 代码
/**
* Solr Java Api 测试
* @author mazaiting
*/
public class SolrTest {
// Solr链接
public static final String url = "http://localhost:8983/solr/solr_sample";
/**
* 检索数据
* @throws IOException
* @throws SolrServerException
*/
@Test
public void retrieveDataTest() throws SolrServerException, IOException {
// 创建客户端
SolrClient solrClient = new HttpSolrClient.Builder(url).build();
// 创建查询
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery("*:*");
// 添加查询字段
query.addField("*");
// 执行查询
QueryResponse queryResponse = solrClient.query(query);
// 获取查询到的结果集
SolrDocumentList results = queryResponse.getResults();
System.out.println(results);
System.out.println(results.get(0));
System.out.println(results.get(1));
System.out.println(results.get(2));
System.out.println(results.get(3));
System.out.println(results.get(4));
System.out.println(results.get(5));
// 提交
solrClient.commit();
}
}
II. 执行结果

7). 查询数据
I. 查询参数
| 参数 | 描述 |
|---|---|
| q | 这是Apache Solr的主要查询参数,文档根据它们与此参数中的术语的相似性来评分。 |
| fq | 这个参数表示Apache Solr的过滤器查询,将结果集限制为与此过滤器匹配的文档。 |
| start | start参数表示页面的起始偏移量,此参数的默认值为0。 |
| rows | 这个参数表示每页要检索的文档的数量。此参数的默认值为10。 |
| sort | 这个参数指定由逗号分隔的字段列表,根据该列表对查询的结果进行排序。 |
| fl | 这个参数为结果集中的每个文档指定返回的字段列表。 |
| wt | 这个参数表示要查看响应结果的写入程序的类型。 |
| fl | 表示索引显示那些field(*表示所有field,如果想查询指定字段用逗号或空格隔开(如:Name,SKU,ShortDescription或Name SKU ShortDescription【注:字段是严格区分大小写的】) |
| q.op | 表示q 中 查询语句的 各条件的逻辑操作 AND(与) OR(或) |
| hl | 是否高亮 ,如hl=true |
| hl.fl | 高亮field ,hl.fl=Name,SKU |
| hl.snippets | 默认是1,这里设置为3个片段 |
| hl.simple.pre | 高亮前面的格式 |
| hl.simple.post | 高亮后面的格式 |
| facet | 是否启动统计 |
| facet.field | 统计field |
特殊字符:
1. “:” 指定字段查指定值,如返回所有值*:*
2. “?” 表示单个任意字符的通配
3. “*” 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
4. “~” 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。
5. 邻近检索,如检索相隔10个单词的”apache”和”jakarta”,”jakarta apache”~10
6. “^” 控制相关度检索,如检索jakarta apache,同时希望去让”jakarta”的相关度更加好,那么在其后加上”^”符号和增量值,即jakarta^4 apache
7. 布尔操作符AND、||
8. 布尔操作符OR、&&
9. 布尔操作符NOT、!、- (排除操作符不能单独与项使用构成查询)
10. “+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在
11. ( ) 用于构成子查询
12. [] 包含范围检索,如检索某时间段记录,包含头尾,date:[200707 TO 200710]
II. 示例

查询解释:q查询所有,start,rows从第二条开始到第六条,fl字段过滤,wt显示数据格式
8). Apache Solr中可用的faceting类型 -
- 查询faceting - 返回当前搜索结果中与给定查询匹配的文档数。
- 日期faceting - 它返回在特定日期范围内的文档数。
构面或分组(faceting)命令被添加到任何正常的Solr查询请求,并且faceting计数在同一个查询响应中返回。
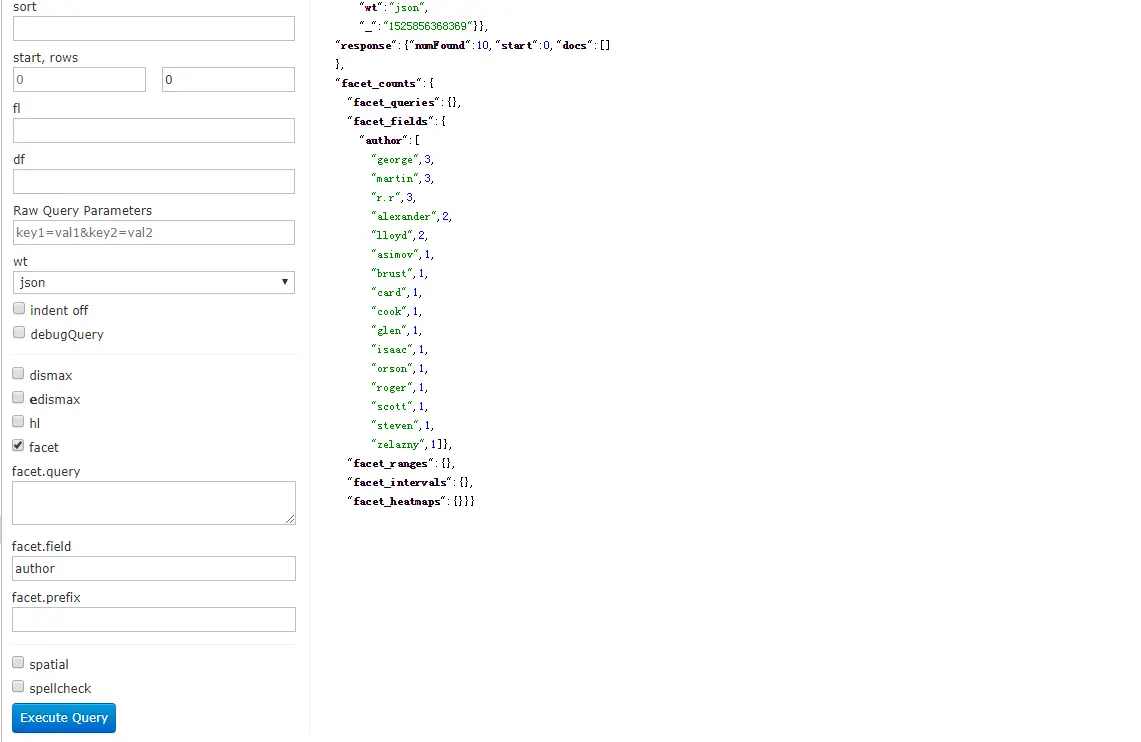
勾选facet后,会出现facet.query、facet.field、facet.prefix三个选项, rows设置为0.
示例:
/**
* Solr Java Api 测试
* @author mazaiting
*/
public class SolrTest {
// Solr链接
public static final String url = "http://localhost:8983/solr/solr_sample";
/**
* 构面或分组
* @throws IOException
* @throws SolrServerException
*/
@Test
public void facetTest() throws SolrServerException, IOException {
// 创建客户端
SolrClient solrClient = new HttpSolrClient.Builder(url).build();
// 准备Solr文档
SolrInputDocument document = new SolrInputDocument();
// 创建查询
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery("*:*");
// 设置终止列
query.setRows(0);
// 设置构面
query.addFacetField("author");
// 创建查询请求
QueryRequest request = new QueryRequest(query);
// 创建查询相应
QueryResponse response = request.process(solrClient);
// 打印
System.out.println(response.getFacetFields());
// 获取构面列表
List<FacetField> facetFields = response.getFacetFields();
// 遍历
for (FacetField facetField : facetFields) {
// 获取值
List<Count> values = facetField.getValues();
for (Count count : values) {
System.out.println(count.getName() + " : " + count.getCount()
+ "[drilldown qry: " + count.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}

3. Solr
1). Solr 与 Lucene 的区别
- Lucene是一个开发源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene 提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene 为基础构建全文检索引擎;
- Solr 的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过 Solr 可以非常快速的构建企业的搜索引擎,通过 Solr 也可以高效的完成站内搜索功能;
2). Solr 文件夹结构
- bin: solr 的运行脚本;
- contrib: solr 的插件,用于增强 solr 的功能;
- dist: 该目录包含 build 过程中产生的 war 和 jar 文件, 以及相关的依赖文件;
- docs: 文档;
- example
- example/solr: 包含了默认配置信息的 Solr 的 Core 目录;
- example/multicore: 包含了在Solr的 multicore 中设置的多个 Core 目录;
- example/webapps: 包含了 solr.war, 该 war 可作为solr的运行实例工程;















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









