







 本文提出了一种名为MODNet的轻量级网络,用于实时无trimap人像抠图。MODNet通过分解抠图任务为语义估计、细节预测和融合,实现高效处理。它在单个RGB输入上运行,无需绿幕,且在PPM-100基准上表现出色。此外,MODNet采用自监督策略(SOC)和单帧延迟技巧(OFD)适应真实世界的视频数据,平滑了视频抠图结果。实验证明,MODNet在实时性能和准确性上优于其他无trimap方法。
本文提出了一种名为MODNet的轻量级网络,用于实时无trimap人像抠图。MODNet通过分解抠图任务为语义估计、细节预测和融合,实现高效处理。它在单个RGB输入上运行,无需绿幕,且在PPM-100基准上表现出色。此外,MODNet采用自监督策略(SOC)和单帧延迟技巧(OFD)适应真实世界的视频数据,平滑了视频抠图结果。实验证明,MODNet在实时性能和准确性上优于其他无trimap方法。
文章目录
实时人像消光真的需要绿屏吗?
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
KeyPoint
个人突发奇想:总的损失函数与各个损失函数之间不一定是一种累加的关系,也许可以通过取不同的函数来,因为不同的训练阶段,每个损失函数所占的比重都是不一样的。
Overview
- 简化了MODNet
在细化阶段,将原始分辨率的图像裁剪成8×8的patch,细化模型只处理误差概率高的小块
Keywords
BRM:背景恢复模块,一阵一阵基类和完成缺少的背景内容,可以为下一帧生成背景图像
matting objective decomposition network (MODNet):
PRM:patch 细化模块,对于尺寸为(h, w)的输入图像,PRM首先对其进行向下采样,并预测出初始粗alpha matte。然后,PRM将初始糙alphamatte上采样为原始图像大小,并将其分为kxk个patches。同时,PRM对初始alpha matte应用自适应池化层和两个卷积层来预测k×k个的缺陷图(由GCT提出),其中每个像素值对应每个patch的缺陷概率。最后,PRM只细化缺陷概率高于预定义阈值=0.01的补丁。可以有效减少伪影。
trimap-free:
SOC:
OFD:
pipelines:
semantic mask:
channel attention
grid search
MobileNetV2 pre-trained
摘要
对于没有绿幕的肖像抠图,现有的作品要么需要昂贵的辅助输入,要么使用计算昂贵的多个模型。因此,它们在实时应用程序中不可用。在此基础上,提出了一种轻量级抠图目标分解网络(MODNet),该网络可以对单个输入图像进行实时抠图处理。MODNet的设计得益于通过明确的限制同时优化一系列相关的子目标。
The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints
此外,由于无修剪方法在实际应用中容易出现域移位***(domain shift problem)***问题,我们引入了
(1)基于子目标一致性的自监督策略,以使MODNet适应真实数据;
(2)将MODNet应用于图像视频序列时,采用单帧延时策略对结果进行平滑处理。MODNet很容易以端到端方式进行训练。它比同时代的抠图方法快得多,每秒63帧。
在本文新提出的精心设计的肖像抠图基准上,MODNet大大优于先前的无trimap方法。更重要的是,我们的方法在日常的照片和视频中取得了显著的效果。现在,你真的需要一个绿色的屏幕实时人像处理吗?
引言
人像抠图的目的是预测一个精确的阿尔法蒙版,可以用来从给定的图像或视频中提取人物。它有广泛的应用,如照片编辑和电影再创作。目前,绿屏需要实时获得高质量的alpha蒙版。当绿色屏幕不可用时,大多数现有的抠图方法[4,17,28,30,44,49]使用预先定义的trimap作为先验。
当绿色屏幕不可用时,大多数现有的抠图方法[4,17,28,30,44,49]使用预先定义的trimap作为先验。然而,人类注释trimap的代价很高,如果通过depth 相机捕获,则精度会很低,也称为蓝屏技术。因此,一些最新的工作试图消除模型对trimap的依赖,即。trimap-free方法。
例如,背景抠图[37]用一个单独的背景图像替换trimap。其他[6,29,38]应用多个模型首先生成伪trimap或语义掩码,然后作为alpha 蒙版预测的先验。然而,使用背景图像作为输入必须采集并对齐两张照片,同时使用多个模型显著增加了推断时间。这些缺点使得上述的匹配方法不适合实时应用,比如在相机中预览。此外,由于缺乏足够的标记训练数据,无trimap方法在实际应用中经常会出现域移位[40],即模型不能很好地推广到实际数据,这也在[37]中讨论。
为了使用单一模型从一张RGB图像中预测出准确的alpha蒙版,我们提出了MODNet,这是一个轻量级网络,它将肖像抠图任务分解为三个相关的子任务,并通过特定的约束同时优化它们。MODNet的背后基于两个洞见。
- 首先,神经网络更擅长学习一系列简单的目标,而不是复杂的目标。因此,解决一系列的抠图子目标可以达到更好的性能。
- 其次,对每个子目标采用显式监督,可以使模型的不同部分学习解耦的知识,使得所有子目标都可以在一个模型内求解。针对MODNet的域漂移问题,提出了一种基于子目标一致性(SOC)的自监督策略。该策略利用子目标之间的一致性来减少预测alpha蒙版中的伪影。
- 此外,在视频抠图的应用中,我们提出了一种单帧延时(OFD)的后处理方法,以获得更平滑的输出。
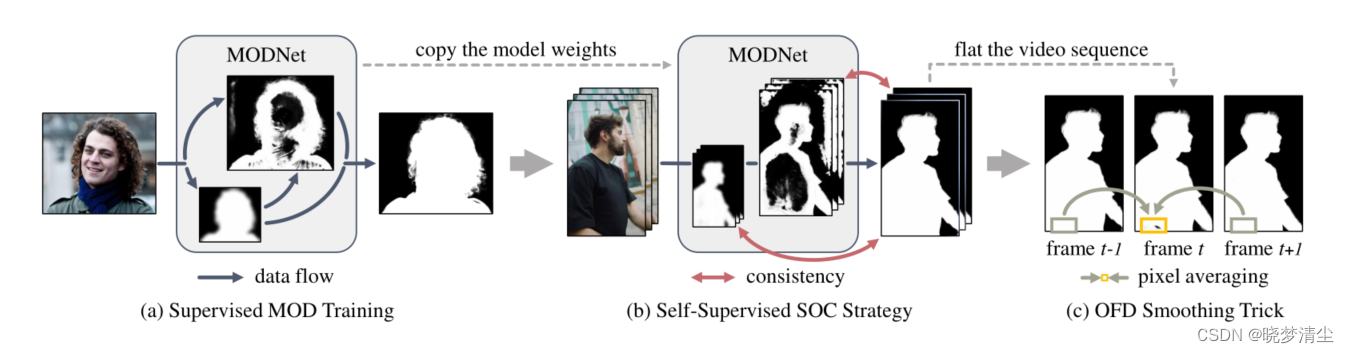
图1:我们的肖像抠图框架。该方法可以在场景变化的情况下实时处理无trimap的人像抠图。(a)在标记的数据集上训练MODNet,从RGB图像学习抠图子目标。(b)为了适应真实世界的数据,我们利用分目标之间的一致性对未标记数据进行MODNet微调。©在视频抠图的应用中,我们的OFD技巧可以帮助平滑视频序列预测的alpha蒙版
MODNet与以前的无trimap方法相比有几个优点。首先,MODNet要快得多。它是为实时应用而设计的,在Nvidia GTX 1080Ti GPU上以63帧每秒(fps)的速度运行,输入大小为512×512。其次,MODNet实现了最先进的结果,得益于(1)目标分解和当前的优化;(2)对每个子目标的具体监督。第三,MODNet可以很容易地进行端到端优化,因为它是一个设计良好的单一模型,而不是一个复杂的管道。最后,得益于我们的SOC策略,MODNet具有更好的泛化能力。虽然我们的结果不能超过那些基于trimap的肖像抠图基准上的方法,但我们的实验表明,MODNet在实际应用中更稳定,因为删除了trimap输入。我们认为我们的方法挑战了使用绿色屏幕进行实时肖像抠图的必要性。
由于开源人像抠图数据集[38,49]的规模或精度有限,之前的工作在不同质量和难度的私人数据集上训练和验证他们的模型。因此,要公平地比较这些方法并不容易。在这项工作中,我们在统一的标准下评估现有的无trimap方法:所有模型都在相同的数据集上训练,并在来自Adobe Matting dataset[49]和我们新提出的基准的肖像图像上进行验证。我们的新基准被贴上了高质量的标签,它比以前的作品中使用的更加多样化。从而更全面地反映出抠图性能。关于这一点的更多讨论将在第5.1节中进行。总之,我们提出了一种新的网络结构,即MODNet,用于实时的无trimap肖像抠图。此外,我们引入了SOC和OFD两种技术,将MODNet推广到新的数据领域,并平滑了视频上的抠图结果。这项工作的另一个贡献是一个仔细设计的人像抠图验证基准。
相关工作
图像抠图
图像抠图的目的是从给定的图像中提取出所需的前景,与图像分割[32]和显著性检测[47]输出的二值掩模不同,蒙版预测每个像素具有精确前景概率的alpha蒙版,其表示为α,公式如下:
I
i
=
α
i
F
i
+
(
1
−
α
i
)
B
i
Ii=αiFi+(1−αi)Bi
Ii=αiFi+(1−αi)Bi
当背景不是绿色屏幕时,这个问题是一个病态问题,因为右侧的所有变量都是未知的。现有的蒙版方法大多以预定义的trimap作为辅助输入,它是一个包含三个区域的遮罩:绝对前景(α= 1)、绝对背景(α= 0)和未知区域(α= 0.5)。这样,抠图算法只需要根据其他两个区域的先验信息来估计未知区域内的前景概率。传统的抠图算法严重依赖底层特征,例如:通过采样[9,10,12,15,22,23,34]或传播[1,2,3,7,14,26,27,41]来确定alpha蒙版,这在复杂场景中往往失败。随着深度学习的飞速发展,人们提出了许多基于卷积神经网络(CNN)的匹配方法,这些方法显著提高了匹配结果。Choet al.[8]和Shenet al.[38]将经典算法与CNN结合,用于alpha蒙版的细化。xue et al.[49]提出了一种自动编码器体系结构,可以从RGB图像和trimap预测alpha蒙版。一些研究[28,30]认为注意机制有助于提高抠图的性能。Lutz等人[31]证明了生成式对抗网络[13]在抠图中的有效性。Caiet al.[4]提出了在抠图前的trimap细化过程,并展示了精心设计trimap的优点。由于获得trimap需要用户的努力,一些最近的方法(包括我们的MODNet)试图避免它,如下所述。
Trimap-free Portrait Matting
图像抠图是非常困难的,当trimap不可用时,因为语义估计将是必要的(定位前景)在预测准确的阿尔法抠图前。
Image matting is extremely difficult when trimaps are unavailable as semantic estimation will be necessary (to locate the foreground) before predicting aprecise alpha matte.
目前,trimap free方法总是专注于特定类型的前景对象,如人类。尽管如此,将rgb图像输入单个神经网络仍然产生不令人满意的alpha蒙版。Sengupta et al.[37]建议捕获一个代价较小的(less expensive) 背景图像作为伪绿色屏幕来缓解这个问题。其他作品设计了包含多个模型的管道。例如,Shen et al.[6]在抠图网络之前组装了trimap生成网络。Zhanget al.[50]采用融合网络将预测的前景和背景结合起来。Liuet al.[29]将三个网络连接起来,以便在抠图中利用粗标记数据。所有这些方法的主要问题是它们不能用于交互式应用,因为:
(1)背景图像可能会一帧一帧地变化,(2)使用多个模型计算昂贵。与它们相比,我们的MODNet在输入和管道复杂性方面都是轻量级的。它以一幅RGB图像为输入,使用单一模型实时处理人像抠图,具有更好的性能。
其他技术
我们简要地讨论了与我们方法的设计和优化有关的一些其他技术。
高分辨率表示:流行的CNN架构[16,18,20,39,43]通常包含一个编码器,即低分辨率分支,以降低输入的分辨率。这样的过程将丢弃图像细节,这些细节在许多任务中是必不可少的,包括图像抠图。Wang et al.[46]提出在整个模型中保持高分辨率的表示,并在不同分辨率之间交换特征,这导致了巨大的计算开销。相反,MODNet只应用一个独立的高分辨率分支来处理前景边界。
注意机制:深度神经网络[5]已经得到了广泛的研究,并被证明可以显著提高性能。在计算机视觉中,我们可以根据它们的操作维度将这些机制分为基于空间的和基于通道的。为了获得更好的结果,一些抠图模型[28,30]结合了耗时的基于空间的注意。在MODNet中,我们整合了基于渠道的注意力,从而在性能和效率之间取得平衡。
一致性约束。一致性是许多半/自监督[36]和域自适应[48]算法背后最重要的假设之一。例如,Keet al.[24]设计了一个基于一致性的框架,可以用于半监督抠图。Toldo et al.[45]提出了一种基于一致性的领域自适应语义分割策略。然而,这些方法由多个模型组成,限制了预测的一致性。相反,我们的MODNet要求模型中各种子目标之间的一致性。
模型
在本节中,我们详细阐述了MODNet的体系结构以及用于优化它的约束条件。
大纲
基于多个模型的方法[6,29,38]表明,**将无trimap的抠图作为一个trimap预测(或分割)步骤加上一个基于trimap的抠图步骤可以获得更好的性能。**这表明神经网络能从分解复杂的目标中受益。在MODNet中,我们将这一思想进行了扩展,将无trimap抠图目标划分为语义估计、细节预测和语义细节融合。直观地说,语义估计输出的是粗糙的前景掩码,而细节预测输出的是精细的前景边界,而语义细节融合则是将前两个子目标的特征融合在一起。如图2所示,MODNet由三个分支组成,它们通过特定的约束学习不同的子目标。
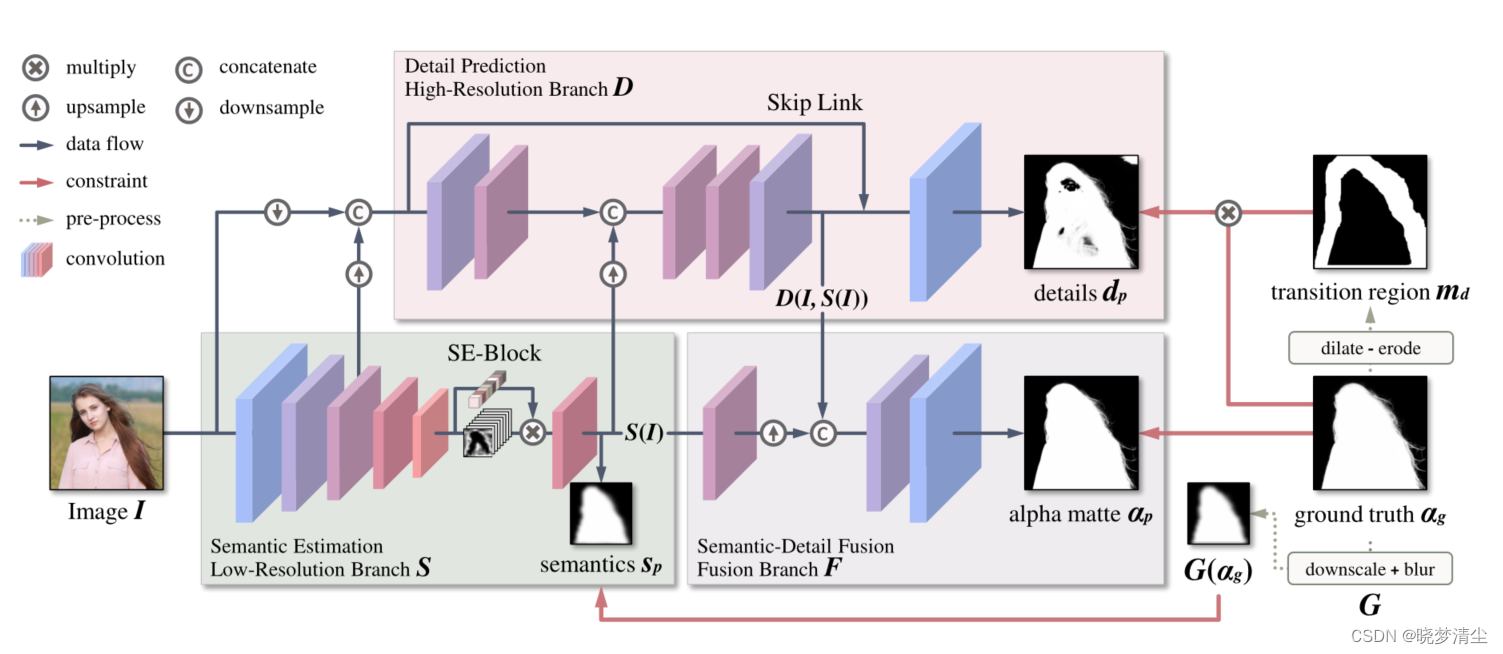
图2。MODNet的体系结构。给定一个输入图像i, MODNet通过三个相互依赖的分支S、D和f预测人类语义 s p s_p sp、边界细节 d P d_P dP和最终alpha 蒙版 α p \alpha_p αp,这些分支受到真实蒙版 α g \alpha_g αg生成的特定监督的约束。由于分解的子目标相互关联,相互加强,我们可以对MODNet进行端到端优化。
具体来说,MODNet有一个低分辨率的分支(由真实蒙版的缩略图监督)来估计人类语义。在此基础上,引入高分辨率分支(由真实蒙版中的过渡区域(α∈(0,1))监督),聚焦于肖像边界。在MODNet的最后,添加了一个融合分支(由整个真实蒙版来监督)来预测最终的alpha蒙版。在下面的小节中,我们将深入研究用于解决每个子目标的分支和监督。
语义估计
与现有的多模型方法类似,MODNet的第一步是在输入图像i中定位人类。不同之处在于,我们只通过编码器提取高级语义,即 MODNet的低分辨率分支S,它有两个主要优点。
- 首先,语义估计变得更加有效,因为它不再由包含解码器的单独模型来完成。
- 其次,高级表示S(I)有助于后续分支和联合优化。
我们可以对S(I)应用任意的CNN骨干。为了便于实时交互,我们采用了MobileNetV2[35]架构,这是一个为移动设备开发的独创模型,作为我们得S。
在分析S(I)中的特征图时,我们注意到一些通道具有比其他通道更准确的语义。此外,这些通道的指数(indices)在不同的图像中也不同。然而,后续分支以同样的方式处理所有的S (I),这可能会导致某些图像中具有虚假语义的f特征图占据预测alpha蒙版的主要位置。我们的实验表明,通道导向的注意力机制可以鼓励使用正确的知识,阻止使用错误的知识。因此,我们在S之后附加一个SE-Block[19],重新加权S(I)的通道。
为了预测粗糙得语义掩码
s
p
s_p
sp,我们将S(I)喂入由一个Sigmoid函数激活的卷积层,将其通道数减少到1。我们以真实蒙版得概略图来监督。由于
s
p
s_p
sp应该是平滑的,我们在这里使用L2损失函数,如:
L
s
=
1
2
∣
∣
s
p
−
G
(
α
g
)
∣
∣
2
\mathcal{L}_s=\frac{1}{2}||s_p-G(\alpha_g)||_2
Ls=21∣∣sp−G(αg)∣∣2
这里的
G
G
G表示高斯模糊后16×下采样。它删除了对人类语义不重要的精细结构(如头发)。
详细的预测
我们用高分辨率分支d处理前景肖像周围的过渡区域,该分支d取I、S(I)和来自S的低层次特征作为输入。重用底层特征的目的是为了减少d的计算开销。此外,我们进一步简化了以下三个方面:
-
(1) 与S相比,d包含更少的卷积层;
-
(2) D中得卷积层得通道数较小;
-
(3) 我们在整个d中不保持原始的输入分辨率。
实际中,d由12个卷积层组成,最大通道数为64。特征图分辨率在第一层下采样到1/4,并在最后两层中恢复。这种设置对细节预测的影响可以忽略不计,因为它包含一个跳过连接。
我们表示以d (I, S(I))表示d的输出,这意味着子目标之间的依赖性-高级人类语义s (I)是细节预测的先验。我们从d (I, S(I))计算了边界细节蒙版dp ,并且通过L1损失函数来学习:
L
d
=
m
d
∣
∣
d
p
−
α
g
∣
∣
1
\mathcal{L}_d=m_d||d_p-\alpha_g||_1
Ld=md∣∣dp−αg∣∣1
其中
m
d
m_d
md一个二进制掩码,来使得
L
d
\mathcal{L_d}
Ld聚焦在人像边界上。通过
α
g
\alpha_g
αg的膨胀和侵蚀产生
m
d
m_d
md。如果像素在过渡区域内,则其值为1,否则为0。实际上,
m
d
m_d
md= 1的像素是在trimap的未知区域。尽管对于
m
d
m_d
md= 0的像素
d
p
d_p
dp可能包含不准确的值,但对于
m
d
m_d
md= 1的像素,它具有较高的精度。
语义细节融合
融合分支f在MODNet中是一个简单的CNN模块,结合了语义和细节。我们首先上采样s (I)来与d (I, S(I))得形状一致。然后我们连接(I)和d (I, S(I))来预测最终的
α
\alpha
α蒙版
α
p
\alpha_p
αp,受以下约束:
L
α
=
∣
∣
α
p
−
α
g
∣
∣
1
+
L
c
\mathcal{L}_\alpha = ||\alpha_p - \alpha_g||_1+\mathcal{L}_c
Lα=∣∣αp−αg∣∣1+Lc
式中为[49]的合成损失。它测量输入图像I与由
α
p
\alpha_p
αp、真实前景和真实背景获得的合成图像之间的绝对差。
MODNet通过
L
s
\mathcal{L}_s
Ls、
L
d
\mathcal{L}_d
Ld、
L
α
\mathcal{L}_\alpha
Lα的总和进行端到端训练,如下:
L
=
λ
s
L
d
+
λ
d
L
s
+
λ
α
L
α
\mathcal{L}=\lambda_s \mathcal{L}_d+\lambda_d \mathcal{L}_s+\lambda_\alpha \mathcal{L}_\alpha
L=λsLd+λdLs+λαLα
其中λs,λd, λα是平衡这三种损耗的超参数。训练过程对这些超参数具有鲁棒性。我们让λs=λα= 1, λd= 10。
适应真实世界的数据
肖像抠图的训练数据需要在头发区域需要进行出色的标记,这对于背景复杂的自然图像几乎是不可能的。目前,大多数标注数据来自摄影网站。虽然这些图像的背景是单色或模糊的,但是标签的过程仍然需要有经验的注释者花相当多的时间和专业工具的帮助来完成。
因此,用于肖像抠图的标签数据集通常很小。xue et al.[49]提出使用背景替换作为数据增强来扩大训练集,已成为图像抠图中的典型设置。但是,由于两个原因,通过这种方式获得的训练样本与日常生活图像的训练样本表现出不同的性质。
-
首先,与前景和背景无缝匹配(fit seamlessly together)的自然图像不同,通过替换背景生成的图像通常是非自然的。
-
第二,专业摄影往往是在可控的条件下进行的,比如特殊的灯光,通常与我们在日常生活中观察到的不同。
因此,现有的无trimap模型总是倾向于过度拟合训练集,在真实数据上表现较差。为了解决域转移问题,我们利用子目标之间的一致性使MODNet适应不可见的数据分布(章节4.1)。此外,为了缓解视频帧之间的闪烁,我们应用了一帧延迟技巧作为后处理(章节4.2)。
SOC
对于来自新域的未标记图像,MODNet中的三个子目标可能有不一致的输出。例如,在预测的alpha蒙版 α p \alpha_p αp中,某一像素属于背景的前景概率可能是错误的,但在预测的粗语义掩码 s p s_p sp中是正确的。直观地说,这个像素在alpha蒙版 α p \alpha_p αp和粗语义掩码 s p s_p sp中应该有接近的值。基于此,我们的自监督SOC策略施加子目标预测之间的一致性约束(图1(b)),以改进MODNet在新领域的性能。
形式上,我们用M表示MODNet。如第3节所述,对于一幅未标记的图像
I
~
\widetilde{I}
I
,
M
M
M有三种输出,分别是:
s
~
p
,
d
~
p
,
α
~
p
=
M
(
I
~
)
\widetilde{s}_p,\widetilde{d}_p, \widetilde{\alpha}_p=M(\widetilde{I})
s
p,d
p,α
p=M(I
)
我们通过下面式子强制将语义
α
~
p
\widetilde{\alpha}_p
α
p和
s
~
p
\widetilde{s}_p
s
p,以及
α
~
\widetilde{\alpha}
α
与
d
~
p
\widetilde{d}_p
d
p保持一致:
L
c
o
n
s
=
1
2
∣
∣
G
(
α
~
p
−
s
~
p
)
∣
∣
2
+
m
~
d
∣
∣
α
~
p
−
d
~
p
∣
∣
1
\mathcal{L}_{cons}= \frac{1}{2}||G(\widetilde{\alpha}_p-\widetilde{s}_p)||_2+\widetilde{m}_d||\widetilde{\alpha}_p-\widetilde{d}_p||_1
Lcons=21∣∣G(α
p−s
p)∣∣2+m
d∣∣α
p−d
p∣∣1
其中
m
~
d
\widetilde{m}_d
m
d表示
α
~
p
\widetilde{\alpha}_p
α
p中的过渡区域,且与Eq.2中的含义相同。但是,在模糊后的
G
(
α
~
p
)
G(\widetilde{\alpha}_p)
G(α
p)上添加L2损失函数将使在被优化的
α
~
p
\widetilde{\alpha}_p
α
p的边界平滑。因此,
α
~
p
和
d
~
p
\widetilde{\alpha}_p和 \widetilde{d}_p
α
p和d
p之间的一致性将会移除高分辨率分支所预测的细节。
为了防止这个问题,我们复制了 M M M为 M ′ M' M′,并在执行SOC之前固定 M ′ M' M′的权重。由于在 d ~ p ′ \widetilde{d}_p' d p′中的细化边缘通过 M ′ M' M′保留了细微的边界,我们在 M M M中附加了一个额外的约束来保持细节:
L d d = m ~ d ∣ ∣ d ~ p ′ − d ~ p ∣ ∣ 1 \mathcal{L}_{dd}=\widetilde{m}_d||\widetilde{d}_p'-\widetilde{d}_p||_1 Ldd=m d∣∣d p′−d p∣∣1
我们通过优化 L c o n s \mathcal{L}_{cons} Lcons和 L d d \mathcal{L}_{dd} Ldd来泛化MODNet到目标域*( target domain)*。
OFD
将图像处理算法独立应用于每个视频帧往往会导致输出的时间不一致。在抠图中,这种现象通常以闪烁的形式出现在所预测的蒙版序列中。由于一帧中闪烁的像素在相邻帧中可能是正确的,我们可以利用前面和后面的帧来固定这些像素。如果 f p s f_{ps} fps大于30,等待下一帧所引起的延迟可以忽略不计。
假设我们有三个连续帧,它们对应的alpha蒙版是αt−1,αt,和αt+1,其中t是帧的下标。如果
α
t
i
\alpha_t^i
αti满足以下条件(如图3所示),我们将其视为闪烁像素:
∣
α
t
−
1
i
−
α
t
+
1
i
∣
≤
ξ
∣
α
t
i
−
α
t
−
1
i
∣
>
ξ
a
n
d
∣
α
t
i
−
α
t
+
1
i
∣
>
ξ
|\alpha_{t-1}^i-\alpha_{t+1}^i| \leq \xi \\ |\alpha_{t}^i-\alpha_{t-1}^i| > \xi \quad and \quad |\alpha_{t}^i-\alpha_{t+1}^i| > \xi
∣αt−1i−αt+1i∣≤ξ∣αti−αt−1i∣>ξand∣αti−αt+1i∣>ξ
在实际应用中,我们设置 ξ = 0.1 \xi=0.1 ξ=0.1来度量像素值的相似性。表明当 α t − 1 i 和 α t + 1 i \alpha_{t-1}^i和\alpha_{t+1}^i αt−1i和αt+1i的值很接近,而 α t i \alpha_{t}^i αti与 α t − 1 i 和 α t + 1 i \alpha_{t-1}^i和\alpha_{t+1}^i αt−1i和αt+1i的值相差很大时, α t i \alpha_{t}^i αti出现闪烁。将 α t i \alpha_{t}^i αti的值替换为 α t − 1 i 和 α t + 1 i \alpha_{t-1}^i和\alpha_{t+1}^i αt−1i和αt+1i的平均值,即:
α t i = { α t − 1 i + α t + 1 i 2 , 如果满足条件C α t i , 其他 \alpha_t^i= \left\{ \begin{aligned} &\frac{\alpha_{t-1}^i+\alpha_{t+1}^i}{2},& \text{如果满足条件C}\\ & \alpha_t^i,& \text{其他} \end{aligned} \right. αti=⎩ ⎨ ⎧2αt−1i+αt+1i,αti,如果满足条件C其他
注意:OFD只适用于平稳移动。它可能在快速动作视频中失败。
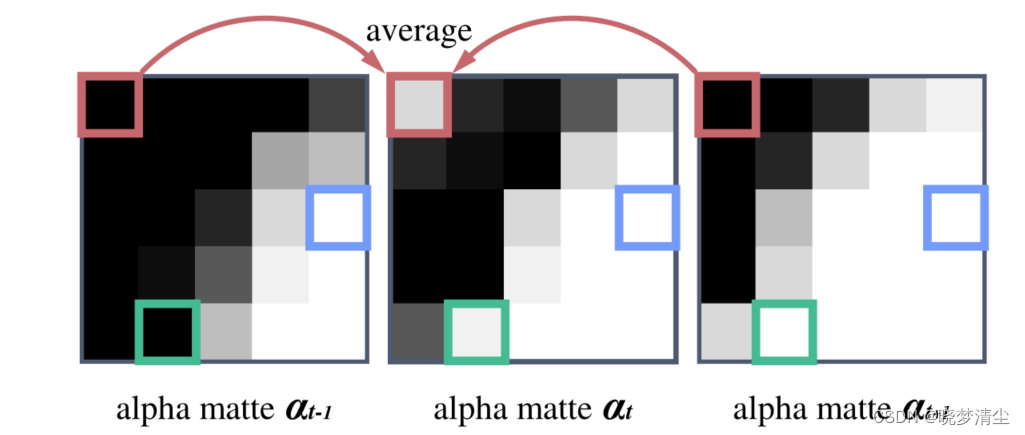
图3。通过OFD判断闪烁像素。前景在连续的三帧中稍微向左移动。我们关注三个像素:(1)绿色标记的像素不满足第一个条件C;(2)蓝色标记的像素不满足第二个条件C;(3)红色标记的像素在帧处闪烁。
实验结果
在本节中,我们首先介绍用于肖像抠图的PPM-100基准。然后将MODNet与现有的PPM-100抠图方法进行比较。我们进一步进行了消融实验,以评估MODNet的各个方面。最后,我们演示了SOC和OFD在使MODNet适应真实数据方面的有效性。
摄影人像消光基准
现有的研究通过图像合成,从少量的标记数据构建了他们的验证基准。由于前景和背景之间不自然的融合或语义不匹配,它们的基准比较容易实现(图4(a))。

图4。基准比较。(a)[6,29,50]中使用的验证基准通过替换背景来合成样本。相反,我们的PPM-100包含了原始的图像背景,在前景中具有更高的多样性。我们展示了(b)带有细毛的样品,©带有附加物体的样品,以及(d)没有散景或全身。
因此,在这些基准上,trimap free模型可能与基于trimap的模型具有可比性,但在自然图像上的结果却不令人满意即 没有背景替换的图像表明无trimap方法的性能还没有得到准确的评价。我们通过Adobe matting Dataset上的抠图结果证明了这一观点。相比之下,我们提出了一个人像照片抠图基准(PPM-100),其中包含100张具有各种背景的经过精细注释的人像图像。为了保证样本的多样性,我们定义了几种分类规则来平衡PPM-100中的样本类型。例如:(1)是否包括整个人体;(2)图像背景是否模糊;(3)是否持有其他物品。我们把人们手里拿着的小物件作为前景的一部分,这更符合实际应用。如图4(b)©(d)所示,PPM-100中的样本背景更自然,姿态更丰富。因此,我们认为PPM100是一个更全面的基准。
Results on PPM-100
我们将MODNet与FDMPA[51]、LFM[50]、SHM[6]、BSHM[29]和HAtt[33]进行了比较。我们遵循原始论文,复制没有公开可用代码的方法。我们使用DIM[49]作为基于trimap的基线。为了公平比较,我们在同一个数据集上训练所有模型,该数据集包含近3000个带注释的前景。使用背景替换[49]扩展训练集。对于每个前景,我们通过随机裁剪生成5个样本,通过从OpenImage数据集[25]合成背景生成10个样本。我们使用预先训练的MobileNetV2在监督人员分割(SPS)[42]数据集上作为所有trimap free模型的主干。对于之前的方法,我们通过网格搜索来探索最优超参数。对于MODNet,我们用SGD进行40个epoch的训练。批量大小为16时,初始学习率为0.01,每10个epoch后乘以0.1。我们使用均方误差(MSE)和平均绝对差(MAD)作为定量指标。
表1显示了pm -100的结果,MODNet在MSE和MAD方面都优于其他无trimap方法。
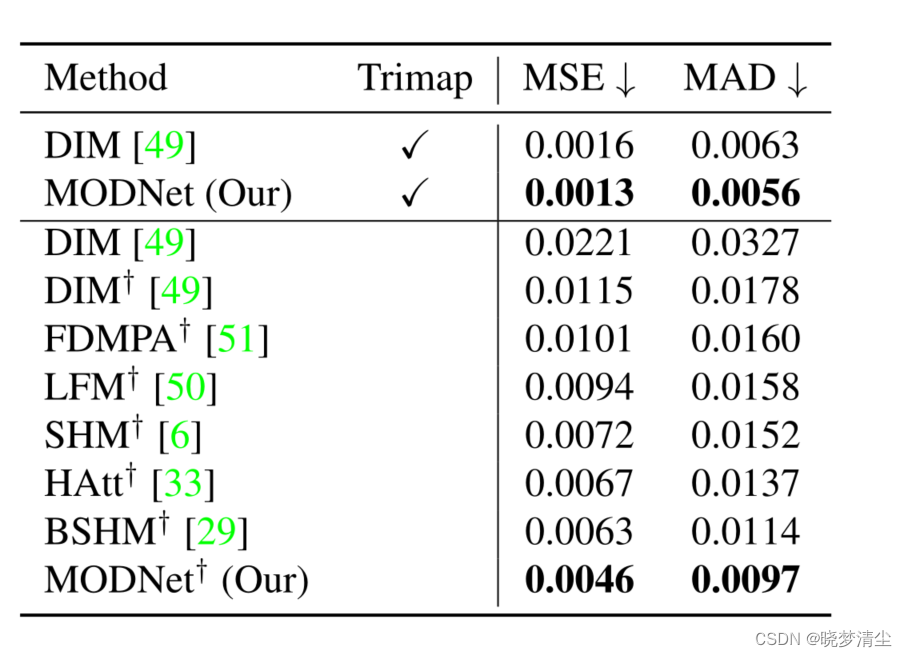
表1。pm -100的定量结果。'†'表示模型在SPS数据集上预先训练。'↓’表示越低越好。
然而,它的性能仍然不如基于trimap的DIM,因为PPM-100包含具有挑战性的姿势或服装的样品。当我们将MODNet修改为基于trimap的方法时,即当采用trimap作为输入时,它的性能优于基于trimap的DIM,这表明了我们的网络体系结构的优越性。Fig.5 可视化了样本3。我们进一步论证了MODNet在模型规模和执行效率方面的优势。较小的模型便于在移动设备上部署,而对于实时应用程序来说,高执行效率是必须的。

图5。无trimap方法对PPM-100的视觉比较。MODNet在中空结构(第一行)和头发细节(第二行)方面表现更好。然而,它仍然可能在挑战姿势或服装(第三排)上犯错误。这里的DIM[49]不采用trimaps作为输入,而是在SPS[42]数据集上进行预训练。放大以获得最佳视觉效果。
我们用参数的总数来衡量模型的大小,我们用PPM-100的平均推理时间来反映在NVIDIA GTX 1080Ti GPU上的执行效率,输入时间超过PPM-100(输入图像裁剪为512×512)。请注意,由于大的特征图或耗时的机制,更少的参数并不意味着更快的推断速度,例如。模型可能有注意。
表6展示了这两个指标,MODNet的推断时间为15.8ms (63 fps),是之前最快的FDMPA (31 fps)的两倍。
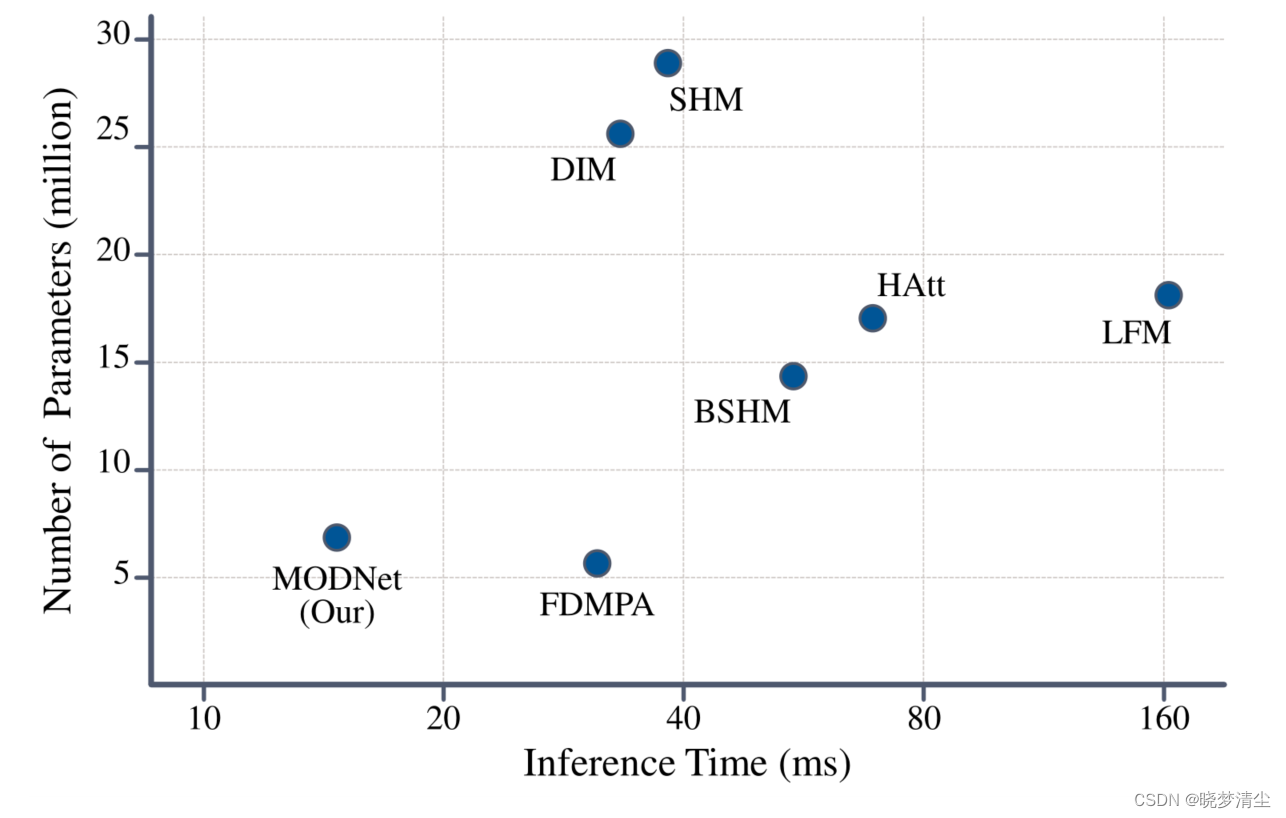
图6。模型规模和执行效率的比较。推理时间越短越好,模型参数越少越好。我们可以用1000除以推理时间得到fps。尽管MODNet的参数数量略高于FDMPA,但我们的性能明显更好。我们还对pm -100进行了MODNet消融实验(表2)。
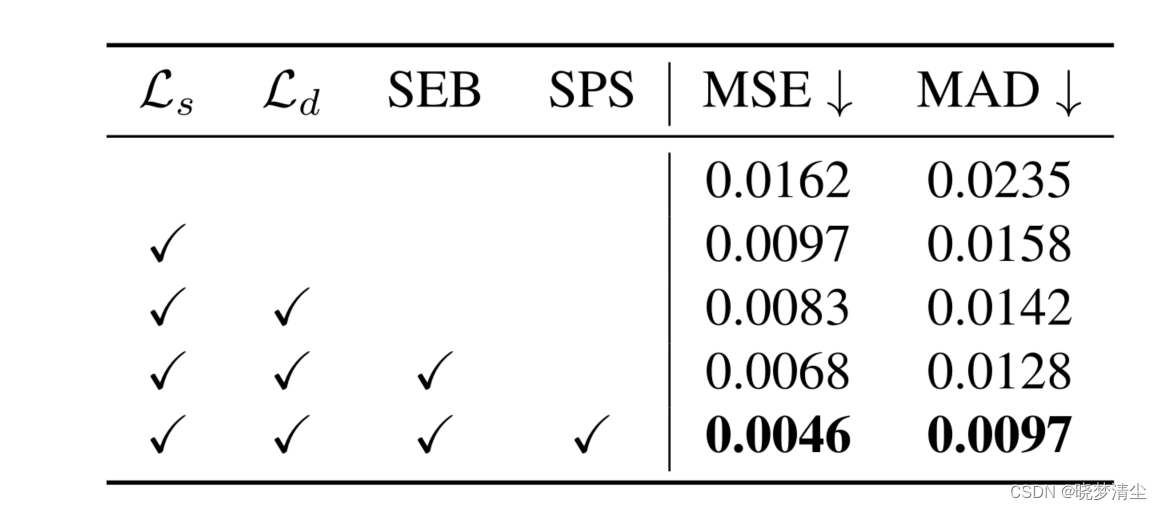
表2。MODNet消融。SEB: MODNet低分辨率分支中的SE-Block。SPS:对SPS数据集进行预训练。
应用 L s \mathcal{L}_s Ls和 L d \mathcal{L}_d Ld来约束人类语义和边界细节带来了相当大的改进。加上SE-Block的结果证明了特征图重新加权的有效性。虽然SPS预训练是MODNet的可选方法,但在其他无trimap方法中起着至关重要的作用。例如,在表1中,未经预训练的trimap free DIM的表现远不如经过预训练的DIM。
真实世界数据的结果
根据不同的设备类型或不同的成像方法,可以将真实世界的数据划分为多个领域。通过假设同一类型设备(如智能手机)捕获的图像属于同一域,我们捕获多个视频片段作为自监督SOC域自适应的未标记数据。在这个阶段,我们在MODNet中冻结BatchNorm[21]层,并由Adam以0.0001的学习率微调卷积层。
这里我们只提供直观的结果,因为没有真实的alpha蒙版。在图7中,我们在绿色屏幕上合成了前景,以强调——SOC对于将MODNet推广到真实世界的数据是至关重要的。

图7:SOC和OFD在真实视频上的结果。我们从左到右显示三个连续的视频帧。从上到下依次为:(a)输入,(b) MODNet, © MODNet + SOC, (d) MODNet + SOC + OFD。t−1帧中的蓝色标记说明了SOC的有效性,而帧中的红色标记突出了OFD消除的闪烁
此外,OFD进一步消除了边界上的闪烁。在实践中应用基于trimap的方法需要额外的步骤来获得trimap,这通常是由深度相机实现的,例如ToF[11]。具体来说,深度图中的像素值表示3D位置到摄像机的距离,距离摄像机越近的位置像素值越小。我们可以首先定义一个阈值,将反向深度图分割为前景和背景。然后,我们可以通过膨胀和侵蚀产生修剪。然而,该方案将识别人类面前的所有物体,即离相机更近的物体,作为前景,在某些情况下导致了蒙版预测的错误trimap。相反,MODNet通过与trimap输入解耦避免了这个问题。我们在图8中给出了一个例子。

图8:MODNet相对于trimap方法的优势。在这种情况下,从深度图生成的不正确的trimap会导致基于trimap的DIM[49]失败。为了比较,MODNet正确地处理了这种情况,因为它只输入了RGB图像。
我们还将MODNet与[37]提出的背景抠图(BM)进行了比较。由于BM不支持动态背景,我们在[37]的固定摄像机场景中进行验证。BM依赖于静态背景图像,它隐含地假设输入图像序列中值发生变化的所有像素都属于前景。如图9所示,当背景中突然出现一个运动物体时,BM的结果会受到影响,但MODNet对这种扰动具有鲁棒性。

结论
本文提出了一种简单、快速、有效的MODNet来避免在实时人像抠图中使用绿屏。该方法仅采用RGB图像作为输入,实现了对变化场景下alpha蒙版的预测。此外,由于提出了SOC和OFD, MODNet在实践中较少受到域转移问题的影响。MODNet在精心设计的PPM-100基准和各种真实世界的数据上显示出良好的性能。不幸的是,不幸的是,我们的方法无法处理训练集未涵盖的奇怪服装和强烈运动模糊。一个可能的未来工作是通过附加的子目标来解决运动模糊下的视频消光,例如,光流估计。


















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









