







安装Hive前需先安装Hadoop,可参考文章:Hadoop_2.7.2安装配置
1、下载安装包
方式一、从官网下载:https://hive.apache.org
方式二、从CSDN资源快速下载:快速下载Hive安装包
2、上传压缩包
将压缩包上传到/usr/local/software/
3、解压到/usr/local/目录下
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local/
4、重命名
mv apache-hive-1.2.1-bin/ hive
5、新建配置文件
将conf目录下的hive-env.sh.template复制一份为hive-env.sh
cp hive-env.sh.template hive-env.sh
6、修改配置文件
#HADOOP_HOME路径
export HADOOP_HOME=/usr/local/hadoop-2.7.2
#HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/usr/local/hive/conf
7、拷贝Mysql连接驱动包
将mysql驱动jar包复制到hive/lib目录下,jar包下载地址:https://download.csdn.net/download/mcajax/12149487
(下载后解压即可得到mysql驱动jar包)
8、将元数据配置到Mysql
在hive/conf目录下新建hive-site.xml
添加内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
9、修改数据仓库位置
在hive-site.xml中添加以下内容
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
10、配置Hdfs中文件夹访问权限
hdfs dfs -chmod 777 /user/hive/warehouse
11、展示当前库及表头配置
在hive-site.xml中添加以下内容:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
12、关闭元数据检查(可选)
在hive-site.xml中添加以下内容:
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
13、配置环境变量
在/etc/profile中添加以下内容:
#hive
export HIVE_HOME=/usr/local/sqoop-1.4.6
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
14、初始化元数据
hive/bin/schematool -dbType mysql -initSchema
若初始化元数据失败,则可能是元数据已经存在,可删除重新生成:
(1)查找metastore目录位置:find / -name metastore,本机路径为:/var/lib/mysql/metastore
(2)删除metastore目录
(3)再次执行上面命令刷新元数据
15、启动hive
hive
16、查看hive数据库默认编码
hive的元数据存在Mysql数据库的metastore库中
查看Hive库编码格式
mysql> show create table columns_v2;
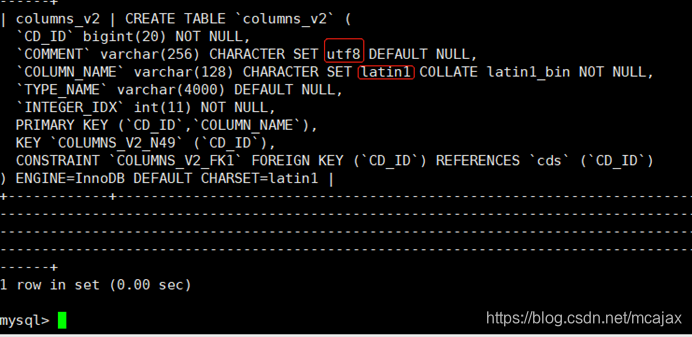
17、修改编码格式防止中文乱码
(1)字段注释
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
(2)表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
(3)分区字段注释
mysql> alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
mysql> alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
(4)索引注释
mysql> alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









